在 亚马逊云科技 中大规模管理数据库时,在某些情况下,您可能需要在单个或多个 亚马逊云科技 账户中维护 A
mazon Aurora
集群。这些情景包括但不限于合并和收购、整合所有账户以仅使用一个账户,或者合规性以在单独的账户中维护生产和开发环境。在当今基于互联网的应用程序中,停机时间总是非常宝贵的,因为公司要求将迁移活动的停机时间降至最低。
在这篇文章中,我们将介绍如何以最少的停机时间将
Amazon Aurora MySQL 兼容版
数据库从一个账户迁移到另一个账户。
解决方案概述
您可以使用简单的
Aurora 快照
副本跨账户迁移数据库。但是,这还不足以最大限度地减少停机时间,因为在目标账户中创建和恢复备份的同时,应用程序可以进行更改。更好的方法是将快照和复制结合使用。您在源账户中拍摄 Aurora 集群的快照并将其恢复到目标账户,然后将所有增量更改复制到目标账户。对于复制,我们可以使用原生
MySQL 二进制日志
复制或
亚马逊云科技 数据库迁移服务
(亚马逊云科技 DMS)。在这篇文章中,我们将演示这两种方法。
下图说明了解决方案架构。
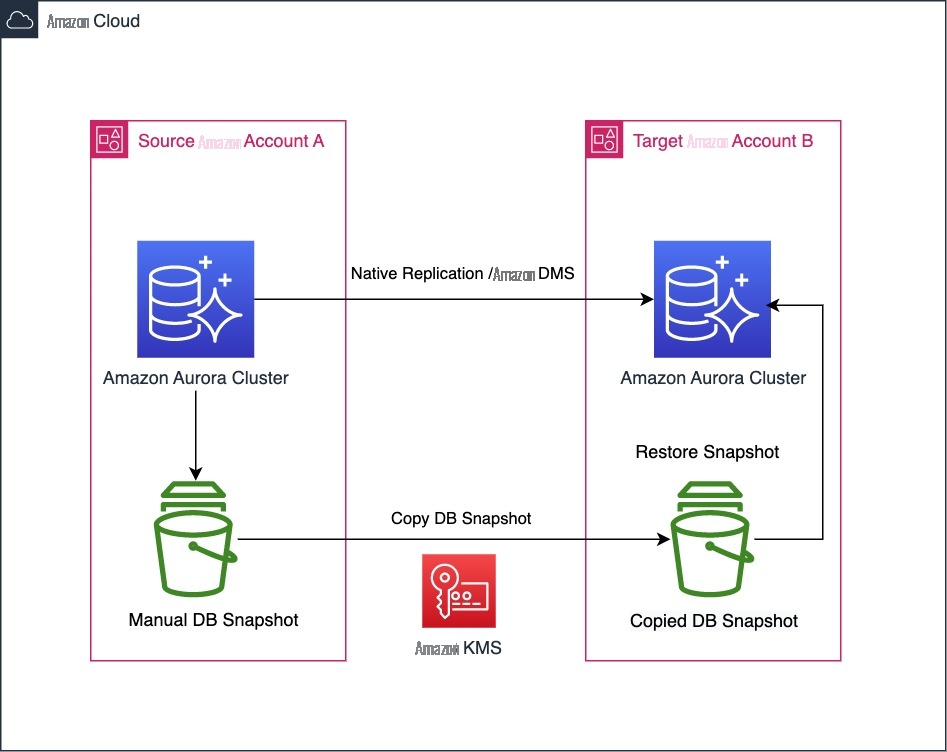
对于我们的解决方案,我们拍摄源 Aurora 集群的快照,然后在另一个账户中将其恢复。然后,我们根据 MySQL 二进制日志序列号为任何增量更改设置复制,以便捕获并应用快照之后的所有更改。
先决条件
原生 MySQL 二进制日志复制和 亚马逊云科技 DMS 方法都需要在源 Aurora MySQL 数据库集群上进行以下配置设置:
-
使用
VPC 对等连接或 亚马逊云科技 Transit Gate
w ay 在两个 亚马逊云科技
账户之间设置联网。要测试两个 亚马逊云科技 账户的网络设置,您可以在与 Aurora 相同的子网中预置
亚马逊弹性计算云
(Amazon EC2) 实例并测试连接。此外,请务必更新您的
安全组
以引用对等安全组。
-
默认情况下,Aurora 不使用二进制日志复制到读取器实例。但是,要使用二进制日志复制方法,我们必须启用二进制日志。我们通过创建自定义
集群参数组 (如果你使用默认参数组
),然后将
binlog_form
at 参数更新为 ROW 来做到这一点。
我们建议在复制期间将
binlog_form
at 设置为 ROW,因为在某些情况下,如果
binlog_form
at 设置 为 STATEMENT 或 MIXED,则在将数据复制到目标时可能会导致不一致。有关基于行的日志记录的更多信息,请参阅
基于行的 复制的优缺点
。
如果源数据库集群已连接到默认参数组,则可以使用
亚马逊云科技 命令行接口 (亚马逊云科技
CLI) 按以下步骤所述,通过修改
binlog_ for
mat 参数创建新的自定义数据库集群参数组,并将其附加到集群:
-
创建参数组:
aws rds create-db-cluster-parameter-group \
--db-cluster-parameter-group-name repl-clstr-param-group\
--db-parameter-group-family aurora-mysql5.7 \
--description "repl source cluster parameter group"
-
将
binlog_form
at 修改为 ROW:
aws rds modify-db-cluster-parameter-group \
--db-cluster-parameter-group-name repl-clstr-param-group \
--parameters "ParameterName='binlog_format',ParameterValue='ROW',ApplyMethod= pending-reboot"
-
将集群参数组应用到您的集群:
aws rds modify-db-cluster \
--db-cluster-identifier repl-source \
--db-cluster-parameter-group-name repl-clstr-param-group --apply-immediately
-
重启集群:
aws rds reboot-db-instance \
--db-instance-identifier repl-source-instance-1
如果您已经将自定义参数组连接到源数据库集群,则只需更改 binlog_format 参数,然后重新启动集群即可。
需要重新启动,因为
binlog_form at 是一个 静态
参数。
-
延长保留期以避免在复制之前删除二进制日志:
CALL mysql.rds_set_configuration('binlog retention hours', 48);
在此示例中,我们将二进制日志保留 48 小时。
-
拍下 Aurora 集群 的
快照
:
aws rds create-db-cluster-snapshot \
--db-cluster-identifier repl-source \
--db-cluster-snapshot-identifier src-snapshot
-
与目标 亚马逊云科技 账户@@
共享
此快照。
如果 Aurora 集群已加密,则需要执行其他步骤才能共享
亚马逊云科技 密钥管理服务
加密密钥。有关更多信息,请参阅
允许访问 亚马逊云科技 KMS 密钥
和
如何与其他 亚马逊云科技 账户共享手动 Amazon RDS 数据库快照或 Aurora 数据库集群快照
。
-
当 Aurora MySQL 快照在目标账户中可用时,请在另一个账户中
恢复
此快照:
aws rds restore-db-cluster-from-snapshot \
--db-cluster-identifier repl-target \
--snapshot-identifier arn:aws:rds:us-east-1:xxxxxxxxx:cluster-snapshot:src-snapshot \
--engine aurora-mysql \
--engine-version 5.7 \
--vpc-security-group-ids sg-xxxxxxxx \
--db-subnet-group-name aurora-subnet-grp \
--no-publicly-accessible
aws rds create-db-instance \
--db-instance-identifier repl-target-instance \
--db-instance-class db.r6g.2xlarge \
--engine aurora-mysql \
--db-subnet-group-name aurora-subnet-grp \
--db-cluster-identifier repl-target
-
恢复完成后,请务必记下可通过
Aurora 事件
获得的 binlog 崩溃恢复位置。在设置增量复制期间需要这个二进制日志位置。以下是崩溃恢复消息示例:
"Message": "Binlog position from crash recovery is mysql-bin-changelog.000002 154”
-
最后,在源 Aurora MySQL 集群上,在数据库中创建一个用于复制的复制用户:
mysql> 创建由 “” 标识的用户 “repl_user'@'%
”;
mysql> GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'repl_user'@'%';
在以下部分中,我们将介绍使用本机二进制日志复制或 亚马逊云科技 DMS 设置复制的步骤。
使用本机 binlog 复制设置复制
要使用本机 binlog 复制,请完成以下步骤:
-
使用 MySQL
外部主
服务器 并使用您之前提到的二进制日志位置在目标 Aurora MySQL 上
启动复制
过程:
mysql> CALL mysql.rds_set_external_master ( 'repl-source.cluster-xxxx.us-east-1.rds.amazonaws.com', 3306, 'repl_user',<enter_your_password>,'mysql-bin-changelog.000002',154,0);
mysql> CALL mysql.rds_start_replication;
-
使用以下命令检查
复制状态
:
mysql> show slave status\G;
-
监控上一个命令
中的 Seconds_Behind_Master
值,了解源和目标 Aurora 数据库之间的复制延迟。当
Seconds_Behind_Master
值为 0 时,源和目标 Aurora MySQL 数据库处于同步状态。
在新 亚马逊云科技 账户中切换到目标 Aurora 集群之前,请执行以下切换前任务:
-
验证新账户中目标集群的配置,以确认数据库基础设施准备就绪。
-
使用新账户中的目标 Aurora 集群测试应用程序关键型数据库操作。
-
如果应用程序对数据库性能敏感,则通过在目标 Aurora 集群上运行顶部 SELECT 查询来预热数据库缓存。
-
停止应用程序对源 Aurora 集群的写入,并将连接重定向到目标 Aurora 集群。
有关更多信息,请参阅在尽量减少停机时间的情况下对
Amazon Aurora MySQL 执行主要版本升级
的切换前任务部分。
使用 亚马逊云科技 DMS 设置复制
我们可以使用 亚马逊云科技 DMS 的
本机 CDC 起始点
功能来捕获快照恢复后的增量更改,以便执行跨账户 Aurora MySQL 数据库迁移。共享和恢复 Aurora MySQL 快照并在另一个账户中创建集群后,通过
亚马逊云科技 管理控制台 或 亚马逊云科技
CLI 记下 Aurora 写入器实例的日志和事件中的崩溃恢复位置。然后完成以下步骤:
-
查看将 MySQL 作为
源
和
目标
的先决条件 ,以准备两个 Aurora MySQL 数据库。
-
创建
亚马逊云科技 DMS 复制实例并对其进行配置,使其可以连接到源数据库和目标数据库。
-
创建源和目标
亚马逊云科技 DMS 终端节点
并检查连接是否成功。
-
创建仅限 亚马逊云科技 DMS CDC 的复制
任务
, 并为迁移类型选择 “
仅 复制数据更改
” 选项。
-
启用自定义 CDC 启动模式并选择
指定日志序列号
。
-
输入之前捕获的崩溃恢复位置(例如,
mysql-bin-
changelog. 000002:154)。
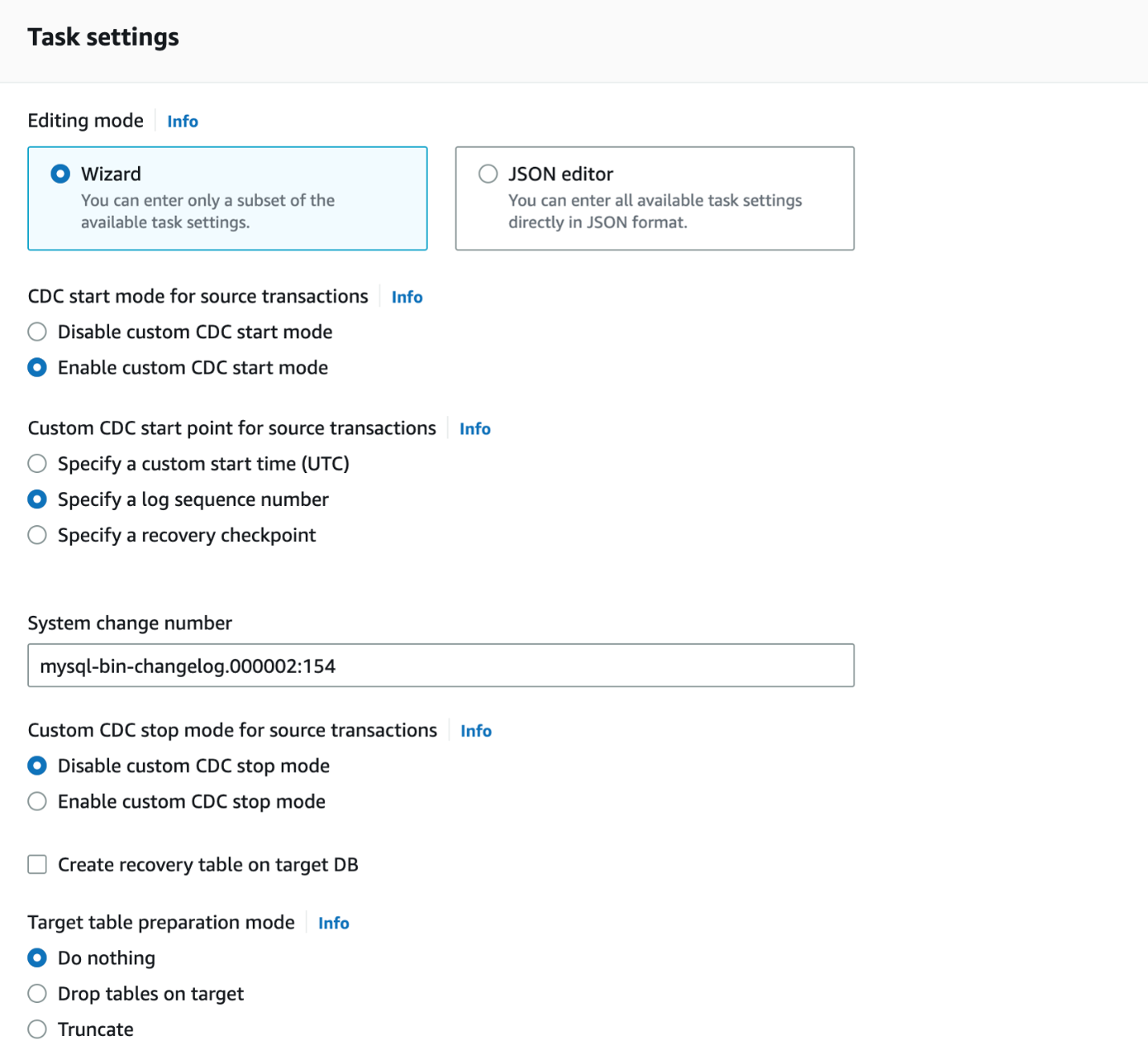
-
指定
相应的映射规则和设置
来创建任务。
-
任务状态更改为 “
已创建
” 后 ,启动任务。
-
监控 亚马逊云科技 DMS 任务中是否存在任何
故障
, 并使用
亚马逊云科技 DMS 数据验证来验证数据 以保持数据
一致性。
-
验证数据一致性后,与应用程序团队合作声明维护时段。
-
监控
cdcLatencySou
rce 和
cdcLatencyTarget
:
当它们的值为 0 时,切换到驻留在另一个 亚马逊云科技 账户中的目标 Aurora MySQL 集群(不要忘记前面讨论的任何切换前任务)。
清理
切换到目标 Aurora MySQL 集群后,您可以
停止
源 Aurora 集群以避免收费。如果不是单向迁移并且您打算保留集群,请通过将数据库集群参数组中的 binlo
g_forma t 参数设置为 OFF 来重置二进制
日志保留期并禁用源上的二进制日志。迁移完成且无需保留源集群后,您可以将其删除。有关说明,请参阅
删除 Aurora 集群和数据库实例
。如果您使用 亚马逊云科技 DMS 将增量更改复制到目标,则
在不再需要时,也应 删除 亚马逊云科技 DMS 复制实例
。
结论
在这篇文章中,您学习了如何使用本机二进制日志复制或 亚马逊云科技 DMS 在最短停机时间内跨不同账户迁移 Aurora MySQL 集群。我们建议您首先使用原生 MySQL 复制方法,如果发现任何问题,请探索 亚马逊云科技 DMS 替代方案。
在评论中提出问题或要求。祝您迁移愉快!
作者简介
 Amay Chopra
是位于德克萨斯州达拉斯的 亚马逊云科技 专业服务的数据库顾问。他与 亚马逊云科技 客户合作开发各种服务,以帮助在 亚马逊云科技 上构建自定义解决方案和运行生产工作负载。工作之余,他喜欢打草地网球、去新地方旅行以及与家人和朋友共度时光。
Amay Chopra
是位于德克萨斯州达拉斯的 亚马逊云科技 专业服务的数据库顾问。他与 亚马逊云科技 客户合作开发各种服务,以帮助在 亚马逊云科技 上构建自定义解决方案和运行生产工作负载。工作之余,他喜欢打草地网球、去新地方旅行以及与家人和朋友共度时光。
 Sushant Deshmukh
是 亚马逊云科技 专业服务团队的数据库顾问。他与 亚马逊云科技 客户和合作伙伴合作,在 亚马逊云科技 上构建高度可用、可扩展和安全的数据库架构。他提供在 亚马逊云科技 上运行数据库工作负载的技术设计和实施专业知识,还帮助客户将其数据库迁移到 亚马逊云科技 云并对其进行现代化改造。工作之余,他喜欢旅行和探索新地方,打排球以及与家人和朋友共度时光。
Sushant Deshmukh
是 亚马逊云科技 专业服务团队的数据库顾问。他与 亚马逊云科技 客户和合作伙伴合作,在 亚马逊云科技 上构建高度可用、可扩展和安全的数据库架构。他提供在 亚马逊云科技 上运行数据库工作负载的技术设计和实施专业知识,还帮助客户将其数据库迁移到 亚马逊云科技 云并对其进行现代化改造。工作之余,他喜欢旅行和探索新地方,打排球以及与家人和朋友共度时光。
 Devinder Singh
是 亚马逊云科技 的南非经理。他在使用各种数据库和存储技术方面拥有超过 25 年的经验。Devinder 专注于帮助客户踏上 亚马逊云科技 之旅,帮助他们基于各种关系和 NoSQL 亚马逊云科技 数据库服务架构高度可用和可扩展的数据库解决方案。不与客户合作时,你总能发现 Devinder 喜欢长途徒步旅行或骑自行车。
Devinder Singh
是 亚马逊云科技 的南非经理。他在使用各种数据库和存储技术方面拥有超过 25 年的经验。Devinder 专注于帮助客户踏上 亚马逊云科技 之旅,帮助他们基于各种关系和 NoSQL 亚马逊云科技 数据库服务架构高度可用和可扩展的数据库解决方案。不与客户合作时,你总能发现 Devinder 喜欢长途徒步旅行或骑自行车。