我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
在 Amazon EKS 上使用 Amazon S3 表和 Apache Spark 优化数据湖
这篇博文由阿里特拉·古普塔(S3 高级产品经理)、瓦拉·邦图(负责人,开源软件专家解决方案架构师)、拉特诺帕姆·查克拉巴蒂(容器和开源软件高级解决方案架构师)和马纳布·麦克洛斯基(高级开源工程师)撰写。
导言
随着公司收集的信息比以往任何时候都多,管理业务数据变得越来越具有挑战性。Apache Iceberg 已成为一种受欢迎的解决方案,可帮助公司有效地组织和分析其不断扩大的数据收集。就像组织良好的图书馆系统一样,Iceberg 可以帮助企业跟踪数据,在需要时进行更新,并确保在此过程中不会丢失或重复任何内容。
尽管 Amazon S3 上的 Apache Iceberg 已成为构建数据湖库的一种广泛采用的格式,但大规模管理 Iceberg 表会带来运营方面的挑战。用户必须手动处理表优化、元数据管理、压缩和事务一致性,这可能会带来性能瓶颈和管理开销。此外,高频事务和优化查询性能需要持续调整。
为了解决这些复杂问题,Amazon S3 Tables 提供了一种完全托管的表存储服务,内置 Apache Iceberg 支持。与 Amazon S3 上的非托管 Iceberg 表不同,与存储在通用 S3 存储桶中的 Iceberg 表相比,S3 Tables 可自动进行表优化,与存储在通用 S3 存储桶中的 Iceberg 表相比,查询性能最多可提高三倍,每秒可支持多达十倍的事务量。这些优化提高了查询性能、自动维护表并简化了安全性,使用户可以专注于分析而不是基础设施管理。通过 Amazon SageMaker Lakehouse 原生集成到亚马逊云科技分析服务中,使 S3 Tables 能够为管理 Iceberg 表提供高性能、成本优化和简化的方法。
对于在 Amazon Elastic Kubernetes Service(Amazon EKS)上运行 Apache Spark 并将 Iceberg 表放在通用 S3 存储桶中的组织,S3 Tables 可简化管理并提高性能。用户可以在 Amazon EKS 上使用 Apache Spark 在 Amazon S3 上构建 Iceberg 支持的数据湖,使用 S3 表实现无缝扩展和内置维护。
这篇文章介绍了如何将 S3 表与 Amazon EKS 上的 Apache Spark 集成,演示了用户如何使用这种托管表服务在 Amazon EKS 上进行可扩展和高性能的数据分析。
建筑
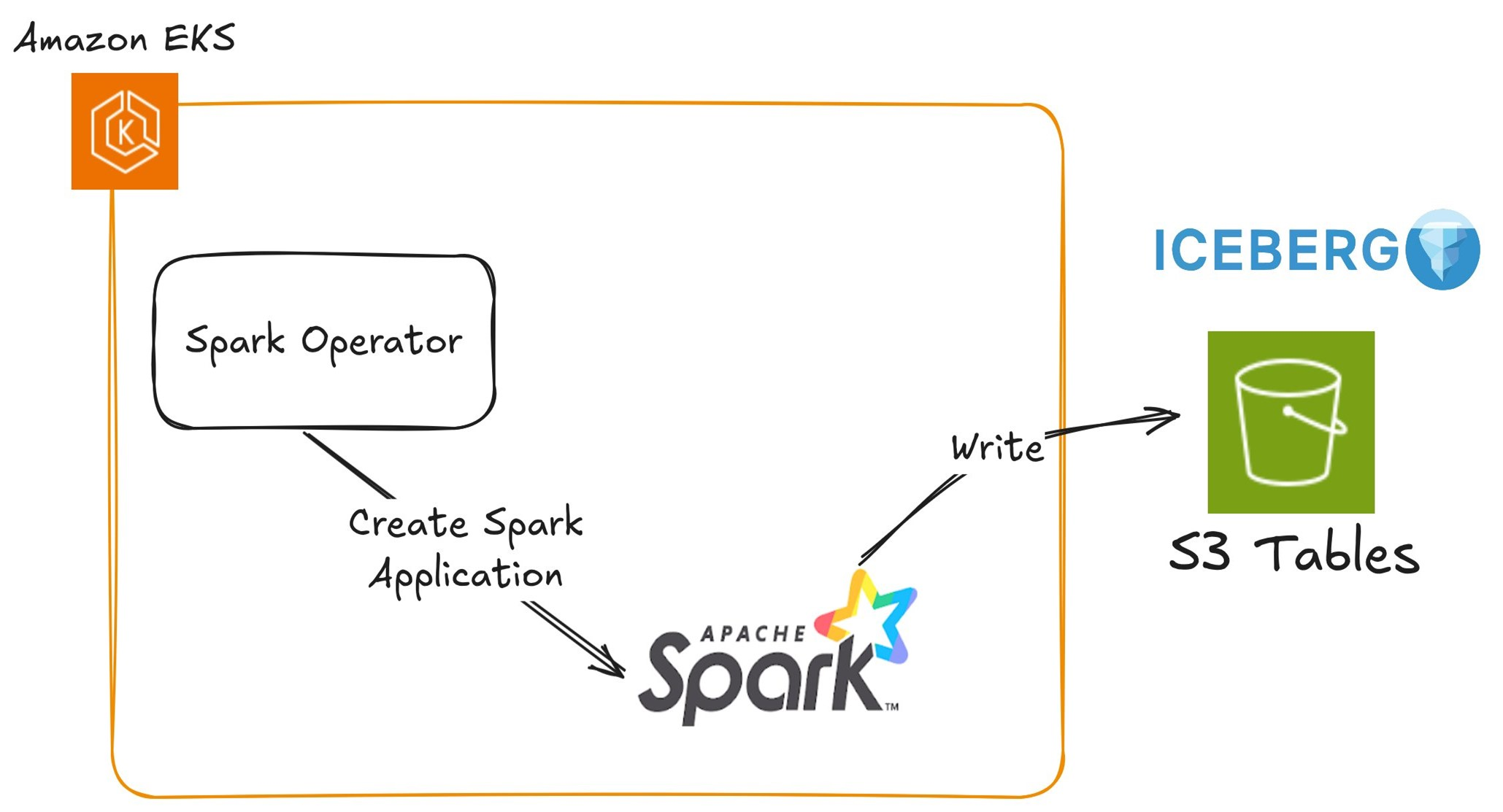
下图显示了 Amazon EKS 上的 Apache Spark 如何使用 Spark 运算符将数据写入 S3 表。Spark 操作员在 EKS 集群中部署和管理 Spark 应用程序,从而实现可扩展的数据处理。Spark 任务与 S3 表进行交互,使用内置的 Iceberg 支持来实现高效的表存储和元数据管理。服务账户 IAM 角色 (IRSA) 提供对 S3 表的安全访问,确保无缝身份验证和权限控制。
在这篇文章中,我们想演示如何在 Amazon EKS 上使用 Apache Spark 开始使用 S3 表。第一个查询检索数据文件详细信息,例如 Parquet 格式、存储位置、记录数和文件大小。第二个查询探索表历史记录,捕获快照 ID、父关系和提交时间戳以跟踪架构随时间推移而发生的变化。第三个查询列出了 Iceberg 快照,详细说明了提交的更改、操作(例如追加)和时空旅行查询的元数据,如下图所示。

冰山输出
解决方案部署
在本节中,我们将介绍如何在 Amazon EKS 上部署 Apache Spark 并将其与 S3 表集成,以实现可扩展和高效的数据处理。我们使用 EKS 蓝图上的数据配置 EKS 集群,部署开源 Kubeflow Spark 操作员,配置表存储桶,并设置 Spark 任务来写入和查询 Iceberg 表。
S3 Tables 现在支持 Apache Iceberg 的 REST 目录接口,支持通过一致的云原生方式直接通过 REST API 管理 Iceberg 表。您可以将 Iceberg REST 客户端连接到 S3 Tables Iceberg REST 端点,然后调用 REST API 来创建、更新或查询 S3 表存储桶中的表。该端点实现了 Apache Iceberg REST Catalog Open API 规范中指定的一组标准化 Iceberg REST API。该端点的工作原理是将 Iceberg REST API 操作转换为相应的 S3 表操作。
在这篇文章中,我们使用开源的 Apache Spark。但是,您也可以使用 Amazon Glue 冰山 REST 终端节点来执行相同的任务。
先决条件
确保在计算机上安装了以下工具:
- 亚马逊云科技命令行界面 (亚马逊云科技 CLI)
- kubectl
- Terraform
第 1 步。创建 EKS 集群
要简化部署,请使用基于 Terraform 的 Data on EKS 蓝图。此蓝图可自动配置以下组件:
- VPC 和子网:Amazon EKS 的网络基础设施。
- EKS 集群:用于运行 Spark 工作负载的 Kubernetes 控制平面。
- Karpenter:用于动态配置计算节点的自动扩缩器。
- Spark 操作员:管理 Kubernetes 上的 Spark 应用程序。
- Prometheus 和 Grafana:用于监控和指标可视化。
- FluentBit:用于日志聚合和转发。
克隆存储库。
导航到示例目录并运行 install.sh 脚本。
该 install.sh 脚本大约需要 15 分钟才能完成执行。完成后,您应该看到类似于以下内容的输出:
记下 S3 存储桶 ID。创建一个环境变量 S3_BUCKET,用于保存安装期间创建的存储桶的名称。此存储桶稍后用于存储示例数据。
第 2 步。设置 S3 表
在此步骤中,您将创建一个存储 Iceberg 表格的表存储桶。我们在 Amazon EKS 上运行的 PySpark 任务使用此存储桶来读取和写入数据。
运行以下命令来创建表存储桶。<S3TABLE_BUCKET_NAME> 替换为所需的存储桶名称和您 <REGION> 的亚马逊云科技区域。
命令执行时,它会生成一个表存储桶亚马逊资源名称 (ARN)。请注意这个 ARN,因为这是 Spark 任务配置所必需的。
第 3 步。为 Spark Job 创建测试数据
在 Amazon EKS 上运行 Spark 任务之前,您需要对示例数据进行处理。在此步骤中,您将生成写入 S3 表的测试数据集。
此脚本 employee_data.csv 在您的当前目录中创建名为的文件。默认情况下,它生成 100 条记录。
如果您需要调整记录数量,则可以修改 input-data-gen.sh 脚本。寻找生成数据的循环,并根据需要更改迭代次数。
第 4 步。将测试数据上传到 S3 存储桶
<YOUR_S3_BUCKET> 替换为您的蓝图创建的 S3 存储桶的名称,然后运行以下命令。
此命令将 CSV 文件上传到您的 S3 存储桶。Spark 作业稍后引用此路径来读取输入数据。在执行命令之前,请确保您拥有写入此存储桶的必要权限。
第 5 步。将 PySpark 脚本上传到 S3 存储桶
我们创建了一个 PySpark 脚本 (s3table-iceberg-pyspark.py) 来配置 Apache Spark 以使用 S3 Tables 进行数据处理。它从通用 S3 存储桶读取输入 CSV 文件,将处理后的数据作为 Iceberg 表写入 S3 Tables 存储桶,然后对其进行查询以验证数据。
运行以下命令,<S3_BUCKET> 替换为您在前面的步骤中创建的 S3 存储桶名称。这可确保脚本可在 Amazon EKS 上运行的 Spark 任务中执行。
第 6 步。更新 Spark 操作员清单
更新 s3table-spark-operator.yaml 文件以配置 Spark 作业:
- 替换
<S3_BUCKET>为 Terraform 输出中的 S3 存储桶名称。 <S3TABLE_ARN>替换为之前捕获的 S3 表 ARN。
这可确保 Spark 任务从 Amazon S3 读取数据,写入 S3 表,并使用正确的配置在 Amazon EKS 上运行。
第 7 步。执行 Spark 作业
在运行读取和写入 S3 表的 Spark 任务之前,你需要一个具有必要依赖关系的 S3 表的 Spark Docker 镜像(Dockerfile-S3Table)。
要使用 Spark 与 S3 表进行通信,Docker 镜像必须包含以下内容:
- Hadoop 亚马逊云科技连接器和依赖关系:启用 Spark 的 S3A 文件系统支持。
- Apache Iceberg 运行时;提供 Iceberg 表管理功能。
- 亚马逊云科技开发工具包套装:与亚马逊云科技交互所必需的。
自定义和使用图像
你可以使用这些依赖关系构建自己的 Docker 镜像,并将其推送到容器注册表(例如亚马逊弹性容器注册表 (Amazon Elastic Container Registry (Amazon ECR))。但是,为了简化此流程,我们预先构建并发布了容器镜像,Spark Operator YAML 文件中引用了该镜像。
运行 Spark 作业
应用更新后的 Spark Operator YAML 来提交和执行 Spark 作业:
这会在 EKS 集群上调度 Spark 作业。Spark Operator 负责将任务提交到 Kubernetes API 服务器。Kubernetes 调度 Spark 驱动程序和执行器 pod 在单独的工作节点上运行。如果需要,Karpenter 会根据节点池配置自动配置新节点。提交 Spark 作业时,它会创建驱动程序和执行器 Pod 来进行处理。您可以按如下方式检查 Spark Pod 的状态:
当执行器 Pod 成功完成处理时,它将被终止,最终驱动程序 Pod 的状态变为 Completed。
第 8 步。检查 Spark 驱动程序日志
列出在 spark-team-a 命名空间下运行的 pod:
此外,验证 Spark 驱动程序日志以查看 Spark 作业的完整输出。该作业从 S3 存储桶读取 CSV 数据,并使用 Iceberg 格式将其写回表存储桶。它还计算处理的记录数并显示前 10 条记录:
第 9 步。使用 S3 表 API 检查 S3 表
确认 Iceberg 表已使用 S3 Tables API 成功创建。将 <ACCOUNT_ID> 和 <REGION> 替换为您的详细信息,然后运行以下命令:
在幕后,它调用 GetTable API。有关详细信息,请参阅 GetTable 和 GettableBucket API 参考。
你应该看到以下输出:
这证实了 Spark 任务成功地以 Iceberg 格式将数据写入了 S3 表。
JupyterHub 的设置和执行
如果您想以交互方式使用 S3 表,那么该蓝图包括一种在集群内的单用户配置中启用 JupyterHub 的方法。要启用它,请创建一个 Terraform 变量文件并将 enable_jupyterhub 值设置为 true。
⚠️ 警告:此配置仅用于测试目的。
配置和访问 JupyterHub Web 界面
- 通过创建 Terraform 变量文件来启用 JupyterHub:
- 验证 JupyterHub 部署已准备就绪。准备就绪后,此命令应返回 1。
- 使 JupyterHub Web 界面在本地可用。
访问 JupyterHub
- 导航至
http://localhost:8888. - 输入任何用户名,将密码字段留空,
- 选择 "登录"。
选择您的环境:
- 选项 1:支持 S3 表格的 PySpark 镜像。
- 选项 2:基本 PySpark 镜像(需要安装更多库:转到这个 Dockerfile)。
选择 "开始"。服务器需要几分钟才能准备就绪。
为 S3 表配置 Spark
要为 S3 表配置 Spark,请按照文档进行操作。
在 Amazon EKS 环境中,我们建议使用
WebIdentityTokenFileCredentialsProvider(IRSA) 或 ContainerCredentialsProvider(Pod Identity)。
你可以浏览 JupyterLab 笔记本 s3table-iceberg-pyspark.ipynb 示例,在 S3 表上交互式运行 Spark 查询。
在 S3 表上执行 Iceberg 查询
现在您已经将数据加载到表中,向表中添加新列并进行一次时空旅行以返回到表的先前状态。
步骤 1:修改 employee_s3_table 中的 doeks_namespace 并添加一个名为的新列 is_manager。
第 2 步:提取表的前五行以验证该表是否已更改。
输出应如下所示,这表明新列 is_manager 已添加到表中(值为 NULL)。
第 3 步。为 "新添加" 列更新所有值为 Y 的行。然后,检索行以验证更新操作的结果。
输出如下所示,它确认行已使用该 is_manager 列 Y 的值进行了更新。
第 4 步。测试该 Time travel 功能。从之前的快照中查询表。此快照中没有您在修改表时新创建的列。
首先,查看快照历史记录
回到 ALTER 表操作之前的状态。输出不显示任何 is_manager 列。
查询最新的快照,其中新插入的列可 is_manager 用。
清理为了避免向您的亚马逊云科技账户收取不必要的费用,请删除在此次部署期间创建的所有亚马逊云科技资源。
删除该表:
删除命名空间:
删除表桶:
删除包含所有基础设施的 EKS 集群:
结论
在这篇文章中,我们演示了如何将 Amazon S3 表与在 Amazon EKS 上运行的 Apache Spark 相集成。我们介绍了从集群设置到执行使用 S3 Tables 功能的 Spark 任务的工作流程。使用 Iceberg REST 目录终端节点,我们展示了如何执行架构演变和时空旅行查询,演示了在 Amazon EKS 上将 S3 表与 Apache Spark 结合时可用的强大功能。
这种集成使数据团队能够构建可扩展且高效的分析工作流程,同时受益于查询性能的提高和成本优化。无论您是处理批量数据还是通过 JupyterHub 执行交互式分析,在 Amazon EKS 上将 S3 表与 Apache Spark 相结合,都能为现代数据处理需求提供坚实的基础。
今天就开始吧!
探索 Amazon S3 表格以及它们如何增强您的分析工作量。
按照 EKS 蓝图上的数据,使用 S3 Tables 设置在 Amazon EKS 上部署你自己的 Apache Spark。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。