我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Locust 进行亚马逊 Kinesis 负载测试
构建流数据解决方案需要对其在生产环境中运行的大规模进行全面测试。大规模运行的流媒体应用程序通常处理高达每秒 GB 的大容量,开发人员很难模拟高流量的 基于
为了克服这些限制,这篇文章介绍了如何使用现代负载测试框架
概述
该项目通过 Locust 向 Kinesis 发射温度传感器读数。我们通过 亚马逊云科技
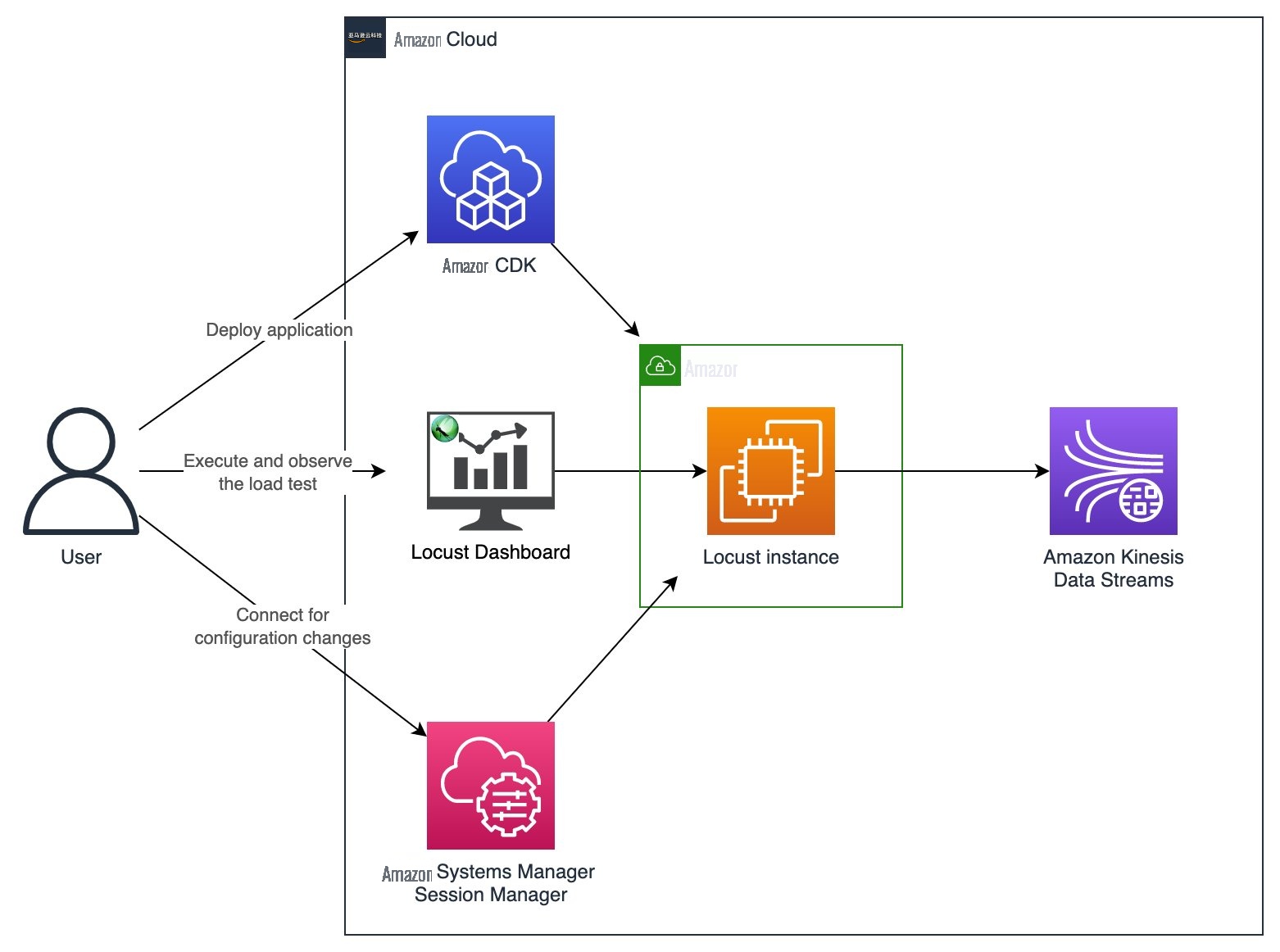
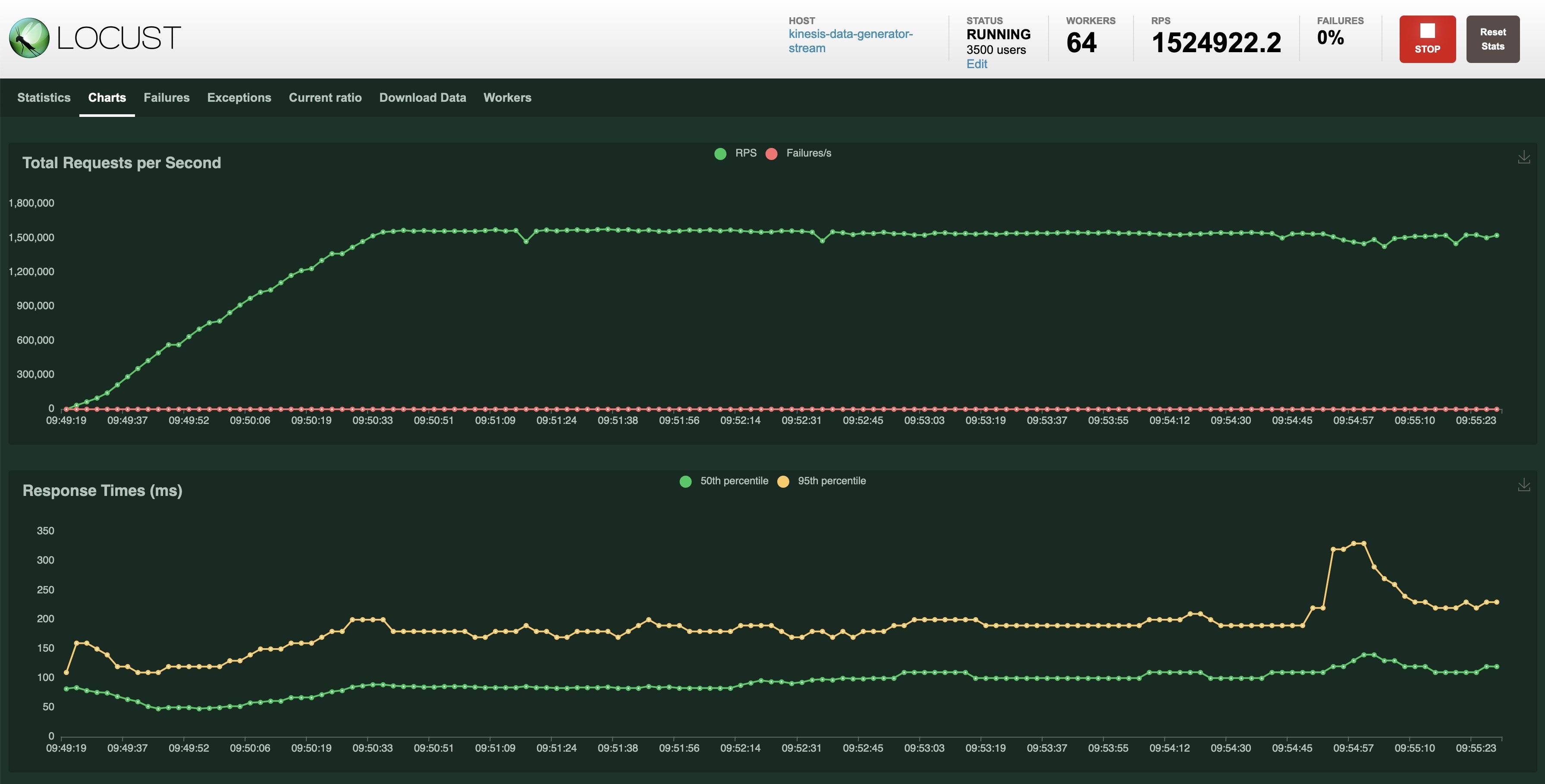
在我们使用最大的推荐实例 (c7g.16xlarge) 进行测试时,该设置能够在按需容量模式下每秒向 Kinesis 数据流发射超过 100 万个事件,批次大小(每个 Locust 用户的模拟用户)为 500。您可以在这篇文章的后面找到有关这意味着什么以及如何配置负载测试的更多详细信息。
蝗虫概述
Locust 是一个开源、可编写脚本且可扩展的性能测试工具,允许您使用 Python 代码定义用户行为。它提供了易于使用的界面,使其对开发人员友好且具有高度可扩展性。凭借其分布式和可扩展的设计,Locust 可以同时模拟数百万用户,以模仿性能测试期间的真实用户行为。
每个 Locust 用户代表真实用户可能在您的系统上执行的场景或一组特定操作。使用 Locust 运行性能测试时,您可以指定要模拟的并发 Locust 用户数量,Locust 将为每个用户创建一个实例,允许您评估系统在不同用户负载下的性能和行为。
有关 Locust 的更多信息,请参阅
先决条件
首先,请从
在本地测试
要先在本地测试 Locust,然后再将其部署到云端,你必须安装必要的 Python 依赖项。如果你不熟悉 Python,请参阅
导航到
load- test
目录并运行以下代码:
要从本地计算机向 Kinesis 数据流发送事件,您需要拥有 亚马逊云科技 证书。有关更多信息,请参阅
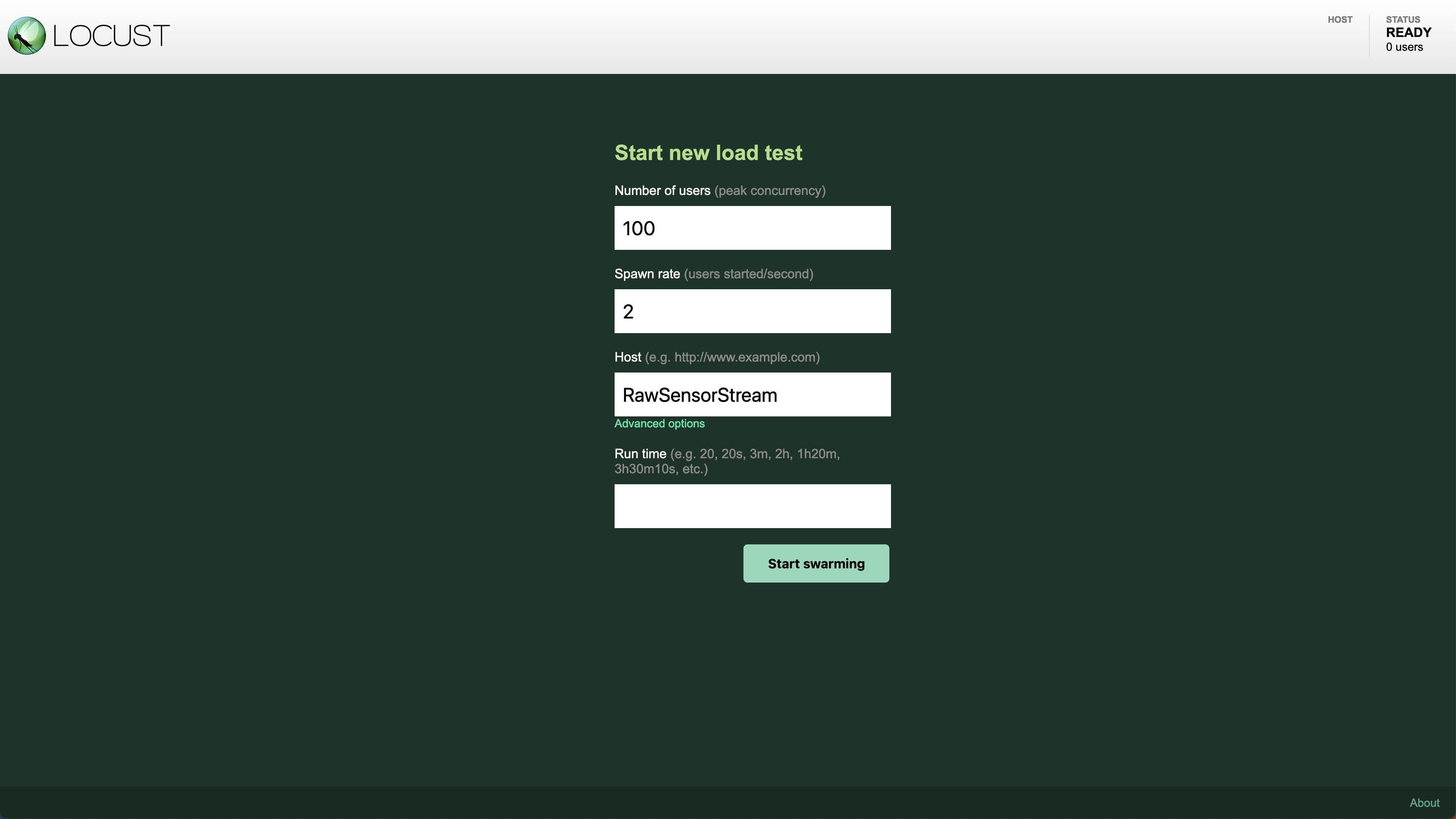
要在本地执行测试,请留在
load- test
目录中运行以下代码:
你现在可以通过
流 DemoStream
。
要查看记录的生成事件,请运行以下命令,该命令仅过滤 Locust 和根日志(例如,没有 Botocore 日志):
使用 亚马逊云科技 CDK 设置资源
GitHub 存储库包含 亚马逊云科技 CDK 代码,用于创建负载测试所需的所有资源。这消除了出现手动错误的机会,提高了效率,并确保了长期配置的一致性。要部署资源,请完成以下步骤:
- 如果尚未下载,请使用以下命令将 GitHub 存储库克隆到您的本地计算机:
-
下载 并安装最新的 Node.js。 - 导航到项目的根文件夹,然后运行以下命令来安装最新版本的 亚马逊云科技 CDK:
- 安装必要的依赖关系:
- 运行 cdk bootstrap 来初始化您的 亚马逊云科技 账户中的 亚马逊云科技 CDK 环境。在运行以下命令之前,请替换您的 亚马逊云科技 账户 ID 和区域:
- 安装依赖项后,您可以运行以下命令来部署 亚马逊云科技 CDK 模板的堆栈,该堆栈将在 5 分钟内设置基础设施:
该模板设置了 Locust EC2 测试实例,该实例默认为 c7g.xlarge 实例,在发布时,us-east-1 的价格约为每小时 0.145 美元。要找到最准确的定价信息,请参阅 Amazon EC2 按需定价。您可以在本文后面找到有关如何根据负载测试规模更改实例大小的更多详细信息。
必须考虑到,负载测试期间产生的费用不仅归因于 EC2 实例成本,还受到数据传输成本的严重影响。
访问 Locust 控制面板
你可以使用 AWS CDK 输出 k
inesislocustLoadTestingStack.locustdas
hboardurl 打开控制面板,例如 http://1.2.3.4:8089 来访问控制面板。
Locust 仪表板受密码保护。
默认情况下,它设置为用户名
locust-user 和密码 locust-dashboard-pw
d。
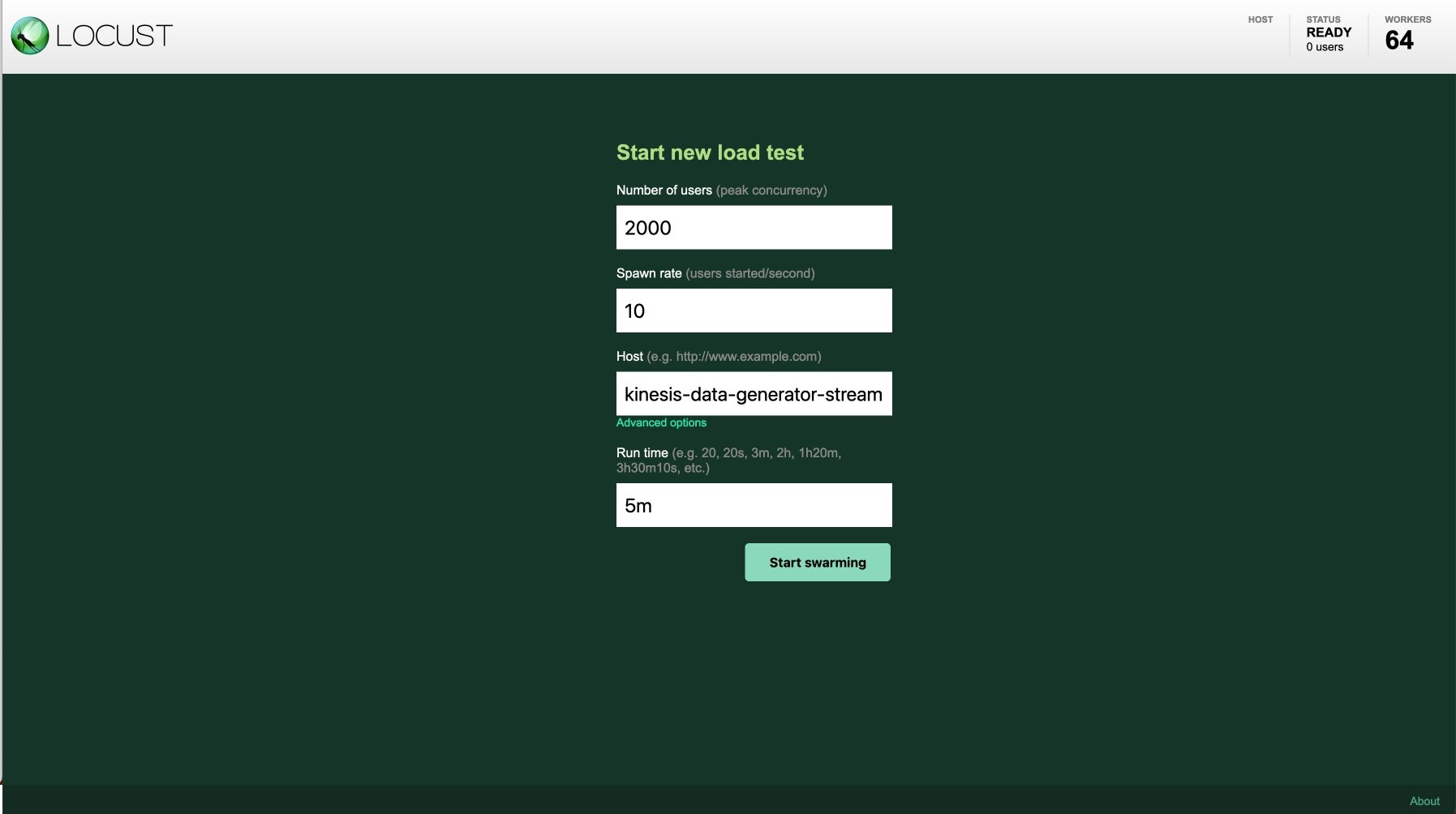
使用默认配置,您每秒最多可以发出 15,000 个事件。 输入 Locust 用户的数量(乘以批次大小)、生成率(每秒添加的用户)以及 Host 的目标 Kinesis 数据流名称。
开始负载测试后,可以在 “ 图表 ” 选项卡上查看负载测试。
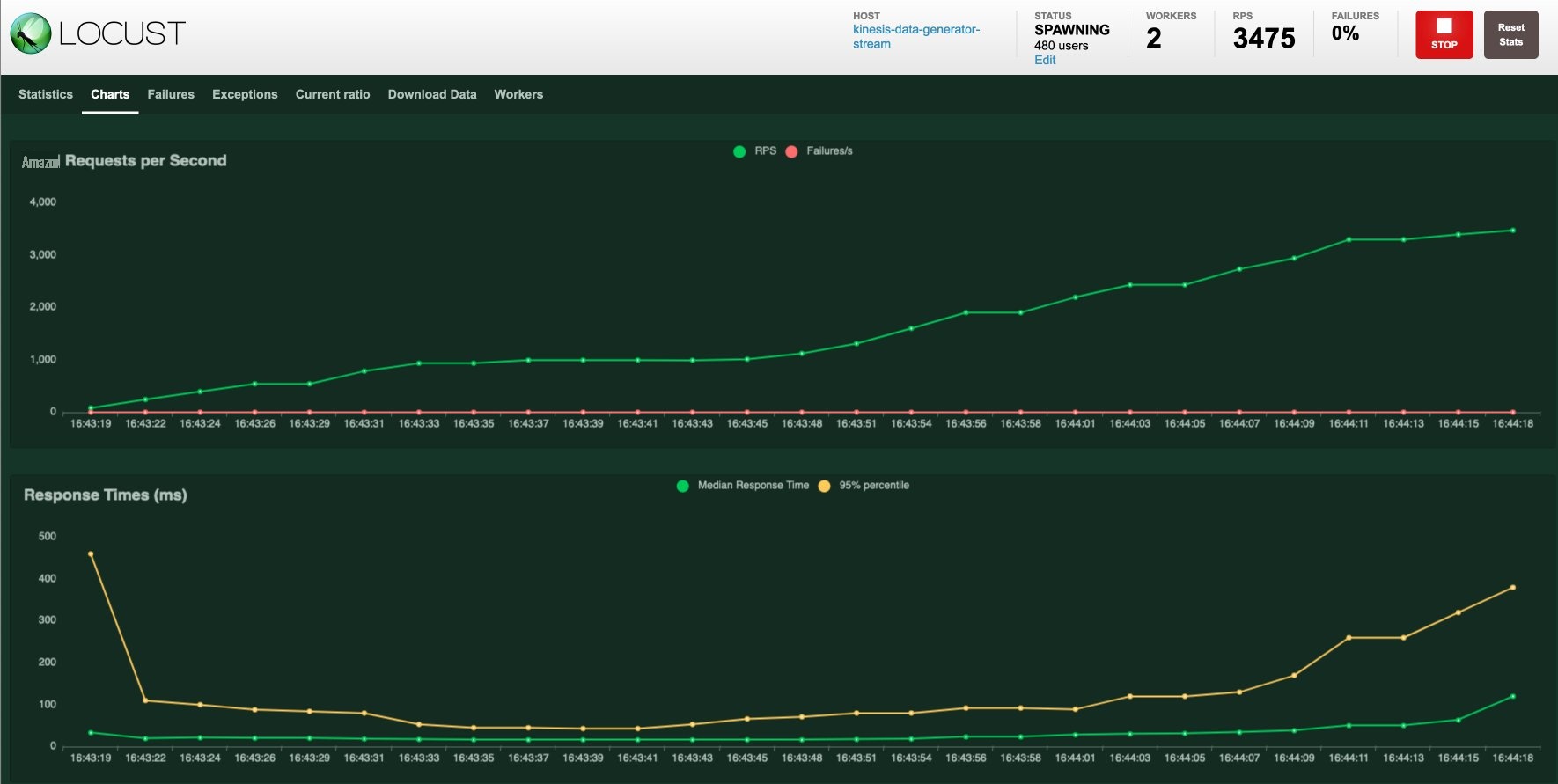
您还可以通过导航到正在进行负载测试的数据流,在 Kinesis Data Streams 控制台上监控负载测试。如果您使用默认设置,请导航到
DemoStream
。在详细信息页面上,选择 “
监控
” 选项卡以查看载入的负载。
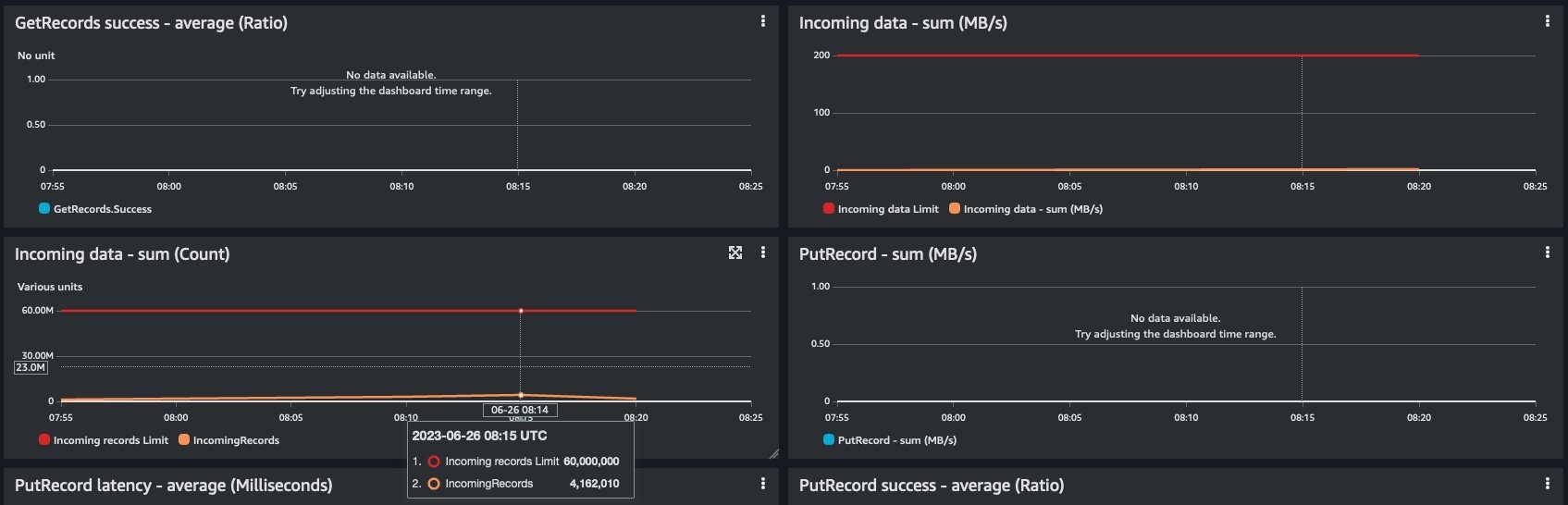
调整工作负载
默认情况下,该项目为每个传感器生成随机温度传感器读数,格式如下:
该项目附带Faker,您可以使用它来调整有效载荷以满足您的需求。
你只需要更新 locust-load-test.py 文件中的 g
enerate_sensor_reading
函数即可:
更改配置
首次部署负载测试工具后,您可以通过两种方式更改配置:
- 连接到 EC2 实例,进行任何配置和代码更改,然后重启 Locust 进程
-
在本地更改配置和加载测试代码,然后通过
cdk deploy 将其重新部署
第一个选项可帮助您更快地在远程实例上进行迭代,而无需重新部署。后者使用基础设施即代码 (IaC) 方法,并确保您的配置更改可以提交到源代码控制系统。为了缩短开发周期,建议先在本地测试您的负载测试配置,连接到您的实例以应用更改,在成功实施后,将其编码为 IaC 存储库的一部分,然后重新部署。
如果您想在不重新部署堆栈的情况下根据需要更改 Locust 的配置,则可以通过系统管理器连接到实例,在 /us
r/local/load-test 上导航到项目目录,更改 loc
t 来重启服务。
ust.env 文件,然后通过运行 sudo systemctl restart l
ocus
大规模负载测试
此设置能够每秒向 Kinesis 数据流发射超过 100 万个事件,批量大小为 500 个,c7g.16xlarge 上有 64 个辅助事件。
要使用 Locust 和 Kinesis 实现最佳性能,请记住以下几点:
-
实例大小
-您的性能受底层 EC2 实例的约束,因此有关扩展的更多信息,请参阅
EC2 实例类型 。要设置正确的实例大小,您可以在 kinesis-locust-load-testing.ts 文件中配置实例大小。 -
辅助服务器的数量
— Locust 受益于分布式设置。因此,该设置启动了一个初级系统来进行协调,并启动了多个辅助系统来完成实际工作。要充分利用内核,您应该为每个内核指定一个辅助内核。你可以在
locust. env 文件中配置这个数字。 -
批量大小
— 由于切换 Locust 用户和线程的资源开销,每个 Locust 用户可以发送的 Kinesis 数据流事件数量受到限制。为了克服这个问题,你可以配置批量大小来定义每个 Locust 用户模拟多少用户。它们作为 Kinesis 数据流
put_ records 调用发送。你可以在locust. env 文件中配置这个数字。
此设置能够每秒向 Kinesis 数据流发射超过 100 万个事件,批量大小为 500 个,在 c7g.16xlarge 实例上有 64 个辅助事件。
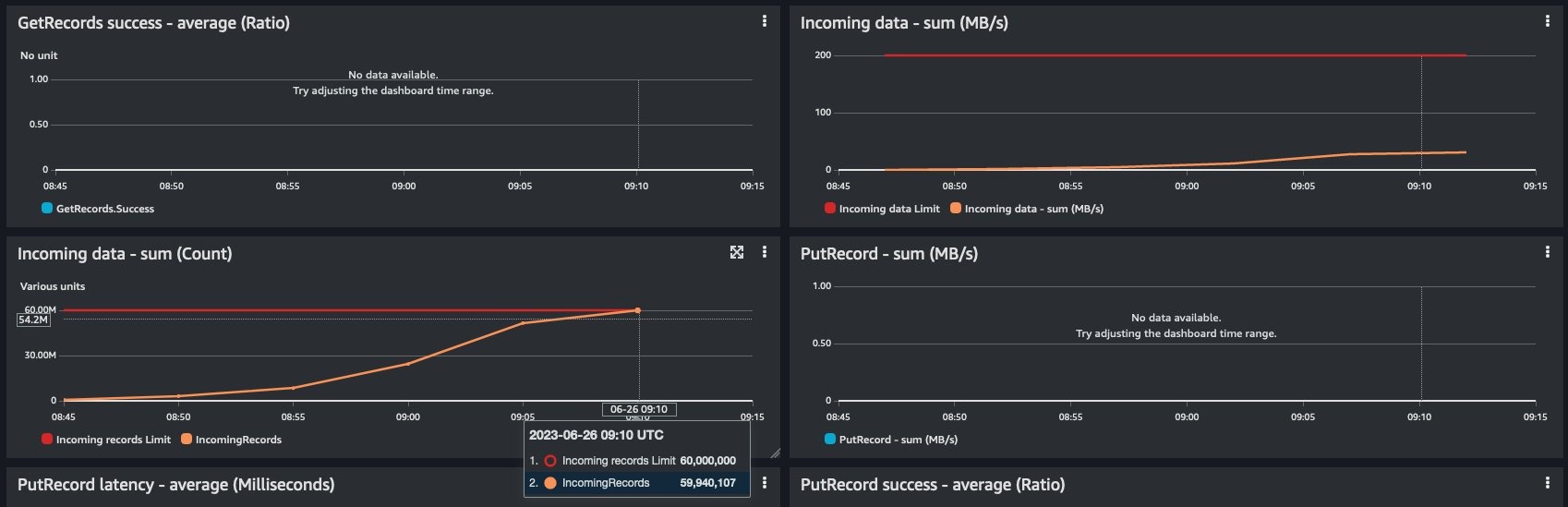
您也可以在 Kinesis 数据流的 “ 监控 ” 选项卡上观察到这一点。
清理
为了不产生任何不必要的成本,请运行以下代码删除堆栈:
摘要
Kinesis已经因其易于使用而在构建流媒体应用程序的用户中广受欢迎。借助这种使用 Locust 的负载测试功能,您现在可以更直接、更快捷地测试工作负载。访问
该项目根据Apache 2.0许可证获得许可,可以根据需要自由克隆和修改它。此外,您可以通过通过 GitHub 提交问题或拉取请求来为项目做出贡献,从而促进测试生态系统的协作和改进。
作者简介

路易斯·莫拉莱 斯在数字原生企业担任高级解决方案架构师,以支持他们在云端不断重塑自我。他热衷于软件工程、云原生分布式系统、测试驱动开发以及代码和安全的所有方面
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。