我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
将 PostgreSQL 从谷歌云平台迁移到亚马逊 RDS,停机时间最短
在这篇文章中,我们将向您介绍将 PostgreSQL 数据库从谷歌云平台 (GCP) Cloud SQL 迁移到适用于 PostgreSQL 的
为了完成这项任务,我们使用了
在这篇文章中,我们执行了示例数据库迁移并描述了分步方法。我们使用的示例数据库数据可以在以下
解决方案概述
以下架构图描述了迁移过程中涉及的组件。
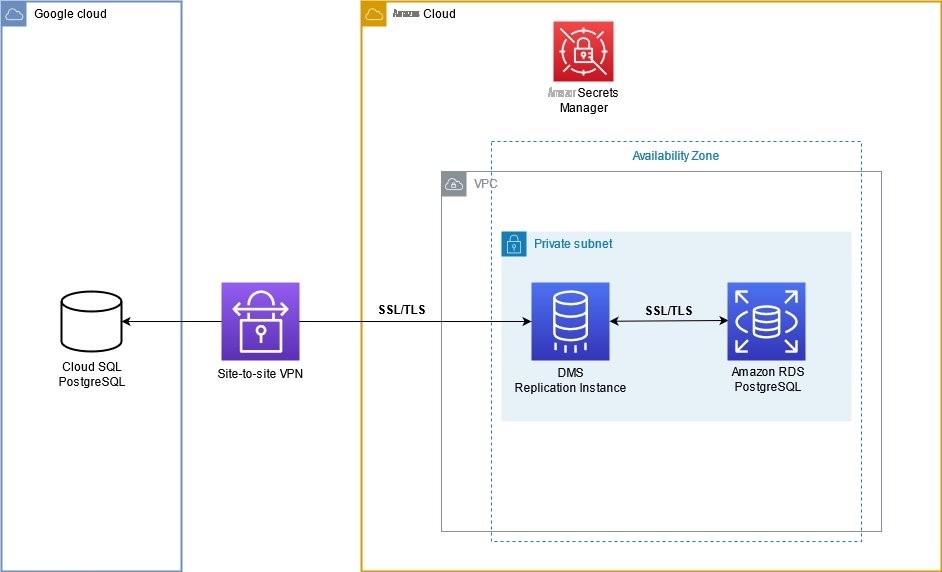
我们建议您使用 GCP 和 亚马逊云科技 之间的点对点虚拟专用网络 (VPN) 连接。我们在私有子网中创建一个 亚马逊云科技 DMS 复制实例,该复制实例通过安全套接字层 (SSL) 和传输层安全 (TLS) 连接连接到 GCP Cloud SQL 数据库。Amazon RDS 实例的流量也经过加密。默认情况下,亚马逊云科技 DMS 会加密复制实例上的静态数据。我们使用
亚马逊云科技 DMS 支持两种从 PostgreSQL 捕获变更数据的方法。一种方法是简单的 test_replica 扩展, 第二种方法是 p glogical 扩展。如果未配置 pglog ical 扩展名,则连接到源 PostgreSQL 数据库的数据库用户必须具有 SUPERUSER 属性。在 GCP Cloud SQL 中,用户 postgres 没有 “超级用户” 和 “复制” 属性,这就是任何尝试使用 postgres 用户捕获变更数据都失败的原因。
好消息是我们可以在 GCP Cloud SQL 数据库 上配置
pglo
gical。我们创建了一个单独的用户,该用户具有完成数据复制任务所需的系统属性和权限。
迁移步骤的总体概述:
- 创建用于复制的数据库用户,并在源 GCP Cloud SQL 上配置 pglogical。
- 将元数据从源数据库导入到 Amazon RDS。
- 创建 亚马逊云科技 DMS 复制实例、终端节点和迁移任务。
- 运行迁移任务并监控复制进度。
- 切换到适用于 PostgreSQL 的亚马逊 RDS。
准备 GCP 云 SQL 数据库以进行复制
首先,为复制连接创建用户。我们称这个用户帐户为 re
plicat
ion_user。以 postgres 用户身份连接到 GCP 云 SQL 实例并执行以下命令:
确保使用安全的密码。
现在我们配置 pglogical 扩展。 此步骤需要重启源数据库。在适当的时间范围内为您的服务计划短暂的停机时间。
- 在实例页面上,选择 “编辑” 以输入实例信息页面。
-
查找
Flags
部分并将其展开。
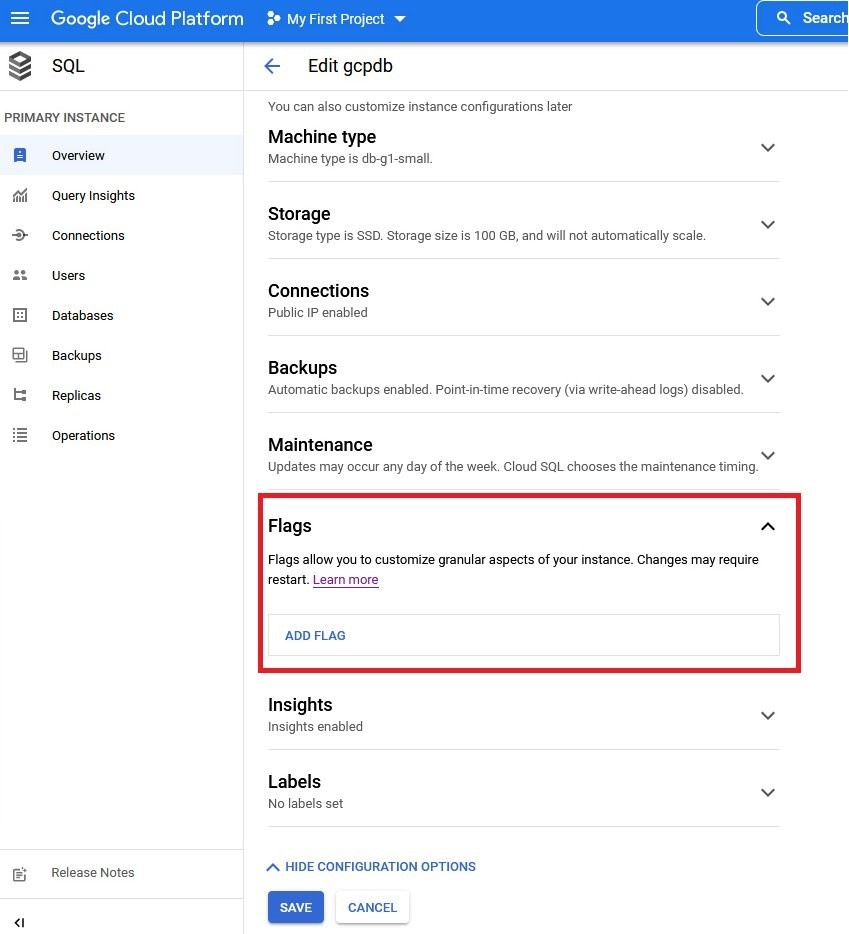
-
选择 ADD FLAG 并添加两个标志 cloudsql将两者的值都设置为 on 。选择 “保 存” 。数据库实例将重新启动。.logical_decoding 和 cloudsql.enable_pglogical。

- 以 postgres 用户身份连接并运行命令创建 p glogic 扩展名:
对于自行管理的 PostgreSQL 数据库,您可以直接在 postg
resql.conf 文件中设置所需的参数,如下
所示:
运行以下查询来检查安装情况:

5。向 rep
lication
_user 授予初始数据复制和 CDC 所需的权限:
在计划迁移的每个架构中的所有表 上授予
选择
权限。在这篇文章中,我们迁移了一个名为
dms_s
ample 的架构:
源表应具有主键或至少具有唯一索引。如果您无法创建主键或唯一索引,则可以通过更改表来 为这些表设置
副本身份
。有关该
副本身份
属性的更多详细信息,请查看 更改
L
,则会强制 PostgreSQL 将受影响表中所有列的旧值记录到日志流中。根据数据库中的列数和数据操作语言 (DML) 语句,它会显著影响生成的预写日志 (WAL) 的大小,并触发更频繁的检查点。频繁的检查点可能会对数据库性能产生负面影响。在这种情况下,可以考虑调整数据库实例的
max_wal_siz
e 参数。通常,建议尽可能避免使用
完整 副本身份
。
将元数据从源数据库导入到目标
这部分很简单。我们会将所有没有数据行的对象从 GCP Cloud SQL PostgreSQL 导出到 sql 文件中,然后在目标亚马逊 RDS for PostgreSQL 实例上运行此脚本。
在有权访问源数据库的 shell 中运行以下命令:
此命令以 DDL 命令的形式将所有元数据导出到名为 gcppg-schema.sql 的文件中。
在有权访问目标 Amazon RDS for PostgreSQL 实例的外壳中运行以下命令:
准备 亚马逊云科技 DMS 组件
亚马逊云科技 DMS 由以下组件组成:
-
复制实例 — 托管
亚马逊云科技 DMS 软件的托管亚马逊弹性计算云 (Amazon EC2) 实例。 - 端点-源数据库和目标数据库的连接描述。
- 数据库迁移任务-描述特定的数据加载和/或更改数据捕获 (CDC) 实例。
复制实例需要测试端点,而端点是定义迁移任务所必需的。由于这种依赖关系,我们将首先创建一个复制实例,然后是终端节点,最后是复制任务。
要创建复制实例,必须正确选择实例类型。所选的实例类型必须足够强大,能够处理源数据库上生成的初始数据负载和大量更改。有关如何选择实例类的更多信息,请参阅为
在 亚马逊云科技 DMS 管理控制台上,选择 复制实例 页面,然后选择 创建复制实例。
按照为
在我们的场景中,我们有几张小表和一张包含超过 1400 万条记录的大表
dms_sample.sporting_
event_ticket。为了最大限度地提高初始数据加载速度和变更数据应用速度,我们将配置两个复制任务。
第一个复制任务将完成小表的初始加载并开始为它们捕获持续的变更数据。第二项任务将对大表
dms_sample.sporting_event_
ticket 进行初始加载,然后启动该表的连续 CDC。由于此表很大,我们还将为其配置并行负载。我们将同时启动这两项迁移任务。
在初始加载和 CDC 阶段,触发器可能会在我们的目标数据库上产生意想不到的结果。在我们的示例数据库中,我们有插入后触发器和更新后触发器,它们会进行一些计算并将结果插入到第三个结果表中。亚马逊云科技 DMS 捕获所有表(包括第三张结果表)中的更改,并将这些更改应用到目标数据库。如果我们将触发器置于启用状态,则触发器会运行,并且表中会出现双重输入。为了避免此类逻辑损坏情况,我们禁用了 亚马逊云科技 DMS CDC 进程的触发器。
为了实现这种行为,我们可以使用会话级别 PostgreSQL 参数
此参数的值
副本
禁用所有触发器,包括内部触发器。由于 PostgreSQL 中的参照完整性是由内部触发器实现的,因此表之间的引用完整性被禁用。
我们在目标亚马逊 RDS
for PostgreSQL 实例上 将 session_
replication_role 参数设置为两个级别:
- 在实例级别上,通过修改实例参数组。由于此参数是动态的,因此无需重启实例。实例级别设置在初始数据加载阶段会有所帮助。在初始加载完成并且复制任务切换到连续更改数据应用模式后,我们将禁用此参数。
- 在 亚马逊云科技 DMS 上,CDC 应用连接级别。通过这种方式,我们可以确保变更数据应用流程始终设置了正确的会话环境,以消除不必要的结果和错误。
有关如何在实例级别上设置
session_replication_role
参数的说明,请参阅
亚马逊云科技 DMS 复制实例运行后,继续创建终端节点。我们需要两个终端节点:一个用于源 GCP 云 SQL 实例,另一个用于目标 Amazon RDS for PostgreSQL 实例。
源端点和目标端点
要创建安全的端点连接,我们需要以下内容:
-
亚马逊云科技 Secrets Manager 将源和目标终端节点的用户名和密码存储为机密。对于源 GCP Cloud SQL 实例,我们将使用之前创建的 re
plication_user 账户。对于 Amazon RDS 实例,我们将使用实例主账户(在本例中为 postgres用户)。 -
亚马逊云科技 身份和访问管理 (亚马逊云科技 IAM) 角色提供 亚马逊云科技 DMS 对 亚马逊云科技 Secrets Manager 机密的访问权限。 - GCP 云 SQL 和亚马逊 RDS 的中间证书和根证书。
要为 Amazon RDS for PostgreSQL 数据库实例创建 亚马逊云科技 Secrets Manager 密钥,请按照
您可以使用相同的说明为 GCP Cloud SQL 实例创建密钥;但是,对于
输入 GCP 云 SQL 实例的 IP 或 DNS 名称以及要连接到 PostgreSQL 实例的数据库的名称。如果您的 GCP Cloud SQL PostgreSQL 实例中有多个数据库要迁移,请为每个数据库创建 亚马逊云科技 Secrets Manager 密钥、源端点和迁移任务。
密钥类型
,为
其他数据库 选择 凭据,对于数据库
, 选择
Post
greSQL。
在本例中,我们创建了 亚马逊云科技 Secrets Manager 密钥: gcppg 用 于 GCP C loud SQL PostgreSQL 数据库, rdsp g 用于 PostgreSQL 实例。
现在,我们需要一个 IAM 角色来允许 亚马逊云科技 DMS 访问我们的机密。在 IAM 控制台中,进入 策略 视图并创建以下策略。将 ARN 替换为之前创建的 亚马逊云科技 Secrets Manager 密钥的 ARN,如以下代码所示:
切换到
角色
视图并使用 DMS 作为 亚马逊云科技 可信实体和之前创建的 IAM 策略创建角色。
确保以 dms 形式 将 DMS 区域服务负责人设置为可信实体。
dms.eu-central-1.amazonaws.com
。
最后一个先决条件是 PEM(增强隐私邮件)格式的中间证书和根证书。要下载适用于 Amazon RDS 的
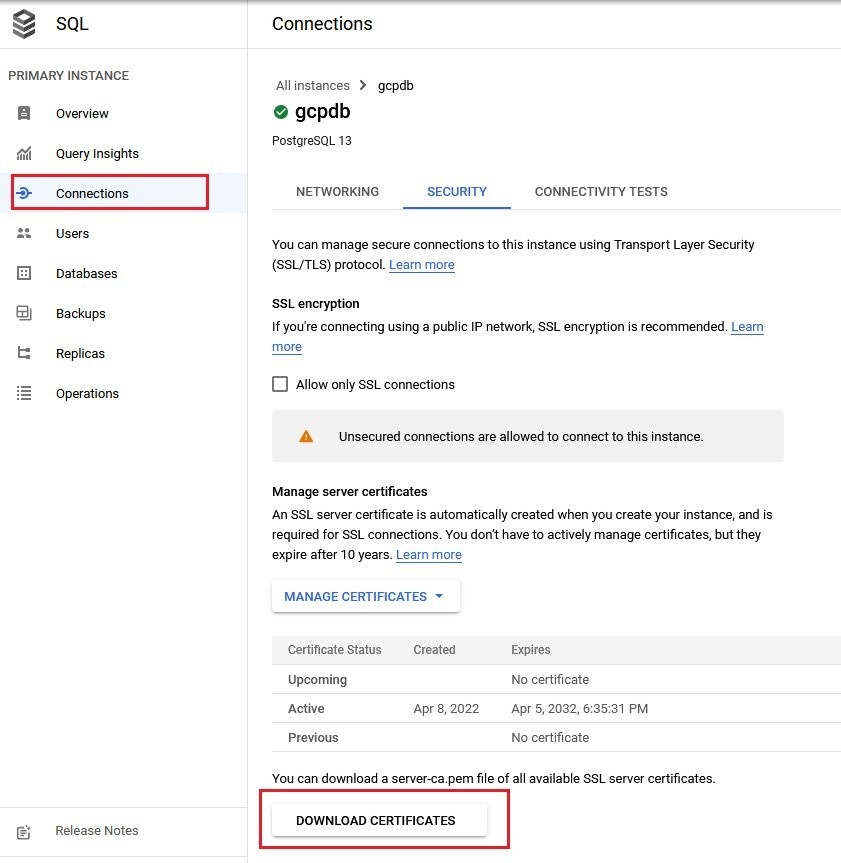
要从 GCP Cloud SQL 下载证书包,请执行以下操作:
- 转到您的数据库实例页面
- 从左侧菜单中选择 “ 连接 ” 。
-
选择 “
下载证书
” 按钮以下载证书包。
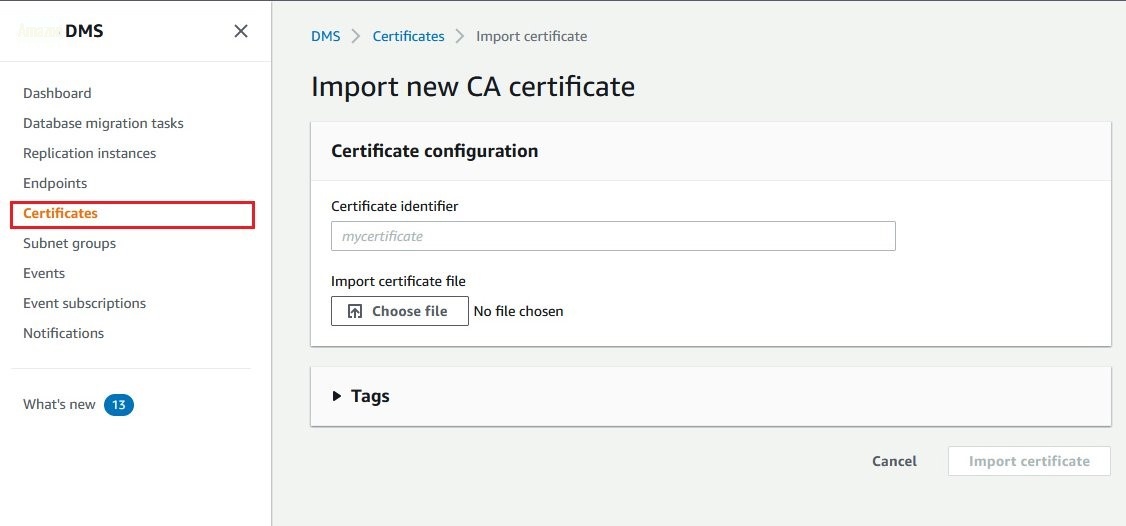
将这些证书包上传到 亚马逊云科技 DMS:
- 前往 亚马逊云科技 DMS 管理控制台。
- 从左侧菜单中选择 证书 。
-
选择 “
导入证书
” 按钮,然后
选择 要上传证书的文件
。
现在我们可以创建 亚马逊云科技 DMS 安全终端节点。
让我们从目标端点开始:
- 前往 亚马逊云科技 DMS 管理控制台。
- 从右侧菜单中选择 端点 。
- 选择 创建端点 按钮。
- 选择 目标端点 选项。
- 选 中 “选择 RDS 数据库实例 ” 复选框。
- 从下拉列表中选择适用于 PostgreSQL 的目标 Amazon RDS 实例。
- 在端点 标识符 文本框中输入此 端点 的名称。
- 选择 亚马逊云科技 Secret s Manager 作为终端节点数据库的访问权限。
- 输入为亚马逊 RDS for PostgreSQL 实例创建的 亚马逊云科技 Secrets Manager 密钥的 ARN。
- 输入之前为允许 亚马逊云科技 DMS 访问密钥而创建的 IAM 角色的 ARN。
- 对于 安全套接字层 (SSL) 模式 , 选择 verf y-ca。
- 选择为亚马逊 RDS 上传的 CA 证书 。
- 输入要连接的数据库名称。
- 在 “ 端点设置” 部分中,选择 “ 添加新设置 ”,然后 从可用 参数列表中选择 AfterConnectScript 。
-
在 “值” 字段中输入
SET session_replica_roleplica。这样,我们指示 AWS DMS 复制任务将 s它禁用 CDC 阶段的触发器和参照完整性。ession_replication_role 参数设置为副本,以 更改数据应用连接。
选择 “
创建端点
” 按钮

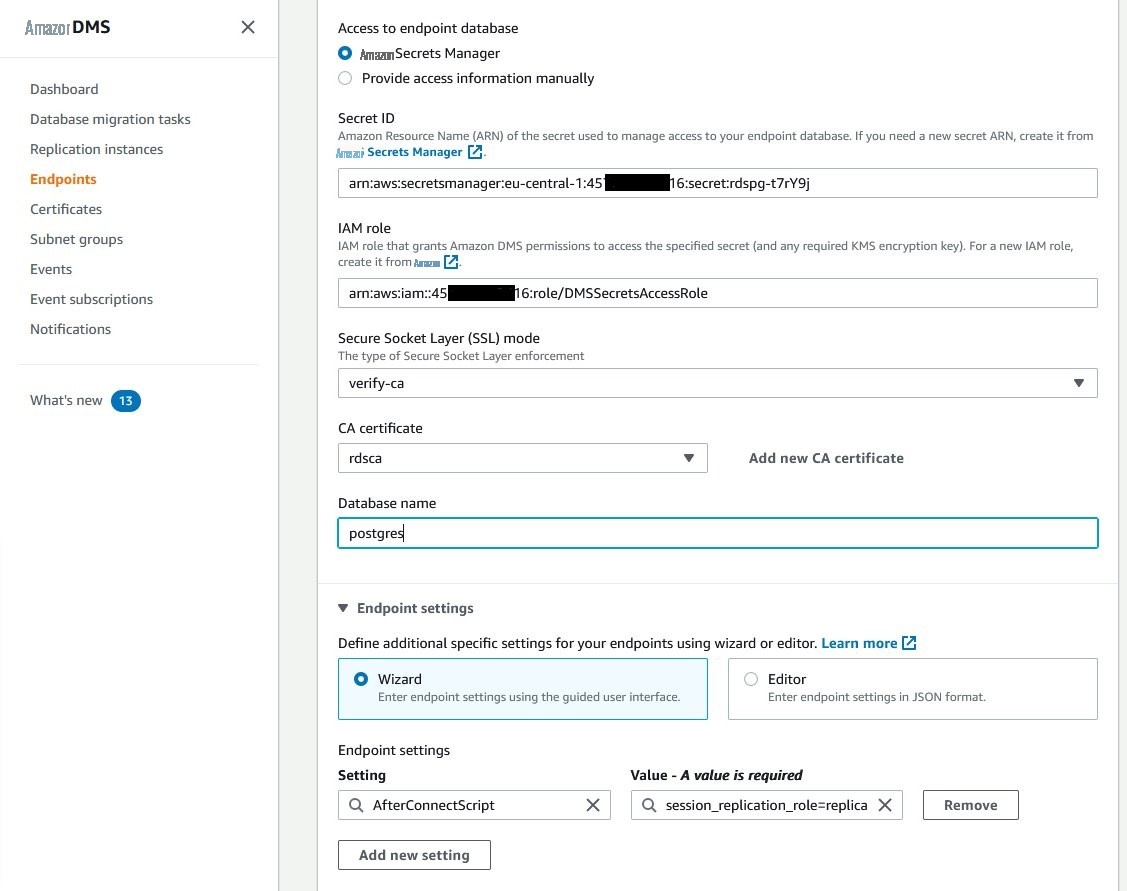
成功创建端点后,从列表中选择它,然后 从 操作 下 拉菜单中选择 测试连接 。测试必须成功才能使用此端点执行复制任务。
按照相同的步骤为 GCP 云 SQL PostgreSQL 创建源端点;但是,请选择 源 端点选项。
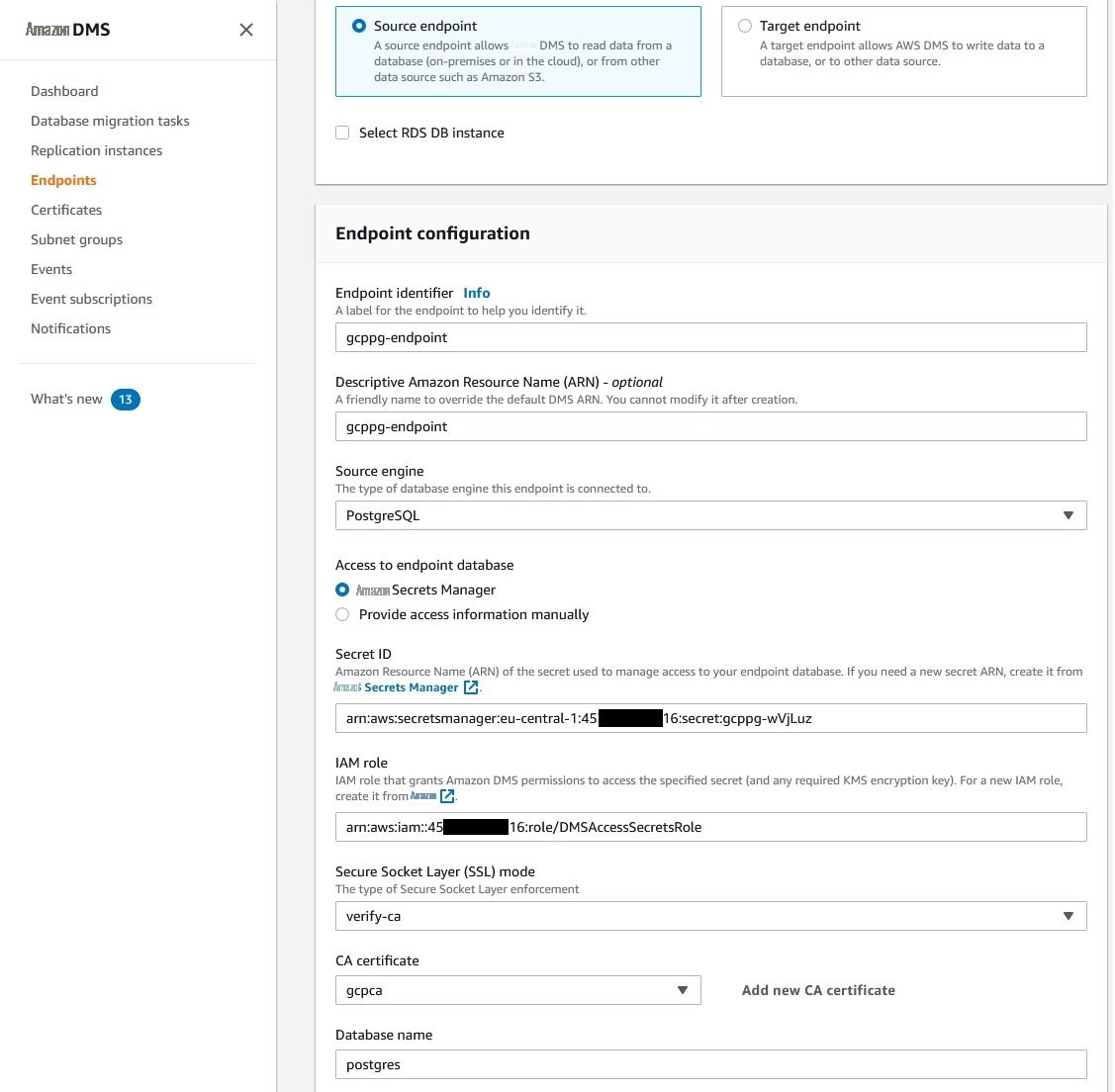
在我们成功测试了安全的源端点和目标端点以及复制实例之后,我们可以继续执行数据库迁移任务的创建步骤。
数据库迁移任务
我们将创建两个迁移任务。第一个复制并复制除最大表(
dms_sample.s
porting_event_ticket)之外的所有表的更改。第二个迁移任务并行复制并复制
dms_sample.sporting_event_t
icket 表。
要创建第一个迁移任务,请执行以下步骤:
- 在 亚马逊云科技 DMS 控制台上, 从右侧菜单中选择 数据库迁移任务 。
- 选择 创建任务 按钮打开任务创建视图。
- 在任务标 识符 文本框中输入 任务 的名称。
- 从 复制实例 下拉列表中,选择复制实例。
- 从 源数据库端点 下拉列表中,选择为 GCP Cloud SQL PostgreSQL 实例创建的源端点。
- 从 目标数据库终端节点 下拉列表中,选择为 Amazon RDS for PostgreSQL 实例创建的目标终端节点。
- 从 迁移类型 下拉列表中,选择 迁移现有数据并复制正在进行的更改 。
-
选中 “
在目标数据库上 创建恢复表
” 复选框,该复选框指示 亚马逊云科技 DMS 在目标数据库上创建
awsdms_txn_state 表。此表包含检查点信息,可用于解决 CDC 问题。 - 对于 T arget 表准备模式, 选择 “ 什么都不 做 ” (因为我们已经预先创建了架构)。
- 如果您希望 亚马逊云科技 DMS 在初始数据加载后比较源表和目标表中的所有数据,请选择 “ 启用验证 ” 复选框。只有具有主键或唯一索引的表才会被比较。
-
选中 “
启用 CloudWatch 日志
” 复选框,将 亚马逊云科技 DMS 日志导出到
亚马逊 CloudW atch 日志中。 - 在 高级任务设置 部分中,您可以设置一些参数来影响初始数据加载性能,例如,默认情况下,要并行加载的表数量和满载期间的提交率为 10000。我们会将提交率设置为 30000。
- 在 表映射 部分中,选择 添加新的选择规则 按钮。
-
在
架构
下拉列表中,选择
输入架构
。在
源名称
文本框字段中,输入要包含的架构的名称。(在本
例 中为 dms_sample
,区分大小写)。对于
表名
, 保留所有表 的值
%
。在 “
操作 ” 中,
选择 “
包括
” 。使用此规则,我们将所有表包含在架构
dms_sample 中。 -
选择 “
添加新选择规则
” 按钮。在
表格名称
文本框中,输入要排除的表的名称(在本例 中为 sp
orting_event_ticket, 区分大小写)。在 “ 操作 ” 中, 选择 “ 排除 ” 。 - 对于 “ 开始迁移任务 ”, 选择 “ 稍后 手动 ” 。创建了两个迁移任务后,我们并行启动它们。
- 选择 “ 创建任务 ” 按钮。
为了并行加载未分区的
dms_sample.sporting_event_t
icket 表,我们将其拆分为几个逻辑分区。我们在这张表上有主键列。主键列名是
id
,我们使用该列将表分成相等的分区。
我们将此表划分为逻辑分区。每个分区必须足够大以减少多个并行选择的开销,也必须足够小,可以利用索引扫描。在我们的例子中,最佳数字将是 7。为了实现它,我们将 max id 除以 7,然后创建七个范围。
我们假设 id 列值的分布是均匀的。否则,我们可以使用 percent
ile_cont ()
函数来实现均匀分布。
结果是
21125353
。第一个范围介于 ID
1
和
21125
353 之间。第二个范围从 21125353 开始,以
21125353+21125353
=4
2250706 结束,依此类
推。结果,我们有以下范围:
通过 亚马逊云科技 DMS 迁移任务,我们可以以 JSON 格式定义规则。对于并行加载,我们将使用
范围
类型的并行加载
规则属性。逻辑分区被定义为范围边界,范围边界仅接受每个范围的上限。该规则的 JSON 表示形式将是:
使用与第一个任务相同的设置创建新的数据库迁移任务,但 表映射 部分除外。
选择 “
添加新选择规则
” 按钮。在
架构
下拉列表中,选择
输入架构。
在
源名称
文本框字段中,输入要包含的架构的名称(在本例中为
dms_sample
)。在
表格名称
文本框中,输入要包含的表格名称(在本例中为 sp
orting_event_ticket
)。在 “
操作 ” 中,
选择 “
包括
” 。
现在选择 JSON 编辑器 按钮。规则编辑器文本框将打开,显示我们的包含规则。将用于并行加载的 JSON 规则添加到 JSON 规则 数组中:
将 “ 开始迁移任务 ” 设置为 “ 稍后 手动 启动” ,然后选择 “ 创建任务 ” 按钮。
运行迁移任务和监控
在做了所有这些准备之后,我们有两项数据库迁移任务。
要启动任务,请从迁移任务列表中选择任务,然后从 “ 操作 ” 下拉菜单 中选择 “ 重新启动/恢复 ”。
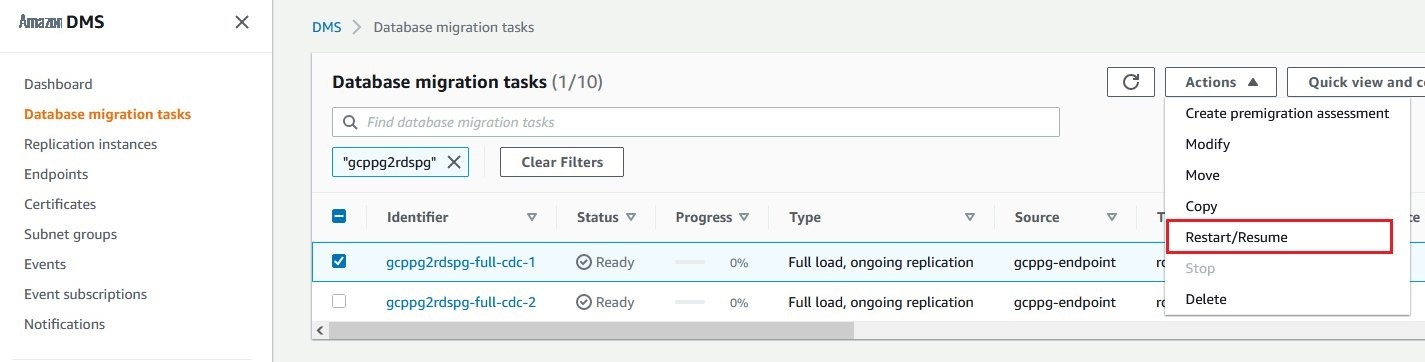
并行启动这两个复制任务。
亚马逊云科技 DMS 启动迁移任务。首先,启动初始数据加载过程。初始加载完成后,数据验证过程逐行比较源数据库和目标数据库之间的数据。然后,变更数据捕获过程将更改应用到迁移的表,这些更改是在数据加载阶段执行的,迁移任务切换到持续复制模式。
您可以在特定数据库迁移任务的 表统计 选项卡上跟踪迁移进度。 CloudWatch 指标 选项卡为您提供有关迁移任务生命周期不同阶段的信息,其中包括:
- 满载 — 以千字节和行为单位的吞吐量指标。
- CDC — 更改数据捕获吞吐量和延迟。
- 验证 -与数据验证阶段相关的指标,例如,验证或失败的行数,查询延迟。
- 对@@ 复制实例的影响 -此特定迁移任务使用了多少内存。
有关 亚马逊云科技 DMS 监控和指标的更多信息,请参阅《
切换到适用于 PostgreSQL 的亚马逊 RDS
亚马逊云科技 DMS 迁移任务在 GCP 云 SQL 和亚马逊 RDS 数据库实例之间同步数据。现在,当数据同步时,可以规划应用程序切换。检查亚马逊 CloudWatch CDC 指标中的复制延迟值,并在需要时执行 DMS 数据验证任务。
在切开之前,请注意以下步骤:
-
将参数你可以在初始加载阶段完成后再做。session_replication_role 设置 回其默认值来源。 - 清理并分析目标亚马逊 RDS for PostgreSQL 实例上的表。
- 考虑将序列从源数据库更新为其当前值。
- 确保在 GCP Cloud SQL 实例上调整的所有数据库参数也是在亚马逊 RDS for PostgreSQL 上设置的。相应地调整它们。
清理
要清理这篇文章中使用的资源,请执行以下操作:
- 删除 GCP 云 SQL 实例。
- 删除 PostgreSQL 版亚马逊 RDS 实例。
- 删除 亚马逊云科技 DMS 复制实例、迁移任务和终端节点。
- 删除数据库密钥和关联的 IAM 角色。
结论
在这篇文章中,我们向您展示了完成数据库从 Google Cloud Platform 或其他平台或本地数据中心迁移到 Amazon RDS 的过程。亚马逊云科技 Database Migration Service 提供完整数据加载、数据验证和持续变更数据捕获的可能性。再加上其广泛的配置和监控功能,它是任何规模的数据迁移项目的强大资产。
如果您有任何问题或反馈,请将其留在评论部分。
作者简介
 艾钦·加西莫夫
是 亚马逊云科技 的高级合作伙伴解决方案架构师。他与我们的客户和合作伙伴合作,为各种数据库迁移和现代化项目提供指导和技术支持。
艾钦·加西莫夫
是 亚马逊云科技 的高级合作伙伴解决方案架构师。他与我们的客户和合作伙伴合作,为各种数据库迁移和现代化项目提供指导和技术支持。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。