我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
在 亚马逊云科技 上使用 IBM 的现代数据加速器更快地实现价值
作者:Tony Giordano,高级合伙人,数据平台服务全球负责人 — IBM
作者
:R
yan Keough,解决方案架构经理 — 亚马逊云科技 作者:A mit Chowdhur
y
,高级合作伙伴解决方案架构师 — A
W
S

|
| IBM |

|
随着数字化转型释放了数据服务的新用途和现有用途,数据用例从数据仓库时代开始发生了变化和扩展。
但是,许多组织仍在管理昂贵的单一用例数据环境,而 IBM 在 亚马逊云科技 上的 Modern Data Accelerators 可以帮助构建数据结构架构的现代实现,使客户能够更快地实现价值。
客户倾向于维护以下数据环境:
- 用于批量商业智能和报告的数据仓库。
- 用于数据科学预测模型测试和开发的数据湖。
- 用于数字互动的数字数据库。
这些一次性使用环境往往会大量重复从内部和外部来源获取数据,从而导致数据质量差、维护成本高和数据环境不灵活。
在这篇文章中,我们将讨论 IBM 的现代数据加速器如何帮助构建数据结构架构的现代实现,从而标准化整个企业的数据集成。
传统数据环境面临的挑战
通常,使用数据科学沙箱中内置的预测模型,传统数据环境与事件驱动的入站和出站数字渠道相互连接。但是,实时可视化需要对组织的数据用例进行更高级别的集成。
可以通过将数据环境构建到提供以下功能的多用例数据平台来解决这一挑战:
- 常见的数据配置数据湖: 经济实惠的云端存储,可从内部和外部来源获取实时和批量数据。
- 集成一致层:符合 特定领域(例如客户、产品和交易)的 企业数据。
- 消费层: 用于信息市场、数据科学沙箱、数字数据存储和运营数据用例。
在 亚马逊云科技 上实例化的具有通用数据预置功能的多用例数据平台通常可以提供成本更低、更灵活的数据环境和更高的数据质量。
IBM 咨询提供的现代数据加速器
IBM Consulting 已经建立了一套名为 “现代数据加速器” 的集成资产,这些资产可以缩短价值实现时间,减少交付时间和成本。
现代数据加速器允许企业构建多用例数据平台,并已开发为一组端到端资产,可以快速实例化在 亚马逊云科技 上实施数据云的数据功能。这些资产已部署在多个地区和各行各业。
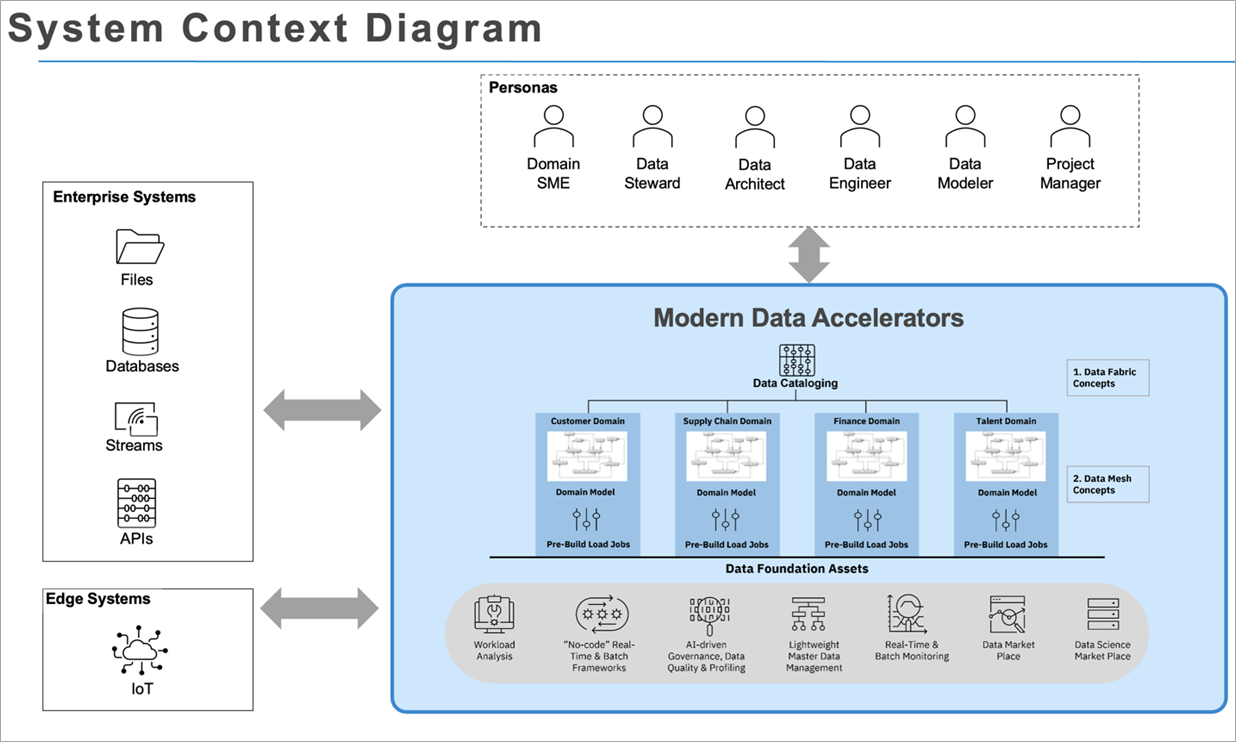
图 1 — 现代数据加速器。
值得注意的是,这些资产不仅仅是软件。它们不是提取、转换、加载 (ETL) 工具、数据库、大数据存储或其他数据管理软件。这是所有这些因素的组合,可以更快地使用数据管理服务。
基本上有两个选项可以加速数据管理服务:
- 执行传统的分析、设计和编码。
- 安装和配置资产,然后根据特定要求对其进行扩展。
解决方案概述
现代数据加速器是已知的数据管理流程,经过编纂以更快地推动业务价值。这些资产通过分析推动数据环境从开发到维护和摄取的生命周期。
现代数据架构组件
以下组件简要概述了 IBM 的现代数据加速器。
- 工作负载分析和现代化自动化: 创建基于角色的数据生态系统及其依赖关系的详细清单。提供传统数据处理代码的自动翻译和自动测试,这对于创建可操作的迁移路线图至关重要。
- 实时和批量智能集成引擎: 基于 Kafk a 的实时批处理引擎,可创建用于管理数据的提取、组织和发布的数据管道。这些引擎包括自定义连接、统一的批处理和流处理功能以及提取 API。数据载入过程使用机器学习模型进行学习和调整。
- 智能工作流程的数字集成: 这是专为企业和非结构化数据设计的智能工作流程的数据配置资产。
- 数据网格控制台: 为数据网格实现提供操作接口,这有助于管理数据产品的生命周期及其依赖关系。数据网格控制台旨在整合和利用数据目录和数据市场,同时还提供数据产品可观测性指标。
- 人工智能驱动的认知分类器: 人工智能驱动的认知分类器可根据企业规范模型自动对数据进行分类和组织,并提供对数据质量的实时洞察。自动数据标记为在数据平台上应用安全策略提供了分类。对组织数据进行培训后,该工具可以集成到智能集成引擎中,以实时和批处理模式对数据进行分类、自动映射和发送通知。
- 轻量级主数据管理 (MDM): 提供多域实体匹配功能,使用概率和确定性匹配逻辑,识别大型数据集中的重复或可疑重复实体。它是利用图形数据库和 Elasticsearch 功能构建的。
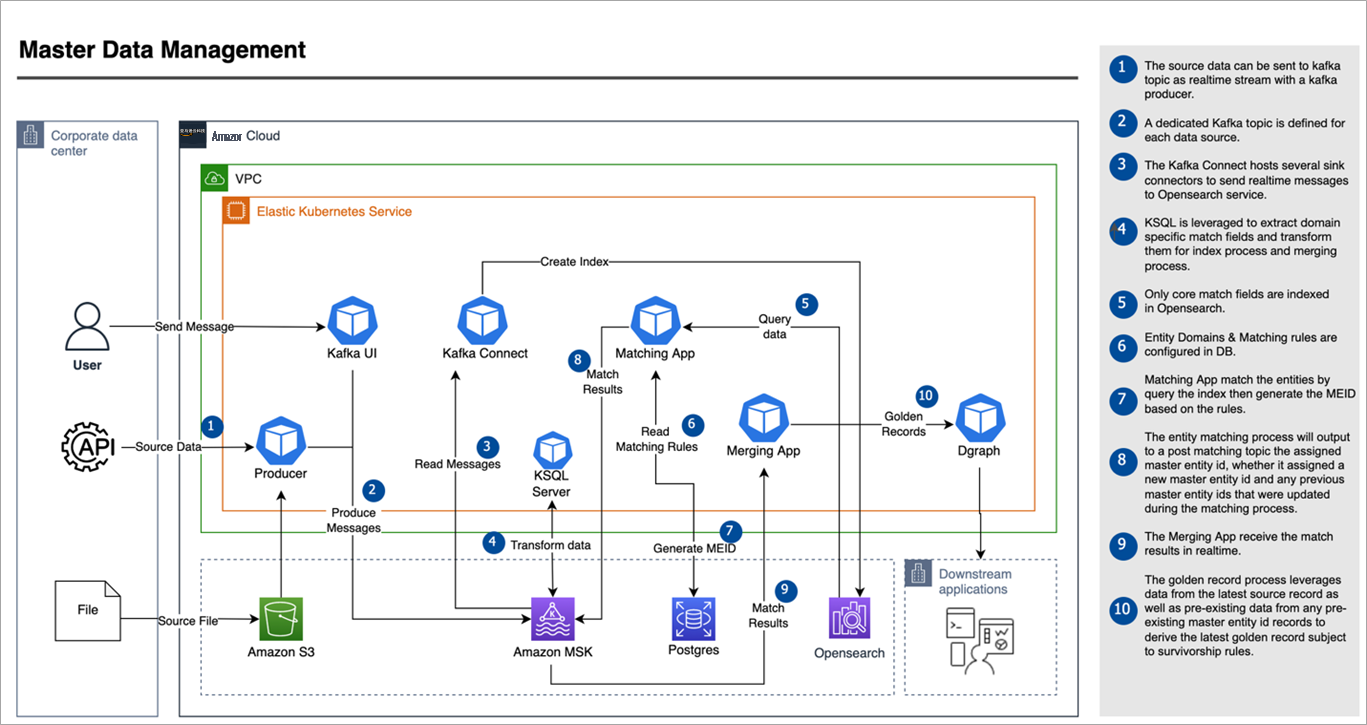
图 2 — 主数据管理。
- 实时和批量监控: 使用可自定义的开源 Grafana 仪表板和 Portlet 来维护 Data Fabric 环境中所有组件 的数据质量。该解决方案使用诸如Airflow之类的现代技术,能够提供高度的自动化数据管道和结构可观测性。
- 数据市场: 这是 亚马逊云科技 现代数据平台中数据消费的中央配置点。数据以原始和精选形式保存,并具有针对性的存储,允许发布和订阅数据。
- 数据科学市场: 包含一组云就绪的数据科学模型,这些模型可以在模型市场中访问和存储,托管在数据平台中。
如前所述,这些资产中的每一项都有助于加快亚马逊云科技上数据云解决方案的价值实现时间。 要了解所有这些组件是如何组合在一起构建现代数据加速器的,请参见 图 5 。
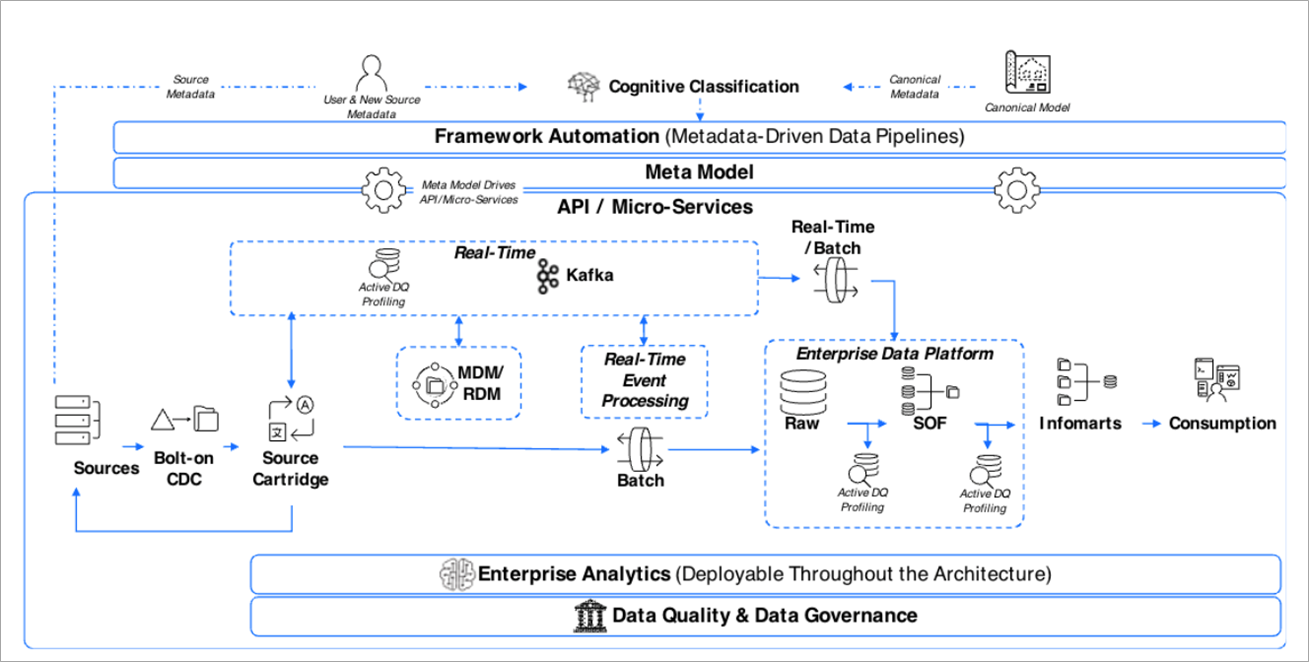
图 3 — 现代数据加速器的各个组件。
客户成功案例
以下案例研究很好地说明了现代数据加速器如何帮助客户缩短实现价值的时间。
IBM Consulting 受聘协助一家大型医疗保健组织以更高效、更主动的方式转变其分析数据的使用,同时降低总体成本。
该组织拥有一个主要用于报告目的的大型传统关系数据库。第一步是使用 IBM 的工作负载分析工具分析现有数据库工作负载,以确定使用该数据的数据类型和人物特征。
为了改变企业用户使用数据的方式,IBM Consulting使用IBM的实时和批量智能集成引擎将来自数百个来源的数据提取到新的
IBM 使用数据科学市场来存储预测模型,这些模型易于在后续模型中重复使用。早期的成功为调整最终状态数据平台的规模、在三个月内精选23个新数据集投入生产以及利用实时和批量监控功能在六个月内将新的单一亚马逊云科技云平台投入生产提供了动力。
结论
IBM 在 亚马逊云科技 上的现代数据加速器是一款久经考验的解决方案,可减少客户的交付时间和成本。它降低了维护传统数据平台的风险,同时缩短了价值实现时间。
现代数据加速器有助于在数据结构、数据网格或现代数据堆栈实现中实现以下目标:
- 管理: 对静态数据、动态数据和数据整合进行管理的 单一综合方法。
- 治理: 将所有企业资产 映射到单一的规范模型和数据目录中。
- 安全: 信息分类是定义安全策略和权利的唯一手段。
要了解有关该解决方案的更多信息,请查看 IBM
。

。
IBM — 亚马逊云科技 合作伙伴聚焦
IBM Consulting 是 亚马逊云科技 顶级服务合作伙伴和 MSP ,提供全面的服务能力,可解决客户当今面临的业务和技术挑战。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。