我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
扩展 DynamoDB:分区、热键和分割如何影响性能(第 2 部分:查询)
在本系列 的
查询
为了以任意大的速率吸引流量并模拟现实世界的行为,我们需要多个多线程客户端,每个客户端都尽可能快地进行查询调用,发送随机创建的 IP 地址。这些会消耗表所能提供的任何查询容量;其余的则受到限制。为了实现这一点,我创建了一个由
查询测试:按需表,一个分区键值
在我们的第一个测试中,我们将查询按需表,其中包含使用单值分区键设计加载的数据。我们之前看到,这种使用单值分区键会减慢我们的加载速度。现在让我们来看看它对我们的查询速度有何影响。
您可能会预期每秒 6,000 次读取的稳定速率:所有数据都在一个分区中,每个分区的最大读取速率为每秒 3,000 个读取单位,我们的每个最终一致 (EC) 查询消耗 0.5 个读取单位。因此,数学表明,对于一个非常热的节流分区,我们将实现每秒 6,000 次查询查询。实际结果完全不是这样。
下面的图 1 显示了我们在测试开始时和前 10 分钟内看到的情况。
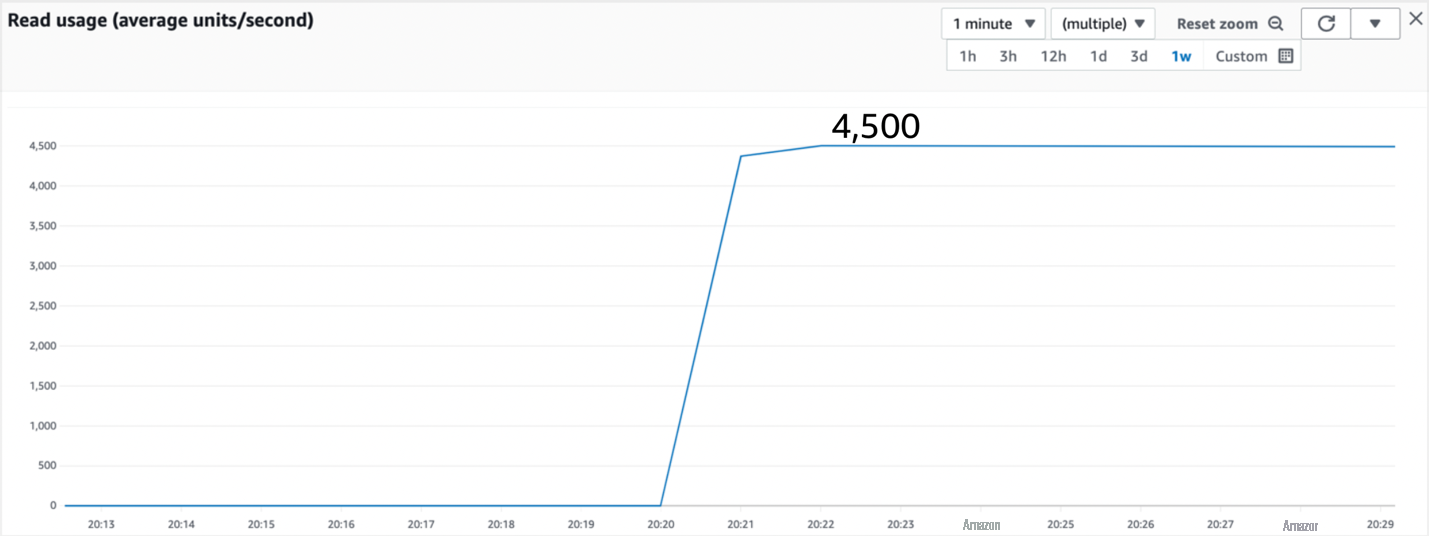
图 1:对一个具有一个分区键值的按需表的查询测试
如图 1 所示,该查询消耗了 4,500 个读取单位,相当于我们每秒 9,000 次的 EC 查询。我们超出了预期。以下是正在发生的事情:每个分区的数据分布在三个节点上以实现冗余,一个领导节点负责处理所有写入操作,两个跟随节点紧随其后。强一致性 (SC) 读取总是进入领导节点以获取最新数据。领导节点每秒可以处理 3,000 次读取,这就是分区每秒可以处理 3,000 次 SC 读取的原因。EC 读取可以进入三个节点中的任何一个。当所有三个节点都处于活动状态时,理论上一个分区每秒可以处理 9,000 次读取,这就是我们在这里找到的。在正常运行期间,有时候三个节点中的一个节点可能会在短时间内停机,例如用于内部维护,或者可能被无法回答查询的日志副本所取代。在此期间,分区每秒只能处理 6,000 次 EC 读取,这仍被视为正常行为。这就是为什么你应该在设计时假设分区每秒可以保持 6,000 个 EC 读取,尽管你有时会以每秒 9,000 个 EC 读取的速度运行。
继续执行查询弹幕,10 分钟后,吞吐量会有所提高,如下面的图 2 所示。
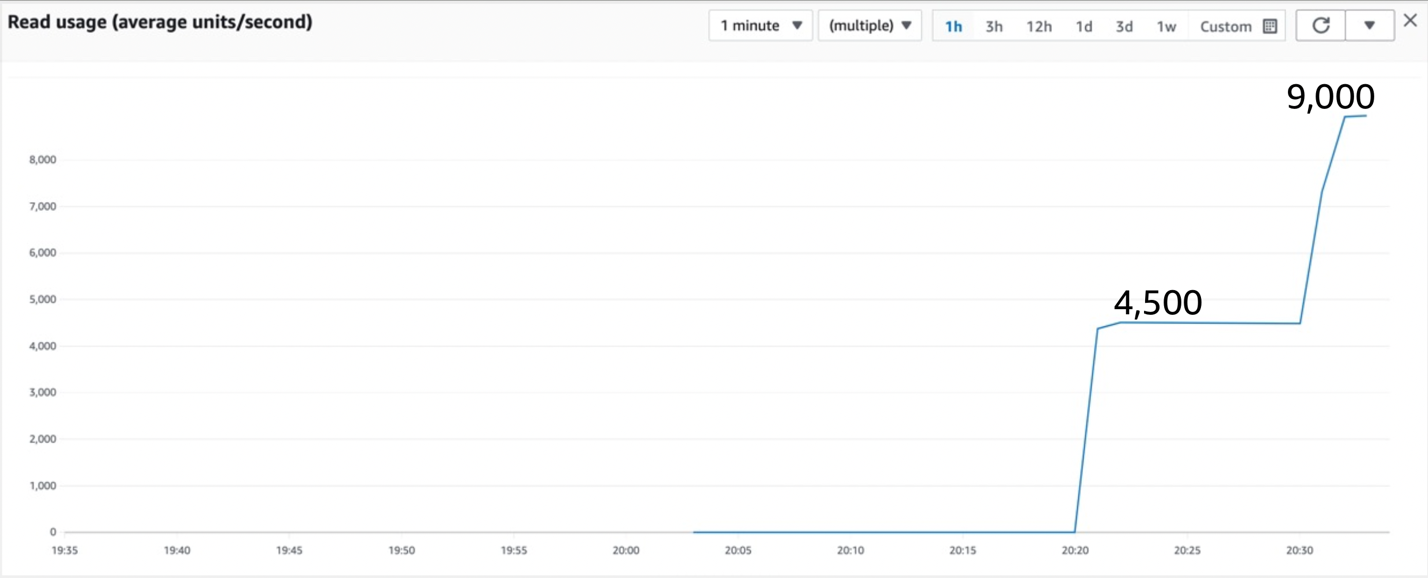
图 2:继续测试显示吞吐量翻了一番
吞吐量恰好翻了一番。DynamoDB 注意到了单个热分区,并决定将其拆分为两个新分区,使吞吐量增加一倍(且不额外收费)。
DynamoDB 具有一项称为自适应容量的功能,除其他外,该功能可以
split for heat 逻辑根据最近的流量模式选择排序键分割点,旨在将热量均匀地分布在两个新分区上。分割点很少位于精确的中心。在 IP 地址用例中,拆分的目的是分离查询次数最多的 IP 范围。
选择拆分点时,DynamoDB 必须考虑表是否具有本地二级索引 (LSI)。如果是,则分割点只能在项目集合之间(共享相同分区键的项目)。如果没有 LSI,则 DynamoDB 可以选择使用排序键值作为拆分点位置的一部分在项目集合内进行拆分。这意味着具有相同分区键的项目可能会根据其排序键值分配给不同的分区。分区键的哈希值提供了分区放置的第一部分,排序键的值进一步细化了分区布局。请注意,如果我们的 IP 表是使用 LSI 构建的,那么由于我们的单项集合无法进一步拆分,因此无法提高我们在此处的查询性能。
Split for heat 适用于读取和写入,也适用于持续高流量的任何时候。实际上,在
回到测试中。过了一会儿,我们发现吞吐量再次翻了一番,如下面的图 3 所示。
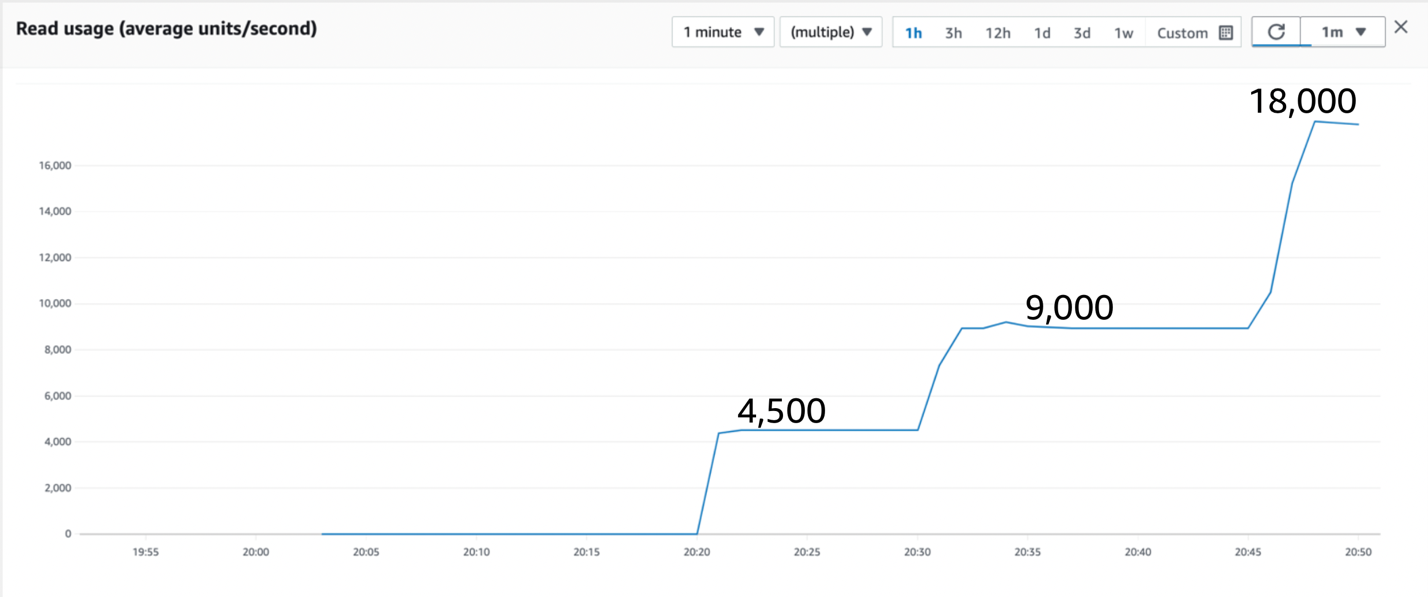
图 3:继续测试显示又翻了一番
此时,包含数据的两个分区都已拆分,现在有四个分区正在处理查询,使最大速率翻了一番。
在稳定负载下总共运行 90 分钟后,该图显示了图 4 中的模式,如下所示。
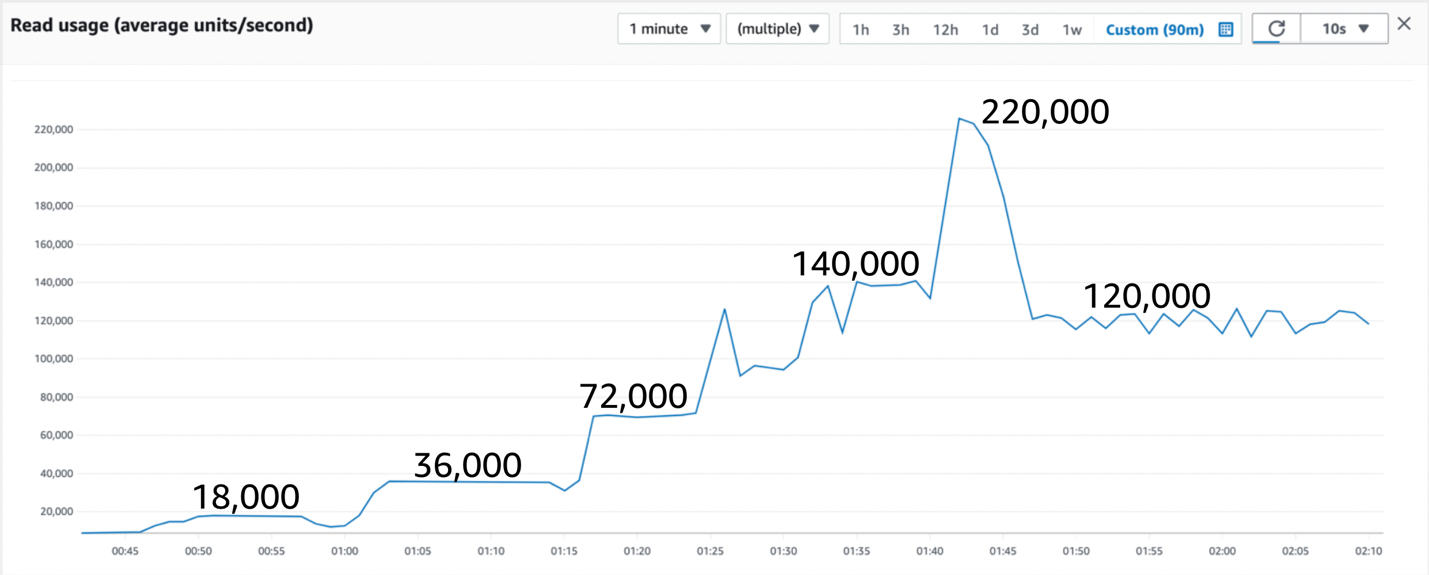
图 4:运行 90 分钟后的查询性能
图 4 中有很多值得注意的地方。初始读取速率受到分区容量限制的限制,这导致 split for Heat 反复添加分区以增加容量。大约一个小时后,分区被拆分到这样的程度,以至于没有一个分区接近其极限。
有时,作为拆分过程的一部分,查询率会暂时下降,这提醒您设计每秒 6,000 次 EC 读取,有时会观察 9,000 次。随着分区领导责任转移到新的领导节点,对于对该分区的任何写入(或强一致性读取),在分区从旧分区切换到新分区时,预计还会看到大约一秒钟的 内部服务器错误 响应。
暂时跳过中间部分,在测试的最后 30 分钟内,吞吐量最终被
表
级读取吞吐量限制限制为 120,000 个 RCU。 每个账户
现在让我们讨论中间那个奇怪的峰值。由于突发容量,吞吐量有可能在短时间内超过表的限制。
允许的突发容量是有限的(大小相当于 5 分钟的最大容量,此表的容量为 80,000*300 = 24,000,000 个读取单位),之后流量将根据表级读取吞吐量限制进行限制。
如果我们让查询负载减轻到限制以下,则突发容量将再次累积以备后用,但是查询速率始终保持在表所能支持的最大值,因此该行继续保持平稳,徘徊在表级读取吞吐量限制处。
如果我们进行 SC 读取,则每秒只能读取 80,000 次。因为我们正在进行 EC 读取,所以我们还有 50% 的读取量,使我们能够以每秒 120,000 个读取单位的速度运行,如图表所示。
这里有趣的是,即使没有特殊规划,只有一个分区键值(与最佳实践建议相反),基础架构也可以在一小时后每秒处理 440,000 次查询,而我们只受到账户相关配额的限制。
查询测试:按需表,多个分区键值
在第二个测试中,让我们遵循最佳实践建议并使用多个分区键值。我们使用新的按需表重新开始该流程,如下面的图 5 所示。我们期待什么?
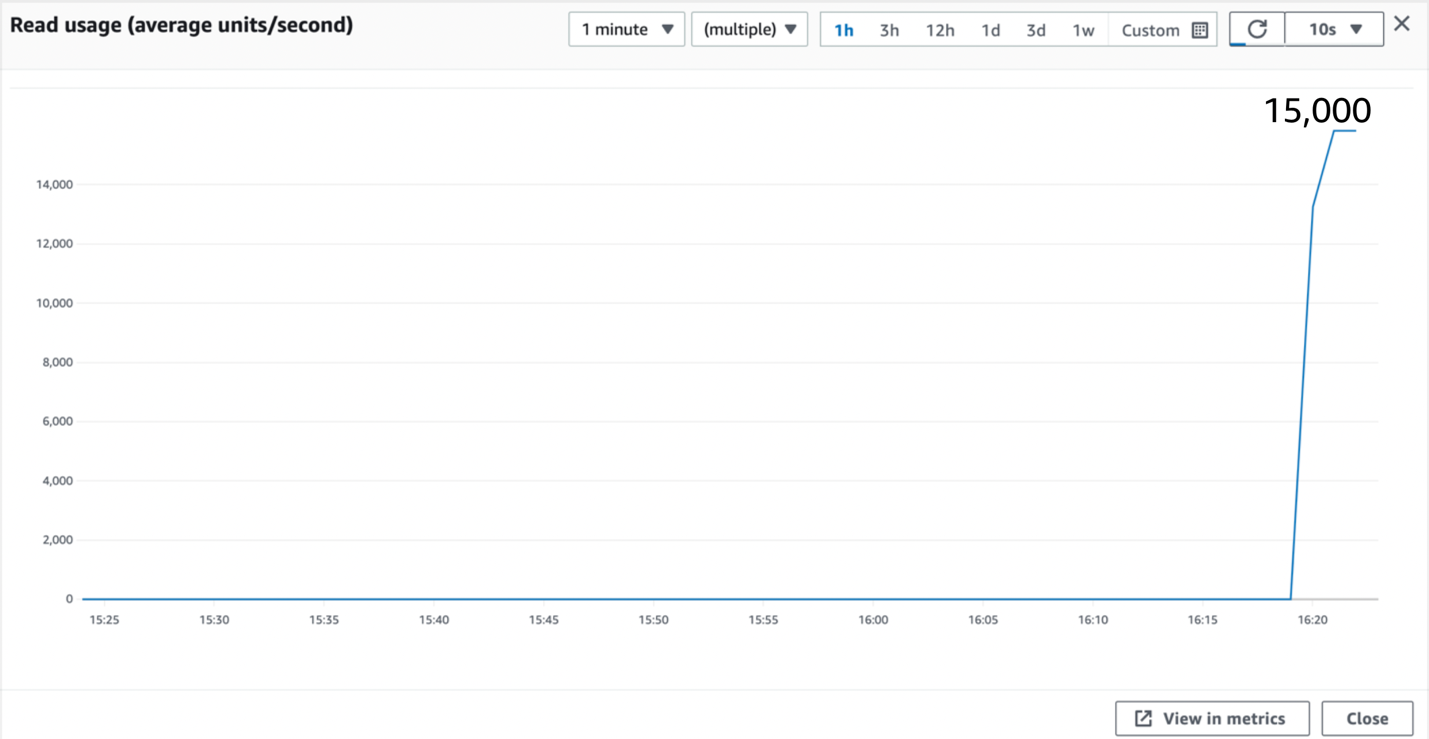
图 5:使用 200 多个分区键值进行查询测试
我们立刻实现了更高的吞吐量,约为每秒 15,000 个读取单位(30,000 次查询)。这是我们之前起点的四倍。这是有道理的,因为我们使用的是新创建的按需表中的所有四个分区。当我们保持高流量时,分区再次拆分和拆分,如下面的图 6 所示。

图 6:分区拆分允许更高的吞吐量
它与使用一个分区键的模式相同,但从四个可拆分的分区开始,而不是一个。
最终的图表看起来很像第一张图,但峰值出现在 45 分钟而不是一个小时之后,如下面的图 7 所示。
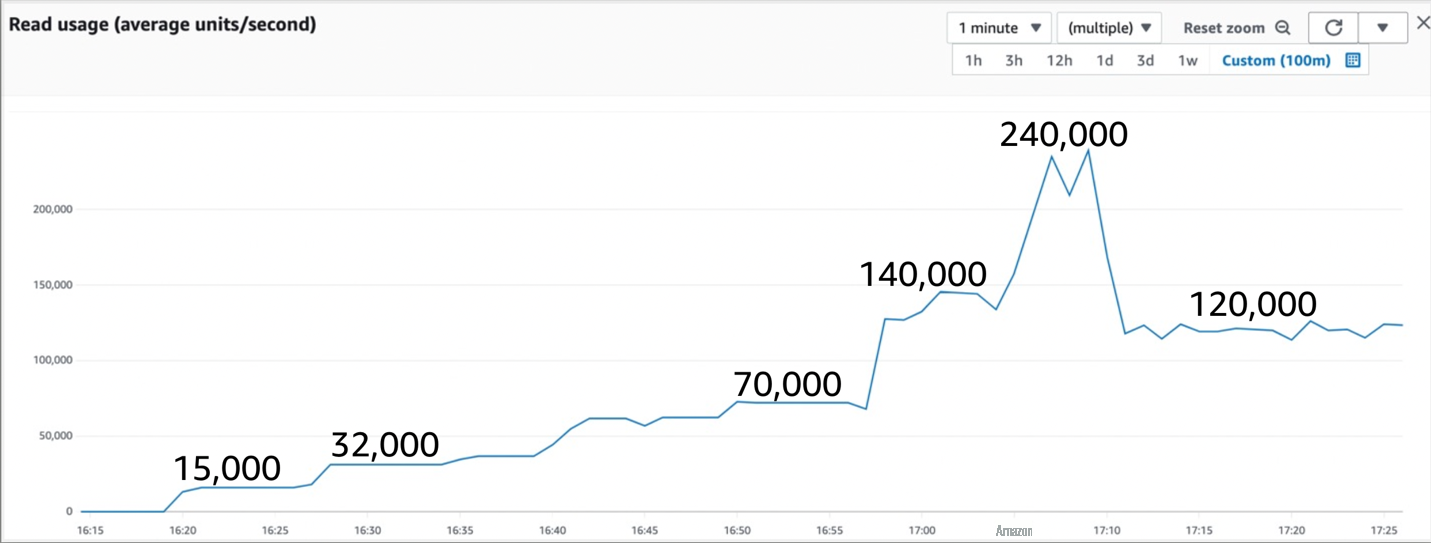
图 7:允许运行查询一小时后的吞吐量
这里的结论是,分区键的分散性比较好。扩展 200 个以上的分区键比扩展 1 个要快。
另一个结论是,由于自适应容量,在对 DynamoDB 进行基准测试时,不要假设您在前 5 分钟内看到的是一小时后看到的内容!
查询测试:每秒一百万个请求
最后,让我们做一个旨在每秒处理一百万个请求的测试。
为此,我们预置了一个包含 500,000 个读取单位的表(这需要提高默认账户配额)。对于每秒一百万次查询,这应该足够了。然后,我们可以让表处于预置状态,也可以在创建后切换到按需配置。按需表没有预置的大小信号来指导它们,因此它们通常比预置表更积极地拆分分区。但是,我们将继续为测试做好准备。原因之一是它给了我们一条漂亮的红线,显示了 500,000 个读取单位的预置吞吐量,这本质上是我们的每秒百万个请求的目标。
下图显示了我们在前 15 分钟内观察到的情况。
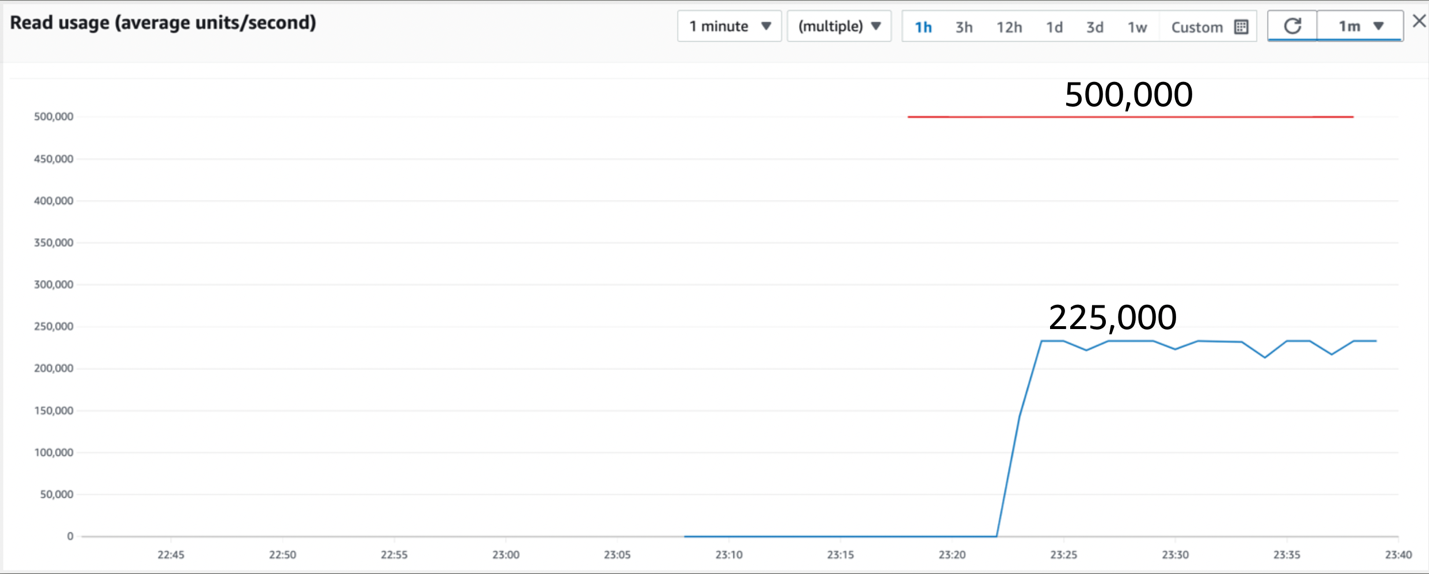
图 8:具有超过 200 个分区键值的初始读取流量,与配置为 500,000 个 RCU 的表相比
如前面的图 8 所示,最初,该表实现了大约 225,000 个读取单位或每秒 450,000 次查询。吞吐量没有在表级别上受到限制,因此我们可以推断出一些热分区限制了我们的读取吞吐量。我们是否应该找到更好的机制来将数据分布在更多的分区键值上,更均匀地分布在表的分区上?理想情况下,是的。但是,让我们测试一下如果不这样做会发生什么。
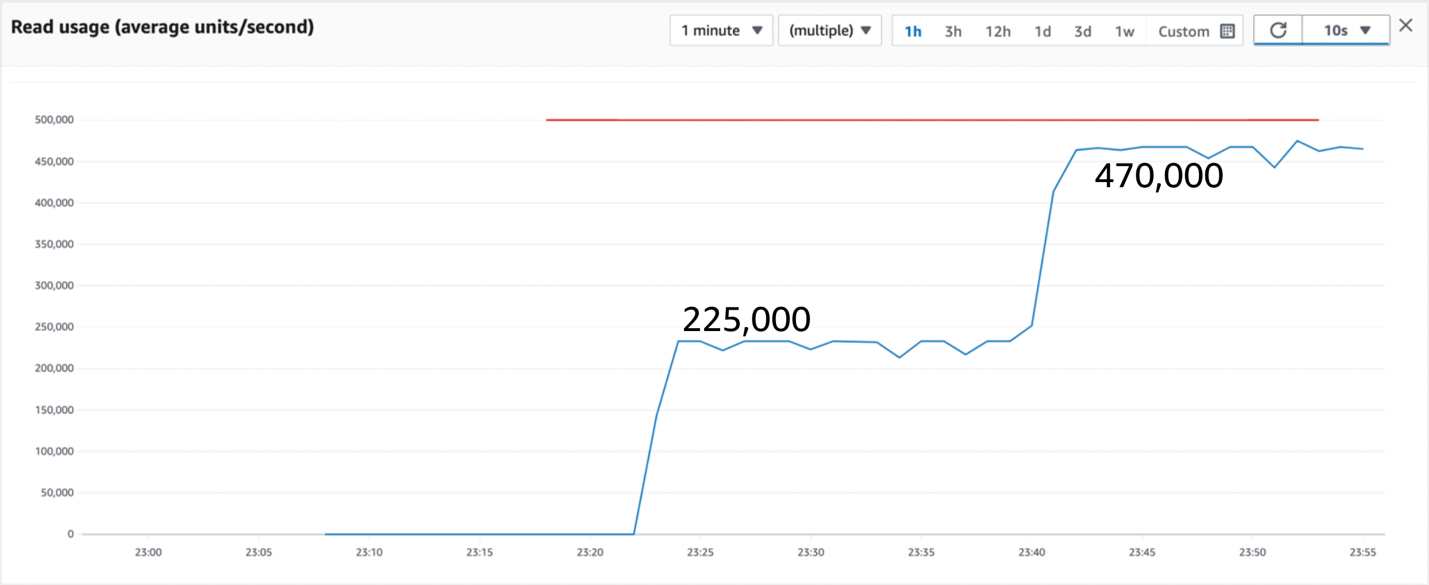
图 9:读取流量在 15 分钟后翻倍
前面的图 9 显示,split for Heat 使我们的吞吐量在 15 分钟后翻了一番,消耗 470,000 个 RCU 意味着我们每秒可实现 940,000 次最终一致查询。我们差不多达到每秒百万次查询大关。再过一个小时,我们已经生成了如图 10 所示的整体流量模式,如下所示。
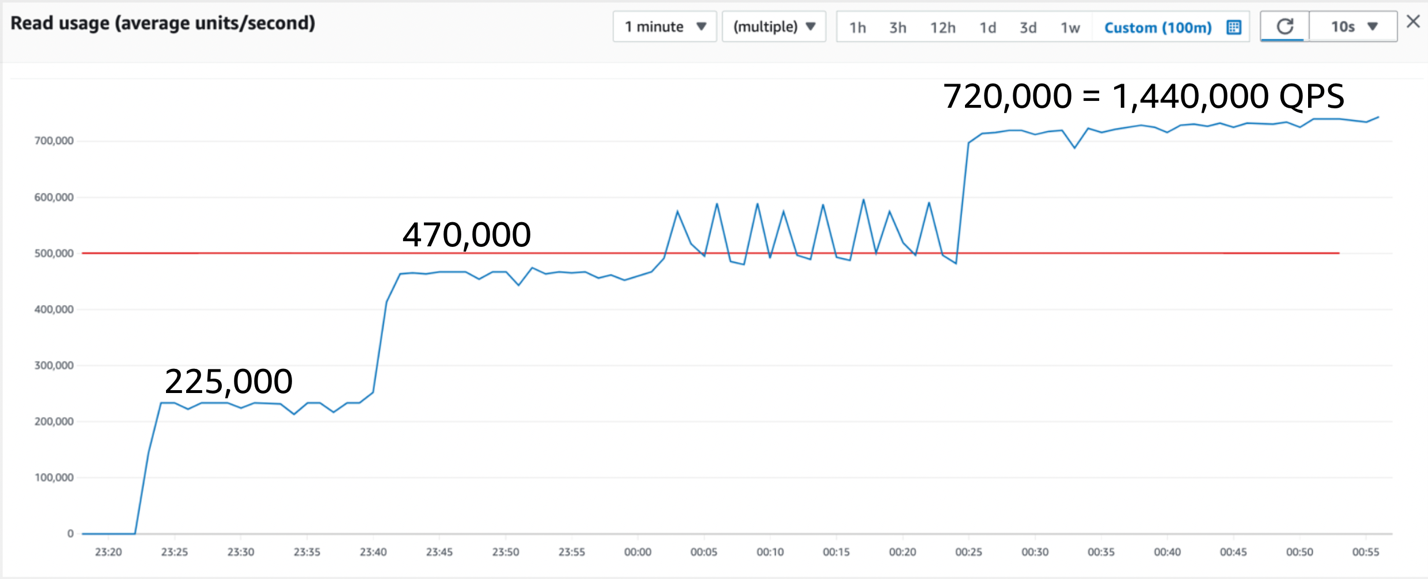
图 10:在 90 分钟内读取流量,实现每秒 1,440,000 次的稳定查询
这是每秒将近150万次查询的稳定状态。由于表级读取吞吐量限制,它只停在那里。
哦,延迟是多少?我们可以在
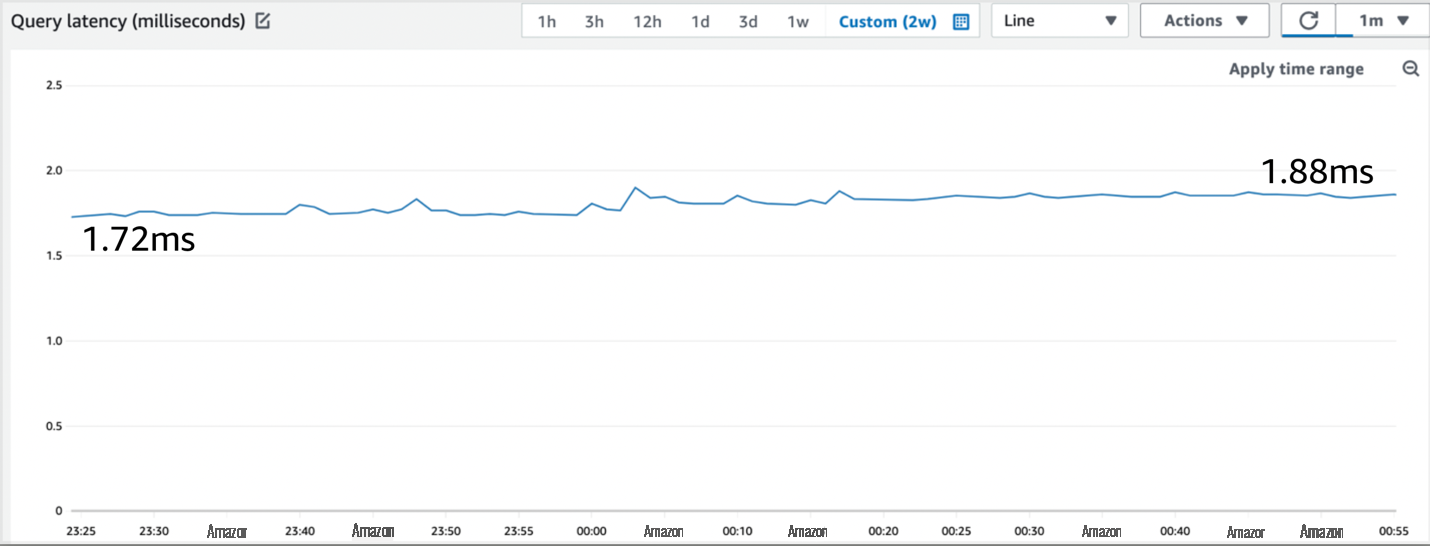
图 11:CloudWatch 的查询延迟指标
CloudWatch 报告每个查询的稳定平均值为 1.72-1.88 毫秒,即使每秒运行的查询超过一百万次。这就是稳定的大规模性能。
查询测试:摘要
如果分区持续收到读取或写入流量,DynamoDB 可能会拆分该分区。这使该分区中项目的可用吞吐量翻了一番。分割点是根据最近的流量模式计算得出理想的。如果表格中有 LSI,则分割点只能在物品集合之间。
预置表的流量可能会受到其读取或写入容量设置的限制。根据表级读取和写入吞吐量限制,按需表具有隐含的最大预置容量。这些限制可以提高。
突发容量允许流量在短暂突发时超过表的限制。
使用高基数分区键可以将项目平滑地分配给分区,并允许所有分区为表的吞吐量做出贡献。使用低基数分区键可能会在分区之间造成不均衡的工作负载。在这些情况下,分开加热可能特别有用。但是,如果存在 LSI,或者如果确定拆分没有好处,例如在编写不断增加的排序键时,则无法在项目集合中进行分割。
继续阅读
作者简介
 杰森·亨特
是加利福尼亚的首席解决方案架构师,专门研究 DynamoDB。自 2003 年以来,他一直在使用 NoSQL 数据库。他以对 Java、开源和 XML 的贡献而闻名。
杰森·亨特
是加利福尼亚的首席解决方案架构师,专门研究 DynamoDB。自 2003 年以来,他一直在使用 NoSQL 数据库。他以对 Java、开源和 XML 的贡献而闻名。
 Vivek Natarajan
是普渡大学主修计算机科学,也是 亚马逊云科技 的解决方案架构师实习生。
Vivek Natarajan
是普渡大学主修计算机科学,也是 亚马逊云科技 的解决方案架构师实习生。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。