许多客户在其本地环境中拥有 Oracle 多租户数据库,他们可能希望在使用多租户数据库的同时使用
亚马逊关系数据库服务 (Amazon RDS) 获 得 Oracle
功能。截至 2022 年 8 月,适用于 Oracle 的亚马逊 RDS 支持多租户架构的子集,称为
单租户
架构。 多租户架构使 Oracle 数据库能够充当多租户容器数据库 (CDB)。CDB 可以包含客户创建的可插拔数据库 (PDB)。在适用于 Oracle 的 RDS 中,CDB 仅包含一个 PDB。单租户架构使用与非 CDB 架构相同的 Amazon RDS API。带有非 CDB 数据库的 Amazon RDS for Oracle 在使用 PDB 时基本上是相同的。
在这篇文章中,我们讨论了将您的本地 Oracle 多租户可插拔数据库迁移到适用于 Oracle 的
Amazon RDS
的解决方案。
解决方案概述
可插拔数据库是架构、架构对象和非架构对象的可移植集合,在 Oracle Net 客户端看来是非 CDB。PDB 可以插入 CDB,一个 CDB 可以包含多个 PDB。每个 PDB 作为单独的数据库出现在网络上。
创建 CDB 时,请像指定非基于 CDB 的单租户 Oracle RDS 实例一样指定数据库实例标识符。实例标识符构成终端节点的第一部分。系统标识符 (SID) 是 CDB 的名称。每个 CDB 的 SID 都是 RDSCDB。你不能选择不同的值。
本节介绍将可插拔数据库迁移到 Amazon RDS for Oracle 的移位和转移程序。这包括基于数据库大小的停机时间、本地和 亚马逊云科技 之间的网络带宽以及导出和导入数据库所消耗的时间。为了最大限度地减少停机时间,您可以参考
使用 亚马逊云科技 DMS 迁移停机时间接近零的 Oracle 数据库
在这篇文章中,我们使用
亚马逊弹性计算云
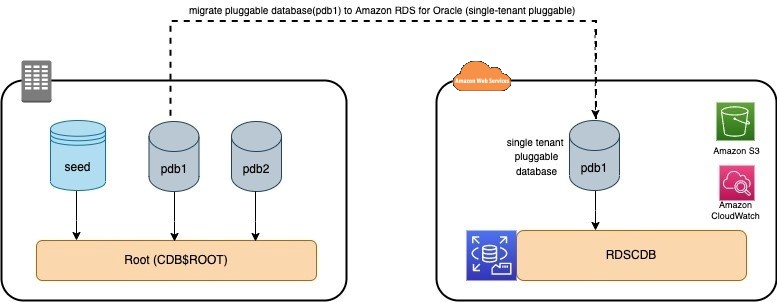
(Amazon EC2)作为我们的源Oracle数据库服务器。下图说明了我们的架构。
先决条件
在开始之前,请完成以下必备步骤:
-
使用以下 亚马逊云科技
CloudF
ormation 模板创建 RDS 适用于 Oracle 的多租户容器数据库。
注意:
CloudFormation 模板为 Oracle 实例创建了自带许可 (
BYOL
) RDS。
-
确保源数据库是位于本地或 EC2 实例上的 Oracle Pluggable 数据库,可以连接到相应账户中托管的 亚马逊云科技 资源。
-
确认您可以同时连接到本地 Oracle 数据库和 RDS for Oracle 实例。
-
在源数据库服务器(本例中为 Amazon EC2)中添加 Oracle RDS tnsentry 以连接到目标。
-
在可以访问
亚马逊简单存储服务
(
Amazon S3)和 RDS 实例的计算机上安装和配置 亚马逊云科技 命令行接口
(亚马逊云科技 CLI)。有关说明,请参阅
安装或更新最新版本的 亚马逊云科技 CLI
。
将 RDS for Oracle 数据库(目标数据库)创建为单租户架构后,您可以使用端点标识符和 PDB 数据库名称连接到 PDB 数据库。以下示例显示了 SQL*Plus 中连接字符串的格式:
sqlplus 'dbuser@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=endpoint)(PORT=port))(CONNECT_DATA=(SID=pdb_name)))'
从源 Oracle 数据库导出数据
连接到源数据库并提取与 PDB 数据库关联的架构及其相应表:
SQL> select con_id, name, open_mode from v$pdbs;
CON_ID NAME OPEN_MODE
---------- ---------- ----------
2 PDB$SEED READ ONLY
3 ORCLPDB READ WRITE
SQL> ALTER SESSION SET CONTAINER = ORCLPDB;
Session altered.
SQL> SHOW CON_NAME;
CON_NAME
------------------------------
ORCLPDB
SQL>
SQL> l
1 SELECT p.PDB_ID, p.PDB_NAME, t.OWNER, t.TABLE_NAME
2 FROM DBA_PDBS p, CDB_TABLES t
3 WHERE p.PDB_ID > 2 AND
4 t.owner not like '%SYS%' and t.OWNER NOT IN ('ORDDATA','DBSFWUSER',
5 'CTXSYS',
6 'RDSADMIN','PUBLIC',
7 'XDB',
8 'OUTLN',
9 'ORACLE_OCM',
10 'DBSNMP',
11 'DBUPTIME',
12 'GSMADMIN_INTERNAL',
13 'SVCSAMLMSRO',
14* 'REMOTE_SCHEDULER_AGENT','PERFSTAT')
SQL>
SQL> /
PDB_ID PDB_NAME OWNER TABLE_NAME
---------- ----------------------------------- --------- ------------------------------
3 ORCLPDB HR REGIONS
3 ORCLPDB HR COUNTRIES
3 ORCLPDB HR LOCATIONS
3 ORCLPDB HR DEPARTMENTS
3 ORCLPDB HR JOBS
3 ORCLPDB HR EMPLOYEES
3 ORCLPDB HR JOB_HISTORY
3 ORCLPDB SALES TEST
8 rows selected.
使用 TNS 连接到源 PDB 数据库,并使用
Oracle
数据泵导出迁移范围内的架构:
$ expdp admin/admin@orclpdb directory=ORA_DIR dumpfile=hr_dmp_file2.dmp schemas=hr,sales
Export: Release 12.2.0.1.0 - Production on Fri Jun 10 19:12:54 2022
Copyright (c) 1982, 2017, Oracle and/or its affiliates. All rights reserved.
Connected to: Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit Production
Starting "ADMIN"."SYS_EXPORT_SCHEMA_01": admin/********@orclpdb directory=ORA_DIR dumpfile=hr_dmp_file2.dmp schemas=hr,sales
Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA
Processing object type SCHEMA_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS
Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS
Processing object type SCHEMA_EXPORT/STATISTICS/MARKER
Processing object type SCHEMA_EXPORT/USER
Processing object type SCHEMA_EXPORT/SYSTEM_GRANT
Processing object type SCHEMA_EXPORT/ROLE_GRANT
Processing object type SCHEMA_EXPORT/DEFAULT_ROLE
Processing object type SCHEMA_EXPORT/TABLESPACE_QUOTA
Processing object type SCHEMA_EXPORT/PRE_SCHEMA/PROCACT_SCHEMA
Processing object type SCHEMA_EXPORT/SEQUENCE/SEQUENCE
Processing object type SCHEMA_EXPORT/TABLE/TABLE
Processing object type SCHEMA_EXPORT/TABLE/COMMENT
Processing object type SCHEMA_EXPORT/PROCEDURE/PROCEDURE
Processing object type SCHEMA_EXPORT/PROCEDURE/ALTER_PROCEDURE
Processing object type SCHEMA_EXPORT/VIEW/VIEW
Processing object type SCHEMA_EXPORT/TABLE/INDEX/INDEX
Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/CONSTRAINT
Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/REF_CONSTRAINT
Processing object type SCHEMA_EXPORT/TABLE/TRIGGER
. . exported "HR"."EMPLOYEES" 17.09 KB 107 rows
. . exported "HR"."LOCATIONS" 8.437 KB 23 rows
. . exported "HR"."JOB_HISTORY" 7.195 KB 10 rows
. . exported "HR"."JOBS" 7.109 KB 19 rows
. . exported "HR"."DEPARTMENTS" 7.125 KB 27 rows
. . exported "HR"."COUNTRIES" 6.367 KB 25 rows
. . exported "HR"."REGIONS" 5.546 KB 4 rows
. . exported "SALES"."TEST" 5.054 KB 1 rows
Master table "ADMIN"."SYS_EXPORT_SCHEMA_01" successfully loaded/unloaded
******************************************************************************
Dump file set for ADMIN.SYS_EXPORT_SCHEMA_01 is:
/home/oracle/hr_dmp_file2.dmp
Job "ADMIN"."SYS_EXPORT_SCHEMA_01" successfully completed at Fri Jun 10 19:13:42 2022 elapsed 0 00:00:47
将导出的转储文件传输到 Amazon S3 并将亚马逊 S3 角色与 RDS 实例集成
适用于 Oracle 的 RDS 实例必须有权访问 S3 存储桶才能使用
适用于甲骨文的 亚马逊 RDS 与亚马逊 S3 的集成
。创建 Amazon RDS for Oracle 实例和 S3 存储桶后,按照本节所述创建 IAM 策略和一个 IAM 角色,然后将策略附加到该角色。
要使用适用于 Oracle 的亚马逊 RDS 与 Amazon S3 的集成,您的亚马逊 RDS for Oracle 实例必须与包含 S3_INTEGR ATION
选项的选项组
相关联。选项组已连接到我们的 RDS 实例;要添加 S3_Integration 功能,请完成以下步骤:
-
在 Amazon RDS 控制台上,选择
选项组
。
-
选择连接到 RDS 实例的组。
-
选择 “
添加” 选项
。
-
对于
选项 ,选择
S3
_INTEGRATION。
-
对于
版本
,选择
1.0
。
-
对于 “
立即 申请
” ,选择 “
是
” 。
-
选择 “
添加选项”
。
将 S3_Integration 添加到选项组后,创建一个 IAM 角色以与 Oracle RDS 实例集成。
-
在 IAM 控制台的导航窗格中,选择
角色
,然后选择
创建角色
。
-
在
“选择可信实体”
下 ,选择
亚马逊云科技 服务
, 然后选择
RDS
。
-
在
添加权限
下 ,选择
Amazons
3FullAccess。
-
在 “
角色详细信息
” 下 ,输入 RDS_s3_integration_role 作为角色名称,然后选择创建角色。
创建 IAM 角色和 S3_Integration 后,将其与您的 RDS 数据库实例关联起来。
-
在 Amazon RDS 控制台上,选择您的数据库实例。
-
在
连接和安全
选项卡上,选择
管理 IAM 角色
。
-
要向该实例 添加 IAM 角色
,请选择
RDS_s3_integration_role
(您创建的角色)。
-
对于
功能
,选择
S3
_INTEGRATION。
-
选择 “
添加角色
” 。
将 IAM 角色和亚马逊 S3 集成功能与您的 RDS for Oracle 数据库关联后,您可以将数据转储文件从本地 Oracle 数据库实例上传到亚马逊 S3,也可以从 Amazon S3 下载到 RDS 实例。此步骤要求在主机上可用 亚马逊云科技 CLI(亚马逊云科技 命令行接口),按照
安装或更新 亚马逊云科技 CLI 最新版本的
分步说明进行操作 。
aws s3 cp hr_dmp_file2.dmp s3://mydbs3bucket/orcl
将转储文件从 Amazon S3 下载到 RDS 实例
将数据转储文件上传到 S3 存储桶后,连接到您的目标数据库实例,并将数据泵文件从 Amazon S3 下载到目标实例的 DATA_PUMP_DIR。参见以下代码:
注意:
确保您的 RDS 实例有足够的存储空间来容纳转储文件。您可以通过
CloudWatch
指标监控存储空间,并通过在 RDS 存储上
创建 cloudwatch 警报来防止 Amazon RDS
空间耗尽。
SELECT rdsadmin.rdsadmin_s3_tasks.download_from_s3(
p_bucket_name => 'mydbs3bucket ',
p_s3_prefix => 'orcl/hr_dmp_file2.dmp',
p_directory_name => 'DATA_PUMP_DIR')
AS TASK_ID FROM DUAL;
TASK_ID
---------------------------------------------------------------------
1654638896204-1266
这为你提供了任务 ID
165463
8896204-1266。使用以下 SQL 查询验证您上传到 RDS for Oracle 实例的文件的状态:
SQL> SELECT text FROM table(rdsadmin.rds_file_util.read_text_file('BDUMP','dbtask-1654638896204-1266.log'));
TEXT
--------------------------------------------------------------------------------
2022-06-10 21:54:56.295 UTC [INFO ] This task is about to list the Amazon S3 obj
ects for AWS Region us-east-1, bucket name <S3-bucket>, and prefix orcl/hr_dmp_file2.dmp.
2022-06-10 21:54:56.343 UTC [INFO ] The task successfully listed the Amazon S3 o
bjects for AWS Region us-east-1, bucket name <S3-bucket>, and prefix orcl/hr_dmp_file2.dmp.
2022-06-10 21:54:56.360 UTC [INFO ] This task is about to download the Amazon S3
object or objects in /rdsdbdata/datapump from bucket name <S3-bucket> and key
orcl/hr_dmp_file2.dmp.
2022-06-10 21:54:56.557 UTC [INFO ] The task successfully downloaded the Amazon
S3 object or objects from bucket name <S3-bucket> with key orcl/hr_dmp_file2.dmp
to the location /rdsdbdata/datapump.
2022-06-10 21:54:56.557 UTC [INFO ] The task finished successfully.
在 SQL 查询输出显示成功下载的文件后,您可以使用以下查询在 RDS for Oracle 数据库中列出数据泵文件:
SQL> SELECT * FROM TABLE(RDSADMIN.RDS_FILE_UTIL.LISTDIR('DATA_PUMP_DIR')) order by mtime;
FILENAME TYPE FILESIZE MTIME
----------------- ------------ ---------- ---------
D118F77AAA8B1A73E0530100007FE761 directory 4096 03-APR-22
hr_dmp_file2.dmp file 638976 10-JUN-22
datapump/ directory 4096 10-JUN-22
导入数据
数据转储文件可用后,您可以在目标 RDS for Oracle 数据库上创建表空间、授权和架构,然后再启动导入。
使用以下代码在导入之前向目录授予权限:
GRANT READ, WRITE ON DIRECTORY DATA_PUMP_DIR to RDSADMIN;
连接到源 Oracle 服务器或其他可以连接到目标 RDS 实例的服务器并运行以下命令:
impdp admin@orclpdb directory=DATA_PUMP_DIR logfile=import.log dumpfile=schemas_exp.dmp
Import: Release 12.1.0.2.0 - Production on Fri Jun 10 15:59:06 2022
Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved.
Password:
Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Master table "ADMIN"."SYS_IMPORT_FULL_01" successfully loaded/unloaded
Starting "ADMIN"."SYS_IMPORT_FULL_01": admin/********@orclpdb directory=DATA_PUMP_DIR_PDB logfile=import.log dumpfile=schemas_exp.dmp
Processing object type SCHEMA_EXPORT/USER
Processing object type SCHEMA_EXPORT/SYSTEM_GRANT
Processing object type SCHEMA_EXPORT/ROLE_GRANT
Processing object type SCHEMA_EXPORT/DEFAULT_ROLE
Processing object type SCHEMA_EXPORT/TABLESPACE_QUOTA
Processing object type SCHEMA_EXPORT/PRE_SCHEMA/PROCACT_SCHEMA
Processing object type SCHEMA_EXPORT/SEQUENCE/SEQUENCE
Processing object type SCHEMA_EXPORT/TABLE/TABLE
Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA
. . imported "HR"."EMPLOYEES" 17.09 KB 107 rows
. . imported "HR"."LOCATIONS" 8.437 KB 23 rows
. . imported "HR"."JOB_HISTORY" 7.195 KB 10 rows
. . imported "HR"."JOBS" 7.109 KB 19 rows
. . imported "HR"."DEPARTMENTS" 7.125 KB 27 rows
. . imported "HR"."COUNTRIES" 6.367 KB 25 rows
. . imported "HR"."REGIONS" 5.546 KB 4 rows
. . imported "SALES"."TEST" 5.054 KB 1 rows
Processing object type SCHEMA_EXPORT/TABLE/COMMENT
Processing object type SCHEMA_EXPORT/PROCEDURE/PROCEDURE
Processing object type SCHEMA_EXPORT/PROCEDURE/ALTER_PROCEDURE
Processing object type SCHEMA_EXPORT/VIEW/VIEW
Processing object type SCHEMA_EXPORT/TABLE/INDEX/INDEX
Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/CONSTRAINT
Processing object type SCHEMA_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS
Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/REF_CONSTRAINT
Processing object type SCHEMA_EXPORT/TABLE/TRIGGER
Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS
Processing object type SCHEMA_EXPORT/STATISTICS/MARKER
Job "ADMIN"."SYS_IMPORT_FULL_01" successfully completed at Fri Jun 10 19:59:34 2022 elapsed 0 00:00:22
在 Amazon RDS 上验证 PDB 中的表
连接到 RDS 实例并运行以下命令来验证表:
SQL> l
1 SELECT p.PDB_ID, p.PDB_NAME, t.OWNER, t.TABLE_NAME
2 FROM DBA_PDBS p, CDB_TABLES t
3 WHERE p.PDB_ID > 2 AND
4 t.owner not like '%SYS%' and t.OWNER NOT IN ('ORDDATA','DBSFWUSER',
5 'CTXSYS',
6 'RDSADMIN','PUBLIC',
7 'XDB',
8 'OUTLN',
9 'ORACLE_OCM',
10 'DBSNMP',
11 'DBUPTIME',
12 'GSMADMIN_INTERNAL',
13 'SVCSAMLMSRO',
14* 'REMOTE_SCHEDULER_AGENT','PERFSTAT')
SQL> /
PDB_ID PDB_NAME OWNER TABLE_NAME
---------- -------------------- ---------- ----------
3 TESTDB6 HR COUNTRIES
3 TESTDB6 HR REGIONS
3 TESTDB6 HR LOCATIONS
3 TESTDB6 HR DEPARTMENTS
3 TESTDB6 HR JOBS
3 TESTDB6 HR EMPLOYEES
3 TESTDB6 HR JOB_HISTORY
3 TESTDB6 SALES TEST
8 rows selected.
执行切换
数据迁移和验证完成后,使用以下步骤执行直接转换:
-
适用于 Oracle 数据库的 RDS 已准备好首次为流量提供服务,因此请对其进行快照。
-
将源数据库置于只读模式。
-
手动重新验证数据。
-
如果未启用,则启用触发器;您可以使用以下查询来获取已禁用的触发器列表:
select 'alter trigger '||owner||'.'||trigger_name|| ' enable;' from dba_triggers where owner=<OWNER_NAME> and status = ‘DISABLED’;
-
获取序列的状态并将序列设置为相应的值:
select sequence_owner,sequence_name,min_value,max_value,increment_by,last_number,cache_size from dba_sequences where sequence_owner=<SCHEMA_NAME>;
-
验证源 Oracle 数据库没有流量,并将所有应用程序流量重定向到 RDS 实例。
清理
要删除此解决方案创建的所有组件,请完成以下步骤:
-
登录 A
WS 管理控制台
。
-
选择您的 RDS for Oracle 实例所在的区域。
-
在 CloudFormation 控制台上,选择您的
堆栈
, 然后选择
删除, 然后选择
删除
堆栈。
摘要
在这篇文章中,我们演示了如何将本地可插拔或不可插拔的数据库迁移到 Amazon RDS for Oracle 数据库(单租户架构)。您可以执行这些步骤将数据库迁移到适用于 Oracle 的亚马逊 RDS,并利用 Amazon RDS 托管服务和功能。
我们鼓励您尝试此解决方案,并充分利用将 亚马逊云科技 DMS 与 Oracle 数据库结合使用的所有好处。有关更多信息,请参阅
亚马逊云科技 数据库迁移服务 入门
和 A
WS 数据库迁移服务 最佳实践
。有关 Oracle 数据库迁移的更多信息,请参阅将
Oracle 数据库 迁移到 亚马逊云科技 云的
指南 。
作者简介
 Jeevith Anumalla
是亚马逊网络服务专业服务团队的高级数据架构师。他担任数据迁移专家,帮助客户建立数据湖和分析平台。
Jeevith Anumalla
是亚马逊网络服务专业服务团队的高级数据架构师。他担任数据迁移专家,帮助客户建立数据湖和分析平台。
 萨加尔·帕特尔
是亚马逊网络服务专业服务团队的高级数据库专业架构师。他是一名数据库迁移专家,负责提供技术指导并帮助亚马逊客户将其本地数据库迁移到 亚马逊云科技。
萨加尔·帕特尔
是亚马逊网络服务专业服务团队的高级数据库专业架构师。他是一名数据库迁移专家,负责提供技术指导并帮助亚马逊客户将其本地数据库迁移到 亚马逊云科技。