我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用可观测性控制面板优化您的 亚马逊云科技 Batch 架构以实现扩展
亚马逊云科技 Batch 是一项完全托管的服务,使您无需管理计算资源即可运行任何规模的计算任务。客户经常要求提供指导,以优化其架构并使用该服务使其工作负载快速扩展。每个工作负载都不同,有些优化可能不会在每种情况下产生相同的结果。为此,我们构建了一个
在这篇博客文章中,您将了解 亚马逊云科技 Batch 是如何工作的:
- 扩展亚马逊弹性计算云 (Amazon EC2) 实例以处理任务。
- 亚马逊 EC2 如何为 亚马逊云科技 Batch 预置实例。
- 如何利用我们的可观察性解决方案在 Batch 的掩护下窥视您的架构。
这篇博文中的知识适用于 Amazon EC2 上的常规任务和数组任务,这里不讨论利用 亚马逊云科技 Fargate 资源的 亚马逊云科技 Batch 计算环境和多节点并行任务。
亚马逊云科技 Batch:实例和任务如何按需扩展
要在 亚马逊云科技 Batch 上运行任务,您需要将其提交到批处理任务队列 (JQ),该队列管理任务的生命周期,从提交接收到发送再到跟踪返回状态。提交后,作业处于 “
已提交
”
RUNNABLE
状态,这意味着它已准备就绪,可以安排执行。
AWS Batch 调度器服务会定期查看您的任务队列并评估可运行任务的需求(vCPU、GPU 和内存)。
基于此评估,该服务确定是否需要扩展相关的批处理计算环境 (CE) 以处理队列中的作业。
一旦 Amazon EC2 创建了实例,它们就会
RUNNAB
LE 中等待 并安装空闲资源的作业将过渡到容器
启动
期间的 STARTING 状态。容器执行后,作业将转换为 RUNNIN
G
状态。它会一直保持在那里,直到成功完成或遇到错误。当没有任务处于
RUNNABLE 状态且
实例处于空闲状态时,亚马逊云科技 Batch 会将该实例从计算环境中分离,并请求 Amazon ECS 从集群中
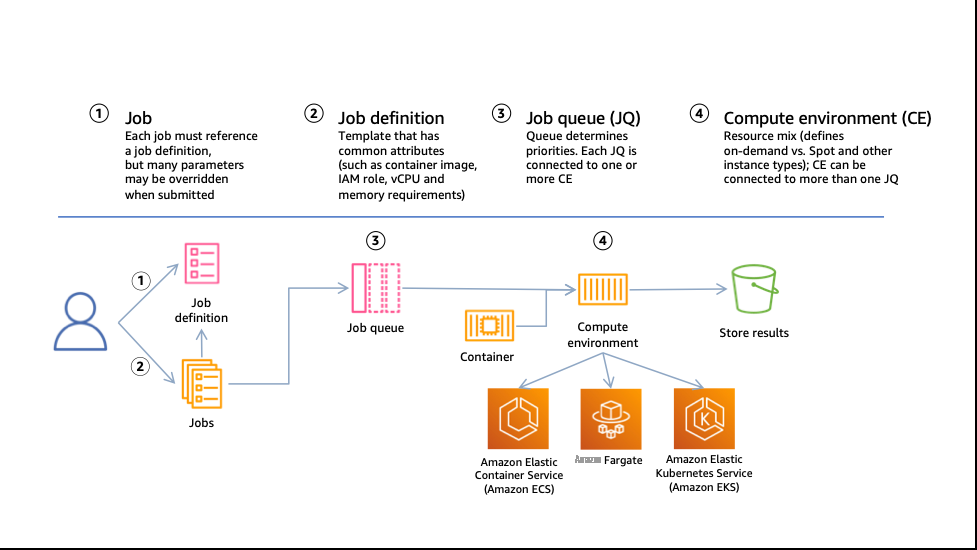
图 1:亚马逊云科技 Batch 资源和交互的高级结构。该图描绘了用户根据作业定义模板向作业队列提交任务,然后该队列向计算环境传达需要资源的信息。计算环境资源可扩展 Amazon EC2 或 亚马逊云科技 Fargate 上的计算资源,并将其注册到容器编排服务,即亚马逊 ECS 或亚马逊弹性 Kubernetes 服务 (Amazon EKS)。在这篇文章中,我们仅介绍带有 EC2 实例的 Amazon ECS 集群。
将任务放置到实例上
在 CE 向上和向下扩展的同时,亚马逊云科技 Batch 不断要求亚马逊 ECS 通过调用
如何预置实例
您已经看到 亚马逊云科技 Batch 是如何请求实例的,我们现在将讨论如何配置实例。实例配置由 Amazon EC2 处理,它根据 亚马逊云科技 Batch 生成的列表和创建 CE 时
使用名为 B
EST_FIT
(BF) 的分配策略,亚马逊 EC2 选择最便宜的实例,BEST_F
IT_PROGRES
SIVE (BFP) 选择最便宜的实例,如果之前选择的类型不可用,则选择其他实例类型。以
SPOT_CAPACITY_OPTIMIZED
为例 ,亚马逊 EC2 Spot
为什么要在您的计算环境中优化 Amazon EC2 实例选择?
了解 亚马逊云科技 Batch 如何选择实例有助于优化环境以实现您的目标。您通过 亚马逊云科技 Batch 获得的实例是根据任务数量、任务的形态(vCPU 数量和所需内存量)、分配策略和价格来挑选的。如果它们的要求较低(1-2 个 vCPU,<4 GB 内存),那么您很可能会从 Amazon EC2(即 c5.xlarge)获得小型实例,因为它们经济实惠且属于最深的竞价型实例池。在这种情况下,您可以为 每个 ECS 集群(位于每个计算环境下方)预置
亚马逊云科技 Batch 环境的可观性很重要的另一个例子是,当作业在运行时需要存储暂存空间时。
这可能是由于每个实例打包的作业数量较多,这将消耗您的
Error 而在较大的实例上崩溃。
为了帮助您了解和调整您的 亚马逊云科技 Batch 架构,我们在 GitHub
我们将详细讨论这个可观测性解决方案,并演示如何使用它来了解在给定工作负载下计算环境的行为。此处提供的示例可以使用 Amazon CloudFormation 模板部署到您的账户上。
亚马逊云科技 Batch 可观测性解决方案
这款适用于 亚马逊云科技 Batch 的开源
SAM 应用程序架构
SAM 应用程序使用 CloudWatch 事件从您的 亚马逊云科技 Batch 环境中收集数据点。根据其性质,这些事件会触发
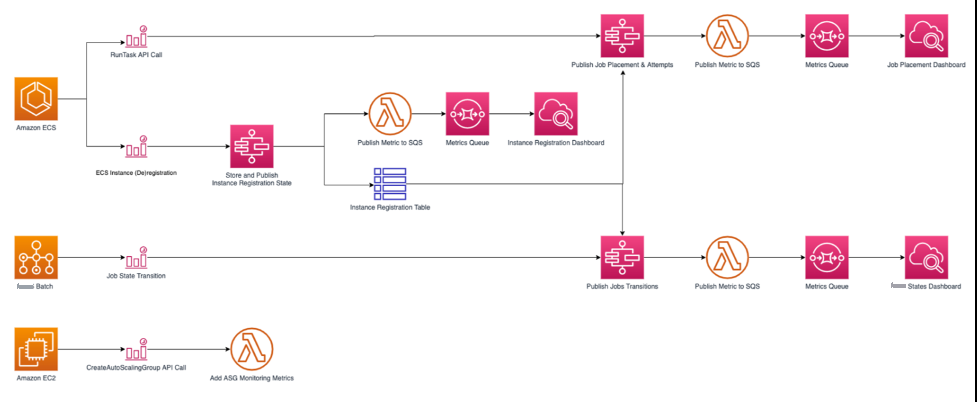
图 2:SAM 应用程序架构。该图描述了如何收集亚马逊 ECS、亚马逊云科技 Batch 和 Amazon EC2 发出的不同 API 调用并将其显示在控制面板中。Amazon ECS 对 RunTask API 调用和 EC2 实例注册/取消注册进行了监控,这会触发 亚马逊云科技 Step Functions,触发 亚马逊云科技 Lambda 将指标发布到队列,然后发布到相应的控制面板。亚马逊云科技 Batch 具有任务状态转换触发器步骤函数,可在控制面板的过渡中发布。亚马逊 EC2 的 createAutoscalingGroup API 调用使用 Lambda 来监控自动扩展组指标。
在 亚马逊云科技 Batch 中使用亚马逊 CloudWatch 事件
此解决方案仅使用服务生成的事件,而不是调用
无服务器应用程序捕获的事件如下:
-
ECS 容器实例
注册 和取消注册 :当实例达到 RUNNING 状态时,它将自己注册到 ECS,成为运行作业的资源池的一部分。删除实例后,它会取消注册,ECS 将不再使用它来运行作业。这两个 API 调用都包含有关实例种类、其资源(vCPU、内存)、实例所在的可用区、ECS 集群和容器实例的 实例 注册状态的信息,这些信息收集在 Amazon DynamoDB 表中,用于确定使用容器实例 ID 的任务使用的 EC2 实例、可用区域和 ECS 集群。 -
批处理使用
RunTask API 调 用来请求在实例上放置作业。如果成功,则会找到一份工作。如果返回错误,则原因可能是缺少可用的实例或资源(vCPU、内存)来执行任务。在 Amazon DynamoDB 表中捕获调用,以将批处理作业与其运行的容器实例关联起来。 -
当@@
作业在状态之间 转换 时,批处理 作业状态转换 会 触发事件 。移至 “正在运行” 状态时,会将jobID与 ECS 实例和 runTask DynamoDB 表进行匹配,以识别作业的运行位置。
在进入下一节之前,必须在您的账户上部署无服务器应用程序。如果您尚未这样做,请按照
了解您的批处理架构
现在您可以可视化 亚马逊云科技 Batch 如何获取实例和部署任务,我们将使用这些数据来评估实例选择对测试工作负载的影响。
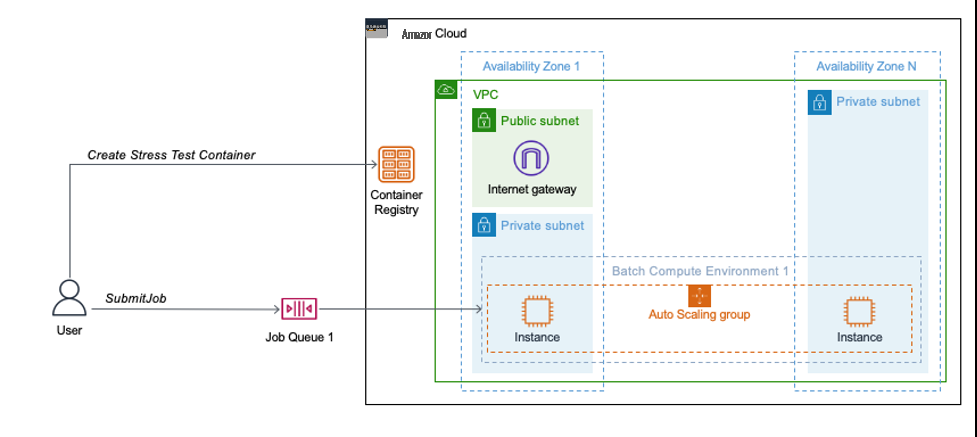
图 3:用于测试工作负载的 亚马逊云科技 Batch 架构。该图描述了由 亚马逊云科技 CloudFormation 模板部署的环境。VPC 堆栈在 2 个或更多可用区中部署 VPC。在一个可用区中,您既有公有子网,又有私有子网,在其余可用区中只有私有子网。互联网网关是在公有子网中创建的。批处理堆栈创建了 Amazon 弹性容器注册表、任务队列和跨私有子网的计算环境。
了解您的计算环境的实例选择
创建
在此
CE1
配置 为从 c5、c4、m5、m4 Amazon EC2 实例系列中挑选实例,无论实例为何,并使用
测试
在 CE1 上运行和可视化您的工作负载
当您的工作负载运行时,请在仪表板上查看 vCPU 和实例容量 bat ch-ec2 容量。在下面的运行中,CE 获取了最多 766 个实例,并提供了 2,044 个 vCPU 的峰值。它还表明,运行 1,000 个作业需要 18 分钟。此运行时间可能因获取的实例数量而异。仪表板反映了运行快要结束时丢失的一些数据,但它对作业的处理没有影响。
控制面板 Batch-ECS-runtaskJobs Placed (图 4)有 2 张图,您可以在其中比较批处理 请求的 所需容量 和 ECS 维护的服务中容量。 当工作负载处于最佳状态时,它们应该紧密地相互映射。
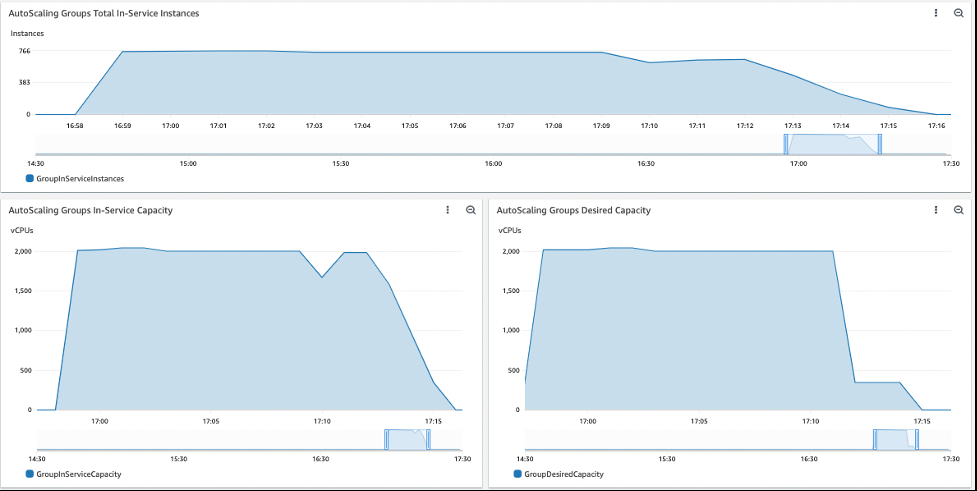
图 4:仪表板 bat ch-ecs-runtaskJobsPlaced
要确定哪些实例类型已启动、在哪个可用区启动以及它们何时加入 ECS 集群,请打开控制面板
Batch-ECS-InstancesRegistration
(图 5)。 在本例中,获取的实例是 c5.large、c5.xlarge、c5.2xlarge、c4.xlarge,因为它们都可以容纳作业,并且是由
SP
OT_CAPACITY_OPTIMIZED 分配策略选择的,因为它们属于最深的可用实例池。
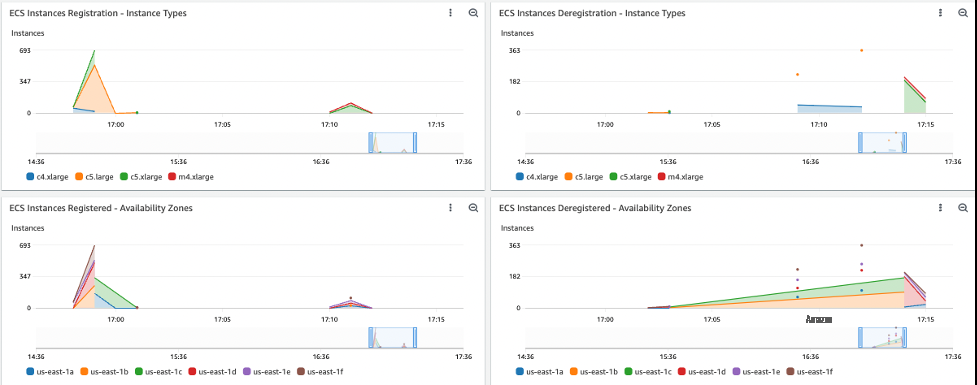
图 5:控制面板 批 处理 ECS 实例注册
仪表板
批处理作业放置
(图 6)显示何时将任务放到实例上(将状态从
在这次运行中,峰值任务放置率为每分钟 820 个任务。
RUNNABLE 移 至 RUNNING )、在哪个实例类型上以及在哪个可用
区中。
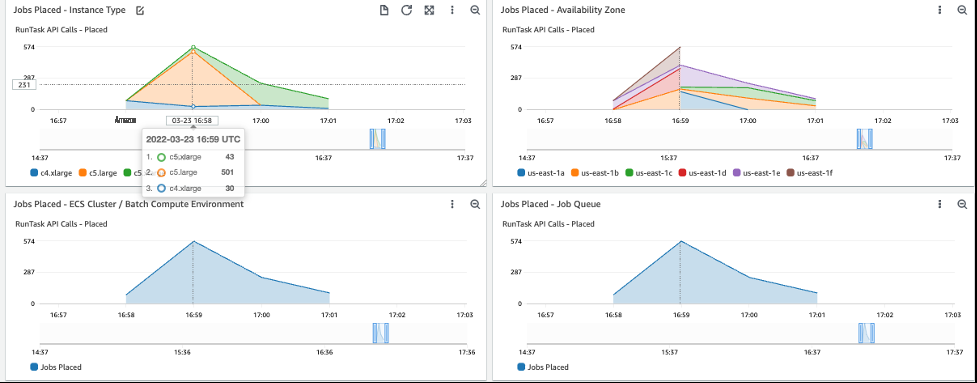
图 6:仪表板 批量作业布局
还有其他情节和仪表板可供探索。通过花时间以这种方式研究工作负载控制面板,您可以根据这些 CE1 设置了解 亚马逊云科技 Batc h 的行为。通过修改设置或运行不同的工作负载,您可以继续使用这些仪表板来更深入地了解每个工作负载的行为。
摘要
在这篇博客文章中,你学习了如何使用运行时指标来了解给定工作负载的 亚马逊云科技 Batch 架构。随着工作负载的扩展,更好地了解您的工作负载可以带来许多好处。
医疗保健和生命科学、媒体娱乐和金融服务行业的几位客户已使用此监控工具,通过重塑任务、优化实例选择和调整 亚马逊云科技 Batch 架构来优化其工作负载以实现大规模扩展。
您还可以使用其他工具来跟踪基础设施的行为,例如
要开始使用 亚马逊云科技 Batch 开源可观察性解决方案,请访问 GitHub
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。