我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 Glue 将基于 SQL 的现有的 ETL 工作负载迁移到 亚马逊云科技 无服务器 ETL 基础设施
数据已成为大多数公司不可或缺的一部分,随着数据量和种类的指数级增长,数据处理的复杂性正在迅速增加。数据工程团队面临以下挑战:
- 操纵数据以使其可供企业用户使用
- 构建和改进提取、转换和加载 (ETL) 管道
- 扩展他们的 ETL 基础设施
许多将数据迁移到云端的客户都在寻找通过使用原生 亚马逊云科技 服务来进一步扩展和高效处理 ETL 任务来实现现代化的方法。在云之旅的早期阶段,客户可能需要指导,以最少的精力和时间实现ETL工作负载的现代化。客户经常使用许多 SQL 脚本来选择和转换托管在本地环境或 亚马逊云科技 上的关系数据库中的数据,并使用自定义工作流程来管理他们的 ETL。
解决方案概述
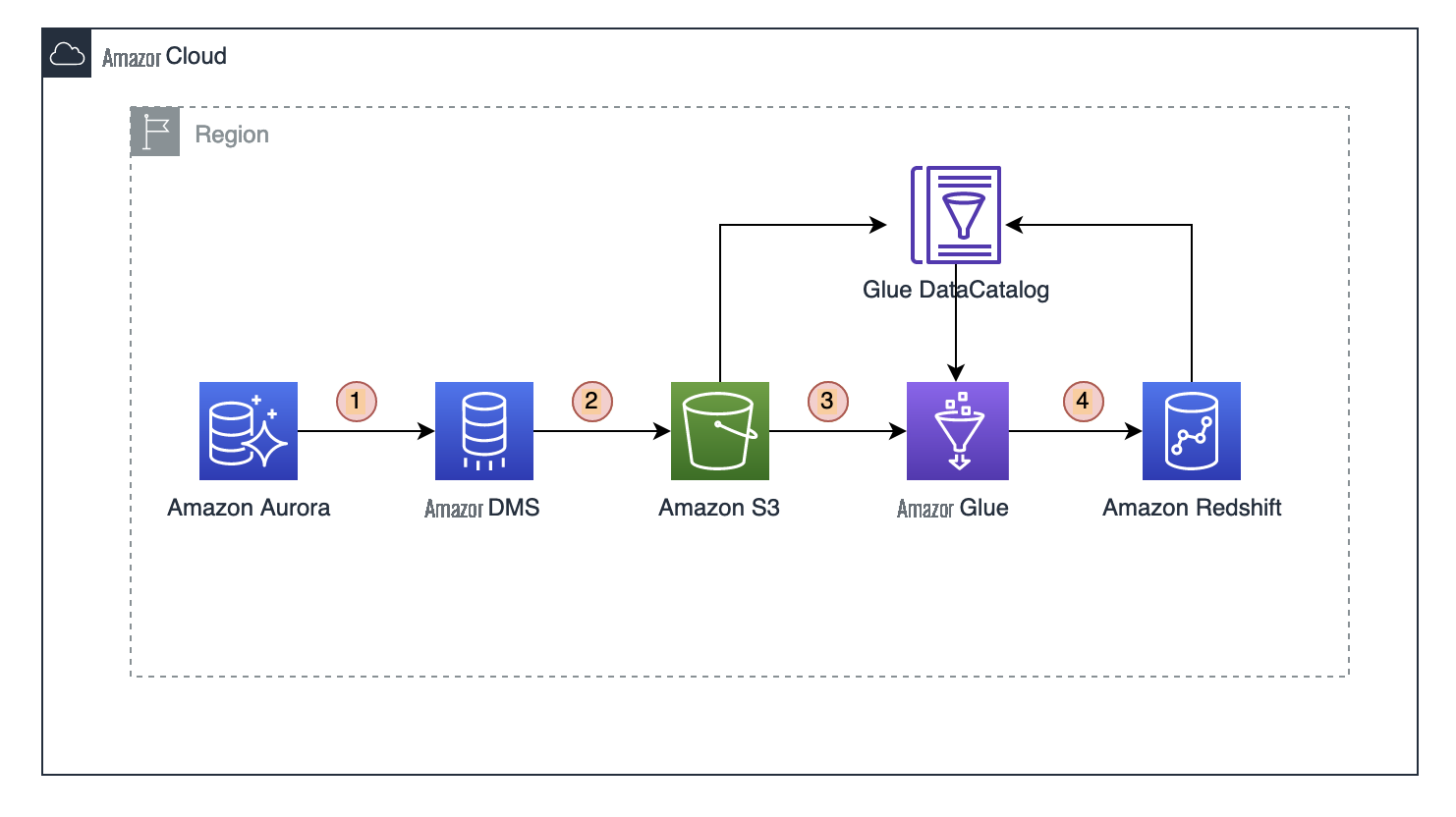
下图描述了我们解决方案的高级架构。该解决方案将 ETL 和分析工作负载与我们的交易数据源 Amazon Aurora 分离,并使用 Amazon Redshift 作为数据仓库解决方案来构建数据集市。在此解决方案中,我们使用 亚马逊云科技 数据库迁移服务 (亚马逊云科技 DMS) 对来自 Aurora 的更改进行满载和持续复制。亚马逊云科技 DMS 使我们能够通过使用更改数据捕获 (CDC) 配置来捕获增量数据,包括从源数据库中删除的内容。DMS 中的 CDC 使我们能够在不编写代码的情况下捕获增量数据,也不会遗漏任何更改,这对于数据的完整性至关重要。请参阅 DMS 中的 CDC 支持,以扩展正在进行的 CDC 的解决方案。
工作流程包括以下步骤:
-
亚马逊云科技 数据库迁移服务 (亚马逊云科技 DMS) 连接到 Aurora 数据源。 -
亚马逊云科技 DMS 从 Aurora 复制数据并迁移到目标目标 A
mazon Simple Storage Service (Amazon S3) 存储 桶。 - 亚马逊云科技 Glue 爬虫会自动推断 S3 数据的架构信息并集成到 亚马逊云科技 Glue 数据目录中。
- 亚马逊云科技 Glue 任务运行 ETL 代码来转换数据并将其加载到亚马逊 Redshift。
在这篇文章中,我们使用
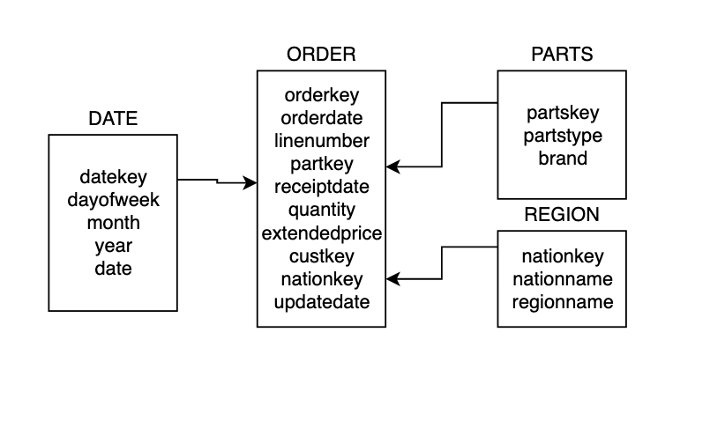
我们使用亚马逊 Redshift 作为数据仓库来实施数据集市解决方案。数据集市事实和维度表是在亚马逊 Redshift 数据库中创建的。下图说明了事实(订单)和维度表(日期、部件和区域)之间的关系。
设置环境
首先,我们使用
-
使用您
的 AW 。S 身份和访问管理 (IAM) 用户名和 密码登录 亚马逊云科技 管理控制台 -
选择
Launch Stack
并在新选项卡上打开页面:

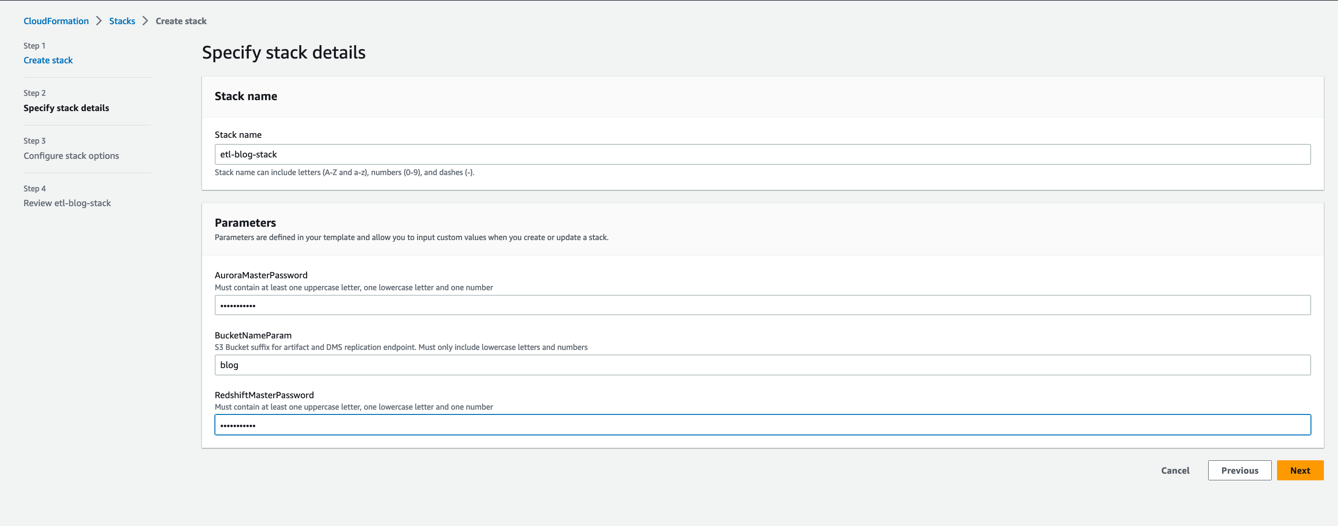
- 选择 “ 下一步 ” 。
- 在 堆栈名称 中 ,输入一个名称。
- 在 参数 部分中,输入所需的参数。
- 选择 “ 下一步 ” 。
- 在 配置堆栈选项 页面上,将所有值保留为默认值,然后选择 下一步 。
- 在 审查堆栈 页面上,选中复选框以确认 IAM 资源的创建。
- 选择 “ 提交 ” 。
等待堆栈创建完成。您可以在 “事件 ” 选项卡上检查堆栈创建过程中的各种 事件 。堆栈创建完成后,您将看到状态为 CREATE_ COMPLETE。堆栈大约需要 25—30 分钟才能完成。
此模板配置以下资源:
-
Aurora MySQL 实例
销售数据库。 -
亚马逊云科技 DMS 任务 d
msreplicationtask-*用于满载数据并将更改从 Aurora(来源)复制到 Amazon S3(目标)。 -
亚马逊云科技 Glue 爬虫 s3-crawler 和 re dshift_crawler。 -
亚马逊云科技 Glue 数据库 s
alesdb。 -
AWS Glue 任务insert_region_dim_tbl、insert_parts_dim_tbl 和 insert_date_dim_tbl。al Studio 手动创建 insert_orders_fact_tbl亚马逊云科技 Glue 任务。 -
包含数据库销售额以及事实和维度表的 Redshift
集群 blog_cluster。 - 用于存储 亚马逊云科技 Glue 任务输出的 S3 存储桶正在运行。
- 具有适当权限的 IAM 角色和策略。
将数据从 Aurora 复制到亚马逊 S3
现在让我们来看看使用 亚马逊云科技 DMS 将数据从 Aurora 复制到亚马逊 S3 的步骤:
- 在 亚马逊云科技 DMS 控制台上,选择导航窗格 中的 数据库迁移任务 。
-
选择任务
dmsreplicationtask-*,然后在 “操作” 菜单上选择 “ 重新启动/恢复”。
这将启动复制任务,将数据从 Aurora 复制到 S3 存储桶。等待任务状态更改为 “
满负荷完成
” 。现在,来自 Aurora 表的数据已复制到新文件夹 sal
es
下的 S3 存储桶中 。
创建 亚马逊云科技 Glue 数据目录表
现在让我们为 S3 数据和亚马逊 Redshift 表创建 亚马逊云科技 Glue 数据目录表:
- 在 亚马逊云科技 Glue 控制台上, 在导航窗格的 数据目录 下,选择 连接 。
-
选择
RedshiftConnection,然后在 “ 操作 ” 菜单上选择 “编辑”。 - 选择 “ 保存更改 ” 。
- 再次选择连接,然后在 “ 操作 ” 菜单上选择 “ 测试连接 ” 。
-
对于
IAM 角色
,请选择
glueBlogRole。 - 选择 “ 确认 ” 。
测试连接可能需要大约 1 分钟。您将看到
“通过连接 blog-redshift-connection 成功连接到数据存储” 消息。
如果您在成功连接时遇到问题,请参阅
- 在导航窗格的 数据目录 下,选择 爬虫 。
-
选择
s3_crawler,然后选择 “运行”。
这将在 亚马逊云科技 Glue 数据目录中生成八张表。要查看创建的表,请在导航窗格中选择 “
数据目录
” 下的 “
数据库
” ,然后选择 s
alesdb
。
-
重复这些步骤来运行
redshift_crawler并生成另外四个表。
如果爬虫失败,请参阅
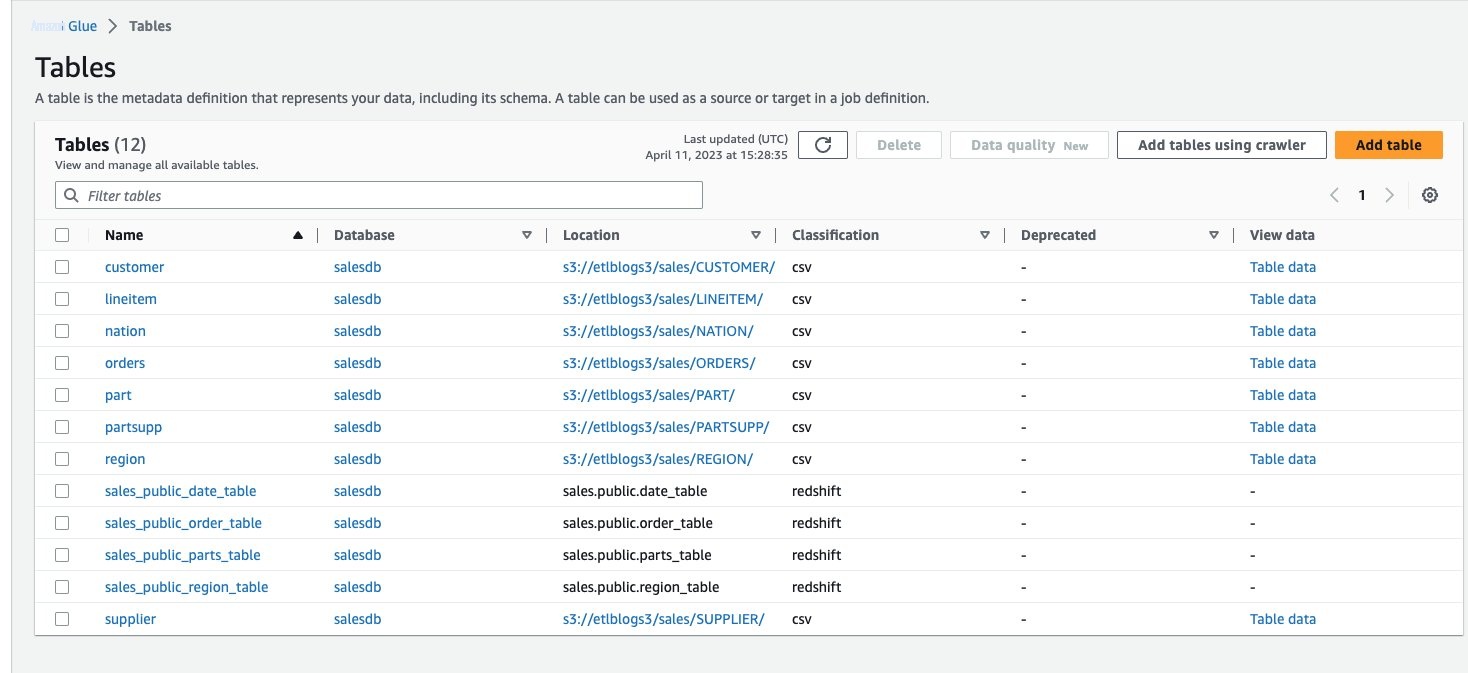
创建基于 SQL 的 亚马逊云科技 Glue 任务
现在让我们来看看如何使用 SQL 语句通过 亚马逊云科技 Glue 创建 ETL 任务。亚马逊云科技 Glue 在 Apache Spark 无服务器环境中运行您的 ETL 任务。亚马逊云科技 Glue 在其自己的服务账户中预置和管理的虚拟资源上运行这些任务。亚马逊云科技 Glue Studio 是一个图形界面,可以轻松地在 亚马逊云科技 Glue 中创建、运行和监控 ETL 任务。您可以使用 亚马逊云科技 Glue Studio 创建任务,从数据源提取结构化或半结构化数据,对该数据进行转换,并将结果集保存在数据目标中。
让我们来看一下使用 亚马逊云科技 Glue Studio 创建用于加载订单情况表的 亚马逊云科技 Glue 任务的步骤。
- 在 亚马逊云科技 Glue 控制台上,选择导航窗格 中的 任务 。
- 选择 创建作业 。
- 选择 带有空白画布的 Visual ,然后选择 “ 创建 ” 。

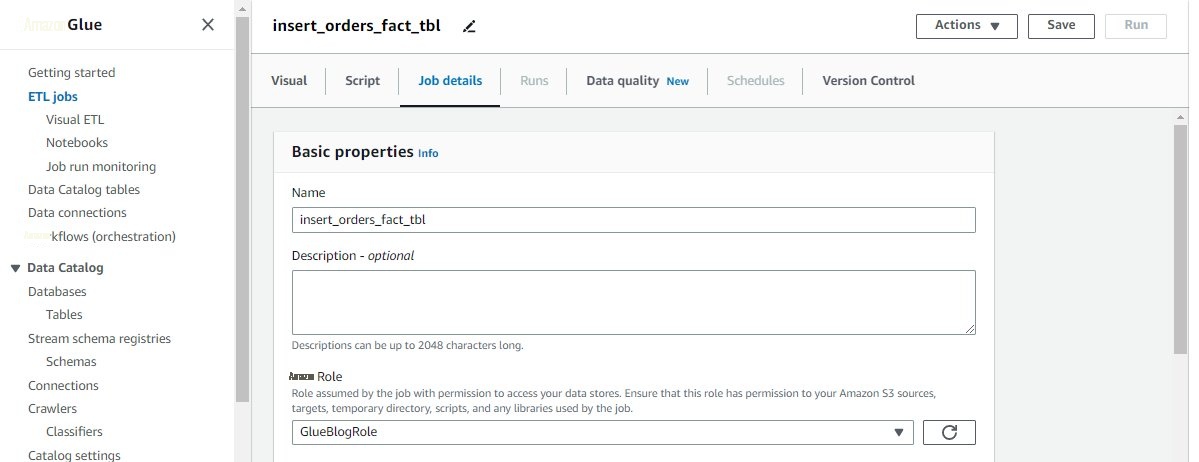
- 导航到 作业详细信息 选项卡。
-
在 “
名称
” 中,输入
insert_orders_fact_tbl。 -
对于
IAM 角色
,请选择
glueBlogRole。 - 对于 “ 作业书签 ” ,选择 “ 启用 ” 。
- 将所有其他参数保留为默认值,然后选择 保存 。
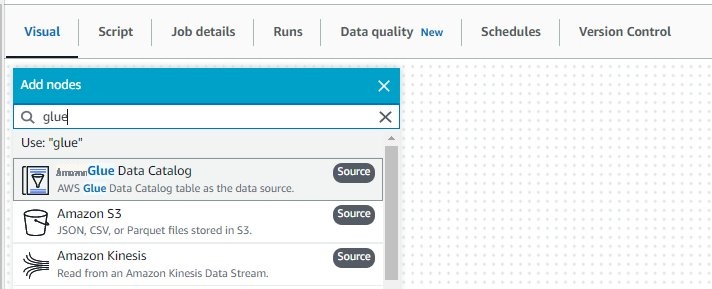
- 导航到 “ 可视 ” 选项卡。
- 选择加号。
- 在 添加节点 下 ,在搜索栏中输入 Glue,然后选择 亚马逊云科技 Glue 数据目录 (来源) 以将数据目录添加为源。
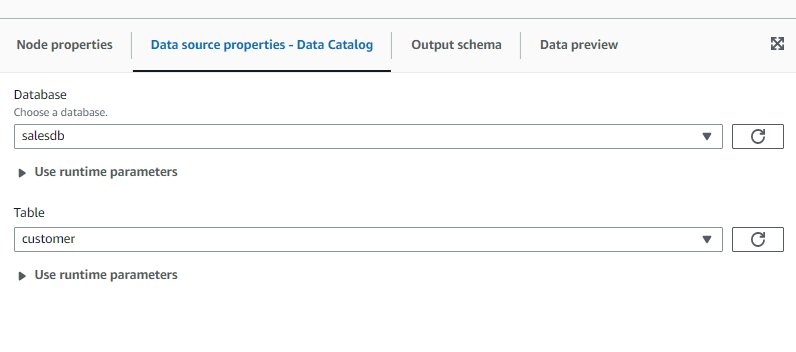
-
在右窗格的 “
数据源属性-数据目录
” 选项卡上, 为
数据库
选择 s
alesdb,为 表 选择 c ustomer。
-
在
节点属性
选项卡上,在
名称
中输入
客户。
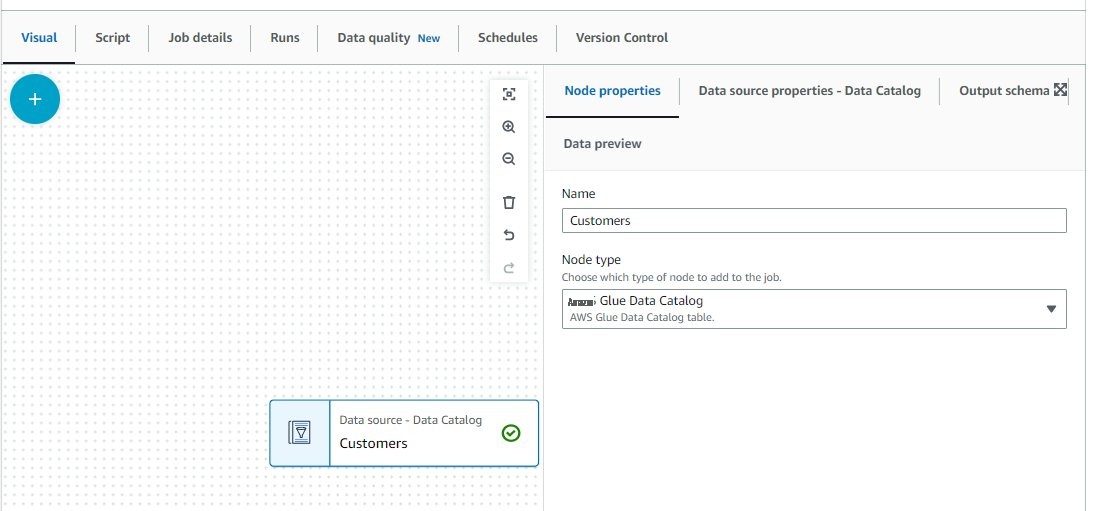
-
对订单 和 订单项表重复这些步骤。
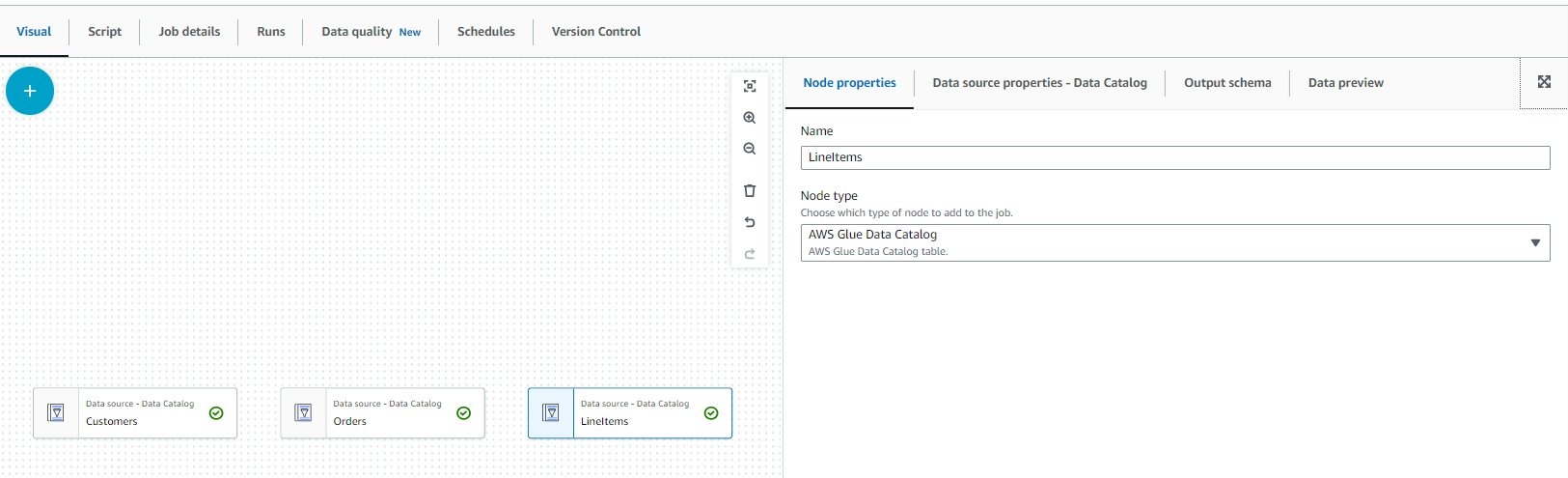
在 亚马逊云科技 Glue 任务画布上创建数据源到此结束。接下来,我们通过组合来自这些不同表的数据来添加转换。
转换数据
完成以下步骤以添加数据转换:
- 在 亚马逊云科技 Glue 作业画布上,选择加号。
- 在 “ 转换 ” 下 ,选择 SQL 查询 。
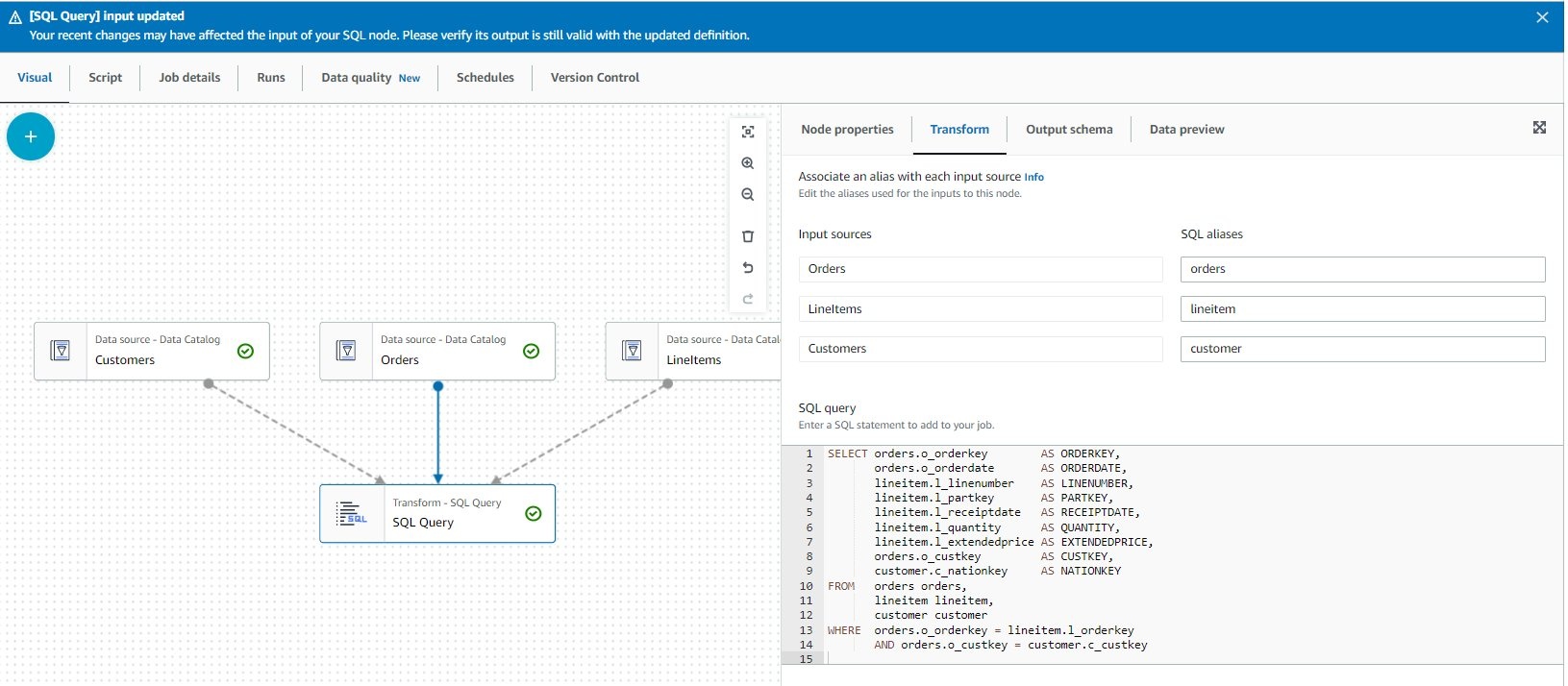
- 在 转换 选项卡上,对于 节点父节点 ,选择所有三个数据源。
- 在 “ 转换 ” 选项卡上的 “ SQL 查询 ” 下 ,输入以下查询:
- 更新 S QL 别名 值,如以下屏幕截图所示。
- 在 数据预览 选项卡上,选择 启动数据预览会话 。
-
出现提示时,选择
GlueBlogRole作 为 IAM 角色 ,然后选择确认。
数据预览过程需要一分钟才能完成。
- 在 输出架构 选项卡上,选择 使用数据预览架构 。
您将看到类似于以下屏幕截图的输出架构。
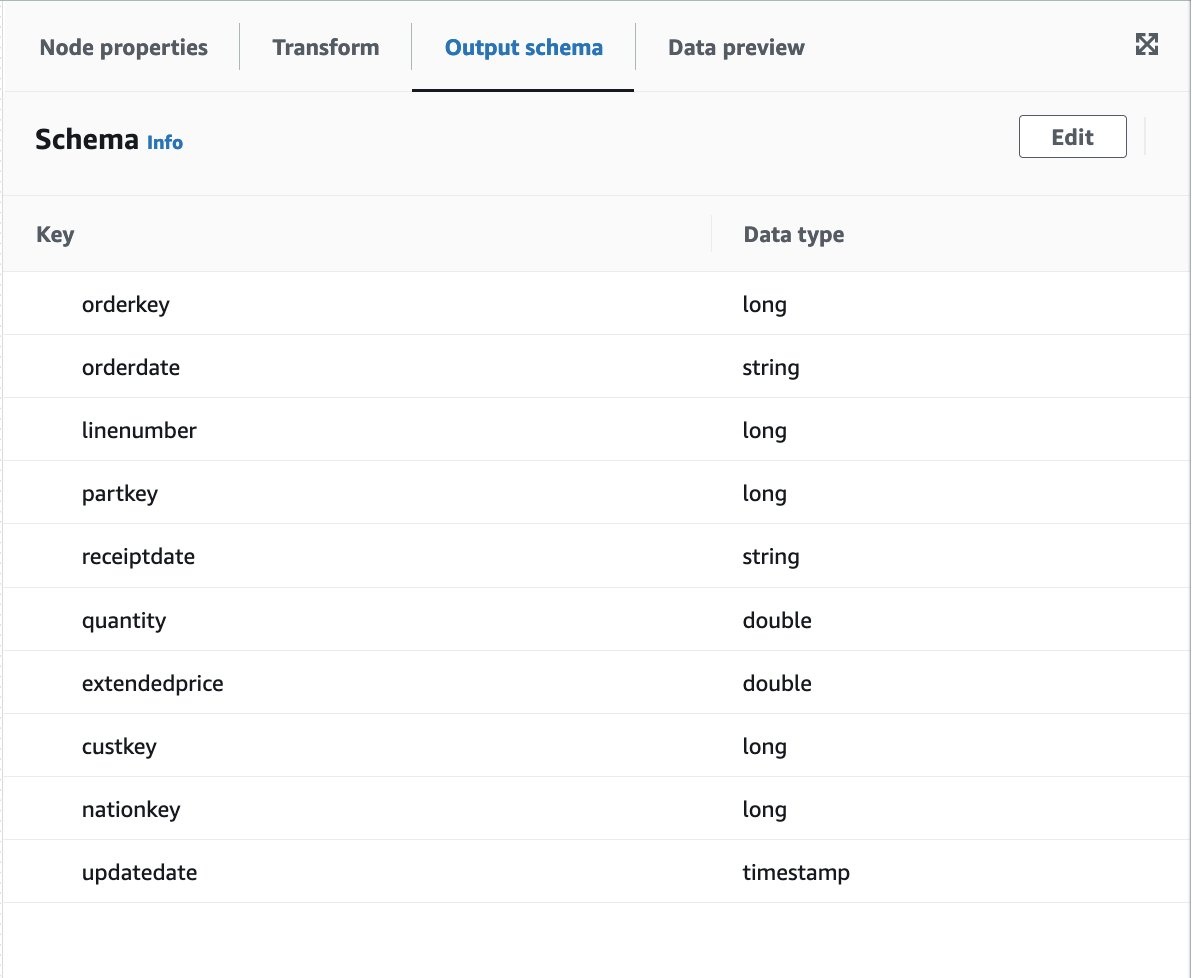
现在我们已经预览了数据,我们更改了一些数据类型。
- 在 亚马逊云科技 Glue 作业画布上,选择加号。
- 在 “ 转换 ” 下 ,选择 “ 更改架构 ” 。
- 选择节点。
- 在 转换 选项卡上,更新 数据类型 值,如以下屏幕截图所示。
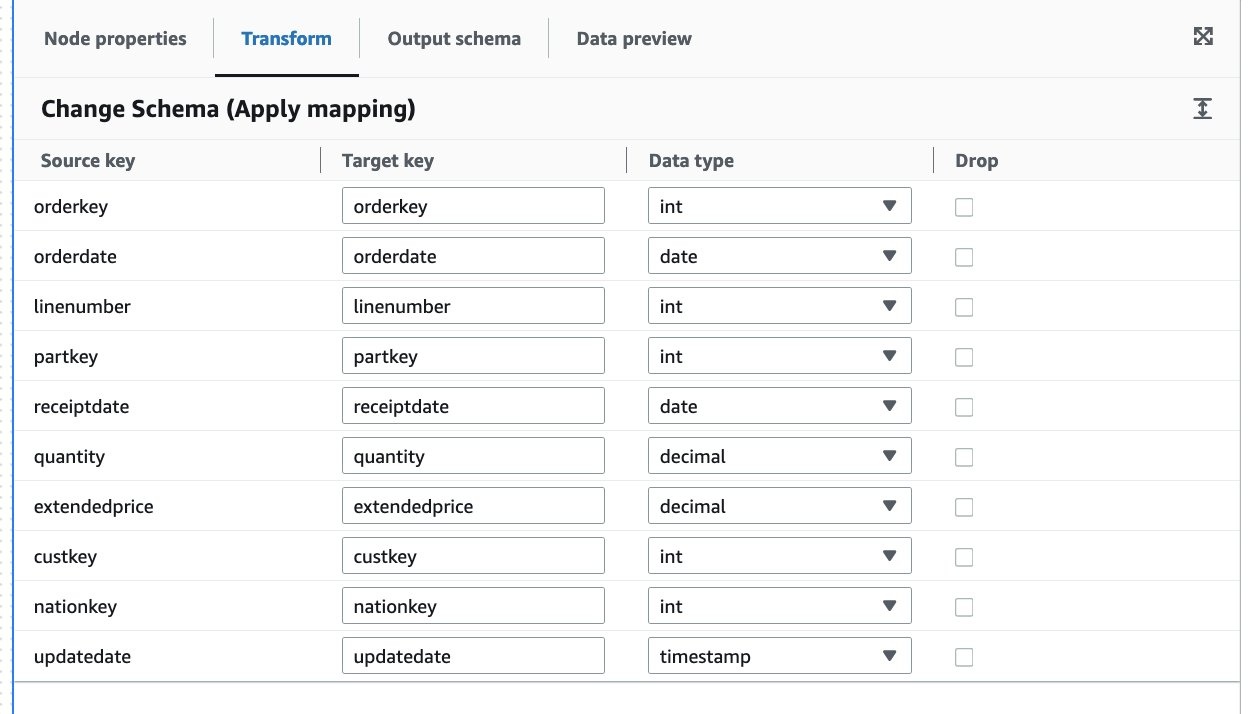
现在让我们添加目标节点。
- 选择 “ 更改架构 ” 节点并选择加号。
- 在搜索栏中,输入目标。
- 选择 亚马逊 Redshift 作为目标。
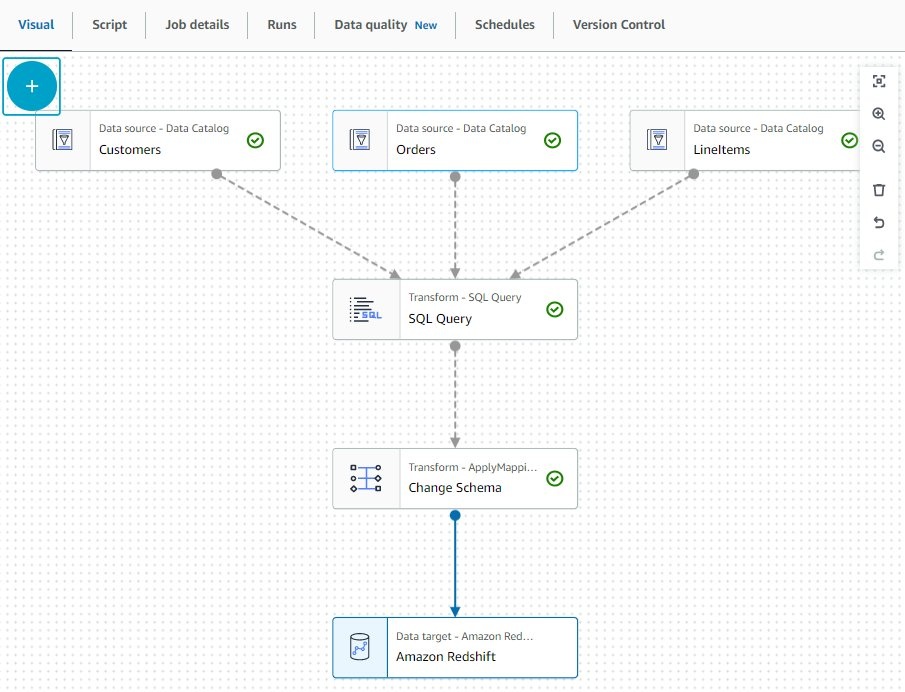
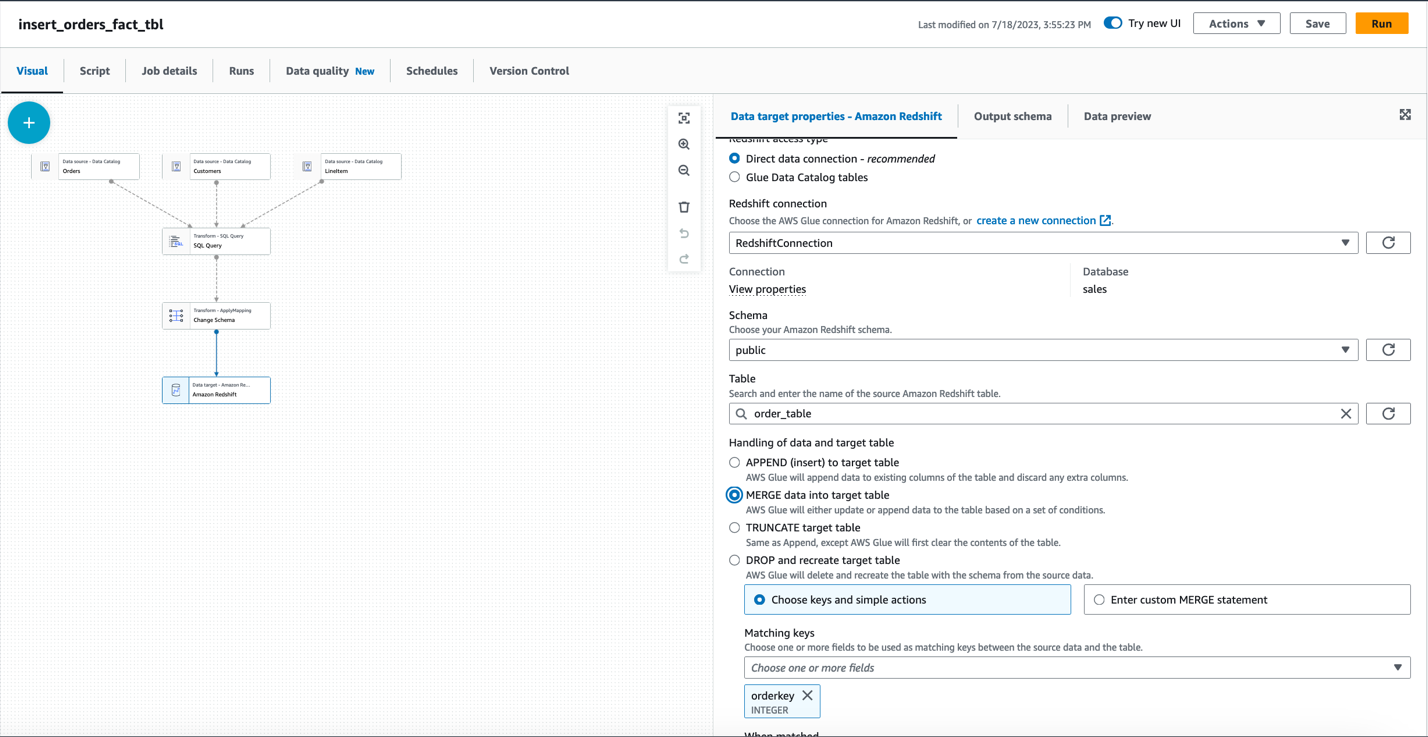
- 选择 Amazon Redshift 节点,然后在 数据目标属性 — Amazon Redshift 选项卡上, 对于 Redshift 访问类型 , 选择直接数据连接。
-
为Redshif t 连接选择 redshiftConnec tion, 为 架构 选择 public,为表格选择 ord er_tab le - 在 “ 处理 数据和目标表” 下选择 “将数据 合并到 目标表中 ” 。
-
为
匹配
密钥选择订购密钥 。
- 选择 “ 保存” 。
亚马逊云科技 Glue Studio 会自动为你生成 Spark 代码。您可以在 “
脚本
” 选项卡上查看它。如果你想进行任何开箱即用的转换,你可以修改 Spark 代码。亚马逊云科技 Glue 任务使用 Apache SparkSQL 查询进行 SQL 查询转换。要查找可用的 SparkSQL 转换,请参阅
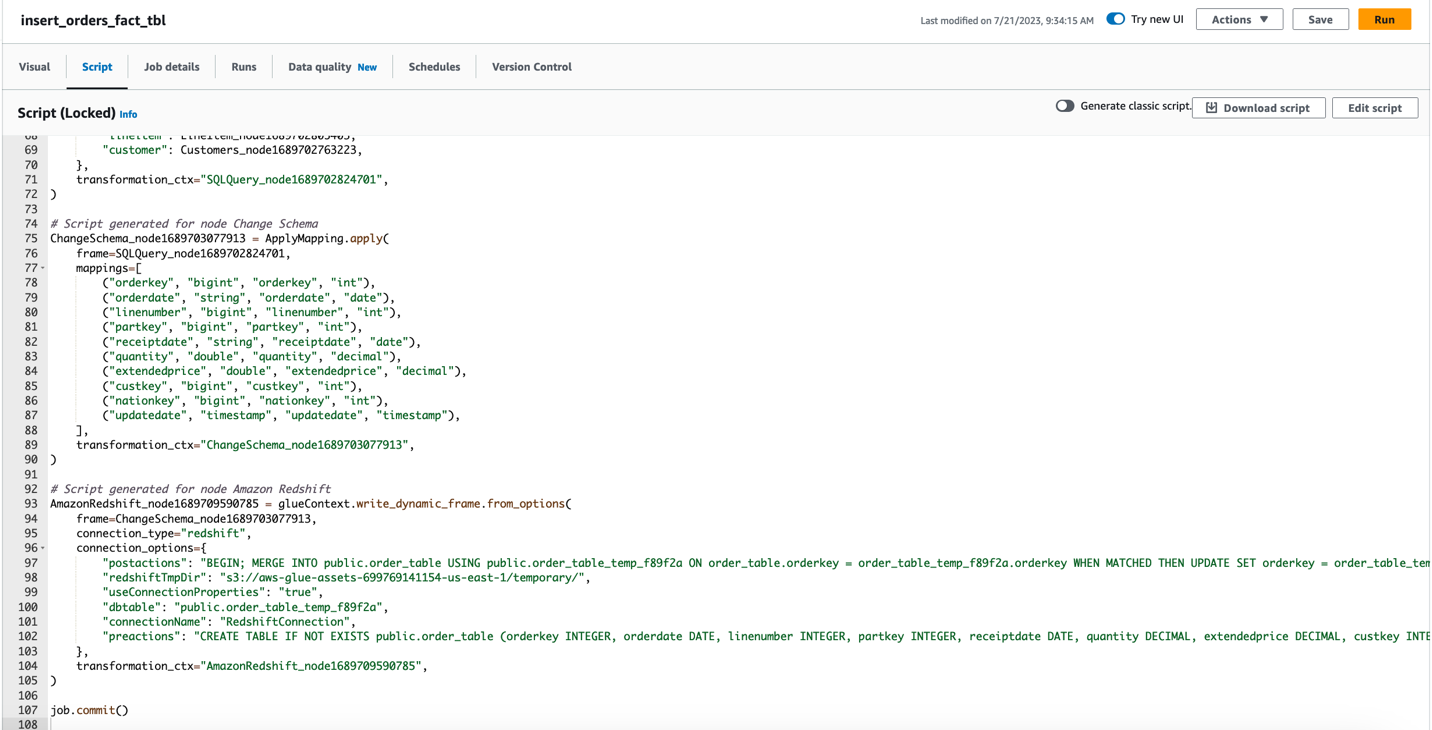
- 选择 “ 运行 ” 来运行作业。
作为 CloudFormation 堆栈的一部分,还创建了另外三个任务来加载维度表。
-
导航回 亚马逊云科技 Glue 控制台上的
任务 页面,选择任务
insert_
parts_dim_tbl,然后选择运行。
此作业使用以下 SQL 来填充部件维度表:
-
选择作业
insert_region_dim_tbl并选择 “运行”。
此作业使用以下 SQL 来填充
区域
维度表:
-
选择作业
insert_date_dim_tbl并选择 “运行”。
此作业使用以下 SQL 来填充
日期
维度表:
您可以通过导航到作业 页面上的作业运行 监控 部分来查看正在运行的 作业 的状态。等待所有任务完成。这些任务会将数据加载到亚马逊 Redshift 中的事实和维度表中。
为了帮助优化资源和成本,您可以使用
验证亚马逊 Redshift 数据加载情况
要验证数据加载,请完成以下步骤:
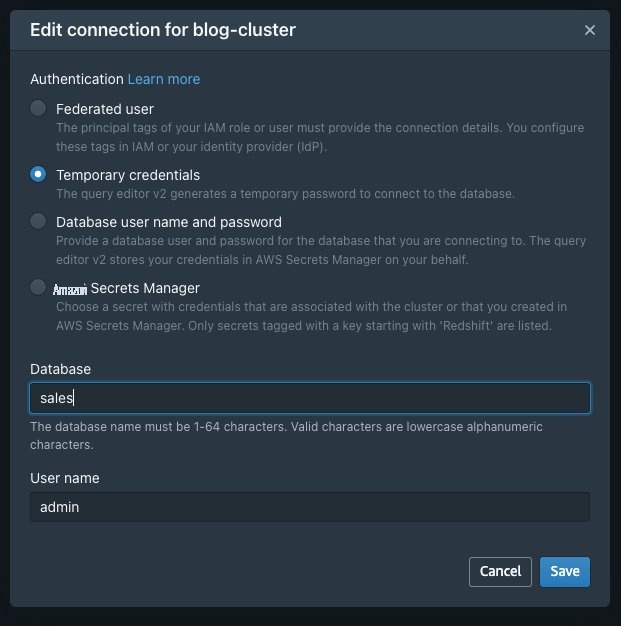
- 在 Amazon Redshift 控制台上,选择集群博客集群,然后在 “ 查询数据 ” 菜单上选择 “在查询编辑器 2 中 查询 ”。
- 对于 身份验证 ,选择 临时证书 。
-
在
数据库中
,输入
销售额。 -
在
用户名
中,输入
admin。 - 选择 “ 保存” 。
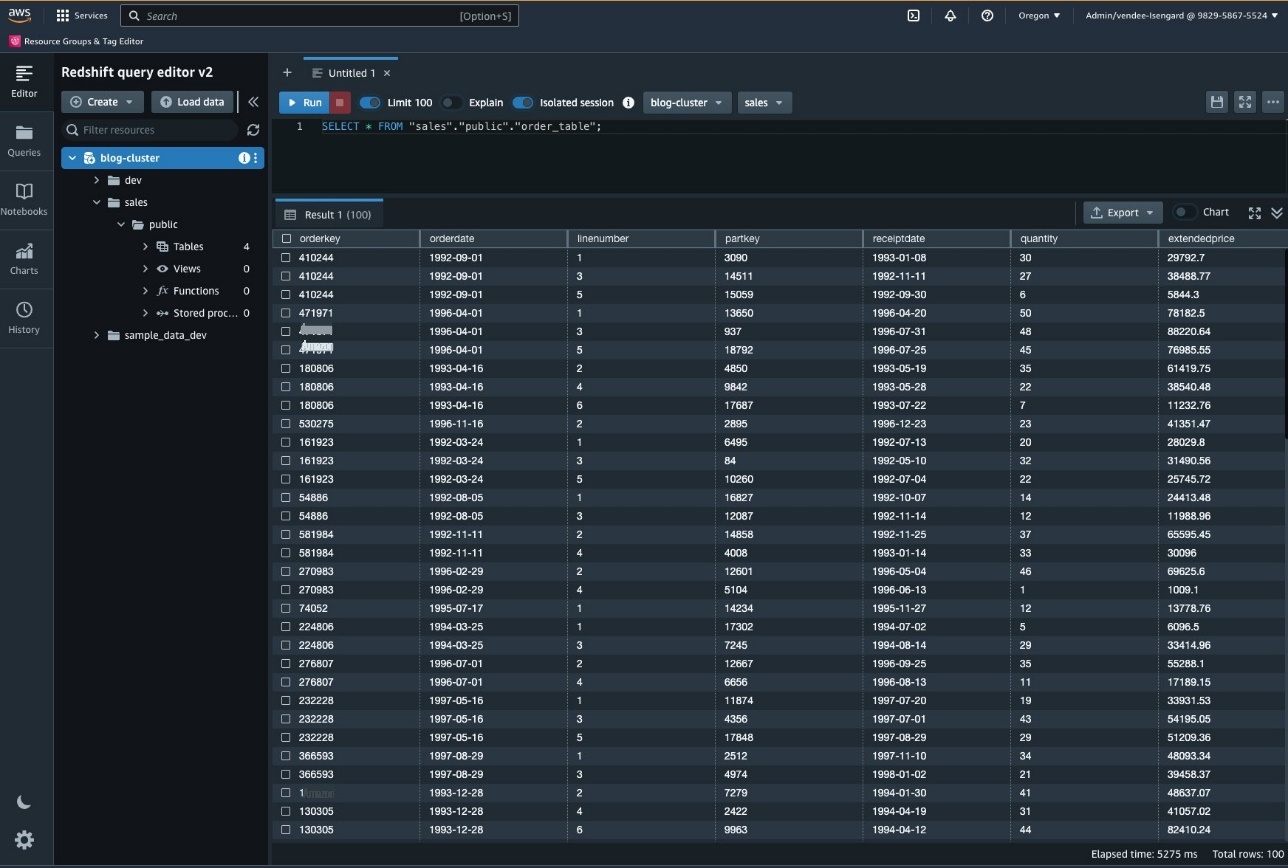
- 在查询编辑器中运行以下命令以验证数据是否已加载到 Amazon Redshift 表中:
以下屏幕截图显示了其中一个 SELECT 查询的结果。
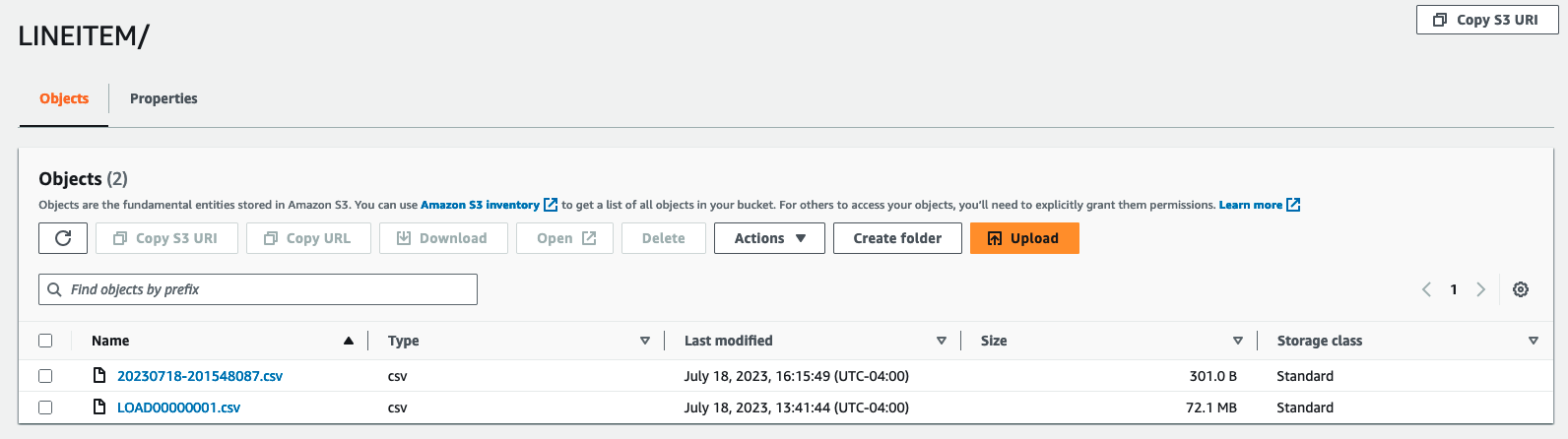
现在,对于CDC,使用以下查询更新 Aurora 数据库中订单号 1 的订单商品的数量。(要连接到您的 Aurora 集群,请使用
DMS 会将更改复制到 S3 存储桶中,如以下屏幕截图所示。
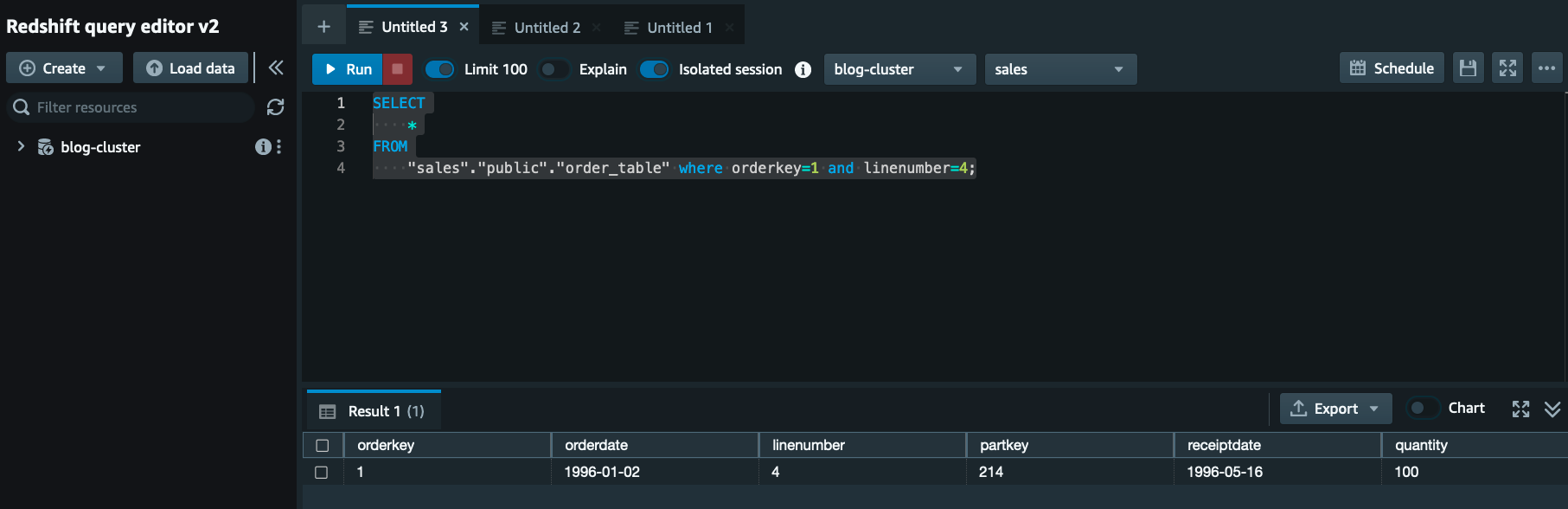
重新运行 Glue 作业
insert_orders_fact_tbl 将更新订单
事实表的更改,如下面的屏幕截图所
示
清理
为避免将来产生费用,请删除为解决方案创建的资源:
- 在 Amazon S3 控制台上,选择作为 CloudFormation 堆栈一部分创建的 S3 存储桶,然后选择 清空。
- 在 亚马逊云科技 CloudFormation 控制台上,选择您最初创建的堆栈,然后选择 删除 以删除该堆栈创建的所有资源。
结论
在这篇文章中,我们展示了如何使用 亚马逊云科技 Glue 任务将基于 SQL 的现有 ETL 迁移到 亚马逊云科技 无服务器 ETL 基础设施。我们使用 亚马逊云科技 DMS 将数据从 Aurora 迁移到 S3 存储桶,然后使用基于 SQL 的 亚马逊云科技 Glue 任务将数据移至亚马逊 Redshift 中的事实表和维度表。
该解决方案演示了使用 亚马逊云科技 Glue 任务从 Aurora 向亚马逊 Redshift 进行一次性数据加载。您可以扩展此解决方案,通过使用
作者简介
 Mitesh Pate
l 是 亚马逊云科技 的首席解决方案架构师,专门研究数据分析和机器学习。他热衷于帮助客户在 亚马逊云科技 中构建可扩展、安全且具有成本效益的云原生解决方案,以推动业务增长。他与妻子和两个孩子住在华盛顿特区都会区。
Mitesh Pate
l 是 亚马逊云科技 的首席解决方案架构师,专门研究数据分析和机器学习。他热衷于帮助客户在 亚马逊云科技 中构建可扩展、安全且具有成本效益的云原生解决方案,以推动业务增长。他与妻子和两个孩子住在华盛顿特区都会区。
 Sumitha AP 是 A
WS 的高级解决方案架构师。她与客户合作,通过在 亚马逊云科技 云中设计安全、可扩展、可靠且经济实惠的解决方案,帮助他们实现业务目标。她专注于数据和分析,并为在 亚马逊云科技 上构建分析解决方案提供指导。
Sumitha AP 是 A
WS 的高级解决方案架构师。她与客户合作,通过在 亚马逊云科技 云中设计安全、可扩展、可靠且经济实惠的解决方案,帮助他们实现业务目标。她专注于数据和分析,并为在 亚马逊云科技 上构建分析解决方案提供指导。
 Deepti Venuturumilli
是 亚马逊云科技 的高级解决方案架构师。她与商业领域客户和 亚马逊云科技 合作伙伴合作,通过提供 亚马逊云科技 服务方面的专业知识和实现工作负载现代化来加速客户的业务成果。她专注于数据分析工作负载和在 亚马逊云科技 上制定现代数据策略。
Deepti Venuturumilli
是 亚马逊云科技 的高级解决方案架构师。她与商业领域客户和 亚马逊云科技 合作伙伴合作,通过提供 亚马逊云科技 服务方面的专业知识和实现工作负载现代化来加速客户的业务成果。她专注于数据分析工作负载和在 亚马逊云科技 上制定现代数据策略。
 Deepthi Paruchuri
是一名驻纽约的 亚马逊云科技 解决方案架构师。她与客户紧密合作,通过在 亚马逊云科技 云中设计安全、可扩展且经济实惠的解决方案,制定云采用策略并解决他们的业务需求。
Deepthi Paruchuri
是一名驻纽约的 亚马逊云科技 解决方案架构师。她与客户紧密合作,通过在 亚马逊云科技 云中设计安全、可扩展且经济实惠的解决方案,制定云采用策略并解决他们的业务需求。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。