我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 Kinesis Data Streams 处理大型记录
在当今的数字时代,数据丰富且不断流动。各行各业的企业都在寻找利用这些丰富信息的方法,以获得有价值的见解并做出实时决策。为了满足这一需求,亚马逊云科技 提供了 A
像 Kinesis Data Streams 这样的数据流技术旨在高效地大规模地实时处理和管理连续的数据流。这些流中的各个数据片段通常被称为 记录 。在处理大型文件或执行图像、音频或视频分析等场景中,您的记录可能超过 1 MB。您可能很难使用 Kinesis Data Streams 摄取如此大的记录,因为截至撰写本文时,该服务的最大数据记录大小的上限为 1 MB。
在这篇文章中,我们向您展示了在 Kinesis Data Streams 中处理大型记录的一些不同选项,以及每种方法的优缺点。我们为每个选项提供了一些示例代码,以帮助您在自己的工作负载中开始使用其中任何一种方法。
了解 Kinesis 数据流的默认行为
你可以使用 putRecord 或
每个存放数据的分片最多可以处理每秒 1 MB 的写入。让我们考虑一个场景,即定义分区键并尝试发送大小超过 1 MB 的数据记录。根据目前的解释,该服务将拒绝此请求,因为记录大小超过 1 MB。为了帮助您更好地理解,我们尝试向直播发送 1.5 MB 的记录,结果是出现以下异常消息:
处理大型记录的策略
现在我们已经了解了 PutRecord 和
P ut
Records
API 的行为,让我们讨论一下可以用来克服这种情况的策略。要记住的一件事是,没有单一的最佳解决方案;在以下部分中,我们将讨论一些可以根据用例进行评估的方法:
-
将大型记录
存储在 亚马逊 Simple Storage Servic e (Amazon S3) 中,并在 Kinesis Data Streams 中提供引用 - 将一条大记录拆分成多条记录
- 压缩您的大型记录
让我们一一讨论这些观点。
在 Amazon S3 中存储大型记录,并在 Kinesis 数据流中提供引用
存储大型记录的一种有用方法包括使用替代存储解决方案,同时在 Kinesis Data Streams 中使用参考数据。在这种情况下,Amazon S3因其卓越的耐用性和成本效益而脱颖而出,是一个绝佳的选择。该过程包括将记录作为对象上传到 S3 存储桶,然后在 Kinesis Data Streams 中写入参考条目。此条目包含一个用作指针的属性,用于指示对象在 Amazon S3 中的位置。
使用这种方法,您可以生成与 S3 对象位置关联的
下图说明了该解决方案的架构。
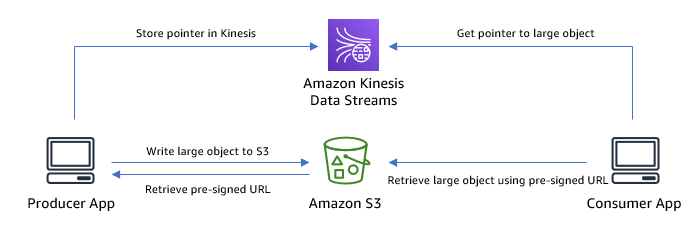
以下是使用这种方法向 Kinesis 数据流写入数据的示例代码:
如果您使用
采用这种技术的固有优势是能够将数据存储在 Amazon S3 中,每个对象可以容纳各种大小。此方法可以帮助您降低使用 Kinesis Data Streams 的成本,因为它占用的存储空间更少,需要更少的读写吞吐量才能访问项目。这种优化是通过在 Kinesis 数据流中仅存储 URL 来实现的。但是,必须承认,访问相当大的对象需要额外调用 Amazon S3,因此在管理额外请求时会给客户带来更高的延迟。
将一条大记录拆分成多条记录
在 Kinesis Data Streams 中将大型记录拆分成较小的记录可以带来诸如更快的处理速度、更高的吞吐量、高效的资源使用以及更直接的错误处理等优势。假设你有一条大型记录,在将其发送到 Kinesis 数据流之前,你想将其拆分成小块。首先,你需要设置一个 Kinesis 制作人。假设你有一条作为字符串的大记录。您可以将其拆分成预定义大小的较小块。在此示例中,假设您将记录拆分为每块 100 个字符的块。拆分后,循环浏览记录区块,并将每个区块作为单独的消息发送到 Kinesis 数据流。以下是示例代码:
确保给定消息的所有区块都定向到单个分区,从而保证其顺序得到保留。在最后一块中,在标题中包含元数据,表示消息在制作过程中的结论。这使消费者能够识别最终区块并促进无缝消息重建。这种方法的缺点是,它增加了分割和重新组合不同部分的客户端任务的复杂性。因此,这些功能需要进行全面测试以防止数据丢失。
压缩您的大型记录
在将数据传输到 Kinesis 数据流之前应用数据压缩具有许多优点。这种方法不仅缩小了数据的大小,实现了更快的传输速度和更高效的网络资源利用,还可以在优化整体资源消耗的同时节省存储开支。此外,这种做法简化了存储和数据保留。通过使用 GZIP、Snappy 或 LZ4 等压缩算法,可以大幅减小大型记录的大小。压缩带来了简单性的好处,因为它可以无缝实施,无需调用者更改项目或使用额外的 亚马逊云科技 服务来支持存储。但是,压缩会给生产者端带来额外的 CPU 开销和延迟,其对压缩率和效率的影响可能因数据类型和格式而异。此外,压缩可以提高消费者的吞吐量,但代价是一些解压缩开销。
结论
对于实时数据流用例,在使用 Kinesis Data Streams 时必须仔细考虑处理大型记录。在这篇文章中,我们讨论了与管理大型记录相关的挑战,并探讨了利用 Amazon S3 引用、记录拆分和压缩等策略。每种方法都有自己的优缺点,因此评估数据的性质和需要执行的任务至关重要。根据数据的特征和处理任务要求选择最合适的方法。
我们鼓励您尝试本文中讨论的方法,并在评论部分分享您的想法。
作者简介
 Masudur Rahaman Sayem 是 亚马逊云科技
的流媒体数据架构师。他与全球 亚马逊云科技 客户合作,设计和构建数据流架构,以解决现实世界的业务问题。他擅长优化使用流数据服务和 NoSQL 的解决方案。Sayem 对分布式计算充满热情。
Masudur Rahaman Sayem 是 亚马逊云科技
的流媒体数据架构师。他与全球 亚马逊云科技 客户合作,设计和构建数据流架构,以解决现实世界的业务问题。他擅长优化使用流数据服务和 NoSQL 的解决方案。Sayem 对分布式计算充满热情。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。