我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 Graviton 处理器优化了 PyTorch 2.0 的推断
由于采用了专门的内置指令,新一代 CPU 显著提高了机器学习 (ML) 推理的性能。结合其灵活性、高速开发和低运营成本,这些通用处理器为其他现有硬件解决方案提供了替代方案。
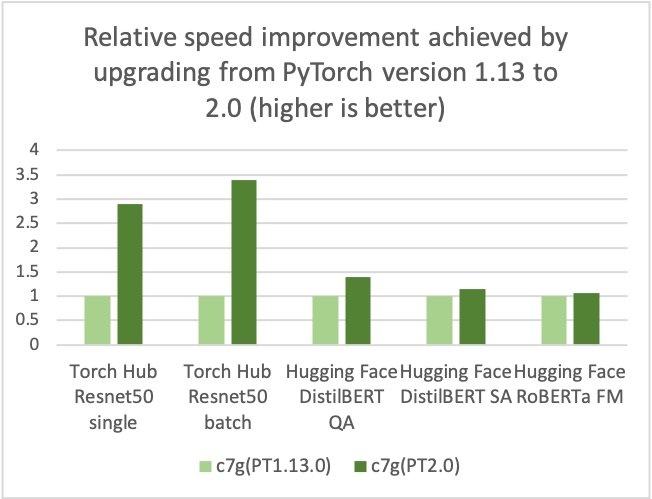
亚马逊云科技、Arm、Meta 等公司帮助优化了基于 ARM 的处理器的 PyTorch 2.0 推理性能。因此,我们很高兴地宣布,PyTorch 2.0的基于亚马逊云科技 Graviton的实例推断性能与之前的PyTorch版本相比,Resnet50的速度高达3.5倍(见下图),以及BERT速度的1.4倍,这使得基于Graviton的实例成为这些模型在亚马逊云科技上最快的计算优化实例。
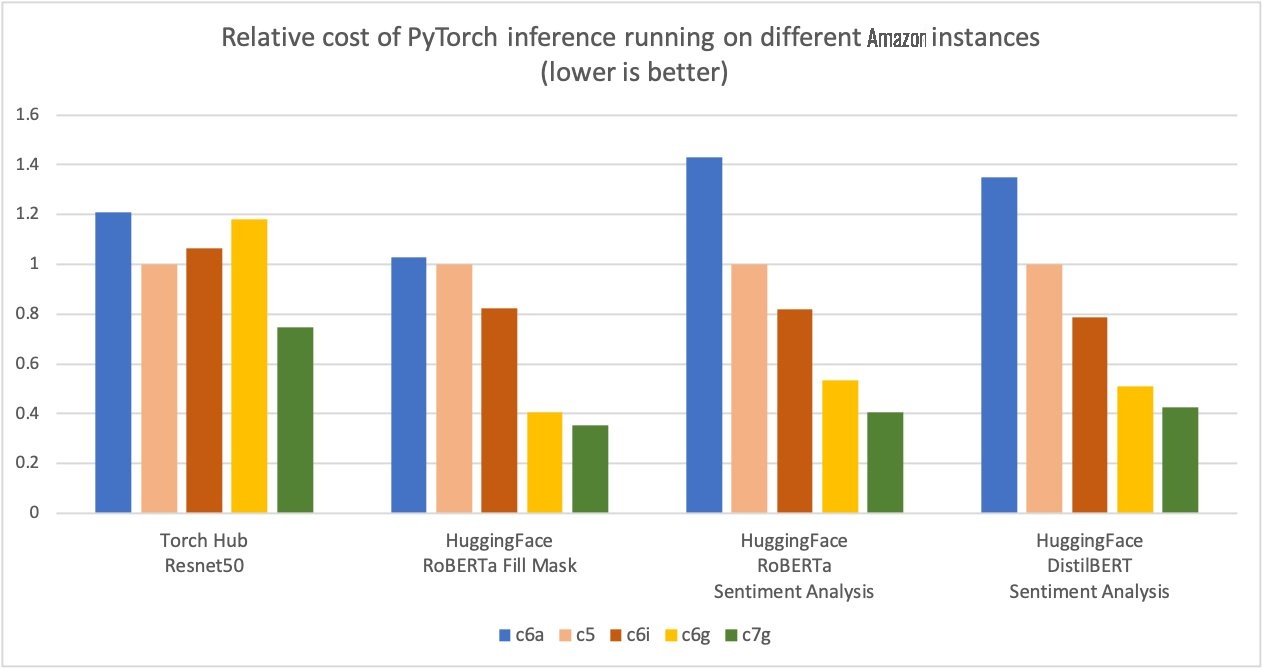
亚马逊云科技测得,在Torch Hub Resnet50上使用基于亚马逊云科技 Graviton3的亚马逊弹性云计算C7g实例,以及与同类EC2实例相比,使用多个Hugging Face模型进行PyTorch推断可节省多达50%的成本,如下图所示。
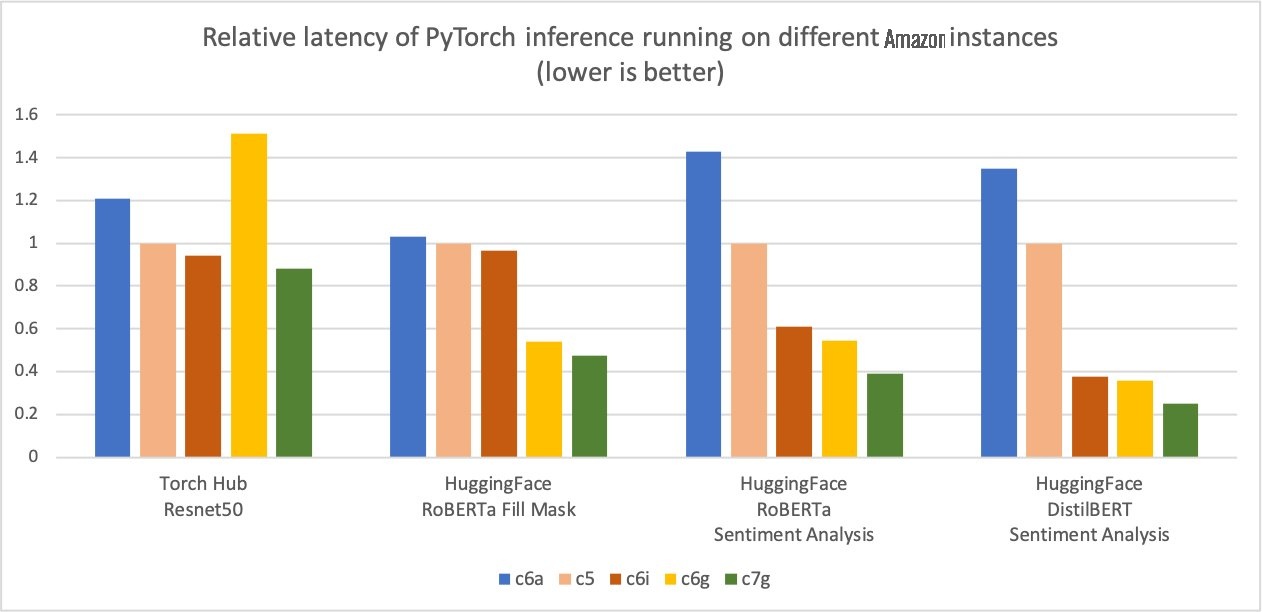
此外,推理的延迟也减少了,如下图所示。
我们在Graviton上看到其他工作负载的性价比优势也有类似的趋势,例如使用FFmpeg进行
优化详情
优化集中在三个关键领域:
- GEMM 内核 — PyTorch 通过 OneDNN 后端(以前称为 MKL-DNN)支持基于 ARM 的处理器的 Arm 计算库 (ACL) GEMM 内核。ACL 库提供适用于 fp32 和 bfloat16 格式的 Neon 和 SVE 优化的 GEMM 内核。这些内核提高了 SIMD 硬件利用率并减少了端到端推理延迟。
- bfloat16 支持 — Graviton3 中的 bfloat16 支持允许高效部署使用 bfloat16、fp32 和 AMP(自动混合精度)训练的模型。标准 fp32 模型通过 OneDNN 快速数学模式使用 bfloat16 内核,无需模型量化,与不支持 bfloat16 快速数学的现有 fp32 模型推断相比,性能最多快两倍。
- 原始缓存 — 我们还为 conv、matmul 和内积运算符实现了原始缓存,以避免冗余的 GEMM 内核初始化和张量分配开销。
如何利用优化
使用 亚马逊云科技 DLC
要使用 亚马逊云科技 DLC,请使用以下代码:
如果你更喜欢通过 pip 安装 PyTorch,请从官方存储库中安装 PyTorch 2.0 轮子。在这种情况下,在启动 PyTorch 以激活 Graviton 优化之前,你必须按照以下代码中的说明设置两个环境变量。
使用 Python 轮子
要使用 Python 轮子,请参阅以下代码:
运行推断
你可以使用 Py
基准设定
您可以使用
结论
亚马逊云科技测得,使用基于亚马逊云科技 Graviton3的亚马逊弹性云计算C7g实例,在Torch Hub Resnet50上进行PyTorch推断可节省多达50%的成本,与同类的EC2实例相比,使用多个Hugging Face模型。这些实例在 SageMaker 和亚马逊 EC2 上可用。
如果您发现在 亚马逊云科技 Graviton 上没有看到类似性能提升的用例,请在
作者简介
 Sunita Nadampalli
是 亚马逊云科技 的软件开发经理。她负责针对机器学习、HPC 和多媒体工作负载的 Graviton 软件性能优化。她热衷于开源开发,并通过 Arm SoC 提供具有成本效益的软件解决方案。
Sunita Nadampalli
是 亚马逊云科技 的软件开发经理。她负责针对机器学习、HPC 和多媒体工作负载的 Graviton 软件性能优化。她热衷于开源开发,并通过 Arm SoC 提供具有成本效益的软件解决方案。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。