我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
下一代 Amazon SageMaker 实验 — 大规模组织、跟踪和比较您的机器学习训练
今天,我们很高兴地宣布对亚马逊 SageMaker 的
机器学习 (ML) 是一个迭代过程。在解决新的用例时,数据科学家和机器学习工程师会遍历各种参数,以找到可用于生产的最佳模型配置(又名超参数),以解决已确定的业务挑战。随着时间的推移,在尝试了多个模型和超参数之后,如果没有工具来跟踪不同的实验,机器学习团队就很难有效地管理模型运行以找到最佳模型。实验跟踪系统简化了比较不同迭代的流程,有助于简化团队中的协作和沟通,从而提高生产力并节省时间。这是通过毫不费力地组织和管理机器学习实验以从中得出结论来实现的,例如,找到最准确的训练过程。
为了解决这一挑战,SageMaker 提供了 SageMaker 实验,这是一项完全集成的 SageMaker 功能。它可以灵活地记录模型指标、参数、文件、工件、绘制来自不同指标的图表、捕获各种元数据、搜索它们并支持模型的可重复性。数据科学家可以通过可视化图表和表格快速比较模型评估的性能和超参数。他们还可以使用 SageMaker 实验下载创建的图表并与利益相关者共享模型评估。
随着 SageMaker 实验的新更新,它现在成为 SageMaker SDK 的一部分,简化了数据科学家的工作,无需安装额外的库来管理多个模型执行。我们正在引入以下新的核心概念:
- 实验 :一组组合在一起的试验。实验包括运行多种类型,可以使用 SageMaker Python SDK 从任何地方启动。
-
运行
:模型训练过程的每个执行步骤。一次运行包含一次模型训练迭代的所有输入、参数、配置和结果。
可以使用 log_parameter、log_parametric 和可以使用log_metric 函数记录自定义参数和指标。log_file 函数记录自定义输入和输出。
作为
Run
类的一部分实现的概念可在安装了 SageMaker Python SDK 的任何 IDE 中使用。用于 SageMaker 训练、处理和
转换作业,如果在运行环境中调用作业,则 SageMaker 实验运行会自动传递给作业。你可以使用
load_run () 从作业中恢复运行
对象。
最后,通过新功能的集成,数据科学家还可以分别使用 run.log_conf
usion_matrix、run.log_precision_recall 和 run.log_roc_curve 函数自动记录混淆
矩阵、精度和召回图以及用于分类用例的 ROC 曲线。
在这篇博客文章中,我们将举例说明如何通过 SageMaker SDK 在 Jupyter 笔记本电脑中使用新的 SageMaker Experiments 功能。我们将使用
- 创建实验的运行和记录参数 :我们将首先创建一个新实验,开始该实验的新运行,并将参数记录到该实验中。
- 记录模型性能指标: 我们将 记录模型性能指标并绘制指标图。
- 比较模型运行: 我们将 根据模型超参数比较不同的模型运行。我们将讨论如何比较这些运行情况,以及如何使用 SageMaker 实验来选择最佳模型。
-
通过
SageMaker 作业运行实验
:我们还将提供一个示例,说明如何通过 SageMaker 处理、训练或批处理转换作业自动共享实验上下文。这允许您使用作业中的
load_run 函数自动恢复运行上下文。 -
集成 SageMaker Clarify 报告
:
我们将演示我们现在如何将
SageMaker Clarify 偏见和可解释性报告与经过训练的模型报告整合到一个视图中。
先决条件
在这篇博客文章中,我们将使用
- SageMaker 工作室域名
- 拥有 SageMaker 完全访问权限的 SageMaker Studio 用户资料
-
一款至少具有 ml.t3.
medium 实例类型的 SageMaker Studio 笔记本电脑
如果您没有 SageMaker 域名和用户配置文件可用,则可以使用此
记录参数
在本练习中,我们将使用
PyTorch 1.12 Python 3.8 CPU 优化
版 和 P
ython 3
内核。下面描述的示例将侧重于 SageMaker 实验功能,代码不完整。
让我们使用
torchvision
包下载数据,并使用 SageMaker 实验将训练和测试数据集的数据样本数量作为参数进行跟踪。
在这个例子中,让我们假设 t
rain_set 和 test_set
已经下载了 torchvis ion 数据集
。
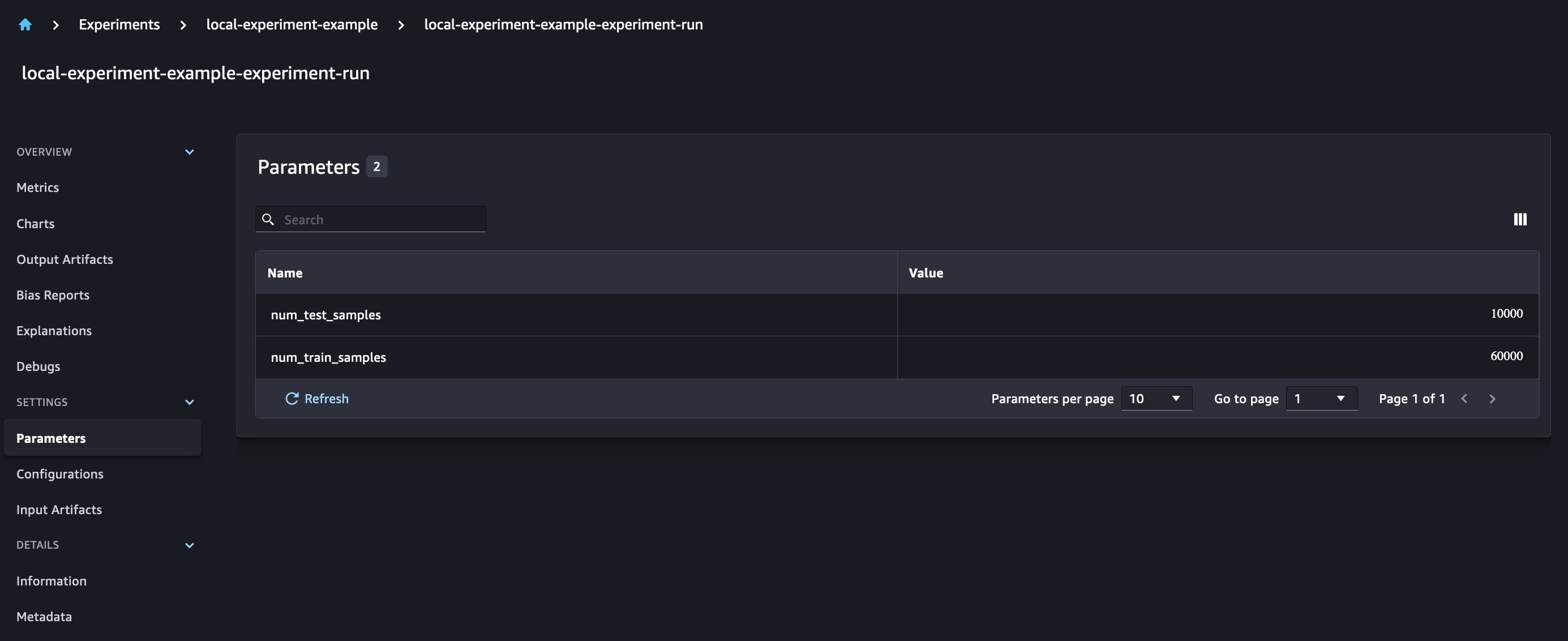
在此示例中,我们使用
run.log_
parameters 来记录训练和测试数据样本的数量,并使用
run.log_file
将原始数据集上传 到 Amazon S3,并将其记录为实验的输入。

训练模型并记录模型指标
现在我们已经下载了 MNIST 数据集,让我们训练一个
我们可以使用
load_run
函数来加载之前的运行并用它来记录我们的模型训练
然后,我们可以使用
run.log_parameter 和 r un.log_
parameters 将一个或多个模型参数
记录 到我们的运行中。
我们可以使用
run.log_metric 将性能指标
记录 到我们的实验中。
对于分类模型,您还可以使用
run.log_confusion_matrix 、run.log_precision_recall 和 run.log_roc_cur ve 来自动绘制混淆矩阵
、精确召回
图和模型的 ROC 曲线
。由于我们的模型解决了多类分类问题,因此让我们只记录混淆矩阵。
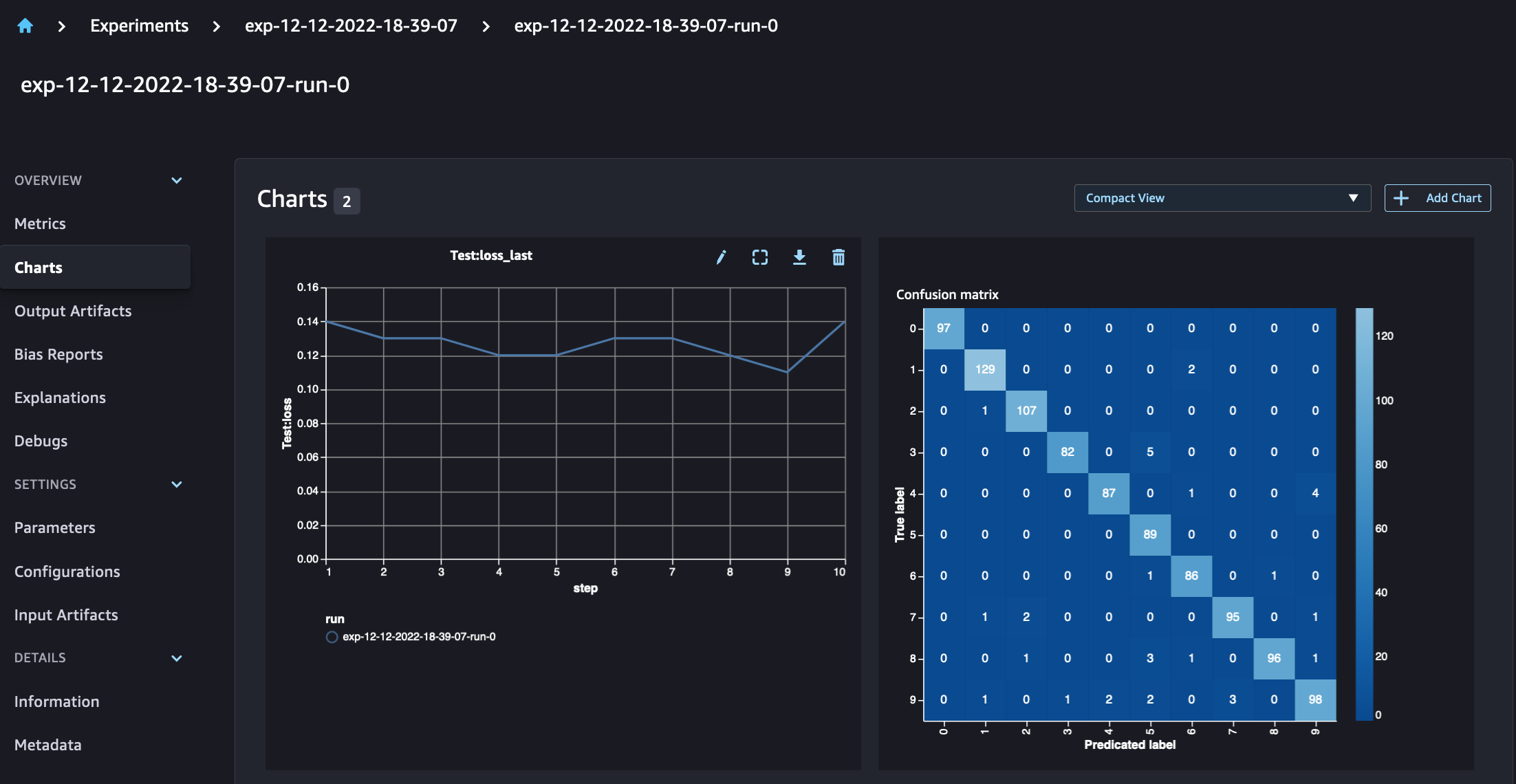
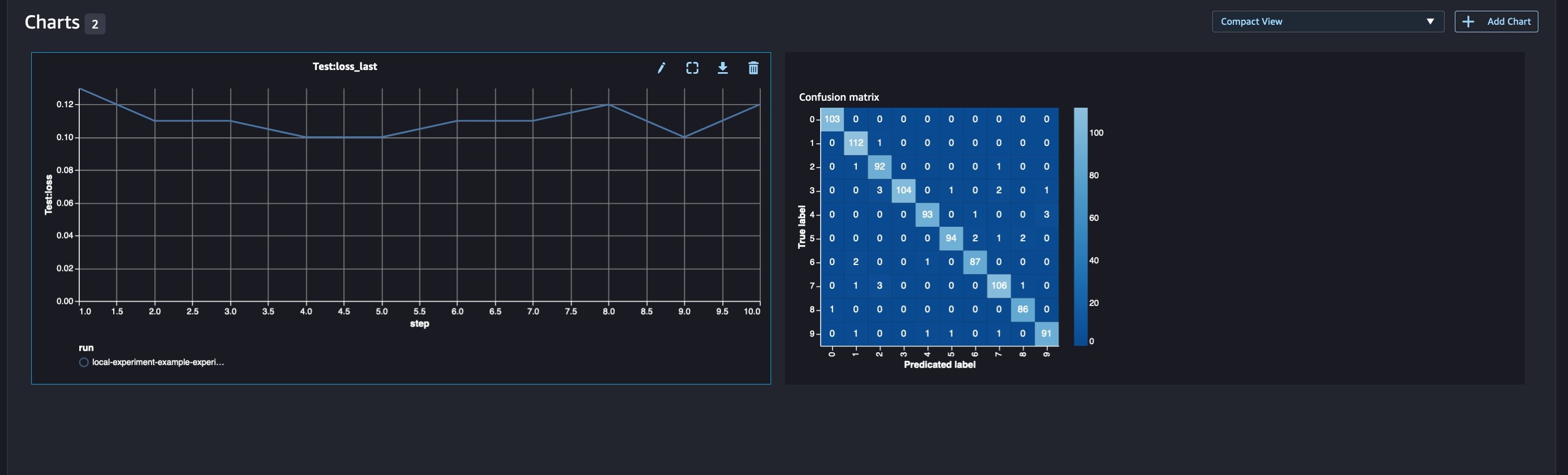
在查看我们的运行详细信息时,我们现在可以看到生成的指标,如下面的屏幕截图所示:

运行详细信息页面提供有关指标的更多信息。

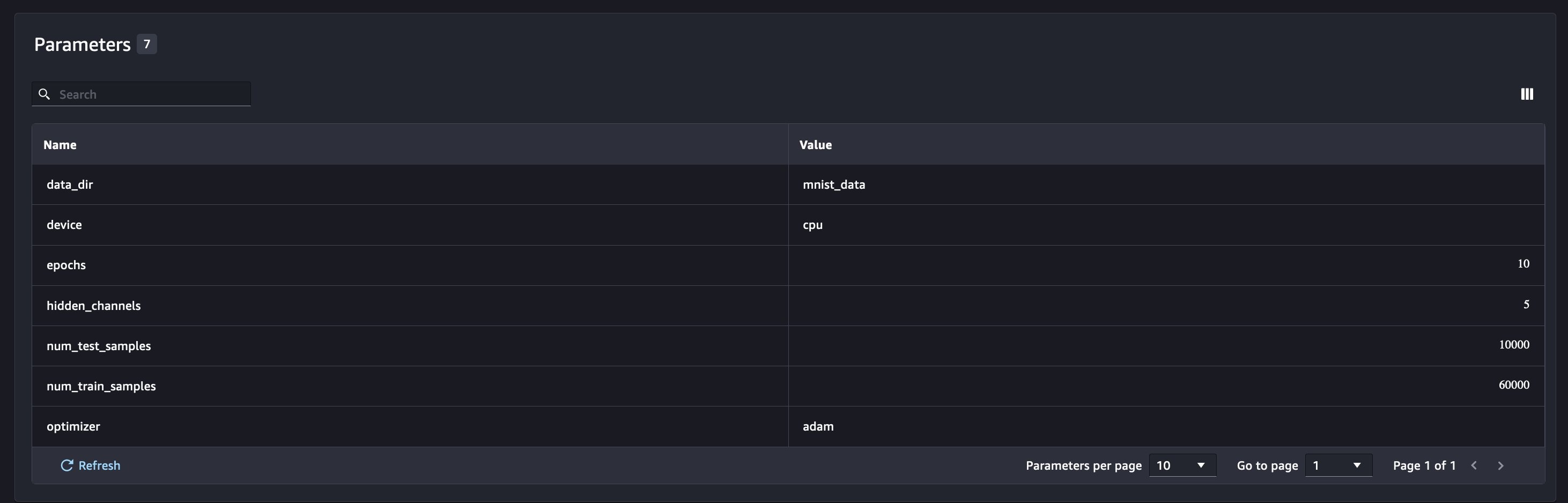
新的模型参数将在参数概述页面上进行跟踪。
您还可以使用自动绘制的混淆矩阵按类别分析模型性能,该混淆矩阵也可以下载并用于不同的报告。而且,您可以绘制额外的图表,根据记录的指标来分析模型的性能。
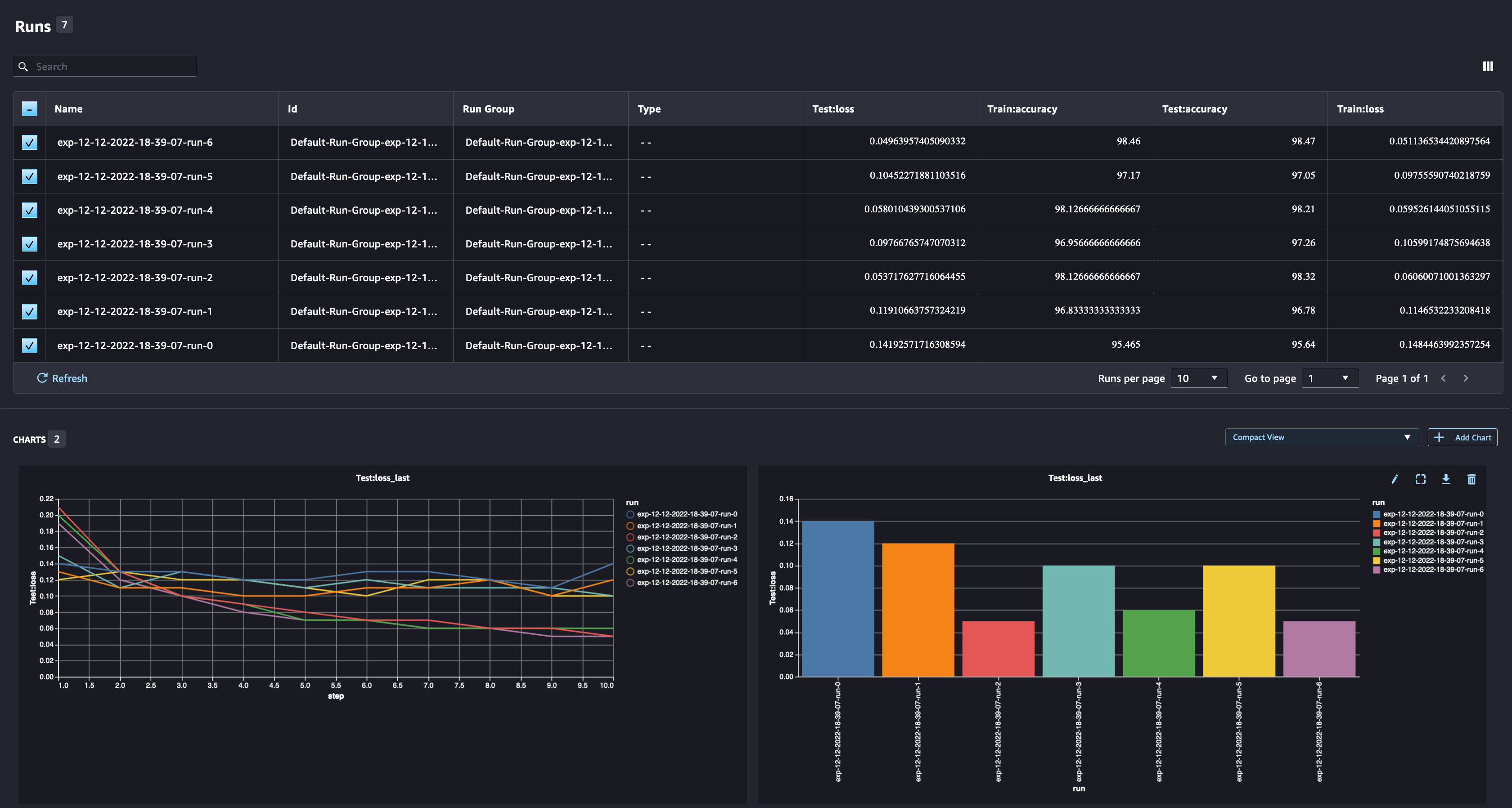
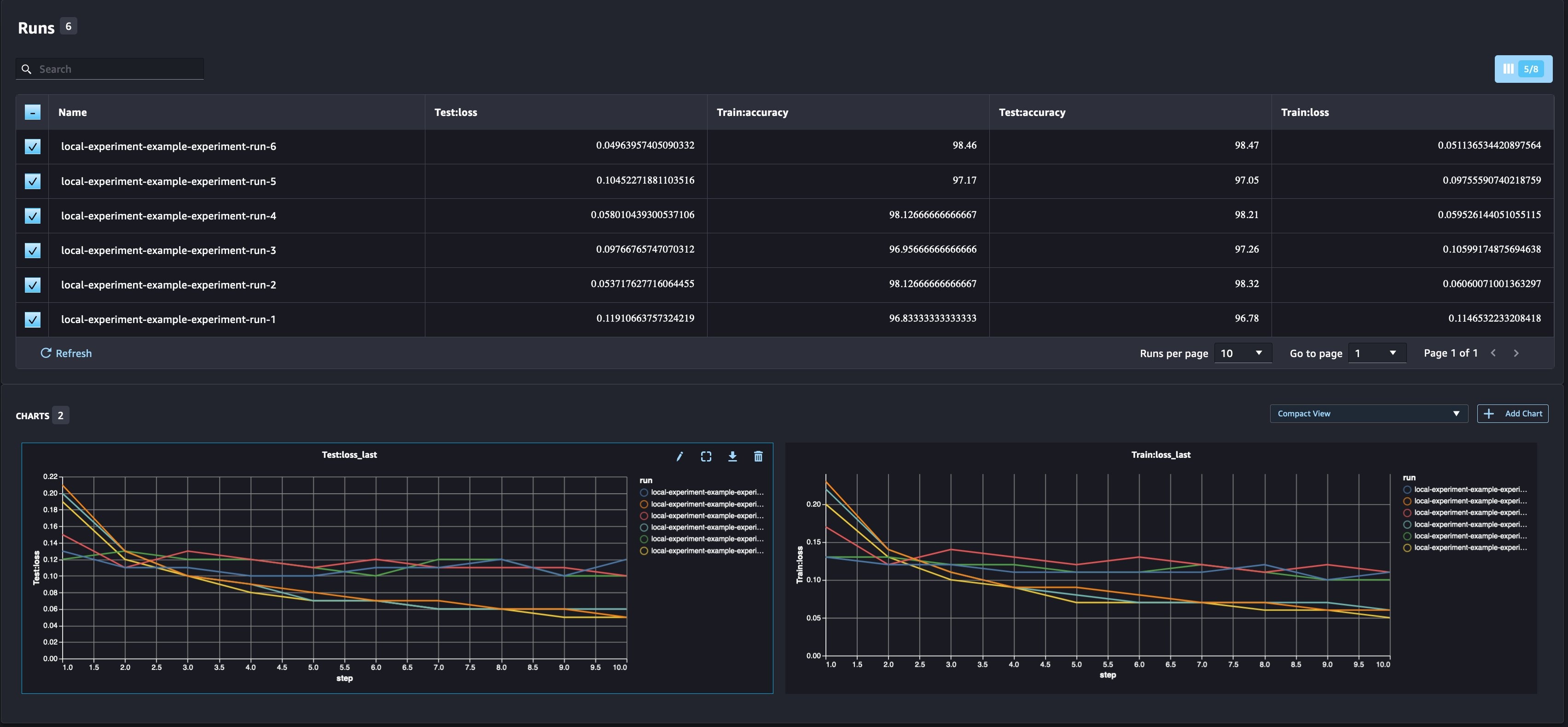
比较多个模型参数
作为数据科学家,你需要找到尽可能好的模型。这包括使用不同的超参数多次训练模型,并将模型的性能与这些超参数进行比较。为此,SageMaker 实验允许我们在同一个实验中创建多个试验。
让我们通过使用不同的
num_hidden_
channels 和优化器训练模型来探索这个概念。
我们现在正在为实验创建六个新的试验。每个人都将记录模型参数、指标和混淆矩阵。然后,我们可以比较运行情况,为问题选择性能最好的模型。在分析跑步时,我们可以将不同跑步的指标图绘制成单个图,比较不同训练步骤(或时期)中跑步的表现。
将 SageMaker 实验与 SageMaker 训练、处理和批量转换作业结合使用
在上面的示例中,我们使用 SageMaker 实验记录了 SageMaker Studio 笔记本电脑中的模型性能,在该笔记本中对模型进行了本地训练。我们可以通过同样的方法来记录 SageMaker 处理、训练和批量转换作业的模型性能。有了新的自动上下文传递功能,我们无需专门与 SageMaker 作业共享实验配置,因为实验配置会被自动捕获。
以下示例将重点介绍 SageMaker 实验功能,但代码不完整。
在我们的模型脚本文件中,我们可以使用 l
oad_run () 获取运行
上下文。 在 SageMaker 处理和训练作业中,我们无需提供用于加载配置的实验配置。对于批量转换作业,我们需要提供
实验名称 和
来加载实验的配置。
运行名称
除了我们在从笔记本脚本运行 SageMaker 实验时获得的信息外,从 SageMaker 作业运行将自动填充作业参数和输出。
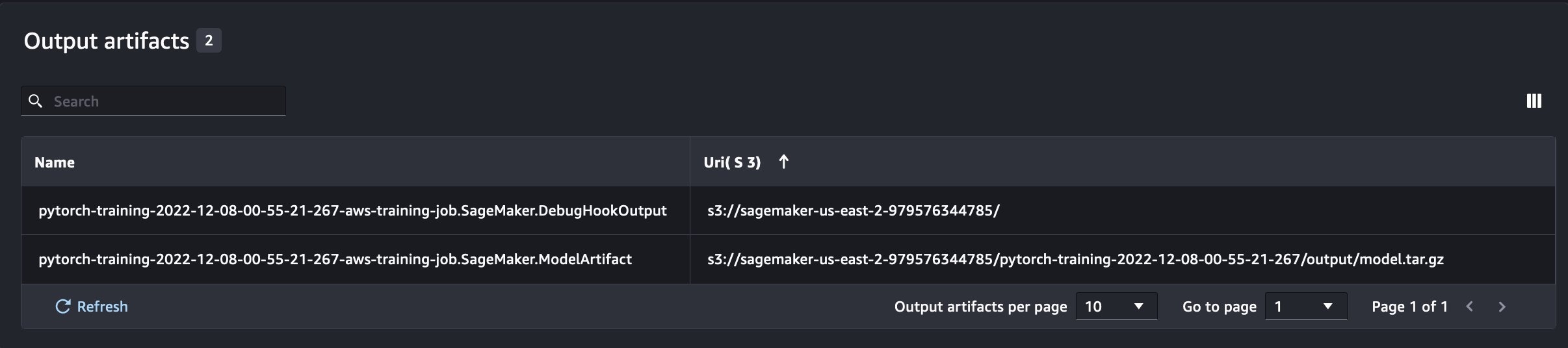
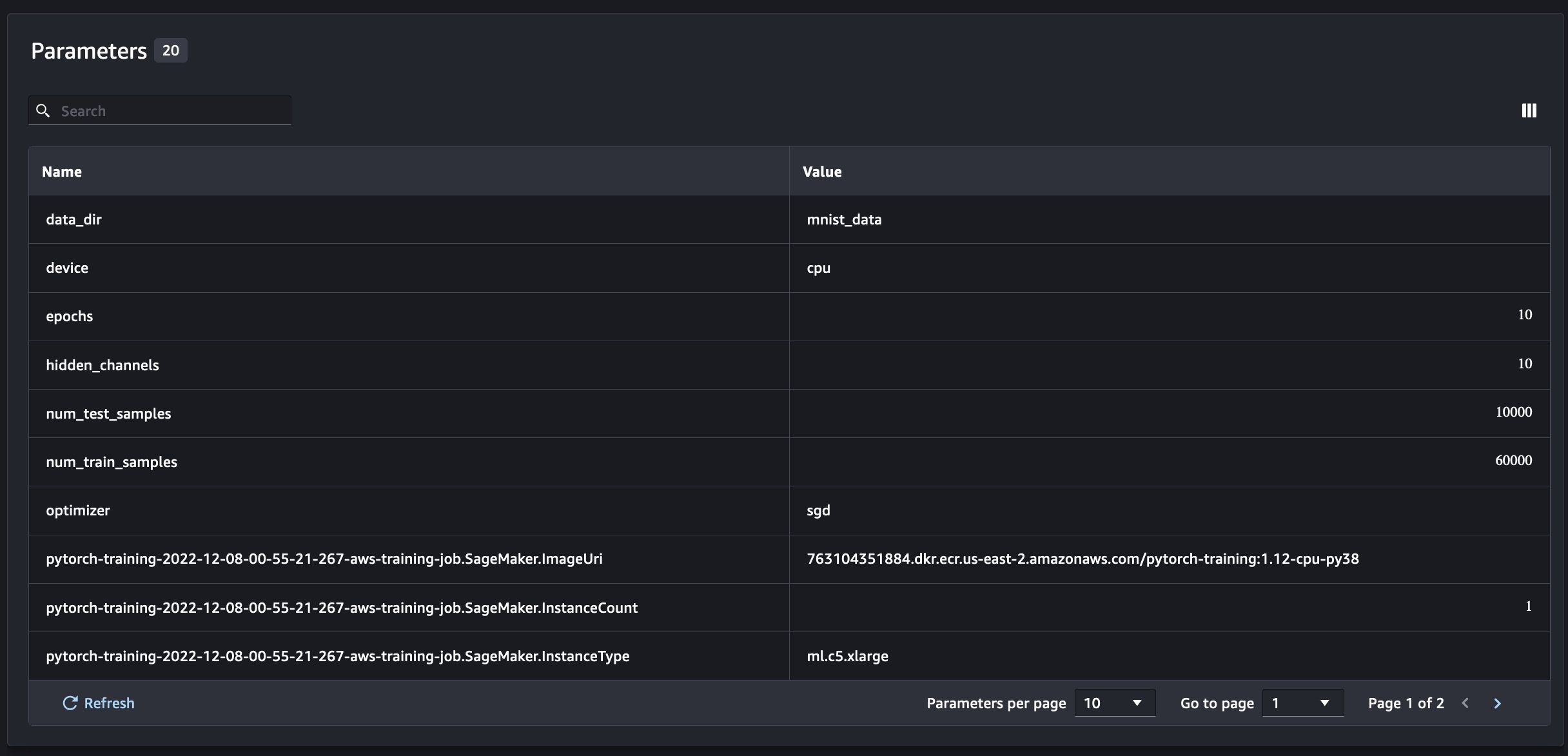
新的 SageMaker Experiments SDK 还使用试用版和试用版组件的概念确保了与先前版本的向后兼容性。使用先前 SageMaker 实验版本触发的任何实验都将自动在新用户界面中提供,用于分析实验。
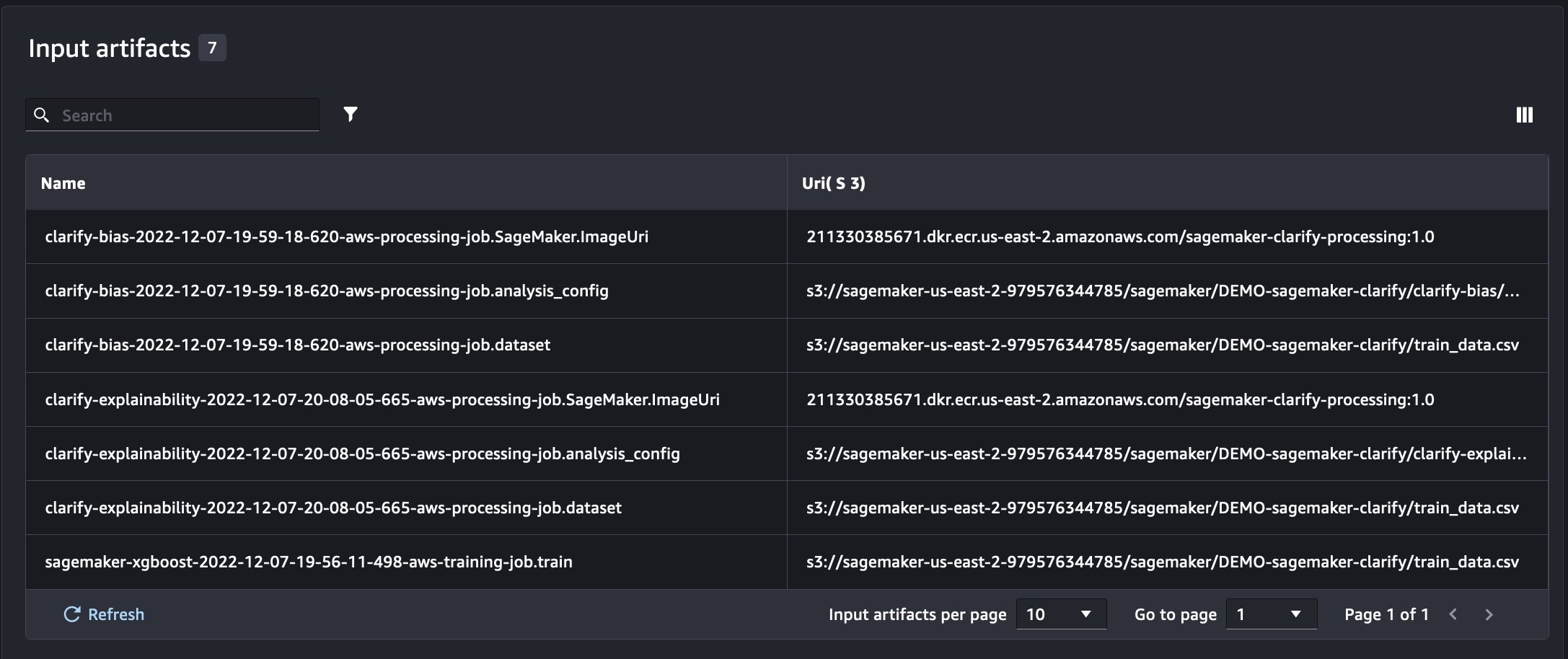
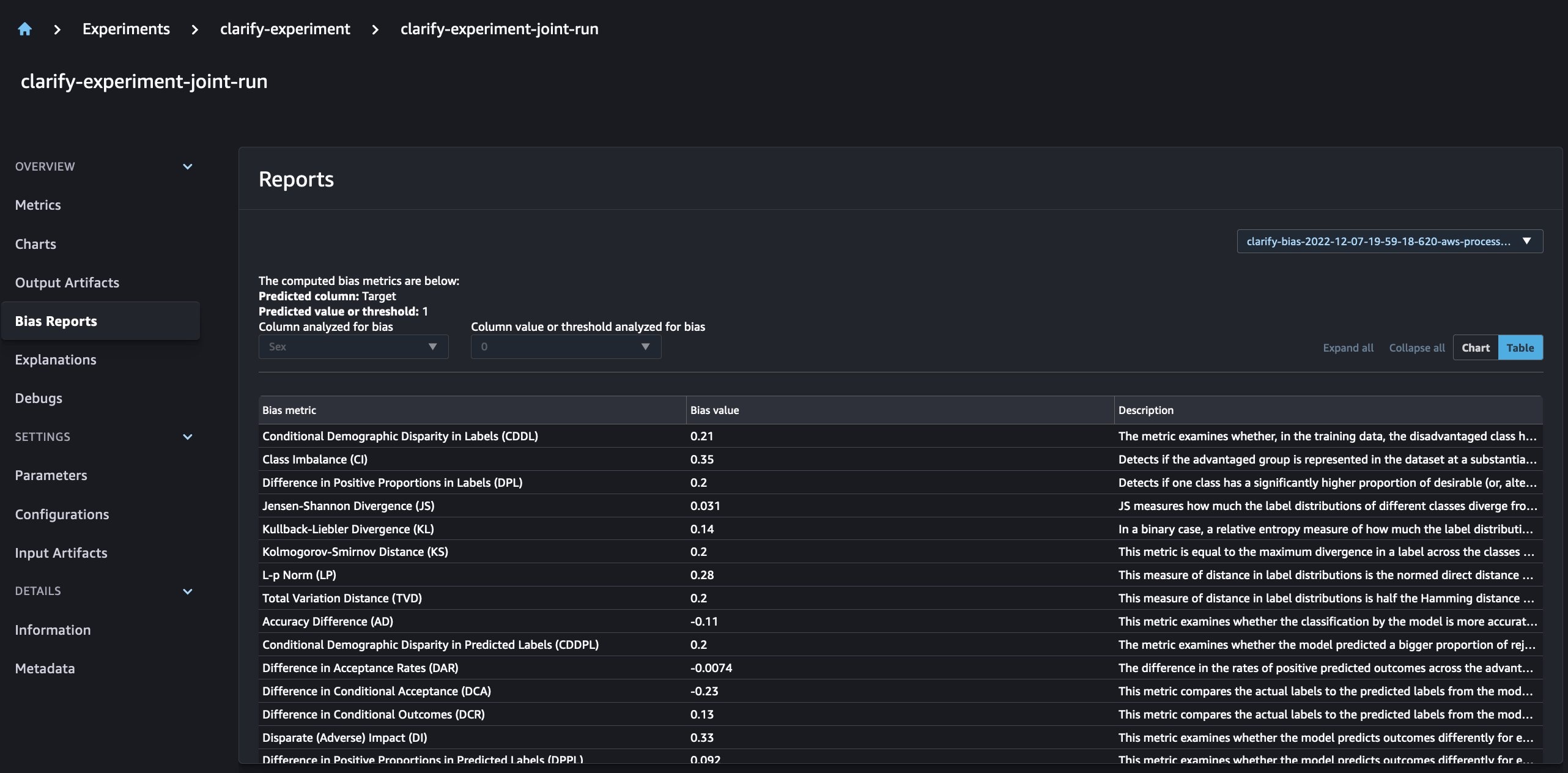
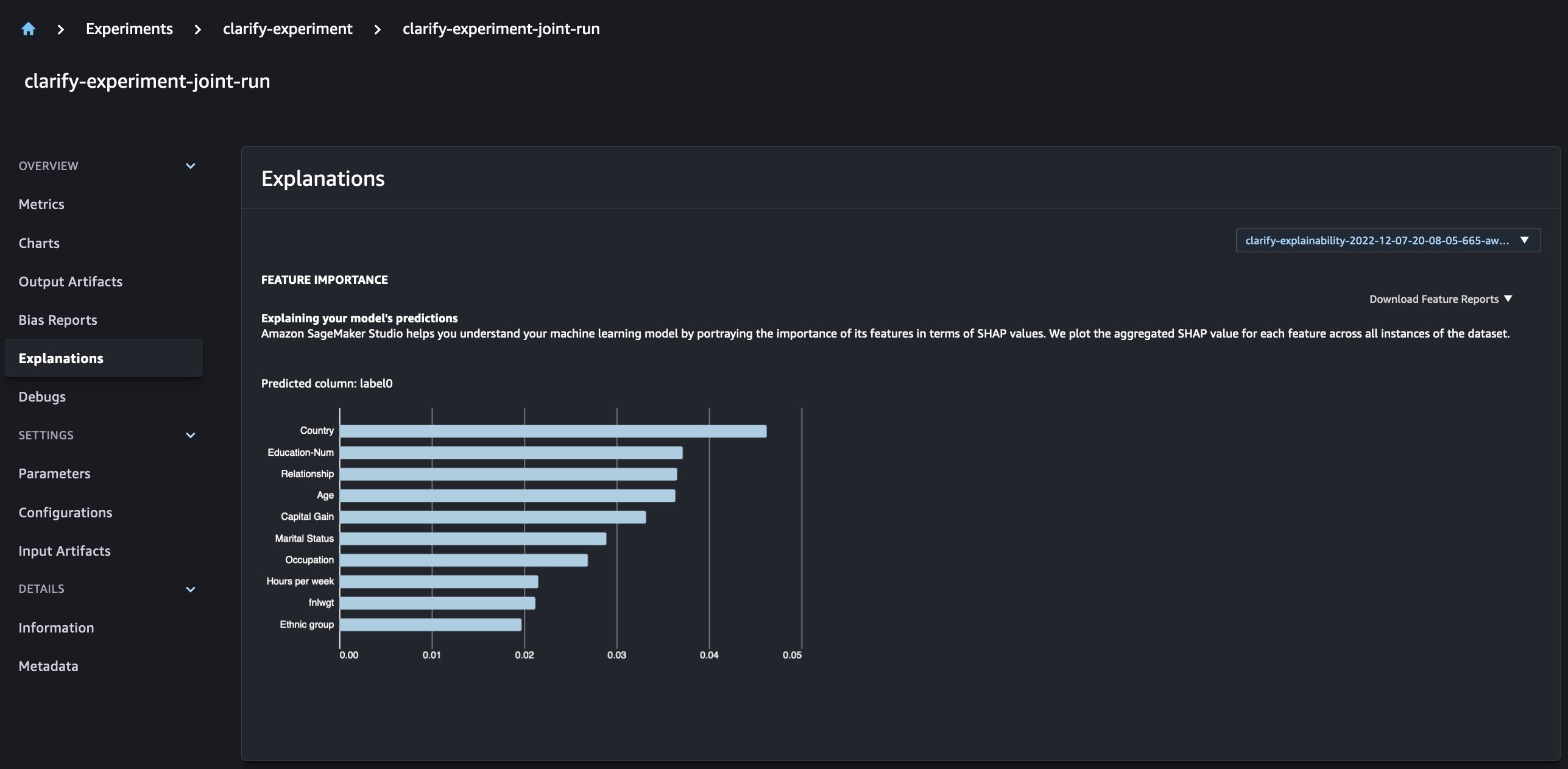
整合 SageMaker Clarify 和模型训练报告
SageMaker Clarify 通过检测
通过新的 SageMaker 实验,我们还可以将 SageMaker Clarify 报告与我们的模型训练相结合,模型训练具有一个事实来源,使我们能够进一步了解我们的模型。要获得一份综合报告,我们所需要做的就是为我们的培训和 Clarify 作业使用相同的运行名称。以下示例演示了我们如何使用
通过这种设置,我们可以获得一个综合视图,其中包括模型指标、联合输入和输出,以及有关模型统计偏差和可解释性的 Clarify 报告。

结论
在这篇文章中,我们探讨了新一代 SageMaker 实验版,它是 SageMaker SDK 的组成部分。我们演示了如何使用新的 Run 类从任何地方记录您的 ML 工作流程。我们推出了新的 Experiments UI,它允许您跟踪实验并绘制单次运行指标的图表,并使用新的分析功能比较多次运行。我们提供了在 SageMaker Studio 笔记本电脑和 SageMaker Studio 训练作业中记录实验的示例。最后,我们展示了如何在统一视图中集成模型训练和 SageMaker Clarify 报告,从而使您能够进一步了解模型。
如果您有任何问题或反馈,我们鼓励您尝试新的实验功能,并
作者简介





*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。