我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用开源 Goldilocks 调整您的 Kubernetes 应用程序的大小以优化成本
在过去的几年中,随着公司实现业务应用程序的现代化,许多公司已使用Kubernetes上的容器转向基于微服务的架构。最初的重点主要是设计和构建新的云原生架构以支持应用程序。随着环境的发展,我们已经看到重点转移到优化资源分配和调整工作负载大小以降低成本。
在这篇博客文章中,我们将分享有关如何使用 Goldilocks 在 Kubernetes 环境中优化资源分配和调整应用程序大小的指南。我们将介绍如何安装 Goldilocks 以及示例应用程序以查看建议的资源推荐。这适用于所有 Kubernetes 应用程序,包括那些在亚马逊弹性 Kubernetes 服务 (Amazon EKS) 上运行的、使用托管节点组、自我管理的节点组和 亚马逊云科技 Fargate 部署的应用程序。
在 Kubernetes 上调整应用程序的大小
在 Kubernetes 中,资源大小调整是通过在应用程序清单中设置资源规格来完成的。这些设置直接影响:
- 性能 — 如果没有适当的资源规范,在同一节点上运行的 Kubernetes 应用程序将任意争夺资源。这可能会对应用程序性能产生负面影响。
- 成本优化 — 部署资源规格过大的应用程序将导致成本增加和基础设施未得到充分利用。
- 自动扩缩 — Kubernetes 集群自动扩缩器和水平 Pod 自动缩放需要资源规格才能运行。
Kubernetes 中最常见的资源规格是针对
请求和限制
容器化应用程序以 Pod 的形式部署在 Kubernetes 上。CPU 和内存请求及限制是 P
请求和限制在 Kubernetes 中分别提供不同的功能,对调度和资源执行的影响也不同。
日程安排
Kubernetes 调度器仅在确定 Pod 在集群中的放置位置时才会考虑请求。可接受的节点是那些有足够可用资源来满足 Pod 的资源请求的节点。调度器不考虑限制。
资源执法
运行 Pod 的节点上的容器运行时负责资源执行。请求和限制都是确保应用程序能够访问其所需计算资源的因素。它们对 CPU 和内存的影响不同:
-
CPU — 如果未指定限制,则节点上的每个 Pod 都可以使用主机上所有可用的 CPU。
一旦可用的 CPU 耗尽,就会使用名 为 cgroups 的 Linux 原语对 Pod 进行限制。 这是一个资源共享原语,可确保每个 Pod 都能获得合理的 CPU 时间。CPU 请求决定公平份额,并进行加权以为 CPU 请求较大的 Pod 提供更多的 CPU 时间。如果指定了限制,则 CPU 时间将不会超过特定限制。 -
内存 — 就像 CPU 一样,如果没有指定内存限制,则每个 Pod 都可以使用主机上的所有可用内存。与 CPU 不同,当内存耗尽时,没有共享机制。这个 Pod 要么被
Linux 内存不足 (OOM) 杀手 终止,要 么kubelet 会驱逐 该 Pod。如果 Pod 的内存使用量超过其限制,也会发生同样的过程。
垂直 Pod 自动扩缩器
那么,应用程序所有者如何为其 CPU 和内存资源请求选择 “正确” 值呢?理想的解决方案是在开发环境中对应用程序进行负载测试,并使用可观测性工具测量资源使用情况。尽管这可能对贵组织最关键的应用程序有意义,但对于部署在集群中的每个容器化应用程序来说,这可能并不可行。
幸运的是,有一个 Kubernetes 项目有一个专门为帮助提供资源推荐而设计的功能——
VPA 有一个推荐引擎,可以衡量应用程序性能并提出规模建议。VPA 推荐引擎可以独立部署,因此 VPA 不会执行任何自动扩展操作。它是通过为每个应用程序创建 VerticalpodautoScaler 自定义资源来配置的,VPA 会使用资源大小建议更新对象的状态字段。
为集群中的每个应用程序创建
VerticalpodautoScaler
对象并尝试读取和解释 JSON 结果在大规模上具有挑战性。
金发姑娘
Goldilocks 是一个来自
-
一种控制器,可自动为集群中的工作负载创建
VerticalpodautoScaler对象。 - 显示所有受监控工作负载的资源推荐的仪表板。
Goldilocks 的默认配置是可选模式。您可以通过向命名空间添加
goldilocks.fairwinds.co
m/enabled: true 标签来选择监控哪些工作负载。
解决方案概述
让我们来看看如何安装 Goldilocks,包括其依赖项指标服务器和垂直容器自动扩缩器。然后,我们将安装一个示例应用程序来查看建议的资源推荐。此处显示的图表说明了 Amazon EKS 集群上的所有组件及其交互作用。
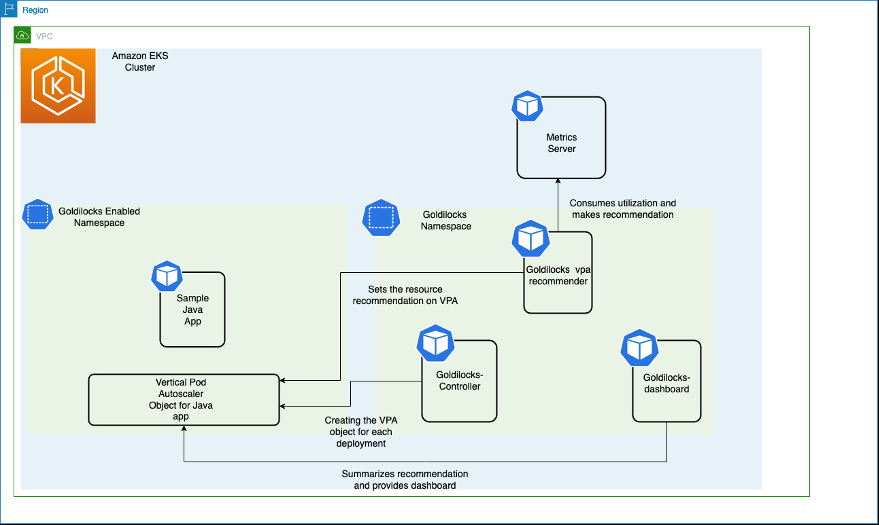
指标服务器从运行在工作节点上的 Kubelet 收集资源指标,并通过 Met
Goldilocks 控制器监视带有 gold
ilocks.fairwinds.com/enabled: true 标签的命名空间,并为这些命名空间中的每个工作负载创建 VerticalpodautoScaler 对象
。
在这篇博客文章中,我们将创建一个名为
javajmx-sample
的命名空间, 并将创建 tomcat 部署。我们将给这个命名空间添加标签,以获得金发姑娘的推荐。一旦我们标记了命名空间,我们就能看到一个名为
goldil
ocks-tomcat-example 的 VPA 对象已创建。
先决条件
要完成本文中的步骤,您将需要以下内容:
-
亚马逊云科技 命令行接口 (亚马逊云科技 CLI) 版本 2 -
kubectl -
helm -
如果你没有 Amazon EKS 集群,你可以使用
eksc t l 创建一个集群
步骤 1:部署指标服务器
在此步骤中,我们将部署指标服务器,该服务器提供供垂直容器自动扩缩器使用的资源指标。
让我们验证指标服务器的状态。成功部署后,您应该能够在几秒钟内看到部署的资源利用率:
第 2 步:启用需要 Goldilocks 推荐资源的命名空间
我们将在
javajmx-s ample 命名空间中部署示例
工作负载,并将获得在其上运行的应用程序的资源建议。让我们继续创建命名空间并为其添加标签。
为确保成功应用标签,请在
javaj
mx-sample 命
名空间
上运行 describe
第 3 步:部署 Goldilocks
我们将使用掌舵图来部署金发姑娘。部署创建了三个对象:
- Goldilocks-Contro ll er:负责为命名空间已启用 Goldilocks 推荐的工作负载创建 VPA 对象
- GoldiLocks-VPA-推荐器: 负责为工作负载提供资源建议
- GoldiLocks-Das hboard :总结了工作负载的资源推荐,还将提供用于实施建议的 yaml 清单。
要部署 Goldilocks,请运行以下 helm 命令:
现在,我们将使用 kubectl 来验证部署是否成功:
步骤 4:部署示例应用程序
在此步骤中,我们将在 javajmx-sample 命名空间中部署示例应用程序,以获取 Goldilocks 的推荐。应用程序 tomcat 示例最初配置的 CPU 和内存请求分别为 100m 和 180Mi,CPU 和 300 Mi 内存的限制为 300 米。
如前所述,Goldilocks将在启用Goldilocks的命名空间中为每次部署创建VPA。使用
kubectl
命令,我们可以验证是否在
javajm
x-sample 命名空间中为 goldilocks-tomcat 示例创建了 VPA:
第 5 步:查看 Goldilocks 推荐控制面板
GoldiLocks-Dashboard 将在端口 8080 中显示仪表板,我们可以访问它来获取资源推荐。我们现在运行这个 kubectl 命令来访问仪表板:
我们现在可以在
让我们分析一下
javajmx-sample
命名空间,看看 Goldilocks 提供的建议。我们应该能够看到
goldiloc
ks-tomcat 示例部署的建议。
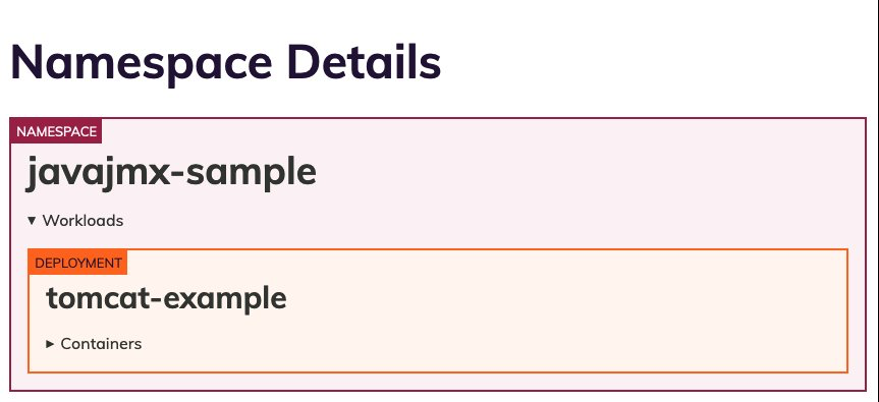
此处的屏幕显示了 javajmx 示例工作负载的请求和限制建议。 每个服务质量 (QoS) 下的 “当前 ” 列表示当前配置的 CPU 和内存请求和限制。 每个 QoS 下的 “ 保证 ” 和 “可突 发性 ” 列表示相应 QoS 的推荐的 CPU 和内存请求限制。

我们可以清楚地注意到,我们已经过度配置了资源,Goldilocks 提出了优化 CPU 和内存请求的建议。CPU 请求和 CPU 限制的推荐级别为 15m 和 15m,而当前的保证 QoS 设置为 100 米和 300 米。建议将内存请求和限制设置为105M和105M,而当前的设置为180Mi和300 Mi。
请注意,这些建议适用于两种不同的服务质量 (QoS) 类型:“保证” 和 “突发性”。Kubernetes 为 pod 提供不同级别的服务质量,具体取决于 Pod 的请求和为其设置的限制。需要保持正常运行状态的 Pod 可以请求有保障的资源,而要求不太严格的 Pod 可以在不保证或不保证的情况下使用资源。
保证 (QoS) p p od 被视为重中之重,保证在超过限制之前不会被杀死。如果为所有容器上的所有资源设置了限制和可选请求(不等于 0),并且限制和请求相等,则该 Pod 被归类为 “保证”。
Burstable (QoS) Pod 具有某种形式的最低资源保障,但在可用时可以使用更多资源。在系统内存压力下,这些容器在超出请求时更有可能被杀死,并且不存在 Best-Effort 容器。如果为一个或多个容器中的一个或多个资源设置了请求和可选限制(不等于 0),但两者不相等,则该 Pod 被归类为 Burstable。
要遵循推荐的资源规范,客户只需复制他们感兴趣的 QoS 类别的相应清单文件并部署工作负载,然后对其进行调整大小和优化。
例如,如果我们决定应用保障 QoS 的建议,我们可以从仪表板中复制 YAML,如下所示,并将其应用于部署对象:
让我们在部署中运行
kubectl edit
命令来应用建议:
容器规范中的资源部分显示,我们已经成功应用了 CPU 和内存的请求和限制建议:
应用建议后,我们应该能够验证 pod 是否正在尝试重启并使用更新的资源配置上线。让我们在 tomcat 示例部署中运行 kubectl describe 命令来验证同样的情况:
输出应如下所示:
清理
要删除我们在博客中创建的部署和示例工作负载,请执行以下命令:
结论
这篇文章演示了如何使用 Goldilocks 来有效地调整 Kubernetes 应用程序的资源请求大小。参与现代化工作的客户通常只有很少的时间来决定其应用程序的资源需求,这通常涉及审查监控仪表板的复杂过程。通过采纳 Goldilocks 的建议,客户可以缩短其应用程序的上市时间并优化 Amazon EKS 成本。
进一步阅读
-
EKS 最佳实践 -
博客:
使用 Prometheus 在 Kubernetes CPU 限制下避免灾难 -
Goldilocks 项目
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。