我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用可传输的表空间将 Oracle 数据库迁移到 亚马逊云科技
在本地或
在这篇文章中,我们描述了迁移时应考虑的关键因素,然后深入探讨了 使用 Oracle 可传输表空间将自行管理的 Oracle 数据库物理迁移到亚马逊 EC2 和
迁移时需要考虑的关键因素
- 确保在目标数据库服务器上分配了足够的存储空间,以便可以复制源数据文件。
- 正在传输的表空间可以由字典管理,也可以由本地管理。从 Oracle 9i 开始,传输的表空间不要求与目标数据库的标准块大小相同。
- 如果您传输的表空间与接收表空间集的数据库的标准块大小不同,则必须首先在接收数据库参数文件中输入 DB_NK_Cache_Size 初始化参数条目。例如,如果您要将块大小为 8 K 的表空间传输到标准块大小为 4 K 的数据库,则必须在参数文件中包含 DB_8K_CACHE_SIZE 初始化参数条目。如果尚未将其包含在参数文件中,则可以使用 ALTER SYSTEM SET 语句设置此参数。
-
您可以使用跨平台增量备份减少可传输表空间的停机时间。请参阅 Oracle
文档编号 2471245.1 。 -
确保使用公共互联网、VPN 或
亚马逊云科技 Direct Connect 进行网络连接 , 并确保有足够的带宽支持源数据库和目标数据库之间的数据传输。带宽应与为满足要求而需要传输的数据量 “成比例”。 -
源和目标 Oracle 数据库版本和数据库实例操作系统类型必须兼容。以下
链接 提供了传输数据的兼容性注意事项。
基于这些因素,您可以使用物理迁移、逻辑迁移或物理和逻辑迁移方法的组合来选择离线或在线迁移。
解决方案概述
在这篇文章中,我们重点介绍使用可传输表空间将亚马逊 EC2 上的 Oracle 数据库迁移到 Amazon RDS Custom for Oracle 的步骤。你可以使用任何 Oracle 源代码和 Oracle 目标。
在确定是否需要在迁移之前转换数据并检查字符集兼容性之后,就可以完成迁移步骤。
下图说明了我们的可传输表空间功能的架构。
源代码可以位于本地,也可以在亚马逊 EC2 上使用 Oracle。在以下架构中,我们使用可传输表空间功能将表空间从本地移动到 RDS Custom for Oracle。您可以使用
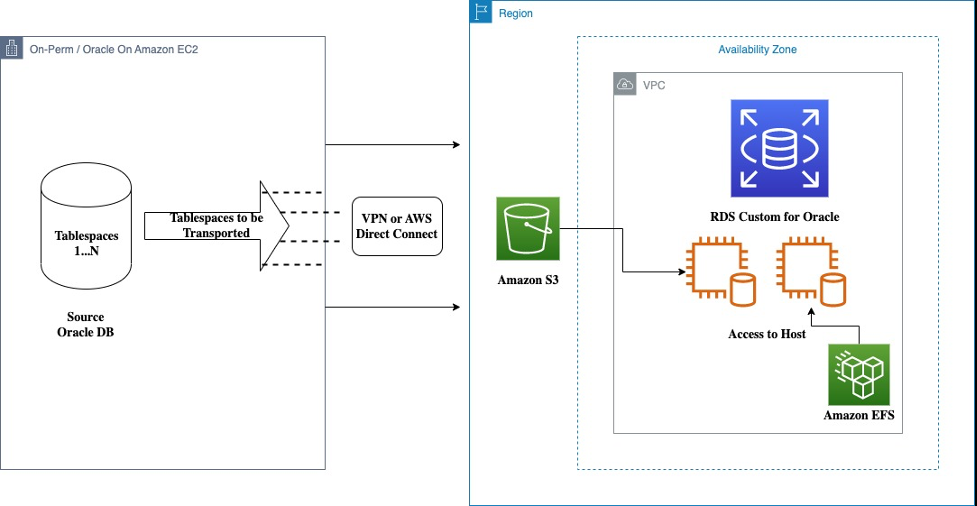
先决条件
确保满足以下先决条件:
- 您应该在源数据库和目标数据库主机上都具有操作系统访问权限
- 来源是在本地运行的 Oracle 数据库或亚马逊 EC2 上运行的 Oracle 数据库
-
如果源平台和目标平台不同,请参阅
检查 Endian 集 兼容性部分 - 目标数据库是适用于 Oracle 的 RDS 自定义数据库实例。我们也可以使用与亚马逊 EC2 上的 Oracle 相同的步骤作为目标
- 源数据库和目标数据库具有相同的字符集,或者目标数据库字符集必须是源数据库字符集的超集
- 以操作系统用户身份运行迁移程序,所有者为 Oracle
此外,请完成以下迁移前清单:
-
为
Oracle 数据库实例创建一个新的、空的 RD S 自定义 - 在目标数据库中创建表空间,其名称与要传输的每个表空间的源数据库同名。新的目标数据库最初仅包含 SYSTEM、SYSAUX、UNDO、USERS 和临时表空间
-
如果要导入到与源
架构不同的用户架构,请在数据泵导入命令 中指定 REMAP_SCHEMA,以便在目标系统的相应架构中创建所有数据库对象(例如表和索引)。默认情况下,将在与源数据库相同的用户架构中创建对象,并且这些用户必须已经存在于目标数据库中。如果它们不存在,则导入实用程序会返回错误 - 将目标数据库的 SYSTEM、SYSAUX、UNDO 和临时表空间的大小与源数据库的大小进行比较。为避免任何空间问题,最佳做法是让目标表空间的大小等于或大于源数据库上的表空间
- 最佳做法是将目标数据库日志文件组和成员的数量与源数据库日志文件组和成员的数量相同。此外,新目标数据库中每个日志文件组的日志文件大小应等于或大于源数据库的大小
-
作为数据文件副本的登录区,您可以使用
亚马逊弹性区块存储 (Amazon EBS)、亚马逊弹性 文件系统 (A m azon EFS) 或亚马逊 Simple Storage Servic e (Amazon S3) - 确保您在源服务器和 Amazon RDS Custom for Oracle 数据库服务器之间建立网络连接,并且数据库监听的数据库端口(默认端口为 1521)处于打开状态,可供两者之间进行通信
- 源数据库中使用的数据库选项和组件应安装在目标数据库上
检查 Endian 集合兼容性
许多(但不是全部)平台都支持跨平台数据传输。您可以查询
V$TRANSPORTABLE_PLAT
FORM 视图以查看支持的平台,并确定每个平台的字节序格式(字节顺序)。以下查询显示支持跨平台数据传输的平台:
如果源平台和目标平台的字节顺序相同,则无需进行任何数据转换即可将数据从源平台传输到目标平台。
如果字节序格式不同 ,请参阅 “ 转换数据 ” 部分。
检查字符集兼容性
在源数据库和目标数据库上运行以下命令以查找兼容的字符集:
在源代码上,使用以下查询:
在目标上,使用以下查询:
从源数据库中选择一组独立的表空间
可传输集合中的数据库对象与可传输集合之外的数据库对象之间可能存在逻辑或物理依赖关系。只能传输自包含的表空间集,也就是说,表空间集中的任何数据库对象都不依赖于该表空间集之外的任何数据库对象。
自包含表空间违规的一些示例有:
- 表空间集内的索引适用于表空间集之外的表。请注意,如果表的相应索引不在表空间集合之外,则不构成违规
- 分区表部分包含在一组表空间中
- 要复制的表空间集必须包含分区表的所有分区,或者不包含分区表的任何分区。要传输分区表分区的子集,必须将这些分区交换成表
- 参照完整性约束指向跨越设定边界的表。传输一组表空间时,可以选择包括参照完整性约束。但是,这样做会影响一组表空间是否独立。如果你决定不传输约束,那么这些约束条件不会被视为指针
- 表空间集内的表包含一个 LOB 列,该列指向表空间集之外的 LOB 列,反之亦然
- 用户 A 注册的 XML DB 架构 (*.xsd) 导入由用户 B 注册的全局架构,以下情况属实:用户 A 的默认表空间为表空间 A,用户 B 的默认表空间为表空间 B,表空间集中仅包含表空间 A
您可以使用以下语句来确定表空间 HR 是否自给自足,同时考虑参照完整性约束(由 TRUE 表示):
运行
如果表空间集是独立的,则此视图为空。
DBMS_TTS.TRANSPORT_SET_CHECK 过程后,您可以通过从 TRANSPORT_SET_
FOLATIONS 视图中进行选择来查看所有违规行为。
必须先解决所有违规问题,然后才能传输表空间。如下一个任务中所述,绕过完整性约束违规的一个选择是不导出完整性约束。
生成可传输的表空间集
在确保有一组独立的表空间要传输之后,通过以下步骤生成可传输的表空间集:
-
启动 SQL*Plus 并以管理员或拥有
ALTER TABLESPACE 或 MANAGE TABLESPACE 系统权限的用户身份连接到数据库。 - 将集合中的所有表空间设置为只读: BLESPACE HR 只读;
必须始终指定 TRANSP
ORT_TABLESPACES
,这表示使用了可传输选项。此示例指定了以下附加数据泵参数:
- DUMPFILE — 指定要创建的结构信息导出转储文件的名称,expdat.dmp
- 目录 -指定指向转储文件操作系统或 Oracle 自动存储管理位置的目录对象
-
DATA_PUMP_DIR
— 在非 CDB 中,目录对象是自动创建的。但是,目录对象
DATA_PUMP_DIR 不是在 PDB 中自动创建的。因此,从 PDB 导出或导入 PDB 时,请在 PDB 中创建一个目录对象,并在运行 Data Pump 时指定目录对象 - LOGFILE -指定要为导出实用程序创建的日志文件。在此示例中,日志文件是在与转储文件相同的目录中创建的,但您可以指定任何其他目录来存储日志文件
要使用严格的包含检查来执行传输表空间操作,请使用 TRANSPORT
_FULL_CHECK
参数,如以下示例所示:
使用
transport_full_check
时 ,数据泵导出实用程序会验证是否存在依赖关系,并且正在传输的表空间集是独立的,否则导出将失败。您必须解决所有违规行为,然后再次运行此任务。
expdp 实用程序在命令行上显示转储文件和数据文件的名称和路径,如以下示例所示。这些是您需要传输到目标数据库的文件。此外,请检查日志文件中是否存在任何错误。
将导出转储文件传输到目标数据库
要将转储文件和数据文件从源复制或移动到目标,可以使用以下任何方法。
如果源和目标都是文件系统,则可以使用:
- 任何用于复制平面文件的工具(例如,操作系统复制实用程序或 FTP)
-
DBMS_FILE_TRANSFER 包 -
RMAN
如果源或目标为自动存储管理 (ASM) 磁盘组,则可以使用:
-
通过 FTP 传入或从 XML 数据库存储库中的
/sys/asm虚拟文件夹 -
dbms_file_transfer 包 - RMAN
将转储文件传输到 DATA_P
UMP_DIR 目录对象指向的目录
,或您选择的任何其他目录。目标数据库必须可以访问新位置。
在目标数据库上,运行以下查询来确定 DATA_PUMP
_DIR
的位置:
移动可传输表空间集的数据文件
将表空间的数据文件(本文为 HR.dbf)从源数据库传输到目标数据库的目录。该目录应是实例存储或安装在实例上的 Amazon EFS 的一部分。
如果您要将 HR 表空间传输到不同的平台,则可以在每个平台上运行以下查询:
如果查询返回一行,则平台支持跨平台表空间传输。
以下是源平台的查询结果:
以下是目标平台的结果:
在此示例中,您可以看到字节序格式是相同的。如果不需要对表空间进行字节序转换,则可以使用任何文件传输方法传输文件。
如果字节序格式不同,则转换数据
当字节序格式不同时,有两种方法可以转换数据
-
使用
DBMS_FILE_TRANSFER 包中的 GET_FILE 或 PUT_FILE 过程来传输数据文件。这些过程会自动将数据文件转换为目标平台的字节序格式。 - RMAN 可以使用备份集跨平台传输数据库、数据文件和表空间。使用备份集执行跨平台数据传输使您能够使用块压缩来减小备份的大小。这提高了备份性能并减少了通过网络传输备份所花费的时间。
将表空间恢复到读/写模式(可选)
使传输的表空间在源数据库中再次读取/写入:
您可以推迟此任务,首先确保导入过程成功。
导入表空间集
要完成可传输表空间操作,请导入表空间集。
以具有 DATA
PUMP_IMP_FULL_DATABASE 角色的用户身份运行数据泵导入实用程序以导入表空间
元数据:
此示例指定了以下数据泵参数:
- DUMPFILE -指定包含要导入的表空间元数据的导出文件
- 目录 -指定用于标识导出转储文件位置的目录对象。该目录必须存在,并且必须向运行导入的用户授予读写权限
-
TRANSPORT_DATAFILE
S -列出包含要导入的表空间的所有数据文件。如果有许多
数据文件,则可以在使用 PARFIL E 参数指定的参数文件中多次指定 TRANSPORT_DATAFILES 参数 -
REMAP_SCHEM A — 更改数据库
对象的所有权。如果您未指定
REMAP_SCHEMA ,则所有数据库对象(例如表和索引)都将在与源数据库相同的用户架构中创建,并且这些用户必须已经存在于目标数据库中。如果它们不存在,则导入实用程序会返回错误 - LOGFIL E -指定要由导入实用程序写入的日志文件的文件名。在此示例中,日志文件被写入读取转储文件的目录,但可以将其写入不同的位置
此语句成功运行后,正在复制的集合中的所有表空间都将保持只读模式。检查导入日志文件以确保没有出现错误。
处理大量数据文件时,可以使用导入参数文件来简化任务定义。例如,您可以按如下方式运行数据泵导入实用程序:
par.f 参数文件包含以下内容:
迁移后任务
完成以下任务以准备目标 Oracle 数据库以供使用。对源数据库和目标数据库运行以下查询,以检查数据是否已完全导出和导入,没有任何错误:
- 查看数据库中存在的所有用户:
- 查看数据库中的对象总数:
- 查看已迁移的数据库架构所拥有的所有表的列表。登录到本示例中的各个架构以 HR 用户身份连接并执行以下命令。
- 查看表空间中对象占用的确切大小(以 MB 为单位):
- 查看占用的总空间(以 MB 为单位):
- 查看数据库的大小:
- 在目标位置将传输的表空间切换到读写模式:
- 在源位置将表空间恢复为读写模式(可选):
成功完成导出命令或导入命令后,可以将源表空间设置为读写状态。如果在导出后将其设置为读写,则可以忽略此步骤。
- 在新的目标数据库上创建并启动相应的数据库服务或网络连接。
- 将应用程序重定向到目标数据库。
- 清理暂存目录。
- 从源主机和目标主机中移除不需要的文件。
对可传输表空间的限制
请注意可传输表空间的以下限制:
- 不能将管理表空间(如 SYSTEM 和 SYSAUX)包含在可传输表空间集中
- 传输表空间集时,除非所有基础对象或包含对象都在表空间集中,否则具有底层对象(例如实例化视图)或包含对象(例如分区表)的对象是不可传输的
- 可传输表空间无法跨具有不同时区文件版本的平台传输带有带时区时间戳的表 (TSTZ) 数据。可传输表空间操作会跳过这些表。您可以按照惯例导出和导入这些表
- 当您在具有不同时区的数据库之间传输包含带有带有本地时区 (TSLTZ) 数据的表的表空间时,带有 TSLTZ 数据的表不会被传输。您可以按照惯例导出和导入这些表
- 适用于 Oracle 数据库实例的 RDS Custom 上单个文件的最大大小为 16 TiB(太字节)
- 不使用区块加密但包含带有加密列的表的表的表空间无法传输。必须使用 Oracle 数据泵导出和导入表空间的架构对象。您可以利用 Oracle 数据泵,它使您能够在导出和导入数据的同时保持对数据的加密
摘要
在这篇文章中,我们重点介绍了如何使用可传输表空间功能将甲骨文数据库迁移到亚马逊 EC2 上的 Oracle 或适用于 Oracle 的 Amazon RDS Custom。
要了解有关可传输表空间和 Amazon RDS 自定义的更多信息,请参阅以下资源:
-
适用于甲骨文的亚马逊 RDS 自定义 -
传输数据库
如果您有任何问题或建议,请发表评论。
作者简介



*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。