我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 SnapStart 减少 亚马逊云科技 Lambda 函数上的 Java 冷启动
由 亚马逊云科技 高级无服务器解决方案架构师 Mark Sailes 撰写。
概述
如今,对于 Lambda 的函数调用,导致启动延迟的最大因素是初始化函数所花费的时间。这包括加载函数的代码和初始化依赖关系。对于对启动延迟敏感的交互式工作负载,这可能会导致最终用户体验不理想。
为了应对这一挑战,客户要么提前配置资源,要么花精力进行相对复杂的性能优化。尽管这些变通办法有助于减少启动延迟,但用户必须将时间花在一些繁重的工作上,而不是专注于提供商业价值。对于基于 Java 的 Lambda 函数,SnapStart 直接解决了这个问题。
SnapStart 的工作原理
使用 SnapStart,当客户发布函数版本时,Lambda 服务会初始化该函数的代码。它拍摄初始化执行环境的加密快照,并将快照保存在分层缓存中以实现低延迟访问。
首次调用函数然后扩展时,Lambda 会从持久快照恢复执行环境,而不是从头开始初始化。这可以降低启动延迟。
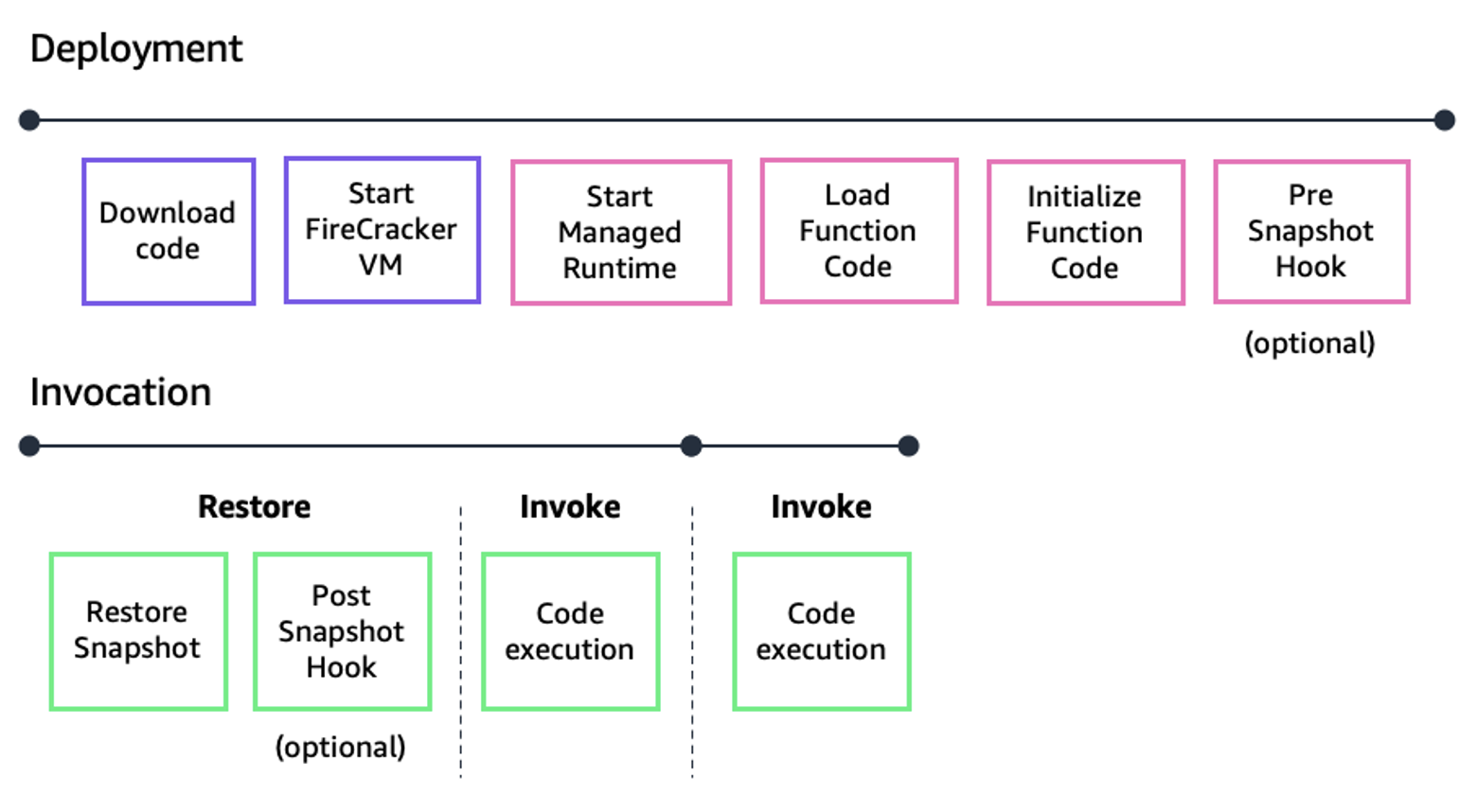
Lambda 函数生命周期
使用 SnapStart 激活的函数版本如果处于空闲状态 14 天,则会转换为非活动状态,之后 Lambda 会删除快照。当你尝试调用处于非活动状态的函数版本时,调用会失败。Lambda 发送 SnapStartNotReadyException 并开始在后台初始化新的快照,在此期间,函数版本保持待处理状态。等到函数到达 A
使用 SnapStart
诸如
如果这些框架带来的功能是在运行时实现的,那么它们通常会导致启动时间的延迟。SnapStart 允许您使用像 Spring 这样的框架,而不会影响尾部延迟。
为了演示 SnapStart,我使用了一个将记录保存 到
要部署,请:
-
克隆 git 存储库然后切换到项目目录:git clone
https://github.com/aws-samples/serverless-patterns.git cd serverless-patterns/apigw-lambda-snapstar t -
使用 亚马逊云科技 SAM CLI 来构建应用程序:
sam build -
使用 亚马逊云科技 SAM CLI 将资源部署到您的 亚马逊云科技 账户:
sam deploy-g
此项目在部署时已启用 SnapStart。要在 亚马逊云科技 管理控制台中启用或禁用此功能,请执行以下操作:
- 导航到您的 Lambda 函数。
- 选择 “配置” 选项卡。
- 选择 编辑 并将 SnapStart 属性更改为 PublishedVersions。
-
选择 “
保存”
。
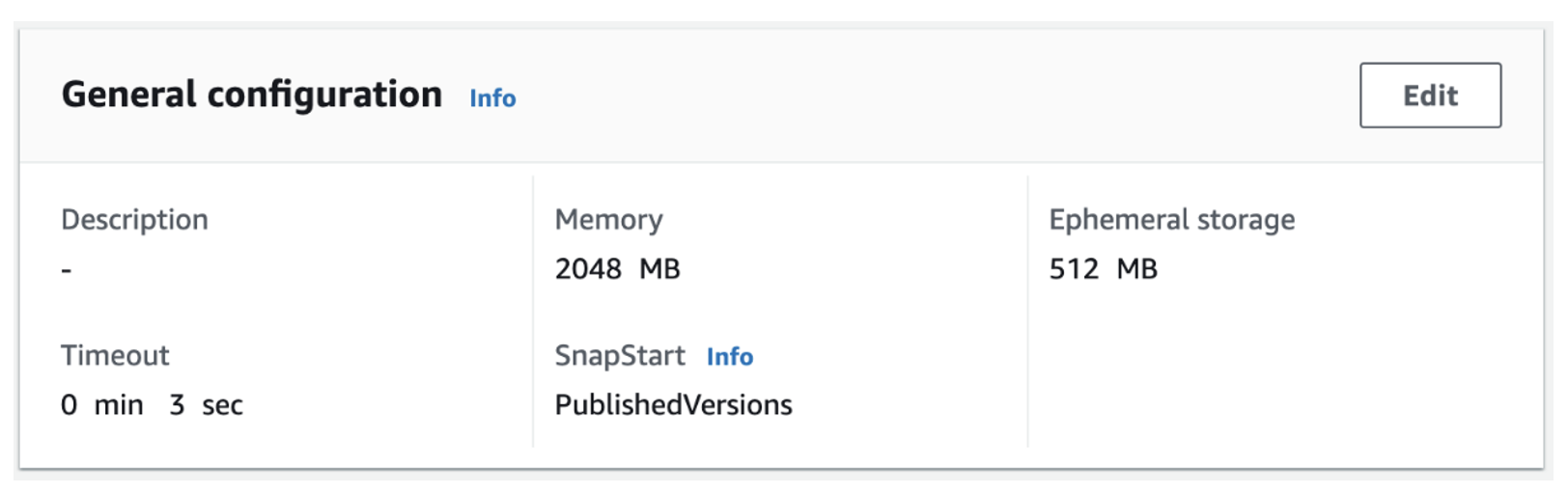
Lambda 控制台配置
- 选择 “ 版本 ” 选项卡,然后选择 “ 发布新 版本” 。
- 选择 “ 发布” 。
启用 SnapStart 后,Lambda 会发布带有快照的所有后续版本。运行发布版本的时间取决于您的初始化代码。使用此功能,您最多可以运行 init 15 分钟。
注意事项
过时的凭证
使用 SnapStart 并从快照中恢复通常会改变您创建函数的方式。使用按需函数,您可以在初始化阶段访问一次性数据,然后在将来的调用中重复使用这些数据。如果这些数据是短暂的,例如数据库密码,则在获取密钥和使用密钥之间可能有一段时间,密码已更改导致错误。你必须编写代码来处理这种错误情况。
使用 SnapStart 时,如果您采用相同的方法,您的数据库密码将保留在加密的快照中。所有未来的执行环境都具有相同的状态。这可能是在拍摄快照后的几天、几周或更长时间。这使得你的函数更有可能存储了错误的密码。为了改进这一点,你可以将获取密码的功能移至快照后挂钩。对于每种方法,重要的是要了解应用程序的需求并在错误发生时进行处理。
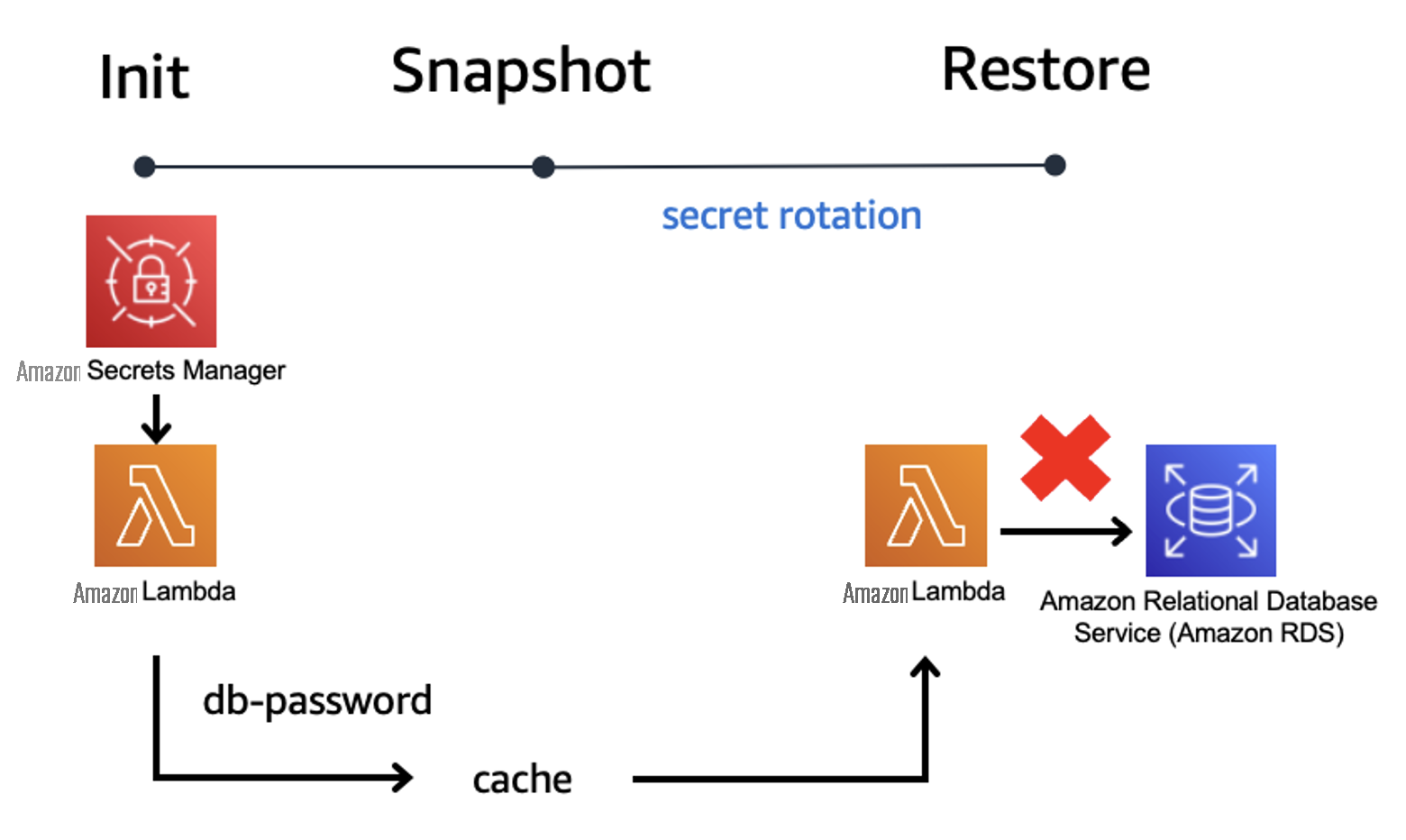
演示应用程序架构
共享初始状态的第二个挑战是随机性和唯一性。如果在初始化阶段将随机种子存储在快照中,则可能会导致随机数可预测。
密码学
亚马逊云科技 更改了托管运行时间,以帮助客户在恢复功能时处理唯一性和随机性的影响。
Lambda 已经整合了
始终从操作系统(例如,来自 /dev/random 或 /dev/urandom)获取随机数的软件已经可以弹性地执行快照操作。它不需要更新即可恢复唯一性。但是,喜欢使用自定义代码实现 Lambda 函数唯一性的客户在使用 SnapStart 时必须验证其代码能否恢复唯一性。
运行时挂钩
这些前置和后挂钩为开发人员提供了一种对快照过程做出反应的方法。
例如,必须始终从
Java 托管运行时使用开源的
以下函数示例显示如何使用运行时挂钩创建函数处理程序。该处理程序实现了 craC 资源和 Lambda RequestHandler 接口。
...
import org.crac.Resource;
import org.crac.Core;
...
public class HelloHandler implements RequestHandler<String, String>, Resource {
public HelloHandler() {
Core.getGlobalContext().register(this);
}
public String handleRequest(String name, Context context) throws IOException {
System.out.println("Handler execution");
return "Hello " + name;
}
@Override
public void beforeCheckpoint(org.crac.Context<? extends Resource> context) throws Exception {
System.out.println("Before Checkpoint");
}
@Override
public void afterRestore(org.crac.Context<? extends Resource> context) throws Exception {
System.out.println("After Restore");
}
}对于编写运行时挂钩所需的类,请将以下依赖项添加到您的项目中:
Maven
<dependency>
<groupId>io.github.crac</groupId>
<artifactId>org-crac</artifactId>
<version>0.1.3</version>
</dependency>Gradle
implementation 'io.github.crac:org-crac:0.1.3'Priming
SnapStart 和运行时挂钩为您提供了构建 Lambda 函数的新方法,从而降低了启动延迟。您可以使用快照前挂钩让 Java 应用程序尽可能为第一次调用做好准备。在拍摄快照之前,在函数中尽可能多地执行操作。这称为引用。
当您将 Java 代码的压缩文件上传到 Lambda 时,压缩文件包含字节码的.class 文件。它可以在任何带有 JVM 的计算机上运行。当 JVM 执行您的字节码时,它最初会被解释,然后编译成本机机器代码。这个编译阶段相对占用 CPU 资源,并且是及时发生的(JIT 编译器)。
在拍摄快照之前,你可以使用快照之前的挂钩来运行代码路径。JVM 编译这些代码路径,并保留优化以备将来恢复。例如,如果您有一个与 DynamoDB 集成的函数,则可以在 快照 之前 的挂钩中执行读取操作。
这意味着您的函数代码、适用于 Java 的 亚马逊云科技 开发工具包以及该操作中使用的任何其他库都经过编译并保存在快照中。这样,当你的函数被调用时,JVM 就不需要编译这段代码了,这意味着第一次调用执行环境时,你的延迟会更短。
Priming 要求您了解应用程序代码以及执行它的后果。示例应用程序包含
快照 前
挂钩,该 挂钩 通过从 DynamoDB 执行读取操作来启动
指标
下图反映了在 10 分钟内每秒 100 次调用示例应用程序 Lambda 函数。无论是否使用 SnapStart,此测试都基于此功能。
| p50 | p99.9 | ||
| On-demand | 7.87ms | 5,114ms | |
| SnapStart | 7.87ms | 488ms |
结论
这篇博客介绍了 SnapStart 如何减少基于 Java 的 Lambda 函数的启动(冷启动)延迟。
要了解更多信息,请参阅
此功能允许开发人员使用具有低延迟响应时间的 Lambda 中的按需模型,而不会产生额外费用。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。