要将 Oracle 数据库迁移到
兼容 Amazon Aurora PostgreSQL 的版本
,您通常需要执行自动和手动任务。自动任务包括架构转换和数据迁移,可以分别
使用 亚马逊云科技 架构转换工具 (亚马逊云科技
SCT) 和 AW
S 数据库迁移服务
(亚马逊云科技 DMS) 来处理。手动任务涉及对某些无法自动迁移的数据库对象进行架构后的 亚马逊云科技 SCT 迁移补充。
亚马逊云科技 SCT 会自动将源数据库架构和大部分自定义代码转换为与目标数据库兼容的格式。在从甲骨文迁移到 PostgreSQL 的数据库时,亚马逊云科技 SCT 会自动将 Oracle PL/SQL 代码转换为 PostgreSQL 中的等效 Pl/pgSQL 代码。
从 Oracle 迁移到 PostgreSQL 时,经常会遇到批量绑定(例如 BULK COLLECT 和 FORALL)。批量绑定是 Oracle 数据库中的一项功能,它允许一次读取或处理多行数据,而不是一次读取或处理一行数据。它的工作原理是将一组值绑定到单个变量,然后由数据库通过单个操作进行处理。
在这篇文章中,我们简要概述了 Oracle 批量绑定的工作原理,并向您展示如何将其迁移到在 Amazon Aurora PostgreSQL 兼容版上运行的数据库。我们还将回顾您在转换过程中可能遇到的一些挑战以及如何解决这些挑战。
解决方案概述
Oracle PL/SQL 允许您批量获取记录,而不是逐一获取。BULK COLLECT 减少了 SQL 和 PL/SQL 引擎之间的上下文切换,允许 SQL 引擎一次性提取所有记录。使用 BULK COLLECT 的优势在于,它通过减少数据库和 PL/SQL 引擎之间的交互来提高性能。
PostgreSQL 提供了数组函数
ARRAY_AGG
,你可以用它来获得与 Oracle 相似的处理逻辑。在这篇文章中,我们讨论了使用 BULK COLLECT 的不同方法以及如何将其迁移到 PostgreSQL 中。我们还讨论了使用 ARRAY_AGG 作为 BULK COLLECT 的替代方案时的常见错误和解决方案。
先决条件
要开始使用本文中描述的解决方案,您需要以下内容:
-
一个活跃的 亚马逊云科技 账户
-
源甲骨文数据库(本地或
适用于甲骨文的 亚马逊 RDS
)
-
目标 Aurora PostgreSQL 数据库
-
对目标数据库具有以下权限的数据库用户(分别使用
您的架构和用户替换 YOUR_SCHEMA_NAM
E 和
YOUR_DB_USER
):
GRANT CONNECT ON DATABASE TO YOUR_DB_USER;
GRANT USAGE ON SCHEMA YOUR_SCHEMA_NAME TO YOUR_DB_USER;
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA YOUR_SCHEMA_NAME TO YOUR_DB_USER;
使用以下代码在 Oracle 和 PostgreSQL 中创建示例表并将数据插入其中。
以下是甲骨文代码:
create table test_table as WITH t(n) AS (
SELECT 1 from dual
UNION ALL
SELECT n+1 FROM t WHERE n < 5000)
SELECT n as id,'test_'||n as name ,sysdate+n as login_date FROM t;
以下是 PostgreSQL 的代码:
CREATE TABLE test_table AS
SELECT n as id,
'test_'||n as name,
CURRENT_DATE +n as login_date
FROM generate_series(1, 5000) as n;
以下部分演示了 BULK COLLECT 在 Oracle 中是如何工作的,以及如何使用批量收集将函数迁移到 PostgreSQL。
使用 FETCH 批量收集
FETCH 语句用于从游标中检索单行数据。与 BULK COLLECT 一起使用时,FETCH 语句一次检索多行数据。
以下 PL/SQL 程序声明了游标和关联数组,并演示了如何使用 BULK COLLECT 在单个 FETCH 中检索所有行:
SET SERVEROUTPUT ON
DECLARE
/* Declaring the collection type */
TYPE t_bulk_collect_test_tab IS TABLE OF test_table%ROWTYPE;
/* Declaring the collection variable */
l_tab t_bulk_collect_test_tab;
CURSOR c_data IS SELECT * FROM test_table;
BEGIN
/* Populate the array using BULK COLLECT that retrieves all rows in a single FETCH ,
getting rid of row by row fetch in a loop */
OPEN c_data;
FETCH c_data BULK COLLECT INTO l_tab;
CLOSE c_data;
-- Process contents of collection here.
DBMS_OUTPUT.put_line(l_tab.count || ' rows');
/* Accessing the collection type - Before Modify */
FOR i IN l_tab.FIRST .. l_tab.LAST
LOOP
EXIT WHEN i = 3;
dbms_output.put_line('Before Modify- Row- '|| i || ': is '||l_tab(i).name);
dbms_output.put_line('Before Modify- Row- '|| i || ': is '||l_tab(i).name);
END LOOP;
/* Modifying collection element values */
l_tab(2).name := 'Change Me';
/* Accessing the collection type – After Modify */
FOR i IN l_tab.FIRST .. l_tab.LAST
LOOP
EXIT WHEN i = 3;
dbms_output.put_line('After Modify- Row- '|| i || ': is '||l_tab(i).name);
END LOOP;
dbms_output.put_line('Program executed successfully.');
END;
我们得到以下输出。
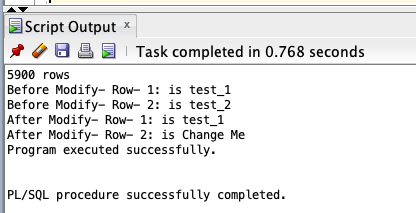
现在让我们将 Oracle 示例转换为等效的 PL/pgSQL 代码。
PostgreSQL 中的 pl/pgSQL 目前没有 BULK COLLECT 语法。但是,我们可以使用
ARRAY_AGG 聚
合函数来运行执行批量处理的查询。
第一步是声明与 Oracle 集合类型匹配的类型的数组。要做到这一点,你有两个选择:
-
在 PostgreSQL 中@@
创建一个类型与 Oracle 中的集合类型相似的域
(例如,将 DOMAI
N l_tab 创建为 CHARACTER VARYING [])
-
直接在 pl/pgSQL 代码中声明一个数组变量(例如,
l_tab
CHARACTER VARYING [])
在以下示例中,我们使用
ARRAY_AGG 将 c_d
ata 游标数据提取 到 l_t
a
b 变量中,通过直接在 PL/p
gSQL 代码中声明数组变量来模仿 Oracle 中 BULK COLLECT 的批量处理功能:
DO $$
Declare
/* l_tab variable declaration of Array type ,this is same as collection type in Oracle */
l_tab test_table[];
/* rec is a record type variable declaration of table type of test_table */
i INTEGER := 1;
rec RECORD ;
BEGIN
/* Removed BULK COLLECT in PostgreSQL while migrating code from Oracle PLSQL.
modified with Array_agg. */
SELECT array_agg((id,name,login_date)::test_table) into l_tab FROM test_table;
RAISE NOTICE 'Bulk count: (%', COALESCE(array_length(l_tab,1),0)|| ' rows): ' ;
/* Accessing the collection type - Before Modify */
FOREACH rec IN ARRAY l_tab
LOOP
EXIT WHEN i =3;
RAISE NOTICE using message := concat_ws('', 'Before Modify- Row- ', i,
': is ', rec.name
);
i := i + 1 ;
END LOOP;
/* Modifying collection element values */
rec := l_tab[2] ;
rec.name := 'Change Me';
l_tab[2] := rec;
i := 1;
/* Accessing the collection type – After Modify */
FOREACH rec IN ARRAY l_tab
LOOP
EXIT WHEN i =3;
RAISE NOTICE USING message := concat_ws('', 'After Modify- Row- ', i,
': is ', rec.name
);
i := i + 1 ;
END LOOP;
RAISE NOTICE 'Program executed successfully.';
END $$;
该示例生成以下输出。
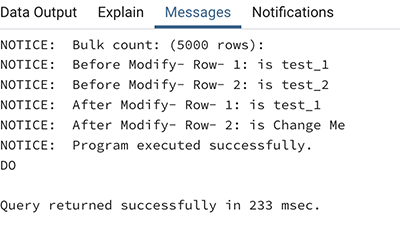
建议在 PostgreSQL 中将 Oracle 全局对象转换为域。这是因为可以在包内的所有过程和函数中公开访问 Oracle 全局对象。同样,在 PostgreSQL 中,我们创建了一个域来复制与 Oracle 全局数组相似的功能。
在 SELECT 语句中批量收集
上一节演示了如何使用带有 FETCH 的 BULK COLLECT 功能将 PL/SQL 代码迁移到 PL/pgSQL 中的等效结构中。现在,让我们探讨 BULK COLLECT 机制的不同方面以及使用 SELECT 语句进行迁移所需的步骤。
以下是在 SELECT 语句中使用 BULK COLLECT 的 Oracle 函数的示例:
SET SERVEROUTPUT ON
DECLARE
TYPE t_bulk_collect_test_tab IS TABLE OF test_table%ROWTYPE;
l_tab t_bulk_collect_test_tab := t_bulk_collect_test_tab();
BEGIN
/* Populate the array using BULK COLLECT that retrieves all rows in a single FETCH ,
Using SELECT INTO CLAUSE */
SELECT *
BULK COLLECT INTO l_tab
FROM test_table;
DBMS_OUTPUT.put_line('Bulk count: (' || l_tab.count || ' rows): ' );
END;
/
该示例生成以下输出。
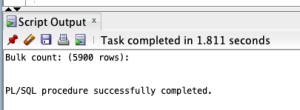
在 PostgreSQL 中,我们可以使用
ARRAY_AGG 函数来实现批
量选择到语句功能:
/*The following statements creates a type of test_table Rowtype */
create type typ_l_tab AS (id integer, name character varying(100), login_date date);
/* Below statement creates a Domain for the above type typ_l_tab that matches the Oracle collection type */
DROP DOMAIN IF EXISTS dom_l_tab ;
CREATE DOMAIN dom_l_tab as typ_l_tab[];
/* In the declaration section of this code, we first created a type l_tab as an array of the table type of test_table.*/
DO $$
Declare
/* Declare array variable using Domain */
l_tab dom_l_tab;
BEGIN
/* Removed BULK COLLECT in PostgreSQL while migrating code from Oracle PLSQL.
BULK COLLECT SELCT INTO CLAUSE statement is modified with array_agg. */
SELECT array_agg((id,name,login_date)::test_table) into l_tab FROM test_table;
RAISE NOTICE 'Bulk count: (%', COALESCE(array_length(l_tab,1),0)|| ' rows): ' ;
END;
$$
该示例生成以下输出。
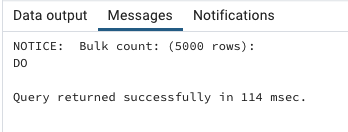
在 PostgreSQL 中,为了实现 BULK COLLECT 语句的类似功能,我们使用了
ARRAY_AGG
函数将查询结果聚合到一个数组中。然后,查询的结果存储在
l_tab 变量中,该 变量是
test
_tab
le 记录的数组。
限量批量收集
使用 BULK COLLECT 时,您还可以指定 LIMIT 子句,该子句表示一次读取的最大行数。这对于管理内存使用情况和防止集合变量变得过大很有用。
以下是使用带限制的批量收集的 Oracle 函数的示例:
SET SERVEROUTPUT ON
DECLARE
CURSOR c1 IS SELECT ID FROM TEST_TABLE;
TYPE V_TAB IS TABLE OF INTEGER INDEX BY BINARY_INTEGER;
V_ID V_TAB;
len INTEGER;
BEGIN
Open c1;
LOOP
/* Here we are using limit along with BULK COLLECT to limit the no of rows to
1000 for each loop */
Fetch c1 bulk collect into V_ID limit 1000;
len:=V_ID.COUNT;
DBMS_OUTPUT.PUT_LINE('len-'||len);
EXIT WHEN C1%NOTFOUND;
End loop;
Close c1;
END;
/
该示例生成以下输出。
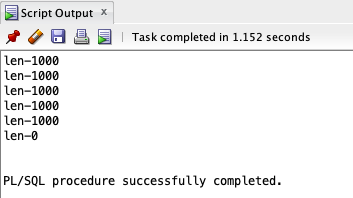
在 PostgreSQL 中,我们在使用数组处理多行时没有 LIMIT 子句,但作为解决方案,我们可以使用 LIMIT 和 OFFSET 来实现类似的功能:
DO $$
DECLARE
V_ID INTEGER[];
l INTEGER;
o INTEGER;
len INTEGER;
v_limit INTEGER;
v_offset INTEGER;
BEGIN
v_limit := 1000;
v_offset := 0;
LOOP
SELECT array_agg(id) OVER (ROWS BETWEEN CURRENT ROW AND (v_limit - 1) FOLLOWING) INTO V_ID
FROM test_table ORDER BY id LIMIT v_limit OFFSET v_offset;
len := COALESCE(array_length(V_ID,1),0);
RAISE NOTICE 'len-%',len;
EXIT WHEN len = 0 ;
v_offset := v_offset + v_limit;
END LOOP;
END;
$$
该示例生成以下输出。
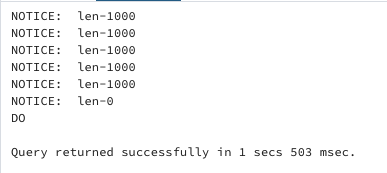
使用 FORALL 进行批量收集
FORALL 语句允许您对集合的所有元素执行单个 DML 操作,而不是逐个处理每个元素。与 BULK COLLECT 一起使用时,它可以显著减少 SQL 引擎和 PL/SQL 引擎之间的上下文切换量,从而加快运行过程。
以下示例说明如何在 Oracle 中使用 FORALL 的批量收集:
CREATE TABLE TEST_TABLE2 AS SELECT * FROM TEST_TABLE WHERE 1=2;
SET SERVEROUTPUT ON
DECLARE
TYPE V_TEST IS TABLE OF TEST_TABLE%ROWTYPE;
V_TAB V_TEST;
V_COUNT INTEGER;
BEGIN
SELECT t.*
BULK COLLECT INTO V_TAB
FROM TEST_TABLE t;
FOR i IN V_TAB.FIRST .. V_TAB.LAST
LOOP
if MOD(V_TAB(I).ID, 2) = 0 THEN
/* Modifying the value of array elements */
V_TAB(I).name := 'EVEN';
END IF;
END LOOP;
DBMS_OUTPUT.put_line('Retrieved-'||TO_CHAR (V_TAB.COUNT)||' rows');
SELECT COUNT(1) INTO V_COUNT FROM TEST_TABLE2;
DBMS_OUTPUT.put_line ('BEFORE TABLE COUNT-'||V_COUNT);
FORALL i IN 1 .. V_TAB.COUNT
INSERT INTO TEST_TABLE2
(
ID,
NAME,
LOGIN_DATE
)
VALUES
(
V_TAB(i).ID,
V_TAB(i).NAME,
V_TAB(i).LOGIN_DATE
);
SELECT COUNT(1) INTO V_COUNT FROM TEST_TABLE2;
DBMS_OUTPUT.put_line ('AFTER TABLE COUNT-'||V_COUNT);
END;
/
我们得到以下输出。
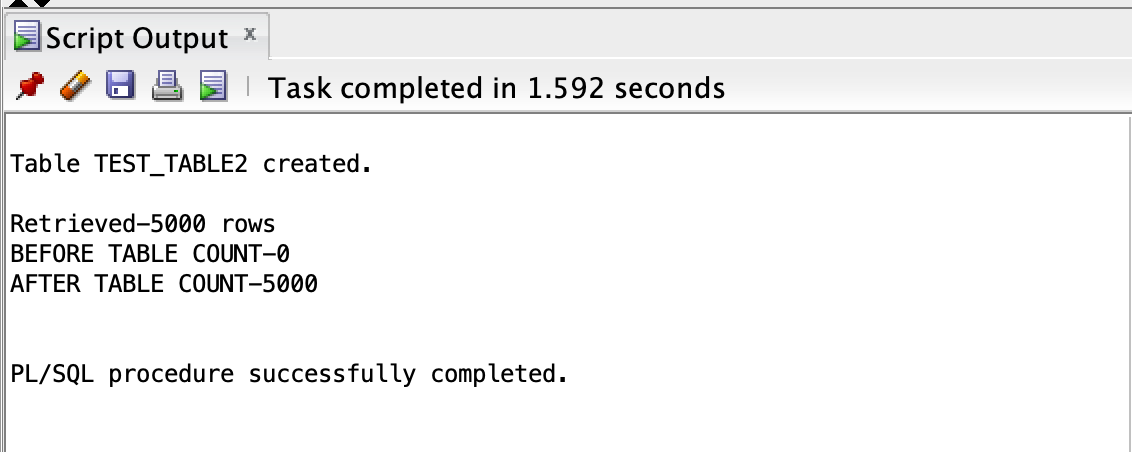
在 PostgreSQL 中,我们可以使用 UNNEST 实现与批量数据的 DML 操作类似的功能。这使用单个 SELECT 语句将数组变量的完整数据加载到表中。
我们使用表 test_table2 进行批量收集 FORALL:
create table test_table2
(
id integer,
name text,
login_date timestamp without time zone
);
我们正在尝试使用 UNNEST 选项在 PostgreSQL 中实现带有 FORALL 功能的批量收集:
DO $$
declare
V_TAB TEST_TABLE[]; -- t is the table name and at the same time a data type
V_COUNT INTEGER;
BEGIN
SELECT array_agg(t)
into V_TAB
FROM TEST_TABLE t;
V_COUNT := cardinality(V_TAB);
RAISE NOTICE 'Retrieved % rows', V_COUNT;
SELECT COUNT(1) INTO V_COUNT FROM TEST_TABLE2;
RAISE NOTICE 'BEFORE TABLE COUNT- %', V_COUNT;
/* This one converts FORALL to PostgreSQL using arrays and unnest */
INSERT INTO TEST_TABLE2
(
ID,
NAME,
LOGIN_DATE
)
SELECT r.*
FROM UNNEST(V_TAB) as r;
SELECT COUNT(1) INTO V_COUNT FROM TEST_TABLE2;
RAISE NOTICE 'BEFORE TABLE COUNT- %', V_COUNT;
END $$;
该示例生成以下输出。
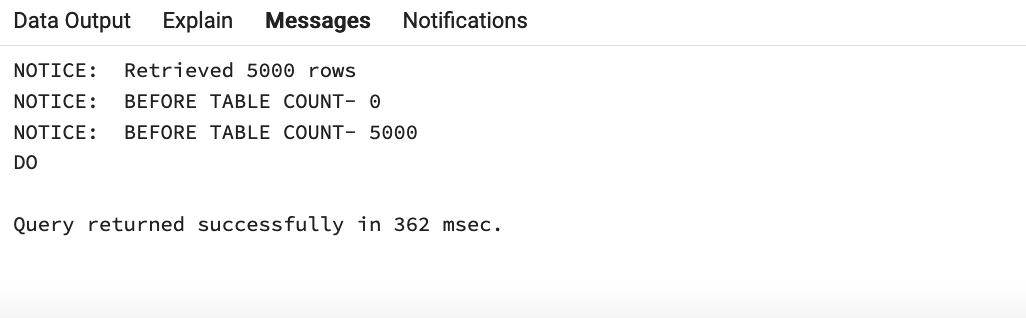
调试常见错误
本节介绍在使用
ARRAY_AGG 作为 BULK_LOA
D
的替代方案时可能遇到的常见错误以及如何解决这些错误。
我们使用以下 Oracle 源代码示例来说明我们在将代码重构为 PostgreSQL 时可能遇到的常见错误。
以下是甲骨文代码:
SET SERVEROUTPUT ON
DECLARE
TYPE t_bulk_collect_test_tab IS TABLE OF test_table%ROWTYPE;
l_tab t_bulk_collect_test_tab := t_bulk_collect_test_tab();
BEGIN
SELECT *
BULK COLLECT INTO l_tab
FROM test_table;
DBMS_OUTPUT.PUT_LINE('Bulk count: (' || l_tab.count || ' rows) ' );
for i in l_tab.first..l_tab.last loop
dbms_output.put_line('ID :'||l_tab(i).id||' ' ||'NAME :'|| l_tab(i).name||' '||'LOGIN_DATE :'||l_tab(i).logindate);
end loop;
END;
/
PL/SQL procedure successfully completed.
Bulk count: (100 rows)
ID :1 NAME :test_1 LOGIN_DATE :29-02-20
ID :2 NAME :test_2 LOGIN_DATE :01-03-20
...
以下部分显示了 PostgreSQL 代码。
ARRAY_AGG 放在单列上
本节重点介绍在表的单列 上使用
ARRAY_AGG
时的常见问题。
在我们的第一个示例中,我们在
ARRAY
_AGG 中使用带有行运算符的单列:
create table test_table_demographic
(
id integer,
place character varying
);
INSERT INTO test_table_demographic VALUES (1, 'Alaska'), (2, 'Arizona'), (3, 'California'), (4, 'Colorado'), (5, 'Chicago');
do $$
declare
arr integer[];
var varchar;
v_place varchar;
begin
select array_agg(row(a.id)) into arr from test_table a where id in (1,2,3,4,5);
RAISE NOTICE 'arr = %', arr;
loop
select place into v_place from test_table_demographic where id=arr[i];
RAISE NOTICE '% , % ',arr[i],v_place;
end loop;
end $$;
在单列上使用行运算符和
ARRAY
_AGG 时,我们会出现以下错误。

在前面的输出中,从数组中获取的值是一行而不是整数,这就是我们得到错误的原因。
为了解决这个问题,在使用
ARRAY_AGG
处理单列时,我们不应该将整数转换为行。解决方案是在
ARRAY_AGG
表达式中仅使用我们想要返回数组列表的那一列。
以下是在单列上使用
ARRAY_AGG
的正确方法:
do $$
declare
arr integer[];
var varchar;
v_place varchar;
begin
select array_agg(a.id) into arr from test_table a where id in (1,2,3,4,5);
RAISE NOTICE 'arr = %', arr;
for i in 1 .. COALESCE(array_length(arr,1),0)
loop
select place into v_place from test_table_demographic where id=arr[i]::integer;
RAISE NOTICE '% , % ',arr[i],v_place;
end loop;
end $$;
我们得到以下输出。

多列上的 ARRAY_AGG
在多列上使用
ARRAY_AGG
时,也可能会遇到问题。例如,参见以下代码:
/* Lets create a table to discuss about array_agg in multi column scenario */
create table test2 as WITH t AS (
SELECT *
FROM generate_series(1, 100) as n
)
SELECT n as c1,'test_'||n as c2 FROM t;
/* Lets create type for this scenario */
create type typ_test2 as (a integer, b text);
/* Example of common mistakes while using of array_agg in multi column scenario */
do $$
declare
arr test2[];
var test2;
begin
select array_agg(a.c1, a.c2) f from public.test2 a into arr;
RAISE NOTICE 'arr = %', arr;
RAISE NOTICE 'arr[1] = %', arr[1];
var := arr[1];
RAISE NOTICE 'var = %', var;
RAISE NOTICE 'var.c1 = %, var.c2 = %', var.c1, var.c2;
end $$;
该示例生成以下输出。

在此示例中,我们在
ARRAY_
AGG 函数中使用了单个列名。结果,我们得到了一个错误,因为函数
ARRAY_AGG
(整数,文本)不存在。为了解决这个错误,让我们讨论一下在
ARRAY_
AGG 函数中使用多列时的两种方法。
在我们的第一种方法中,我们在
ARRAY_AGG
之上使用行运算符 ,它首先将列转换为行。然后
ARRAY_AGG ()
函数将其加载到 arr 变量中,该变量是 test2 表类型的数组。参见以下代码:
do $$
declare
arr test2[];
var test2;
begin
select array_agg(row(a.c1, a.c2)) f from public.test2 a into arr;
RAISE NOTICE 'arr = %', arr;
RAISE NOTICE 'arr[1] = %', arr[1];
var := arr[1];
RAISE NOTICE 'var = %', var;
RAISE NOTICE 'var.c1 = %, var.c2 = %', var.c1, var.c2;
end $$;
该示例生成以下输出。

在第二种方法中,假设我们有
n
列需要进行多列插入。在这种情况下,尽管指定了所有列,但我们可以使用带有 * 运算符的表别名:
do $$
declare
arr test2[];
var test2;
begin
/* Row operator with table alias with ‘*’ operator to specify all column inspite
of individually mentioning them in array_agg() function */
select array_agg(row(a.*)) f from public.test2 a into arr;
RAISE NOTICE 'arr[1] = %', arr[1];
var := arr[1];
RAISE NOTICE 'var = %', var;
RAISE NOTICE 'var.c1 = %, var.c2 = %', var.c1, var.c2;
end $$
我们得到以下输出。

结论
在这篇文章中,我们分享了将 Oracle 批量绑定迁移到亚马逊 Aurora PostgreSQL 兼容版或适用于 PostgreSQL 的亚马逊 RDS 的分步说明,并提供了代码模板、SQL 脚本和最佳实践。我们还讨论了使用
ARRAY_AGG
作为 BULK COLLECT 的替代方案时的常见错误和解决方案。
有关 PostgreSQL 中数组和类型的更多信息,请参阅
数组
和
聚合函数
。
如果您对这篇文章有任何疑问或建议,请发表评论。
作者简介
 Vinay Paladi
是亚马逊网络服务专业服务团队的首席数据库顾问。他是一名数据库迁移专家,帮助客户构建高度可用、经济实惠的数据库解决方案,并将其商业引擎迁移到 亚马逊云科技 云。他热衷于构建创新的解决方案,以加速数据库的云之旅。
Vinay Paladi
是亚马逊网络服务专业服务团队的首席数据库顾问。他是一名数据库迁移专家,帮助客户构建高度可用、经济实惠的数据库解决方案,并将其商业引擎迁移到 亚马逊云科技 云。他热衷于构建创新的解决方案,以加速数据库的云之旅。
 Bikash Chandra Rout
是亚马逊网络服务专业服务团队的首席数据库顾问。Bikash 专注于帮助客户构建高度可用、经济实惠的数据库解决方案,并将其商业引擎迁移到 亚马逊云科技 云。他对数据库和分析充满热情。
Bikash Chandra Rout
是亚马逊网络服务专业服务团队的首席数据库顾问。Bikash 专注于帮助客户构建高度可用、经济实惠的数据库解决方案,并将其商业引擎迁移到 亚马逊云科技 云。他对数据库和分析充满热情。