我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用更新的数据集在 Amazon SageMaker Canvas 中重新训练机器学习模型并自动进行批量预测
现在,您可以使用 Am
训练模型后,您可能需要对其进行预测。在 ML 模型上运行批量预测可以同时处理多个数据点,而不是一个接一个地进行预测。自动化此过程可提高效率、可扩展性和及时的决策。生成预测后,可以对其进行进一步分析、汇总或可视化,以获得见解、识别模式或根据预测结果做出明智的决策。Canvas 现在支持设置自动批量预测配置并将数据集与之关联。手动或按计划刷新关联数据集时,将在相应模型上自动触发批量预测工作流程。预测结果可以在线查看或下载以供日后查看。
在这篇文章中,我们展示了如何使用 Canvas 中更新的数据集重新训练机器学习模型并自动进行批量预测。
解决方案概述
在我们的用例中,我们扮演一家电子商务公司的业务分析师的角色。我们的产品团队希望我们确定影响购物者购买决定的最关键指标。为此,我们使用公司的客户网站在线会话数据集在Canvas中训练机器学习模型。我们会评估模型的性能,并在需要时使用其他数据对模型进行重新训练,以查看它是否提高了现有模型的性能。为此,我们使用了 Canvas 中的自动更新数据集功能,并使用最新版本的训练数据集重新训练我们现有的 ML 模型。然后,我们配置自动批量预测工作流程——更新相应的预测数据集时,它会自动触发模型上的批量预测作业,并将结果提供给我们查看。
工作流程步骤如下:
-
将下载的客户网站在线会话数据上传到
Amazon Simple Storage Servic e (Amazon S3),然后创建新的训练数据集 Canvas。有关支持数据源的完整列表,请参阅在亚马逊 SageMaker Canvas 中 导入数据 。 -
构建 ML 模型并分析其绩效指标。请参阅有关如何在 C
anvas 中 构建自定义 ML 模型 并评估模型性能的 步骤 。 - 设置现有训练数据集的自动更新,并将新数据上传到支持该数据集的 Amazon S3 位置。完成后,它应该创建一个新的数据集版本。
- 使用数据集的最新版本重新训练 ML 模型并分析其性能。
-
在性能更好的模型版本 上设置
自动批量预测 并查看预测结果。
您无需编写任何代码即可在 Canvas 中执行这些步骤。
数据概述
该数据集由属于 12,330 个会话的特征向量组成。数据集的形成使得每个会话在 1 年内属于不同的用户,以避免出现任何特定活动、特殊日子、用户个人资料或时段的趋势。下表概述了数据架构。
| Column Name | Data Type | Description |
Administrative
|
Numeric | Number of pages visited by the user for user account management-related activities. |
Administrative_Duration
|
Numeric | Amount of time spent in this category of pages. |
Informational
|
Numeric | Number of pages of this type (informational) that the user visited. |
Informational_Duration
|
Numeric | Amount of time spent in this category of pages. |
ProductRelated
|
Numeric | Number of pages of this type (product related) that the user visited. |
ProductRelated_Duration
|
Numeric | Amount of time spent in this category of pages. |
BounceRates
|
Numeric | Percentage of visitors who enter the website through that page and exit without triggering any additional tasks. |
ExitRates
|
Numeric | Average exit rate of the pages visited by the user. This is the percentage of people who left your site from that page. |
Page Values
|
Numeric | Average page value of the pages visited by the user. This is the average value for a page that a user visited before landing on the goal page or completing an ecommerce transaction (or both). |
SpecialDay
|
Binary | The “Special Day” feature indicates the closeness of the site visiting time to a specific special day (such as Mother’s Day or Valentine’s Day) in which the sessions are more likely to be finalized with a transaction. |
Month
|
Categorical | Month of the visit. |
OperatingSystems
|
Categorical | Operating systems of the visitor. |
Browser
|
Categorical | Browser used by the user. |
Region
|
Categorical | Geographic region from which the session has been started by the visitor. |
TrafficType
|
Categorical | Traffic source through which user has entered the website. |
VisitorType
|
Categorical | Whether the customer is a new user, returning user, or other. |
Weekend
|
Binary | If the customer visited the website on the weekend. |
Revenue
|
Binary | If a purchase was made. |
收入是目标列,这将帮助我们预测购物者是否会购买产品。
第一步是
先决条件
在本演练中,请完成以下必备步骤:
- 将下载的包含 20,000 行的 CSV 拆分为多个较小的区块文件。
这样我们就可以展示数据集更新功能。确保所有 CSV 文件具有相同的标题,否则在 Canvas 中创建训练数据集时可能会遇到架构不匹配错误。

-
创建 S3 存储桶并
将 online_shoppers_intentions1-3.csv上传 到 S3 存储桶。
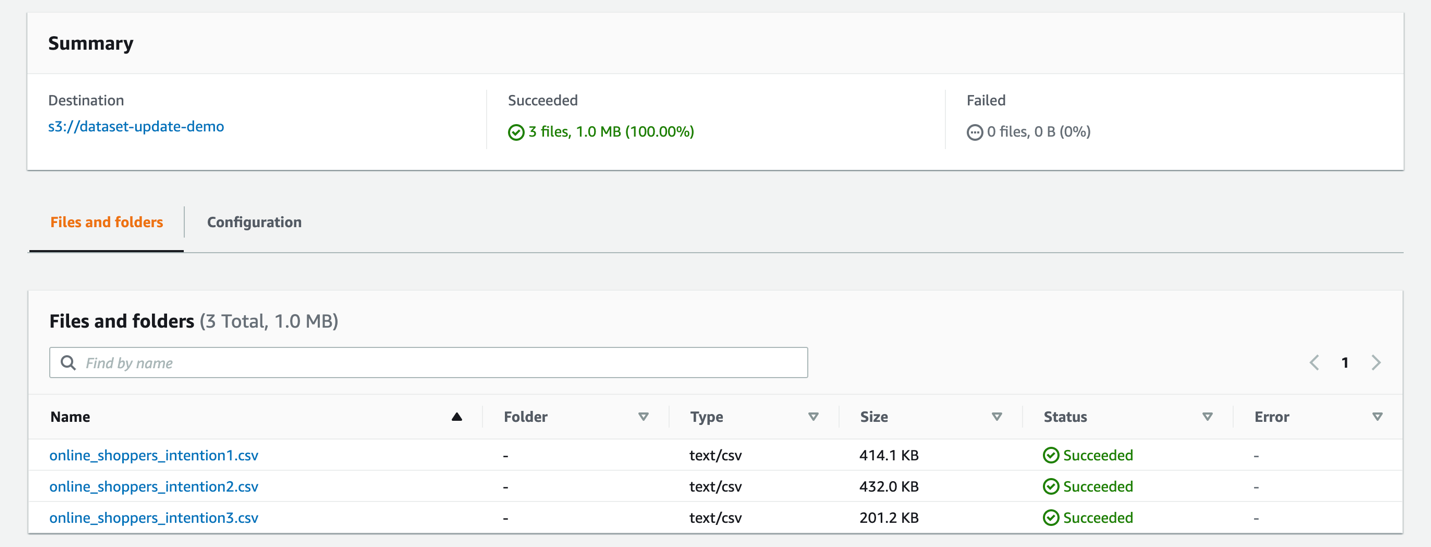
- 在训练机器学习模型后,从下载的 CSV 中预留 1,500 行进行批量预测。
-
从这些文件中移除 “
收入” 列,这样,当您对 ML 模型进行批量预测时,这就是您的模型将预测的价值。
确保所有 pred
ict*.csv
文件具有相同的标题,否则在 Canvas 中创建预测(推断)数据集时可能会遇到架构不匹配错误。

-
执行必要的步骤来
设置 SageMaker 域名和 Canv as 应用程序。
创建数据集
要在 Canvas 中创建数据集,请完成以下步骤:
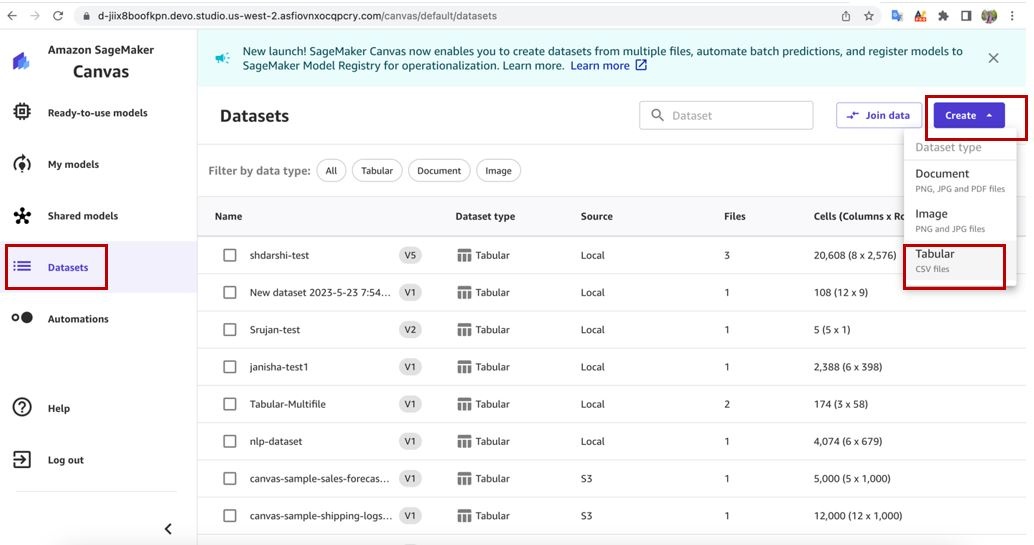
- 在 Canvas 中, 在导航窗格中选择 数据集 。
-
选择 “
创建
” ,然后选择 “
表格”。
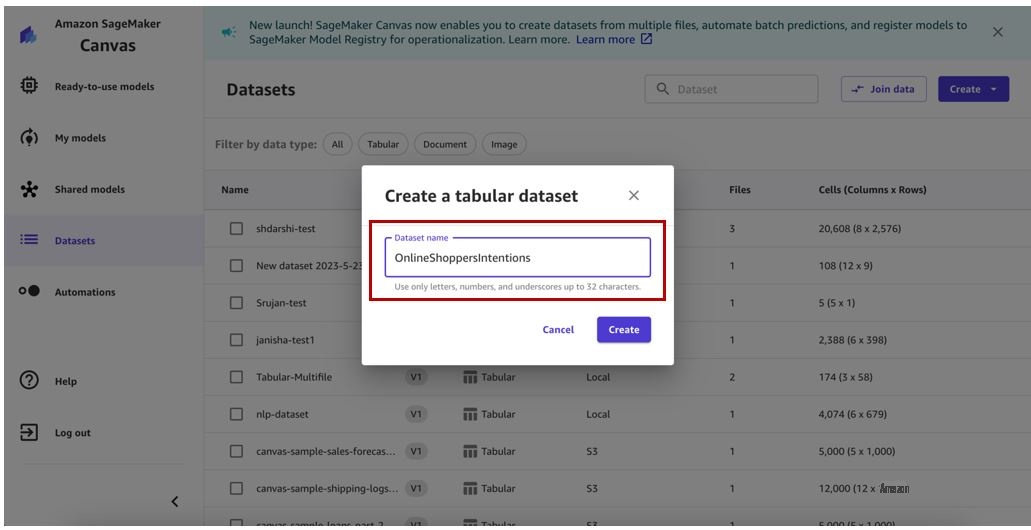
-
为您的数据集命名。在这篇文章中,我们将训练数据集命名为 O
nlineShopperIntent。 -
选择 “
创建
” 。
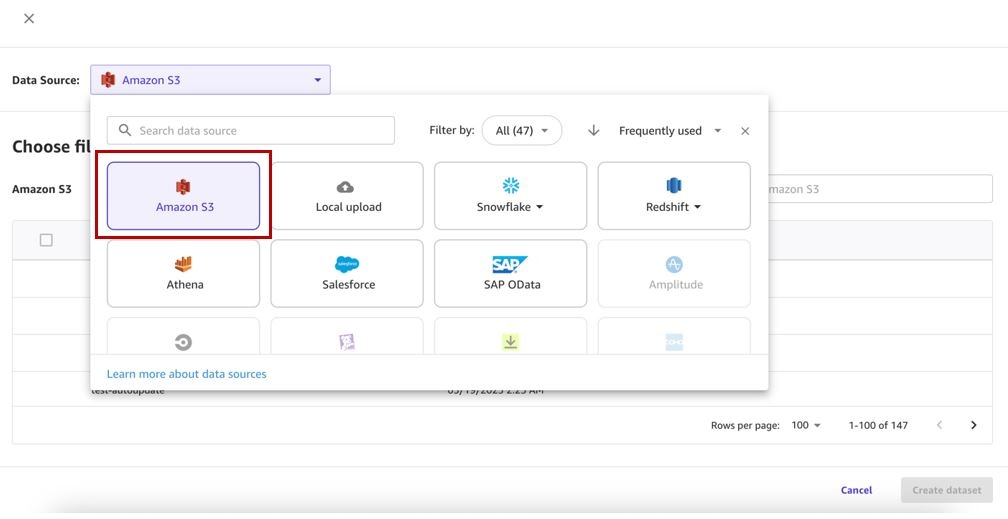
- 选择您的数据源(对于这篇文章,我们的数据源是 Amazon S3)。
请注意,在撰写本文时,数据集更新功能仅支持 Amazon S3 和本地上传的数据源。
- 选择相应的存储桶并上传数据集的 CSV 文件。
现在,您可以创建包含多个文件的数据集。
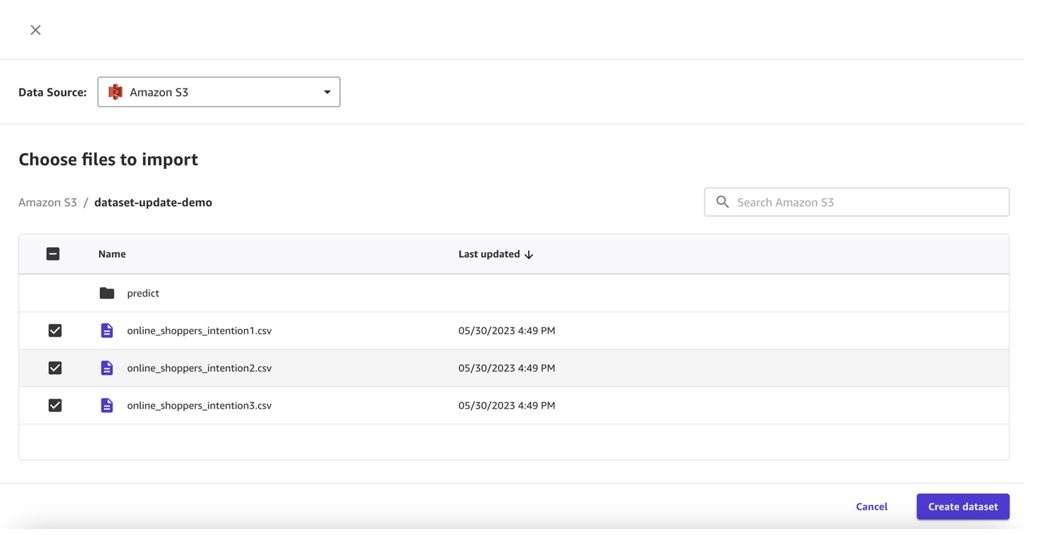
- 预览数据集中的所有文件,然后选择 创建数据集 。
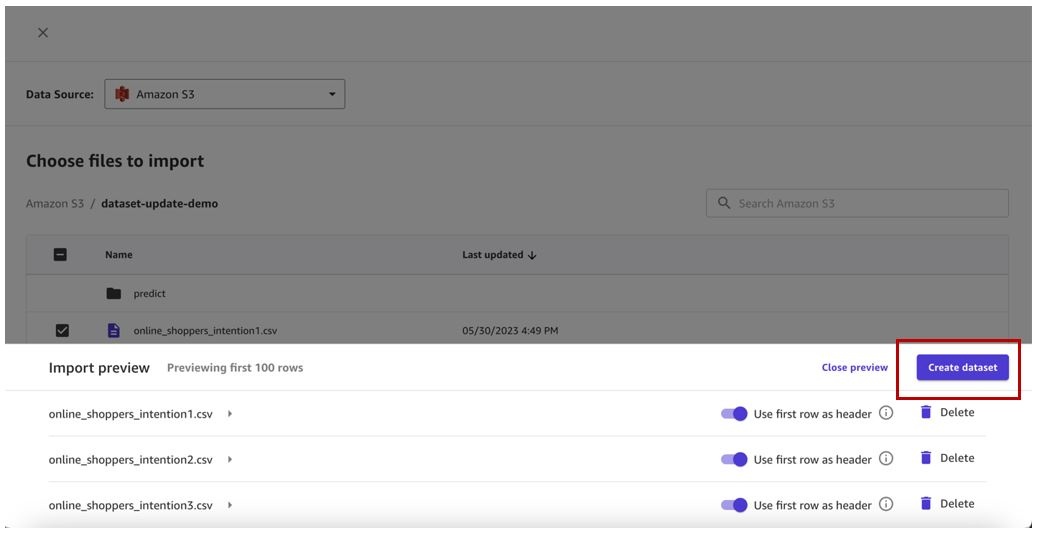
我们现在有了 O
nlineShopperSIntents 数据集的第 1 版,其中创建
了三个文件。
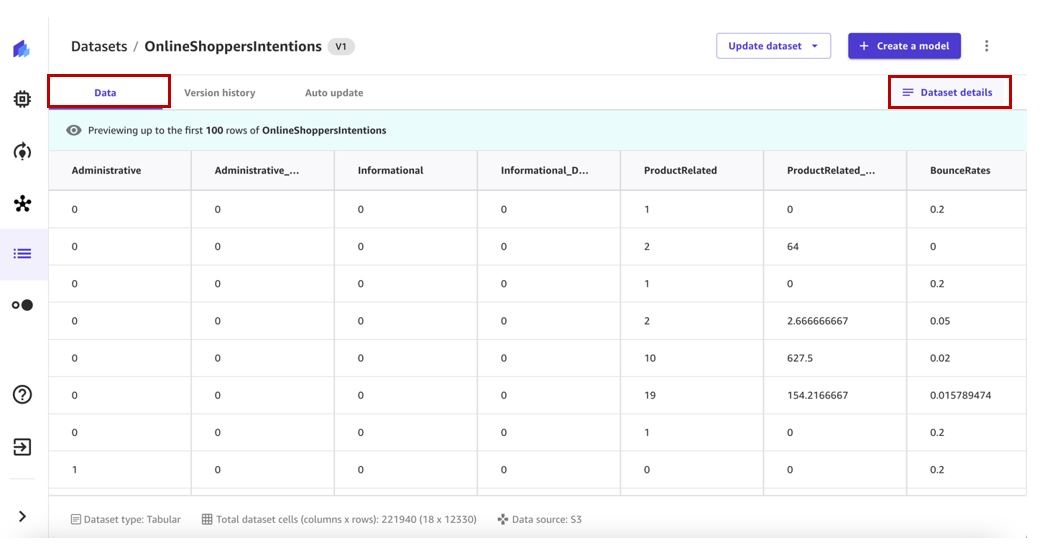
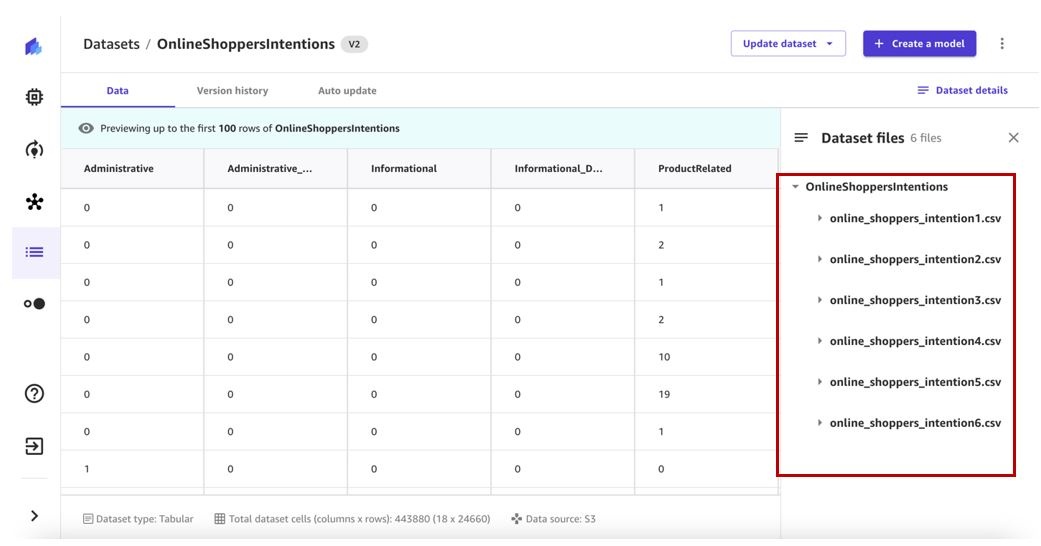
- 选择数据集以查看详细信息。

数据 选项卡显示数据集的预览。
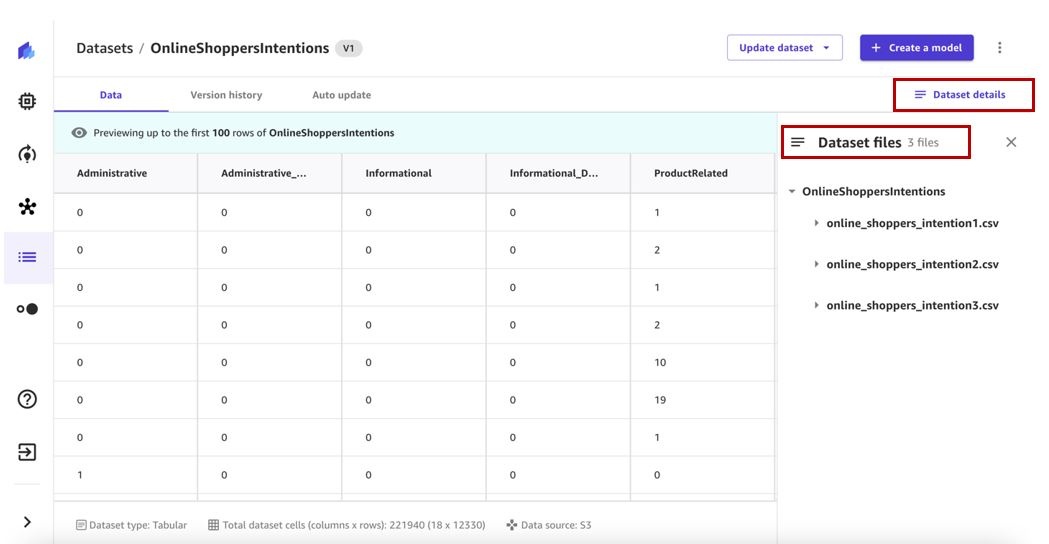
- 选择 数据集详细信息 以查看数据集包含的文件。
数据集文件 窗格列出了可用文件。
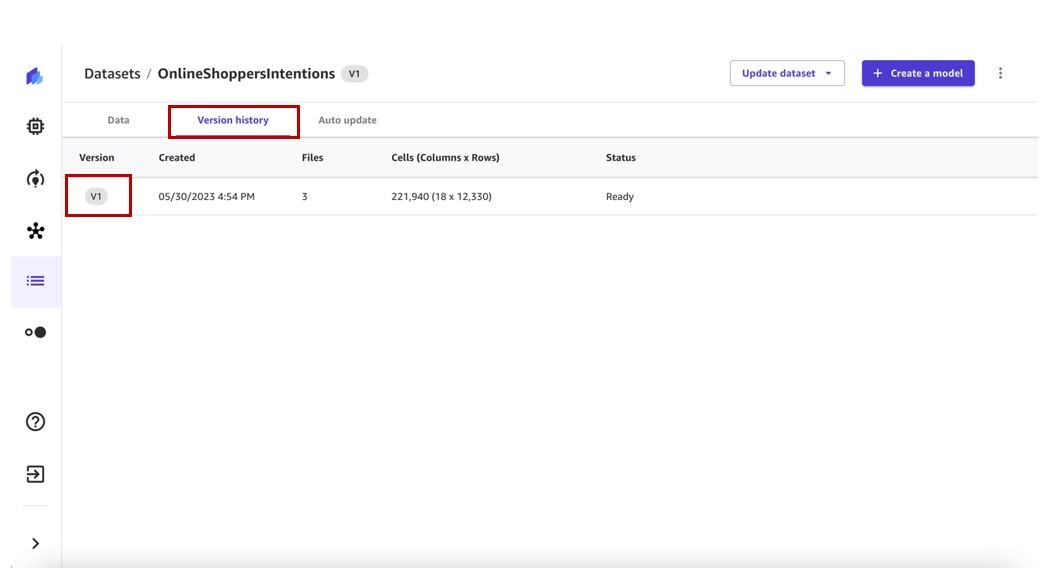
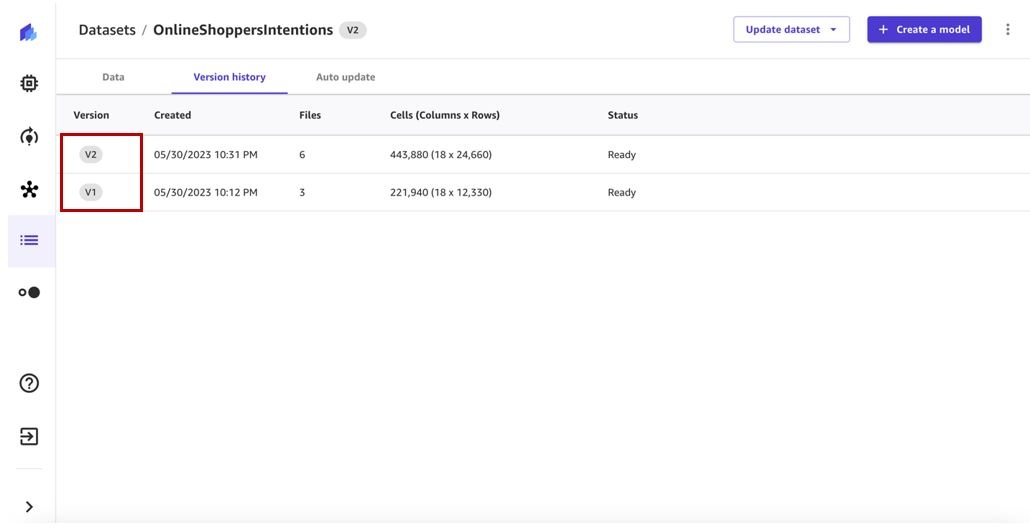
- 选择 “ 版本历史记录 ” 选项卡以查看该数据集的所有版本。
我们可以看到我们的第一个数据集版本有三个文件。任何后续版本都将包含先前版本的所有文件,并将提供数据的累积视图。
使用数据集的版本 1 训练 ML 模型
让我们使用数据集的版本 1 训练 ML 模型。
- 在 Canvas 中, 在导航窗格中选择 我的模型 。
- 选择 新模型 。
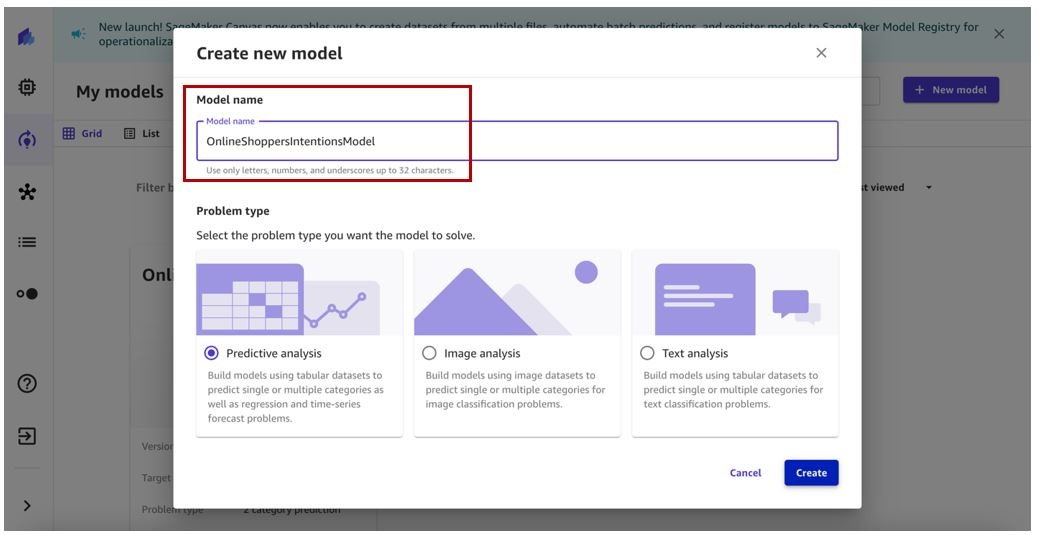
-
输入模型名称(例如,On
lineShopperIntentionsModel),选择问题类型,然后选择创建。
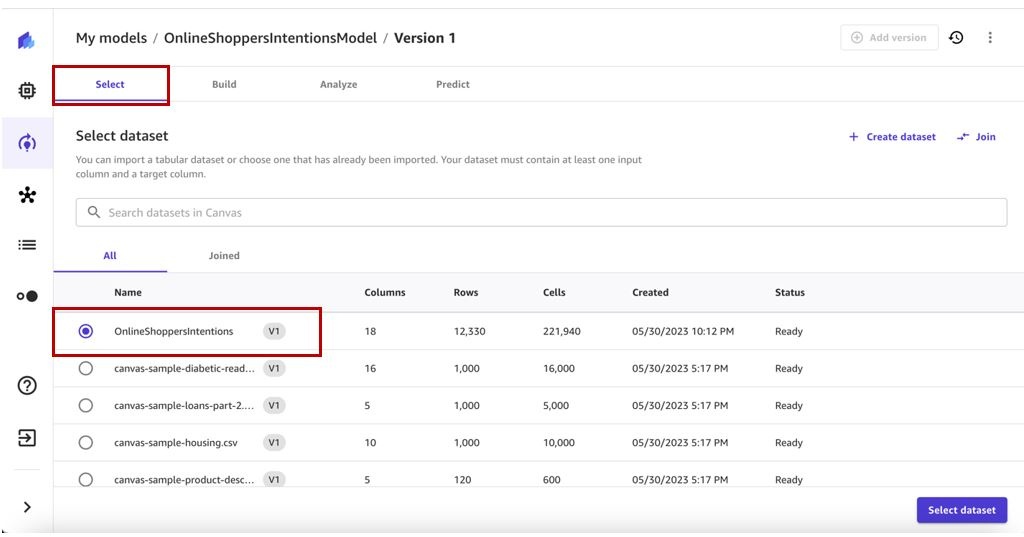
-
选择数据集。在这篇文章中,我们选择了 O
nlineShopperIntent 数据集。
默认情况下,Canvas 将选择最新的数据集版本进行训练。
- 在 “ 构建 ” 选项卡上,选择要预测的目标列。对于这篇文章,我们选择收入列。
- 选择 “ 快速构建 ” 。
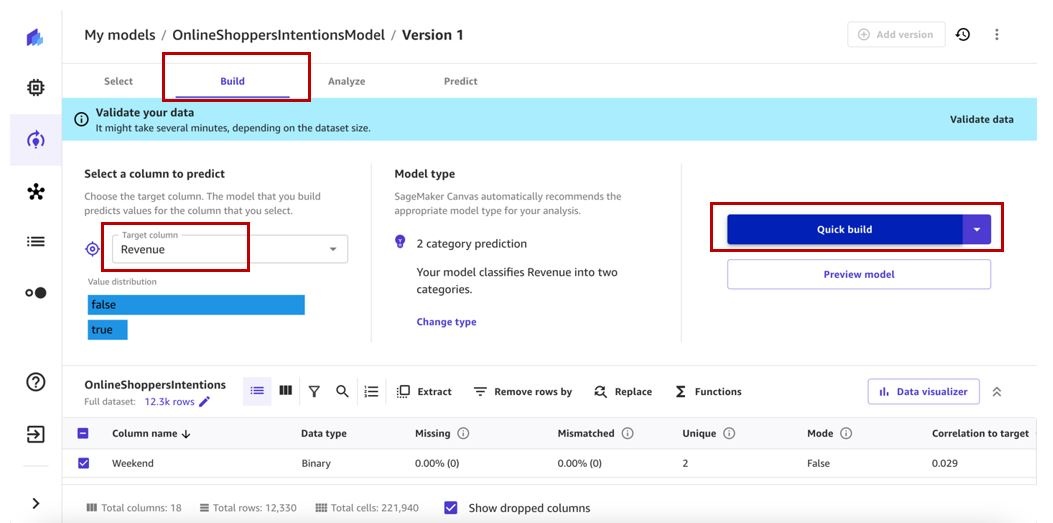
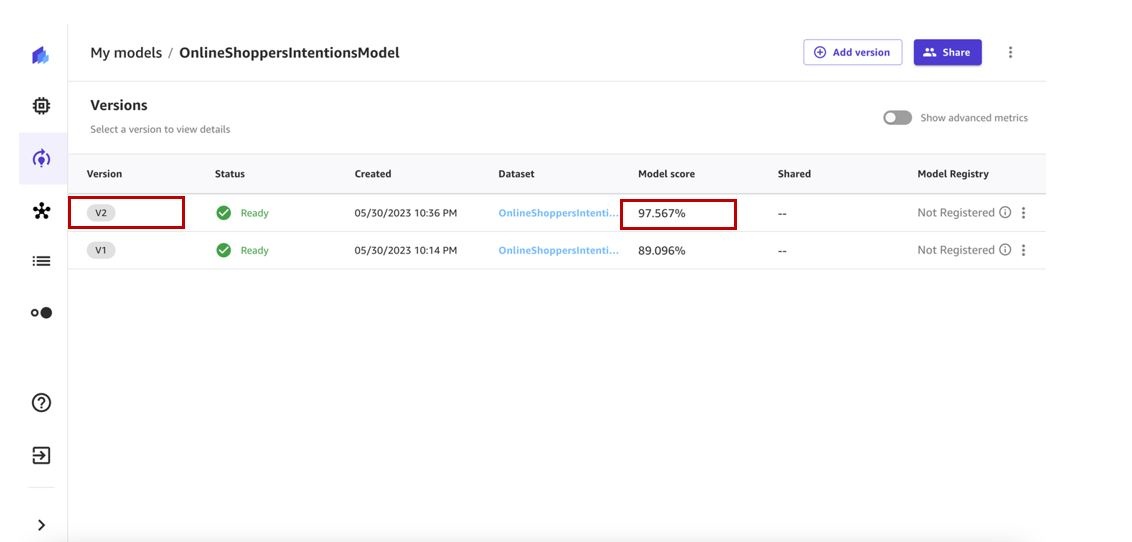
模型训练需要 2-5 分钟才能完成。就我们而言,经过训练的模型给我们的分数为89%。
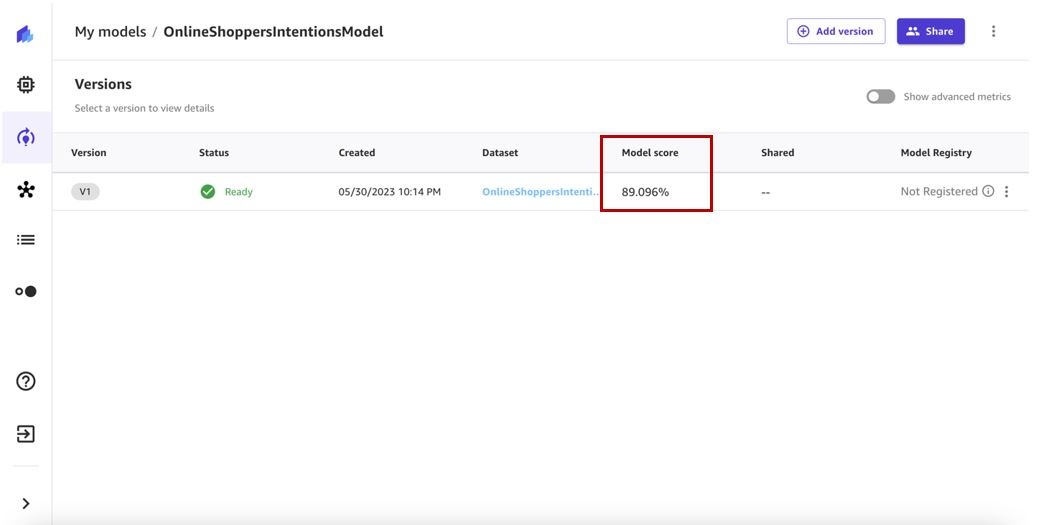
设置自动更新数据集
让我们使用自动更新功能更新我们的数据集并引入更多数据,看看模型性能是否随着数据集的新版本而得到改善。也可以手动更新数据集。
-
在
数据集
页面上,选择
OnlineShopperSIntents 数据集并选择更新数据集。 - 您可以选择 手动更新 (这是一次性更新选项),也可以选择 自动更新 (允许您按计划自动更新数据集)。在这篇文章中,我们展示了自动更新功能。
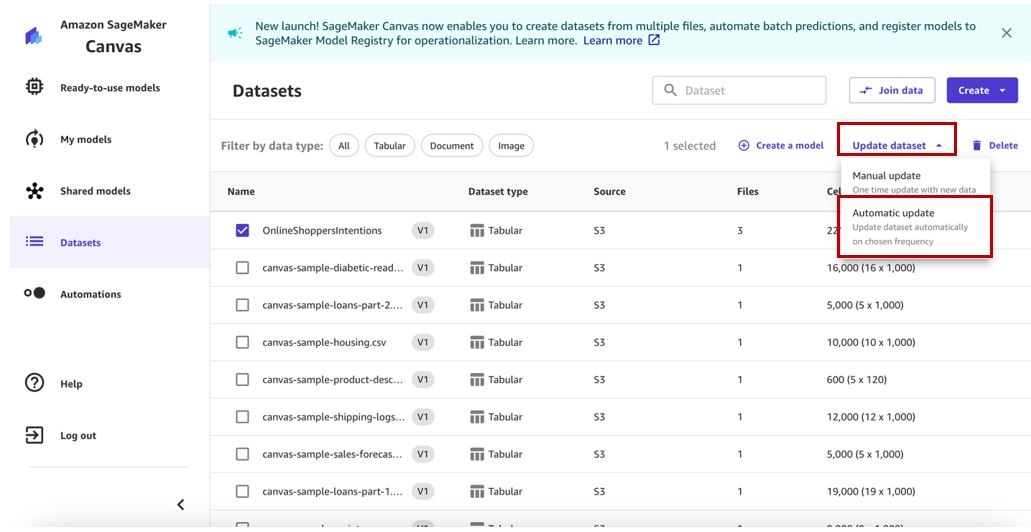
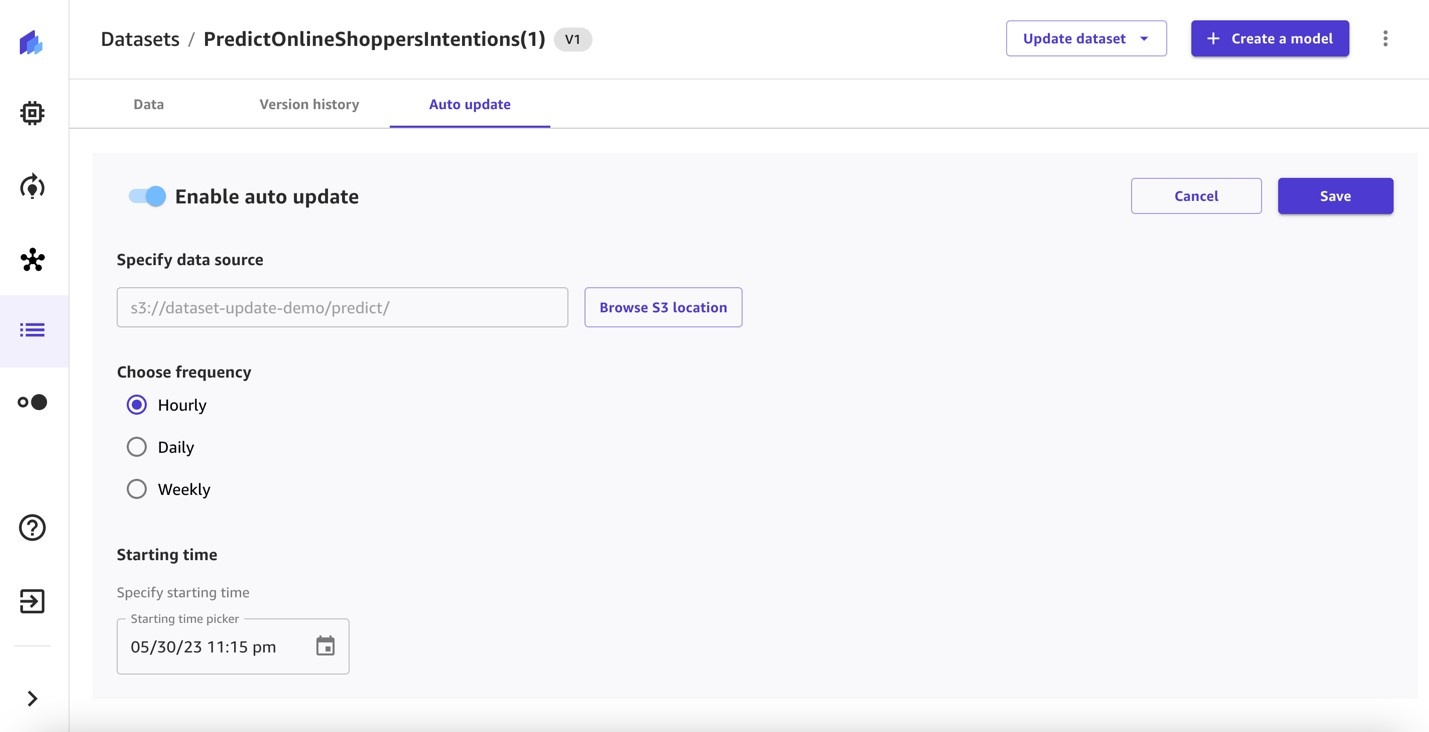
您将被重定向到相应数据集的 自动更新 选项卡。我们可以看到 “ 启用自动更新” 当前 已禁用。
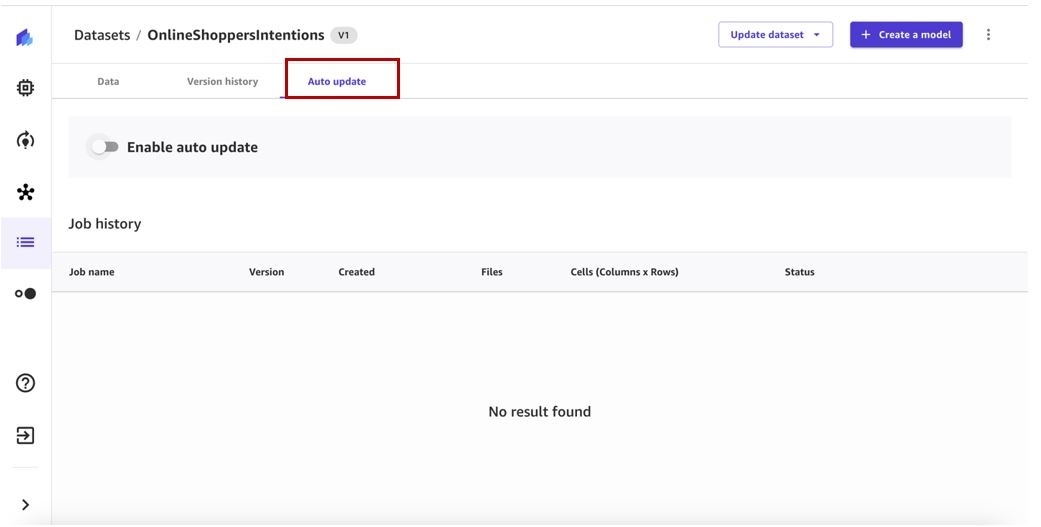
- 将 “ 启用自动更新 ” 切换 为开启并指定数据源(截至撰写本文时,支持 Amazon S3 数据源进行自动更新)。
- 选择频率并输入开始时间。
- 保存配置设置。
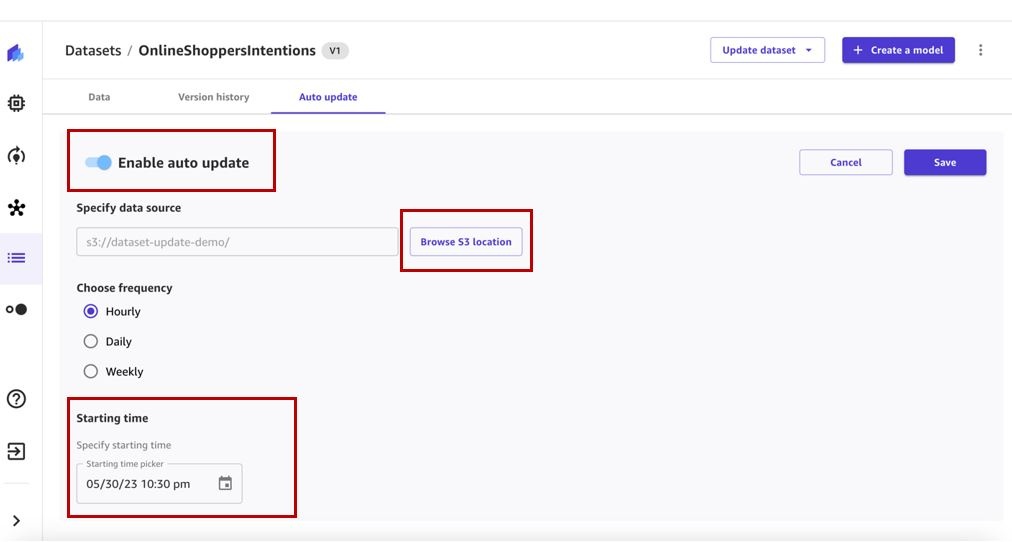
已创建自动更新数据集配置。可以随时对其进行编辑。当按指定的时间表触发相应的数据集更新作业时,该作业将出现在 作业历史记录 部分。
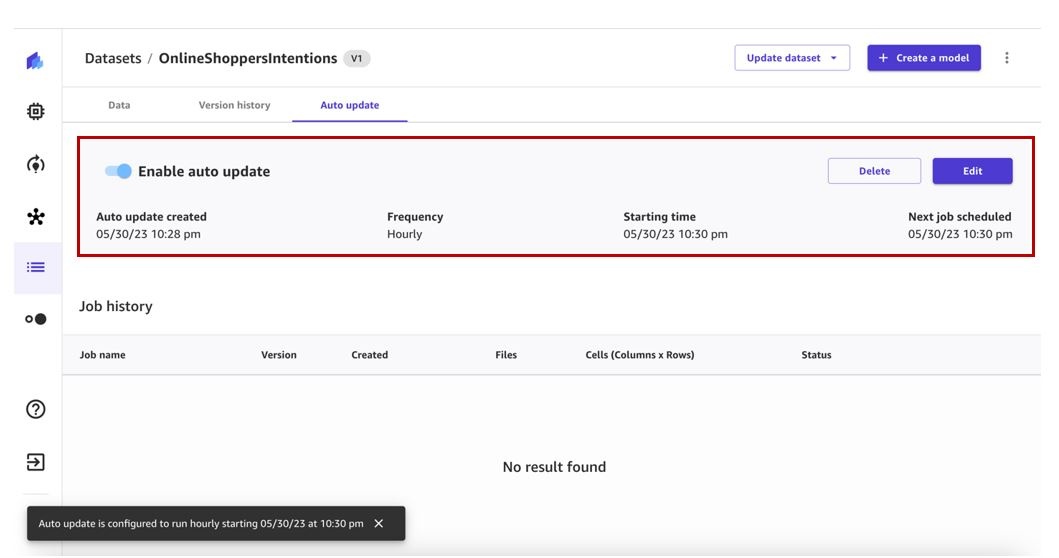
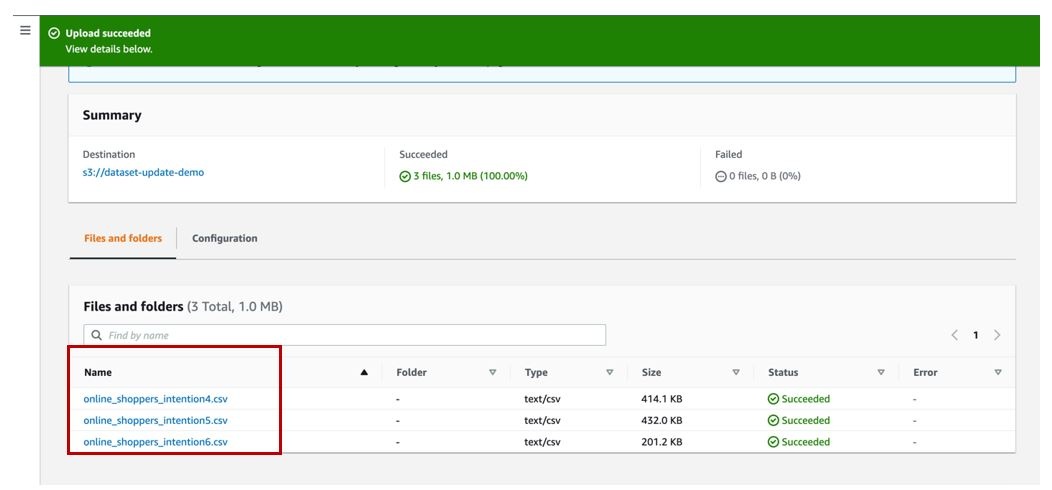
-
接下来,让我们将
online_shoppers_intentions4.csv、online_shoppers_intentions5.csv 和online_shoppers_intentions6.csv文件上传到我们的 S3 存储桶。
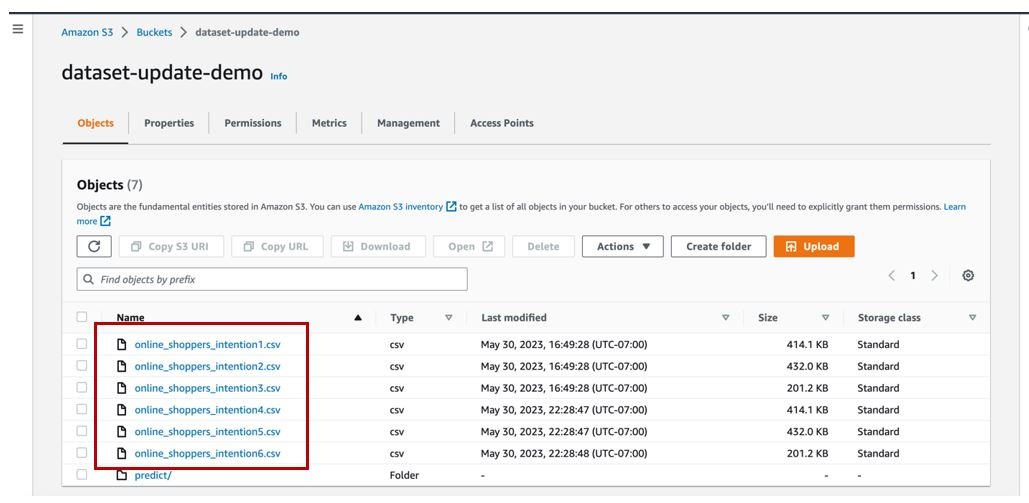
我们可以在
数据集更新演示 S3 存储桶
中查看我们的文件。
数据集更新作业将按指定的时间表触发并创建数据集的新版本。
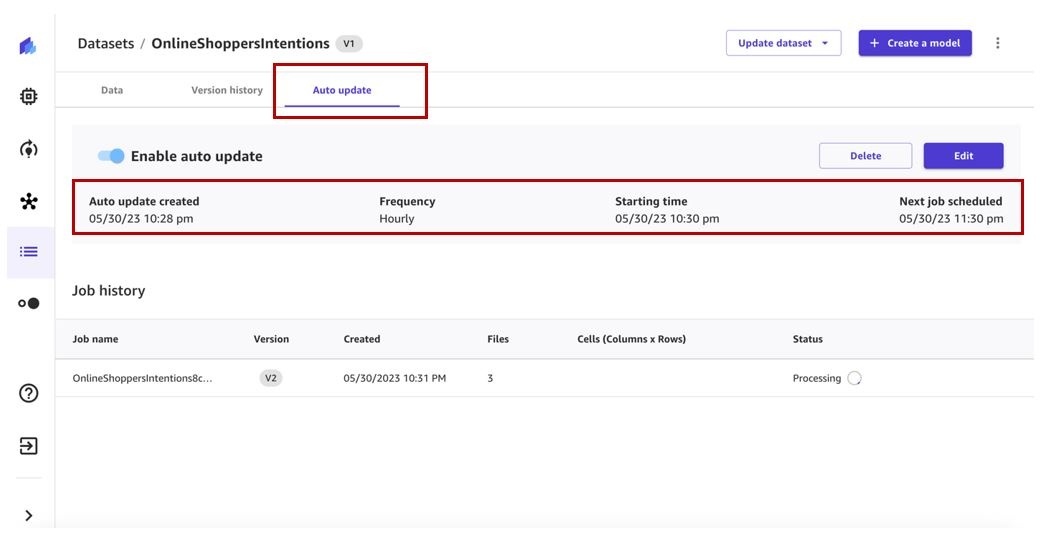
作业完成后,数据集版本 2 将包含版本 1 中的所有文件以及数据集更新作业处理的其他文件。在我们的例子中,版本 1 有三个文件,更新任务额外获取了三个文件,因此最终的数据集版本有六个文件。
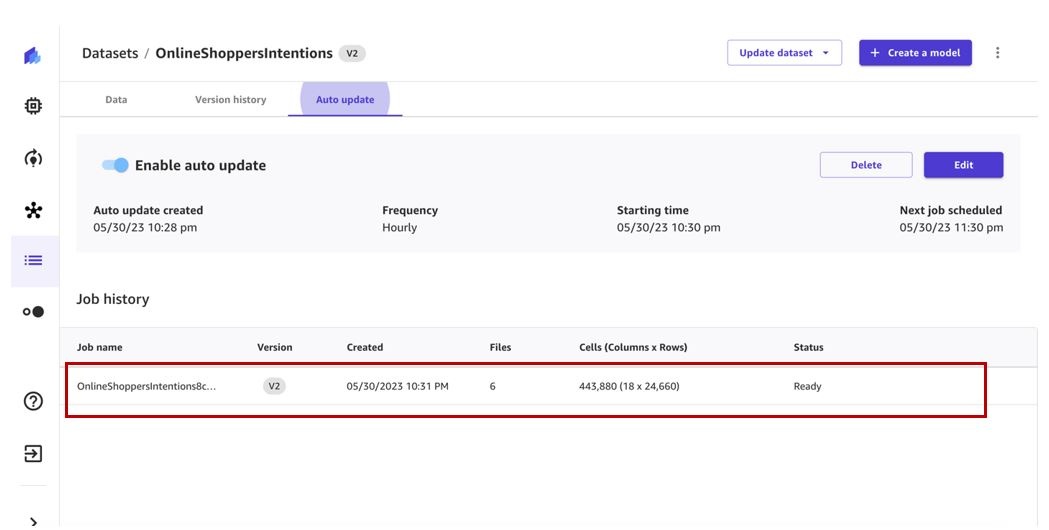
我们可以查看在 “版本 历史记录 ” 选项卡上创建的新 版本 。
数据 选项卡包含数据集的预览,并提供最新版本数据集中所有文件的列表。
使用更新的数据集重新训练 ML 模型
让我们使用最新版本的数据集重新训练我们的 ML 模型。
- 在 我的模特 页面上,选择您的模型。
-
选择 “
添加版本
” 。
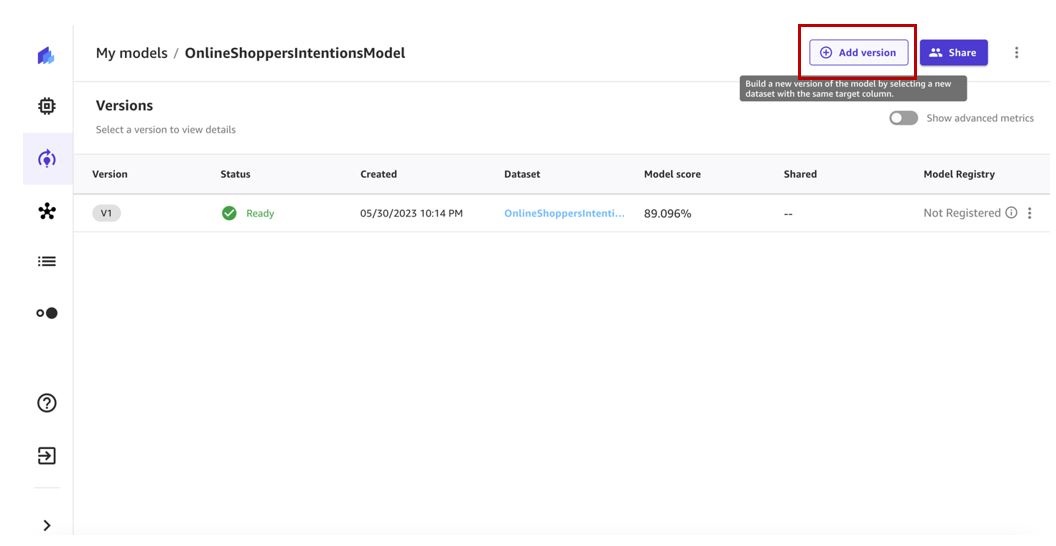
-
选择最新的数据集版本(在本例中为 v2),
然后选择选择数据集
。
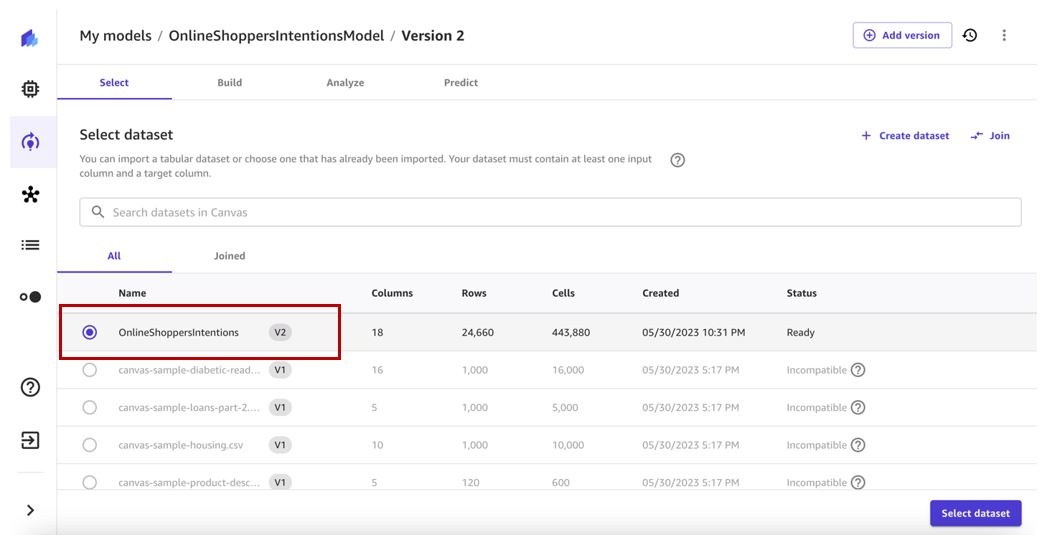
-
保留与先前模型版本相似的目标列和编译配置。
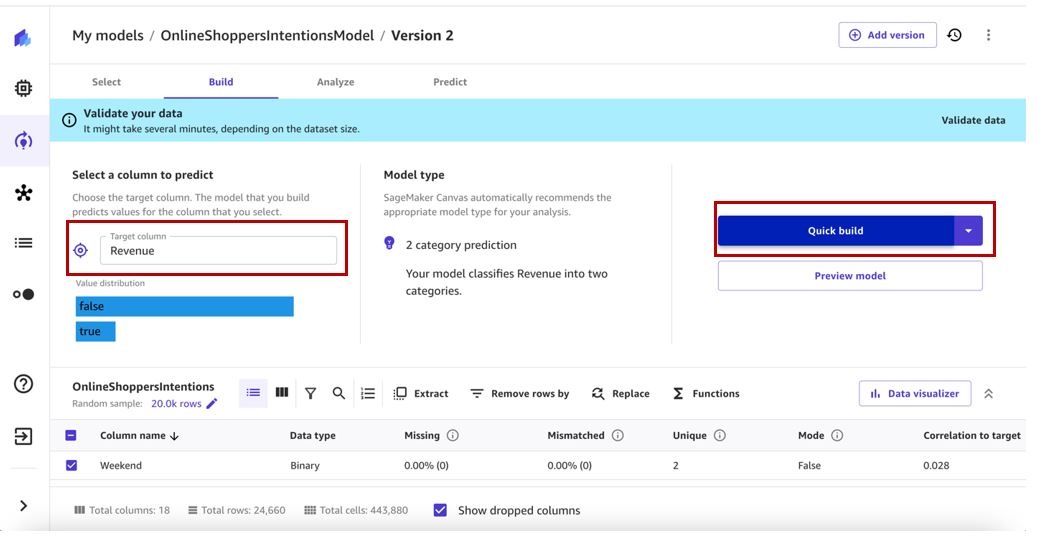
训练完成后,让我们评估模型性能。以下屏幕截图显示,添加其他数据和重新训练我们的 ML 模型有助于提高模型性能。
创建预测数据集
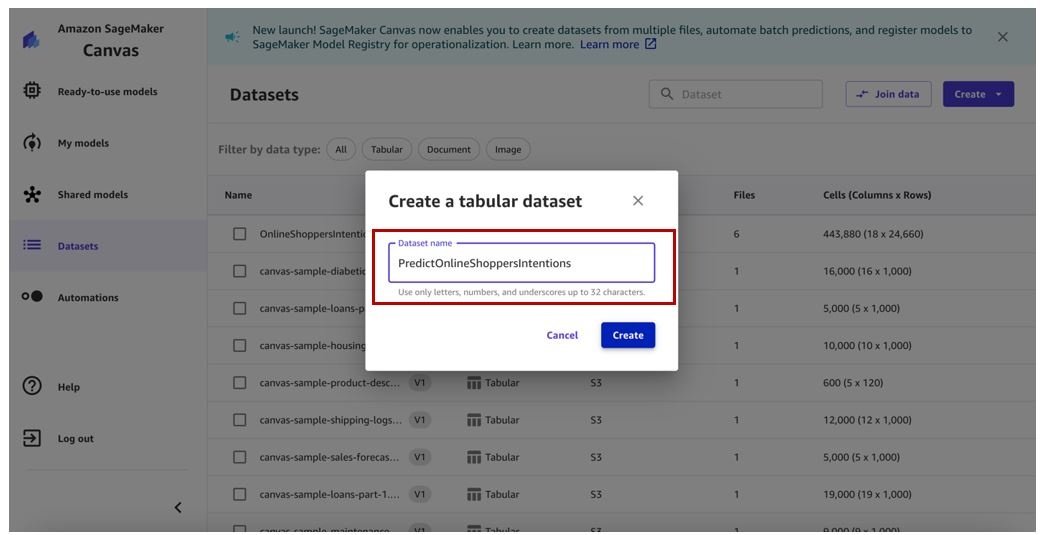
训练好机器学习模型后,让我们创建一个用于预测的数据集并对其进行批量预测。
- 在 数据集 页面上,创建表格数据集。
-
输入名称并选择 “
创建
” 。
-
在我们的 S3 存储桶中,上传一个包含 500 行的文件进行预测。
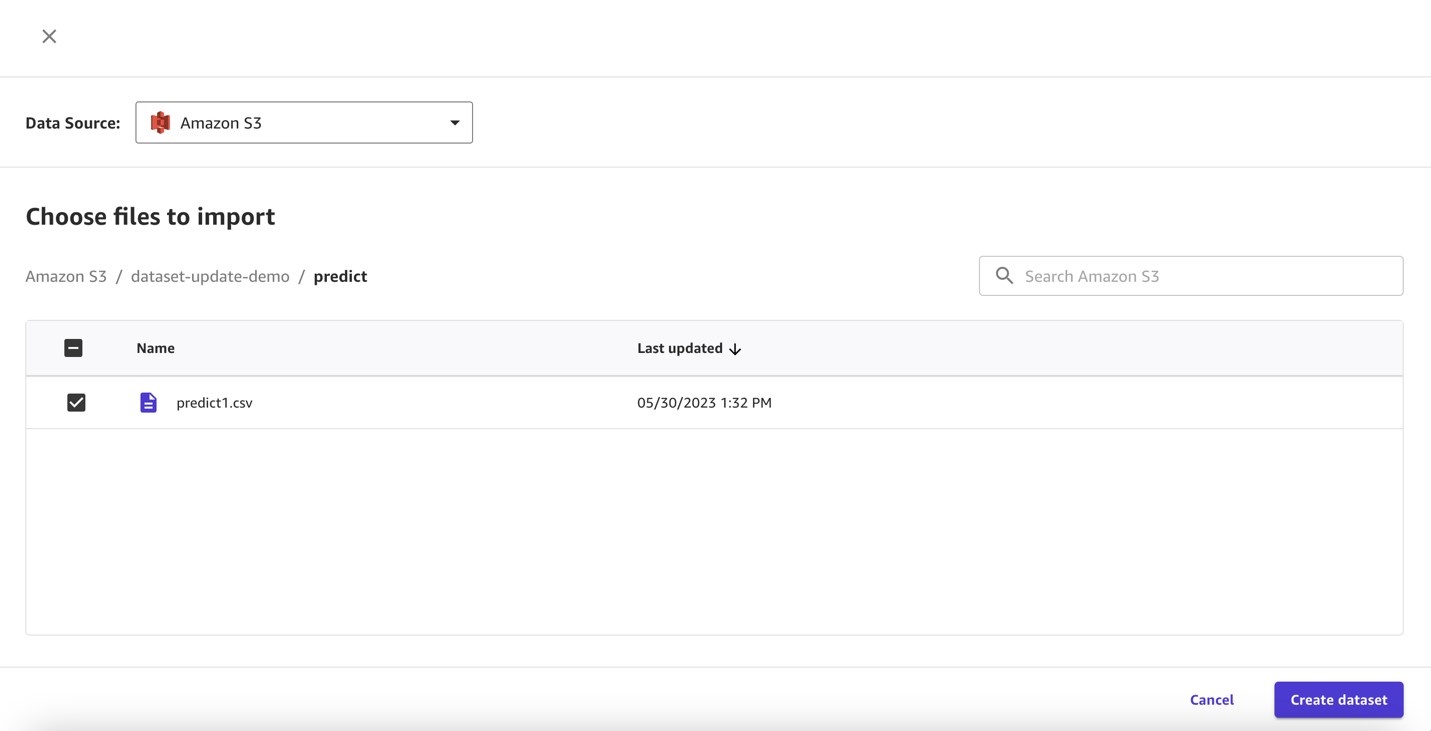
接下来,我们在预测数据集上设置自动更新。
- 将 “ 启用自动更新” 切换 为开启并指定数据源。
- 选择频率并指定开始时间。
-
保存配置。
在自动更新的预测数据集上自动执行批量预测工作流程
在此步骤中,我们配置了自动批量预测工作流程。
- 在 我的模型 页面上,导航到模型的版本 2。
-
在 “
预测
” 选项卡上,选择 “
批量预测
” 和 “
自动
” 。
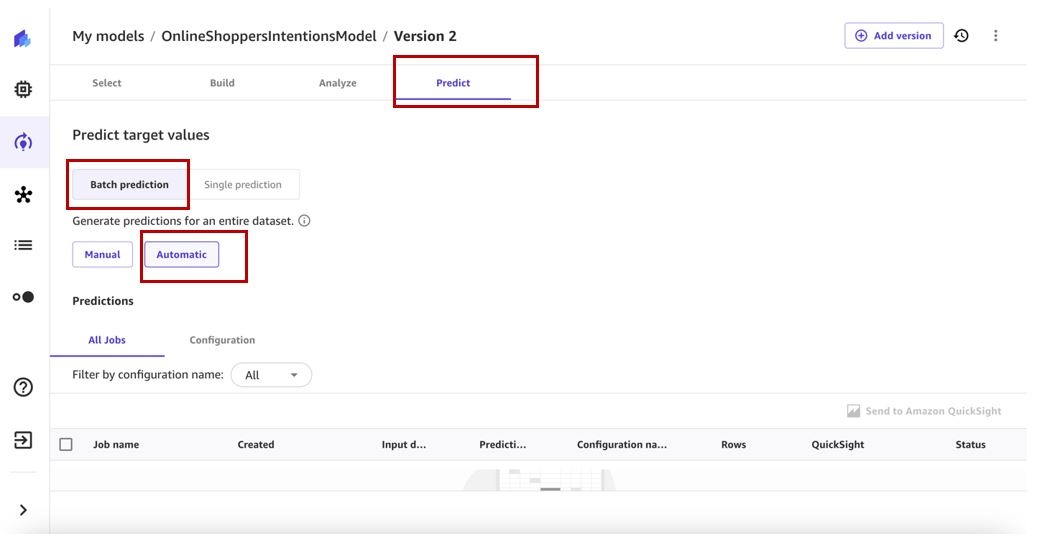
-
选择
选择数据集
以指定要生成预测的数据集。
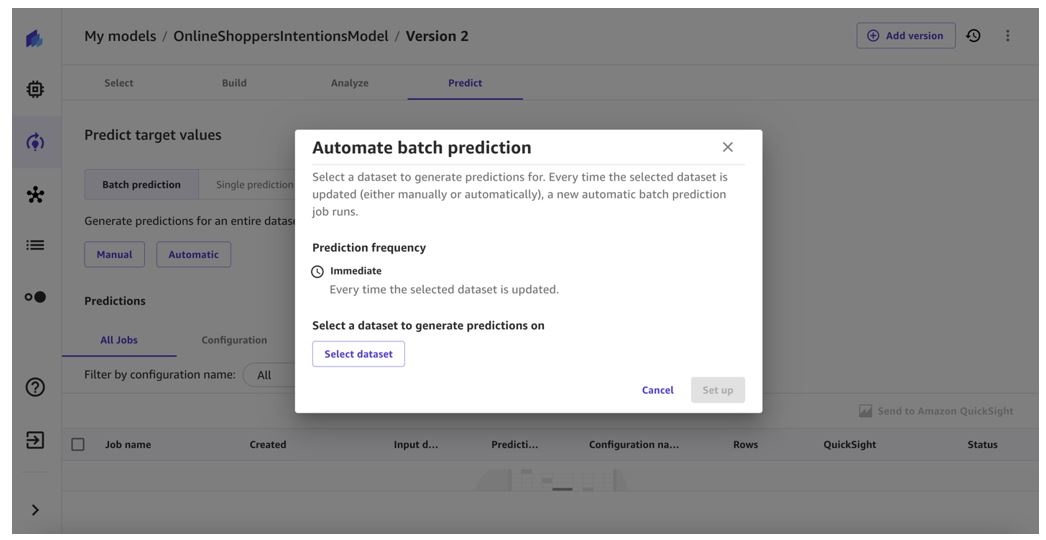
-
选择我们之前创建的
预测数据集,然后选择 选择数据集 。
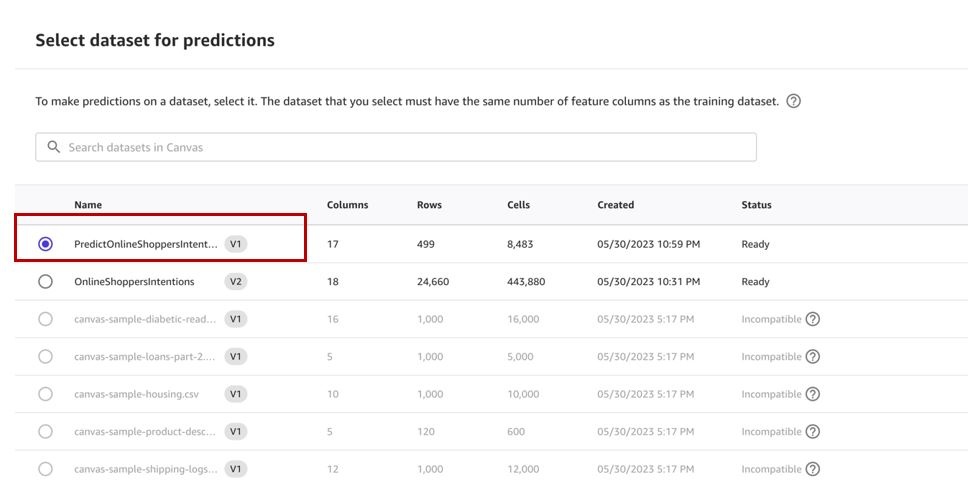
-
选择 “
设置
” 。
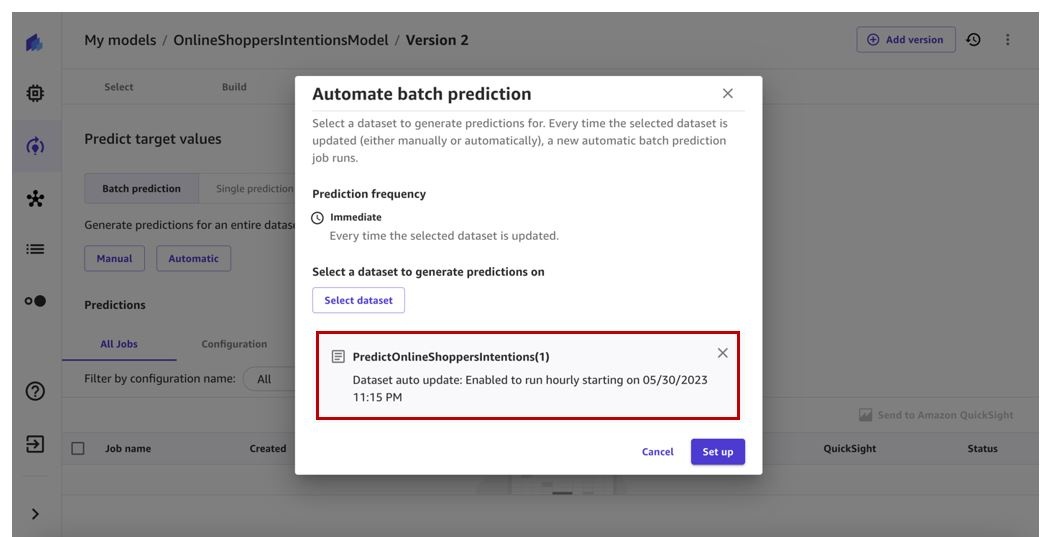
我们现在有了自动批量预测工作流程。这将在 Predict 数据
集
自动更新时触发。

现在,让我们将更多 CSV 文件上传到
预测
S3 文件夹。
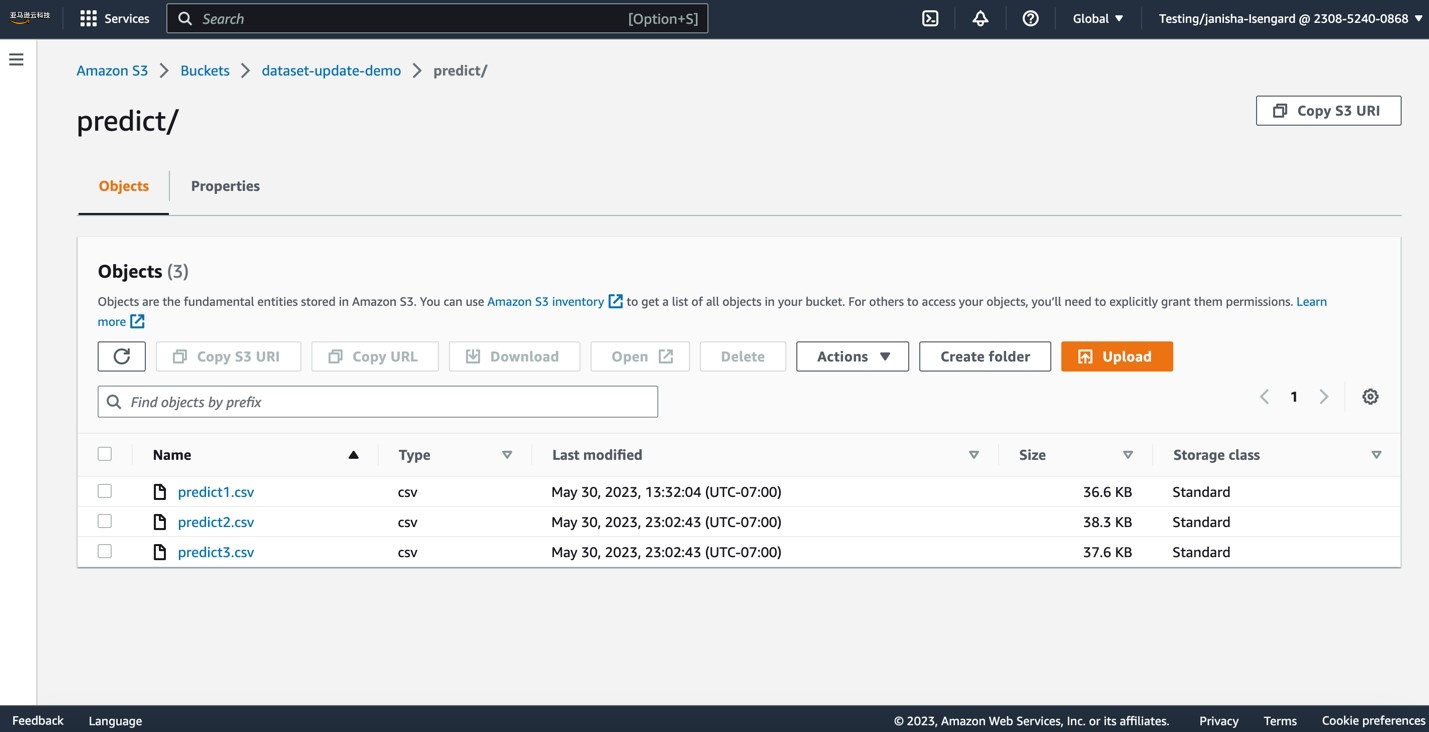
此操作将触发
预测
数据集的自动更新。
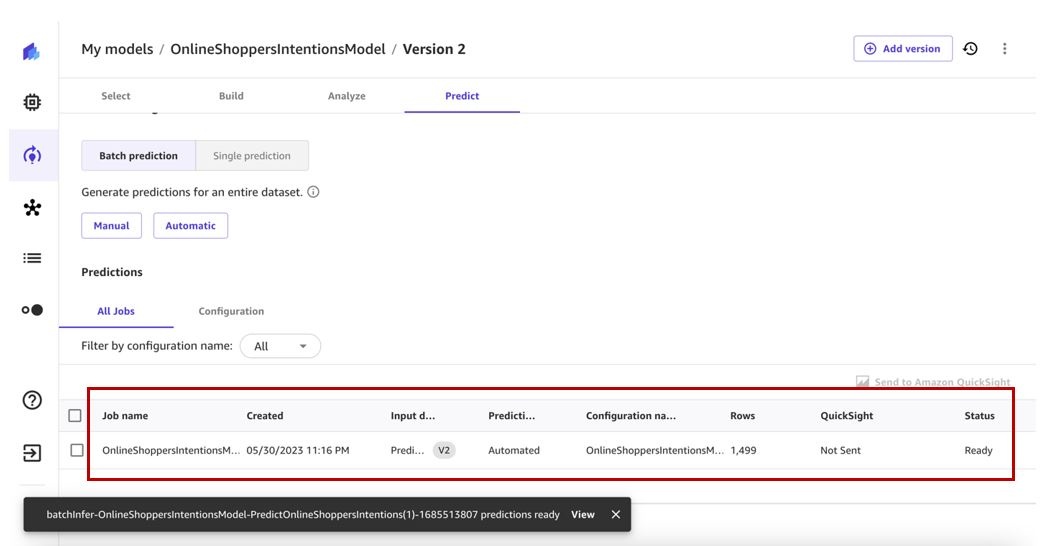
这反过来将触发自动批量预测工作流程,并生成预测供我们查看。
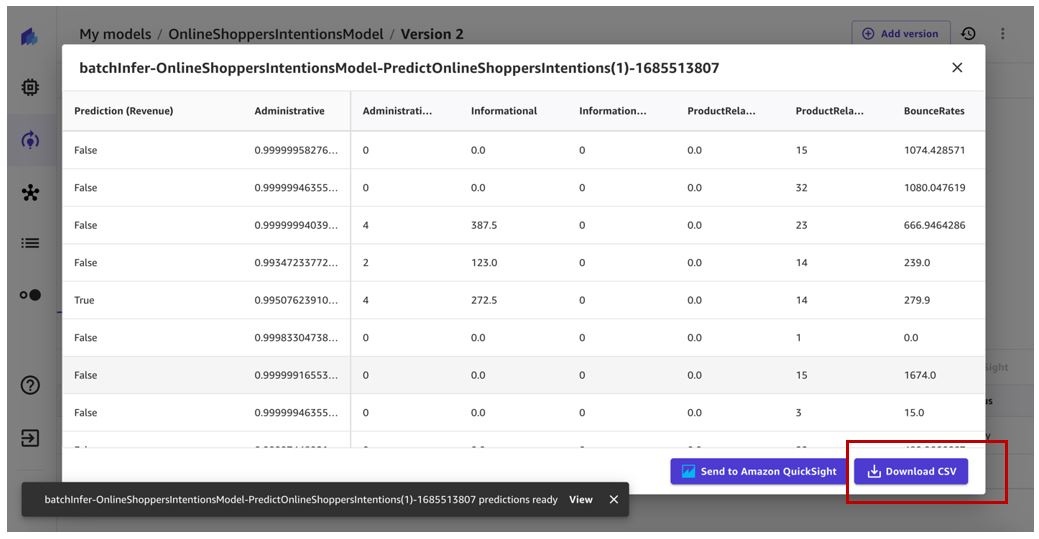
我们可以在 “自动化” 页面上查看所有 自动化。
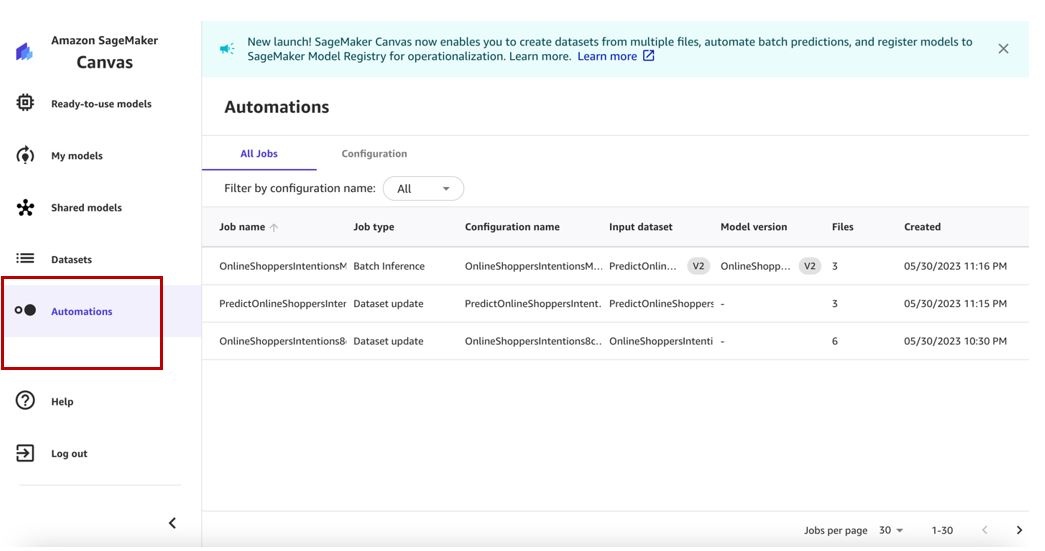
得益于自动数据集更新和自动批量预测工作流程,我们可以使用最新版本的表格、图像和文档数据集来训练机器学习模型,并构建每次数据集更新时自动触发的批量预测工作流程。
清理
为避免将来产生费用,请退出 Canvas。Canvas 会在会话期间向您收费,我们建议您在不使用 Canvas 时将其注销。有关更多详情,请参阅
结论
在这篇文章中,我们讨论了如何使用新的数据集更新功能来构建新的数据集版本,并使用Canvas中的最新数据训练我们的机器学习模型。我们还展示了如何有效地自动化对更新后的数据进行批量预测的过程。
特别感谢所有为发布会做出贡献的人。
作者简介
 Janisha An
and 是 SageMaker No/Low-Code ML 团队的高级产品经理,该团队包括 SageMaker Canvas 和 SageMaker Autopilot。她喜欢喝咖啡、保持活跃以及与家人共度时光。
Janisha An
and 是 SageMaker No/Low-Code ML 团队的高级产品经理,该团队包括 SageMaker Canvas 和 SageMaker Autopilot。她喜欢喝咖啡、保持活跃以及与家人共度时光。
 Prashanth
是亚马逊SageMaker的软件开发工程师,主要使用SageMaker的低代码和无代码产品。
Prashanth
是亚马逊SageMaker的软件开发工程师,主要使用SageMaker的低代码和无代码产品。
 Esha Dutta
是亚马逊 SageMaker 的软件开发工程师。她专注于为客户开发机器学习工具和产品。工作之余,她喜欢户外活动、瑜伽和徒步旅行。
Esha Dutta
是亚马逊 SageMaker 的软件开发工程师。她专注于为客户开发机器学习工具和产品。工作之余,她喜欢户外活动、瑜伽和徒步旅行。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。