我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 SCT 将大型数据仓库从 Greenplum 迁移到亚马逊 Redshift — 第 3 部分
在这篇由多部分组成的系列文章中,我们将探讨
您可以查看本系列
无界字符数据类型
Greenplum 支持在 不指定字段长度的情况下将列创建为
文本
和
varchar
。这在 Greenplum 中可以正常运行,但在迁移到亚马逊 Redshift 时效果不佳。Amazon Redshift 以列格式存储数据,并且在使用较短的列长度时可以获得更好的压缩效果。因此,亚马逊 Redshift 的最佳做法是尽可能使用最小的字符长度。
亚马逊云科技 SCT 会将这些无界字段转换为大型对象 (LOB),而不是将这些列视为具有指定长度的字符字段。在市场上的每种数据库产品中,LOB 的实现方式都不同,但通常,LOB 不与表数据的其余部分一起存储。取而代之的是,有一个指向数据位置的指针。查询 LOB 时,数据库会自动为您重构数据,但这通常需要更多资源。
Amazon Redshift 不支持 LOB,因此,亚马逊云科技 SCT 通过将数据加载到
当前的解决方法是计算这些列的最大长度并更新 Greenplum 表,然后使用 亚马逊云科技 SCT 转换为亚马逊 Redshift。
请注意,在 亚马逊云科技 SCT 的未来版本中,统计数据的收集将包括计算每列的最大长度,无界变字符和文本的转换将自动在 Amazon Redshift 中设置长度。
以下代码是无界字符数据类型的示例:
此表在无界文本列上使用主键列。这需要转换为
varchar (n)
,其中
n
是该列中找到的最大长度。
- 删除受影响列的唯一约束: y;
- 删除受影响列的索引: ;
- 计算受影响列的最大长度: 2))、10);
请注意,在此示例中,desc
ripti on1
和 description2
列仅包含空值,或者表中没有任何数据,或者计算出的列长度为 10。
- 更改受影响列的长度:ALTER TABLE E varchar
现在,您可以继续使用 亚马逊云科技 SCT 将 Greenplum 架构转换为 Amazon Redshift,从而避免使用 LOB 来存储列值。
GitHub
如果你有很多表需要更新并且想要一个自动解决方案,你可以使用
add_varchar_lengths.sh
脚本 来修复 Greenp
请注意,该脚本还将删除受影响列的所有约束或索引。
空字符数据
Greenplum 和亚马逊 Redshift 支持在不同于 NULL 的字段中使用空字符串值。两个数据库之间的行为是相同的。但是,亚马逊云科技 SCT 默认将空字符串转换为空字符串。只需将其禁用即可避免出现问题。
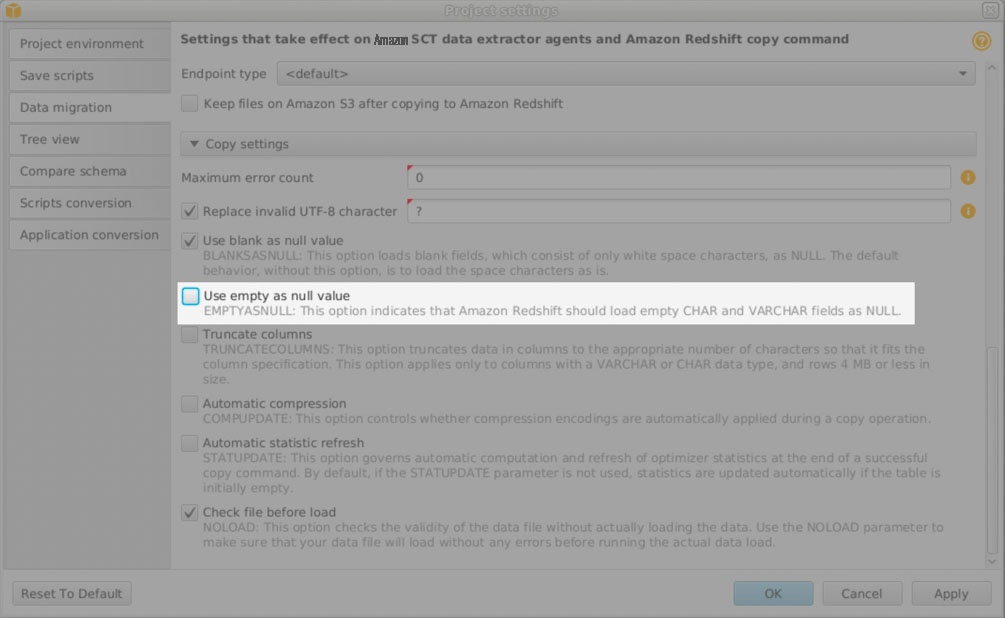
- 在 亚马逊云科技 SCT 中,打开您的项目,选择 设置 、 项目设置 和 数据迁移 。
- 滚动到底部并找到 “ 使用空值作为空值 ” 。
- 取消选择此选项以便 亚马逊云科技 SCT 不会将空字符串转换为 NULL。
NaN 和无穷大数值数据类型
Greenplum 支持在数值字段中使用 NaN 和 Infinity 来表示未定义的计算结果和无穷大。NaN 非常少见,因为在具有 NaN 行的列上使用聚合函数时,结果也将是 NaN。Infinity 也很少见,在聚合数据时也没有用。但是,您可能会在 Greenplum 数据库中遇到这些值。
亚马逊 Redshift 不支持 NaN 和 Infinity,而且 亚马逊云科技 SCT 不会在你的数据中检查这个问题。如果您在使用 亚马逊云科技 SCT 时确实遇到这种情况,则该任务将因数字转换错误而失败。
为了解决这个问题,建议使用 NULL 而不是 NaN 和 Infinity。这使您可以聚合数据并获得除 NaN 以外的结果,重要的是,还允许您将 Greenplum 数据转换为 Amazon Redshift。
以下代码是 NaN 数值的示例:
- 删除 NOT NULL 约束: 删除不为空;
- 更新表格: ';
现在,你可以继续使用 亚马逊云科技 SCT 将 Greenplum 数据迁移到亚马逊 Redshift。
请注意,在 亚马逊云科技 SCT 的未来版本中,可以选择将 NaN 和 Infinity 转换为 NULL,这样您就无需更新 Greenplum 数据即可迁移到亚马逊 Redshift。
在 GP_SEGMENT_ID 上进行虚拟分区
对于大型表,建议使用虚拟分区从 Greenplum 中提取数据。如果没有虚拟分区,亚马逊云科技 SCT 将运行单个查询来从 Greenplum 卸载数据。例如:
如果此表非常大,则提取数据将花费很长时间,因为这是查询数据的单个过程。通过虚拟分区,可以并行运行多个查询,从而更快地完成数据提取。如果任务出现问题,它还可以更轻松地进行恢复。
虚拟分区非常灵活,但是在亚马逊 Redshift 中实现虚拟分区的一种简单方法是使用 Greenplum 隐藏列 gp_segment_id。
此列标识 Greenplum 中的哪个区段有数据,每个分段的行数应相等。因此,为每个
gp_segment_id 创建分
区 是实现虚拟分区的简便方法。
如果你不熟悉该术语 细分 ,它与亚马逊 Redshift 切 片类似。
例如:
- 首先,确定 Greenplum 中的分段数量: ;
现在您可以配置 亚马逊云科技 SCT 了。
- 在 亚马逊云科技 SCT 中,转到 数据迁移视图(其他) , 然后选择(右键单击)一个大表。
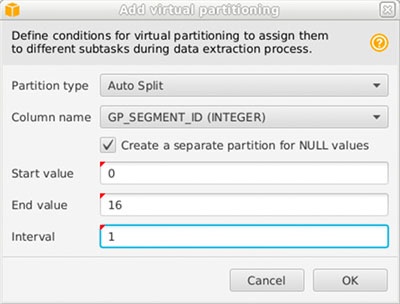
- 向下滚动到 “添加虚拟分区 ”。
-
对于分区类型,选择
自动拆
分 并将列名更改为
GP_SEGMENT_ID。 -
使用
0作为 起始值 ,在步骤 1 中找到的段数作为 结束值 ,间 隔 为1。
当您创建本地任务来加载此表时,每个
gp_segm
ent_id 值都会有一个子任务。
请注意,在 亚马逊云科技 SCT 的未来版本中,可以选择根据 GP_SE
G
MENT_ID 自动对表进行虚拟分区。此选项还将自动检索分段的数量。
数组
Greenplum 支持诸如
bigint []
之类 的无界数组。通常,在 Greenplum 中,数组保持相对较小的容量,因为 Greenplum 中的数组比使用其他策略消耗更多的内存。但是,在 Greenplum 中可能存在亚马逊 Redshift 不支持的非常大的数组。
亚马逊云科技 SCT 将 Greenplum 数组转换为
varchar (65535)
,但是如果转换后的数组长度超过 65,535 个字符,则加载将失败。
以下代码是大型数组的示例:
在此示例中,销售项目存储在每个 s
ales_
id 的数组中。如果您在加载时遇到错误,指出长度太长,无法使用 亚马逊云科技 SCT 将这些数据加载到 Amazon Redshift 中,那么这就是解决方案。在 Greenplum 和亚马逊 Redshift 中存储数据也是一种更有效的模式!
- 创建一个新的销售表,该表包含现有销售表中的所有列,但不包括数组列: );
- 使用除数组列之外的现有数据填充新的销售表: id;
我们创建了一个新表,该表将销售 ID 与销售项目交叉引用。现在,每种关系都将有一行,而不是用一行表示此关联。
- 创建新的销售项目表: );
- 要取消嵌套数组,请为每个数组元素创建一行:在 public.sales_items(sales_id、sales_it );
- 重命名销售表:
在 亚马逊云科技 SCT 中,刷新表格并迁移修改后的销售额和新的 s
ales_
items 表。
以下是之前和之后的一些示例查询。
之前:
之后:
之前:
之后:
真空分析
Greenplum 与亚马逊 Redshift 一样,支持
以下代码是 Greenplum 命令:
这不是很常见,但你会不时看到这种情况。如果你只是向表中插入数据,则无需运行 VACUUM,但为了便于使用,有时开发人员会使用 VACUUM ANALYZE。
以下是亚马逊 Redshift 命令:
Amazon Redshift 不支持将 ANALYZE 添加到 VACUUM 命令中,因此这必须是两个不同的语句。另请注意,Amazon Redshift 会自动为您执行 V
查询时区别
Greenplum 支持一种不寻常的快捷方式来消除表中的重复项。此功能根据读取数据的顺序保留每组行的第一行。看一个例子最容易理解:
我们得到以下结果:
在 Amazon Redshift 中运行此函数的解决方案是使用 ANSI 标准
row_number ()
分析函数,如以下代码所示:
清理
这篇文章中的示例在 Greenplum 中创建了表格。要删除这些示例表,请运行以下命令:
结论
在这篇文章中,我们介绍了将 Greenplum 迁移到 Amazon Redshift 时的一些边缘案例以及如何应对这些挑战,包括简单的虚拟分区、数值和字符字段的边缘案例以及数组。这并不是将Greenplum迁移到亚马逊Redshift的详尽清单,但本系列应该通过迁移到Amazon Redshift来帮助您实现数据平台的现代化。
有关更多详情,请参阅
作者简介
 乔恩·罗伯茨
是一位来自纳什维尔的高级分析专家,专门研究亚马逊 Redshift。他在关系数据库领域拥有超过 27 年的工作经验。在业余时间,他会跑步。
乔恩·罗伯茨
是一位来自纳什维尔的高级分析专家,专门研究亚马逊 Redshift。他在关系数据库领域拥有超过 27 年的工作经验。在业余时间,他会跑步。
 Nelly Susan to
是 亚马逊云科技 数据库迁移加速器的高级数据库迁移专家。她拥有超过 10 年的技术经验,专注于迁移和复制数据库以及数据仓库工作负载。她热衷于帮助客户踏上云之旅。
Nelly Susan to
是 亚马逊云科技 数据库迁移加速器的高级数据库迁移专家。她拥有超过 10 年的技术经验,专注于迁移和复制数据库以及数据仓库工作负载。她热衷于帮助客户踏上云之旅。

*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。