我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 Batch 让 Celery 工作人员执行计算密集型任务
微服务中的常见模式是向某些后台工作队列发送异步请求。这些请求可以从发送电子邮件等简单任务到更复杂的业务流程(例如验证金融交易)不等。另一类后台工作是计算密集型流程,比如对视频进行编码,或者根据经过训练的机器学习模型对数据进行注释,这可能需要与其他请求不同的计算资源集。
开发人员通常会利用直接集成在应用程序中的分布式任务队列系统。这方面的例子有 Django 应用程序中的 Celery 或 Node.js 中的 BullMQ。如果你致力于在应用程序中使用分布式任务队列系统来处理计算密集型异步任务,例如视频编码,那么这篇文章就是为你准备的。
今天,我将向您展示如何使用 亚马逊云科技 Batch 处理计算密集型后台工作请求来运行您的任务队列工作程序。我将以
芹菜的背景信息
与其他分布式任务系统一样,Celery 利用消息代理在消息队列中捕获来自应用程序的请求。一组从队列中读取的独立工作进程,为打开的请求提供服务。
Celery 可以有多个任务队列来路由不同类型的任务。例如,您可以将低优先级和高优先级的任务发送到具有不同服务级别协议 (SLA) 的队列,以了解这些任务何时得到处理。Celery workers 是长时间运行的进程,他们不断监视任务队列中是否有新工作。工作人员可以选择处理来自一组受限队列的消息。在我们的低优先级和高优先级示例中,您可以让一组工作人员专门处理高优先级的工作,而其他工作人员可以根据需求处理任一队列的请求。
在应用程序旁边运行几个工作人员来处理小而罕见的请求(例如,“ 将密码重置链接发送到 user@example.com ”)没问题。但是,让大量工作人员跑来处理高峰请求或为不经常但计算密集型的任务提供服务,这并不具有成本效益。您需要根据任何给定时间点的实际应用程序需求来扩展工作人员总数及其底层计算资源。队列中的消息数量是衡量所需工作人员数量和资源数量的一个很好的指标。
亚马逊云科技 Batch 上的 Celery
现在您已经了解了 Celery,让我们来看看如何将其部署到 亚马逊云科技 上以处理计算密集型任务。
由此可见,我们需要:
- SQS 队列,用于将后台请求存储为消息供工作人员使用。
- 对 SQS 队列指标做出反应的亚马逊 CloudWatch 警报。具体而言,是队列中的消息数量以及最早消息的使用年限。
-
亚马逊 EventBridge 规则会在警报进入警报状态时执行操作,并向 亚马逊云科技 Batch 提交任务以运行 Celery
工作人员。 - 构成工作人员执行环境核心的 亚马逊云科技 Batch 资源(任务队列、计算环境和任务定义)
- 用于运行 Celery 工作进程的容器镜像。容器处理工作人员的生命周期,并在队列中没有其他项目需要处理时退出。
- 容器映像的亚马逊弹性容器注册表 (Amazon ECR) 注册表。
图 1 显示了该解决方案的高级架构。该图显示应用程序向专门供 亚马逊云科技 Batch 处理的 SQS 队列发送 Celery 任务请求。两个 CloudWatch 警报(一个用于少数 (5),另一个用于大量消息(50)——配置为监控队列中的消息数量。当超过各自的阈值时,警报进入警报状态。为每个警报激活一对相应的 Amazon EventBridge 规则。如果队列中有 5 条消息,则 EventBridge 规则将提交一个 亚马逊云科技 Batch 任务,该任务反过来运行一个 Celery 工作线程。如果队列中有 50 多条消息,则 EventBridge 将提交 亚马逊云科技 Batch 数组任务,启动 10 个 Celery 工作线程。
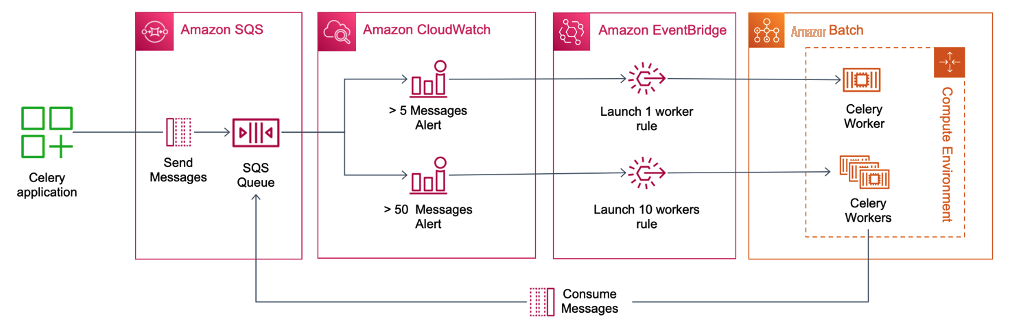
图 1:解决方案的架构。该图显示应用程序向 SQS 队列发送 Celery 任务请求。两个 CloudWatch 警报配置为监控队列中的消息数量,并在超过阈值时进入 “警报” 状态。一对相应的 EventBridge 事件配置为要么为一个 Celery 工作人员提交一个 亚马逊云科技 Batch 任务(如果消息数量较少),要么提交 亚马逊云科技 Batch 数组任务来启动一组工作程序(如果队列中有大量消息)
你可以在 GitHub 上的 aws-samples
员工生命周期管理
Celery 文档建议对工作人员进行 “
-
将 Celery 工作器作为分离的进程启动(使用
--detach参数),并为进程 ID 文件提供位置 - 进入一个循环,在该循环中,该进程将等待几分钟,然后再检查 SQS 队列中的消息数量
- 如果消息仍然存在,则等待循环继续
-
如果没有剩余的消息,它将使用进程 ID 文件向工作人员发送 T
ERM 信号。这将允许工作人员完成当前任务,然后退出 - 工作进程退出后,启动过程将停止,容器也将停止,标志着批处理作业的结束
Celery 工作人员的资源分配与实际任务的对比。
默认情况下,Celery 工作人员将使用所有可用的 CPU 来生成子进程来并行处理任务。此模型适用于不涉及应用程序代码之外的外部依赖关系的任务,Celery 工作人员将高效地使用资源。
话虽如此,很适合 亚马逊云科技 Batch 的任务类型往往会调用位于应用程序之外的多线程应用程序。一个例子是使用
为了解决这个难题,您可以将 Celery 工作线程限制为单个进程(使用
-concur
在 FFmpeg 示例中,亚马逊云科技 Batch 任务定义将容器资源指定为 8 vCPU。Celery 工作人员生成一个进程,该进程下载视频进行编码,然后调用 FFmpeg 使用七个线程处理视频。编码完成后,工作人员会将视频保存到永久存储空间(例如Amazon S3存储桶),并清理所有暂存空间以备下一个编码请求(如果有)。
简而言之,您应该将请求的 亚马逊云科技 Batch 计算环境和任务定义相匹配,以匹配您的计算密集型 Celery 任务所需的资源。你还应该将你的 Celery 工作人员限制在 python 进程所需的资源子集内,其余的则留给任何需要它的外部程序。
批处理任务的预定义队列
默认情况下,Celery 会根据需要
ask_routes 配置选项将 Celery 配置为将任务路由
到特定队列。
ulate_pi ()
方法映射到批处理 SQS 队列。
task_routes = {"app.calculate_pi": {"queue": "celery-batch"}}限制工作人员可以处理的队列
默认情况下,Celery 工作人员将处理来自所有队列的消息。由于我们假设不同的请求需要不同的资源,因此我们要限制工作人员可以访问哪个队列。您可以 使用
-
Q 参数限制 Celery 工作人员
cel
ery-batchjobs 的 SQS 队列中的请求的示例:
celery -A proj worker -Q celery-batchjobs
aws-samples 存储库中的 Bash 脚本使用 亚马逊云科技 Batch 任务定义中定义的 CELER
Y_QUEUE_NAME 和 CELERY_QUEUE_URL 环境变量
来定义要从哪个队列中提取
队列
。
扩展注意事项
示例 CloudWatch 警报和 EventBridge 规则不是很复杂。他们的缩放逻辑有以下限制:
- 只有当 CloudWatch 警报 首次 进入警报状态时,EventBridge 规则才会触发。如果警报状态仍为 ALARM,则该规则将不会启动更多批处理进程。
- EventBridge 规则仅为 “> 5 条消息” 警报运行一个批处理工作器,为 “> 50 条消息” 警报运行 10 个批处理工作器。
换句话说,如果一千个请求非常快地到达,Batch 将只启动 11 个工作程序来处理这些请求。这可能不足以在更多消息到达之前耗尽队列。一种选择是在更高的消息数量下创建更多的警报,但这不是一个可扩展或优雅的解决方案。
如果您的消息速率不可预测且变化很大,更好的方法是将
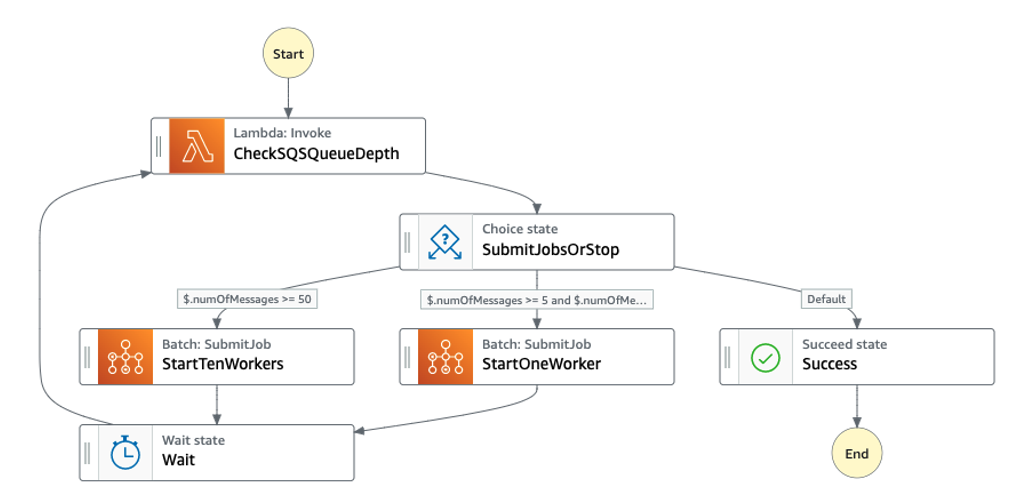
图 2:一个 亚马逊云科技 Step Functions 状态机,它调用 亚马逊云科技 Lambda 函数来返回 SQS 队列中可见消息的数量,并在有 5 到 10 条消息时决定是否启动一个工作程序。如果有超过 50 条消息,则会启动 10 个工作人员。短暂等待后,状态机再次检查可见消息的数量,并在必要时提交更多 亚马逊云科技 Batch 任务。如果没有可见消息,则状态机退出。
消息量低
有时,在您超出处理消息的服务级别协议 (SLA) 之前,后台请求速率可能无法达到最低消息数量阈值。例如,可能需要几个小时才能累积足够多的消息来触发警报,但是您有 SLA,可以在到达后的 30 分钟或更短时间内开始处理消息。
为了满足基于时间的服务级别协议,您可以创建一个 CloudWatch 警报,该警报在 Approxim
ateAgeofoldestMessag
e 接近服务级别协议要求时进入
警报
状态,以及一个对警报做出反应以提交 亚马逊云科技 Batch 任务请求的 EventBridge 规则。
特殊资源需求的核算
最后,如果您的任务子集需要特殊的基础架构,例如 GPU 加速实例,但其他请求在非加速实例上具有更好的性价比,则您可以创建和部署与这些资源对应的多个批处理计算环境、作业队列和作业定义。您的应用程序还需要向相应的队列发送请求,这可以通过在 Celery 中通过任务路由来完成。以下是 t
ask_rout
e 声明的示例,它将任务发送到多种类型的资源:
task_routes = {
'app.encode_video': 'celery-batch-gpu',
'app.sort_csv_file': 'celery-batch-graviton'
}
这种架构模式的适用性
到目前为止,我们假设使用 亚马逊云科技 Batch 对 SQS 队列的指标使用警报来扩展后台工作代理是处理此类请求的最有效架构。
当然不是 。如果您直接将请求发送到批处理作业队列,则可以从根本上简化架构,使其 更易于管理 并 提高效率。这样就无需使用 CloudWatch 警报、EventBridge 规则或我们为管理 Celery 员工的正确扩展行为而引入的其他机制。
但是,就像开发应用程序的许多方面一样,您有时 无法选择 应用程序中包含哪些组件。
我将这篇文章的目标对准了开发人员和运营商,这些应用程序堆栈已在分布式任务队列系统上进行了标准化以实现异步工作,并且需要为各种计算密集型或长时间运行的请求有效地扩展底层资源。
有了这个架构和这些示例,我希望你现在可以很好地了解如何使用 亚马逊云科技 Batch 处理计算密集型工作请求,同时尽量减少对应用程序代码的更改,主要是将这些任务配置到可以监控的特定队列,将扩展需求与其他请求分开进行监控。
摘要
在这篇文章中,我以 Celery 为例,介绍了如何利用 亚马逊云科技 Batch 为后台工作队列运行工作人员。我介绍了如何使用 SQS 队列将发往 Batch 的请求与其他请求分开;如何配置 CloudWatch 警报以在批处理队列中收到足够的消息时激活,以及如何使用 EventBridge 规则对警报状态的变化做出反应。我还介绍了容器化工作流程的一些注意事项、如何调整扩展策略以及需要加速器(如 GPU)的流程的更多注意事项。
要开始在 亚马逊云科技 Batch 上使用 Celery
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。