我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 S3 和亚马逊 EBS 将多 TB 的 SQL 服务器数据库迁移到适用于 SQL 服务器的亚马逊 RDS Custom
这是关于如何将多 TB 数据库迁移到适用于
适用于 SQL Server 的 Amazon RDS Custom 是一项托管数据库服务,可自动对数据库进行设置、操作、备份、高可用性和扩展,同时授予对数据库和底层操作系统 (OS) 的访问权限。数据库管理员可以使用此访问权限来启用 SQL 公共语言运行时 (CLR) 等本机功能、配置操作系统设置和安装驱动程序,以便迁移旧版、自定义和打包应用程序。
概述
适用于 SQL Server 的 Amazon RDS Custom 具有默认数据驱动器 (D:),可容纳高达 16TB 的存储空间。有关 Amazon RDS Custom for SQL Server 存储限制以及如何调整存储的信息,请参阅
在迁移到适用于 SQL Server 的 Amazon RDS 自定义版本时,客户面临的一个常见挑战是数据库大小加上备份文件大于 16 TB。在这篇文章中,我们将向您展示如何使用
避免存储空间过度配置
即使数据库及其备份文件的总和小于 16TB,也可以使用这种方法迁移多 TB 的数据库。它可以防止存储过度配置并降低成本,因为您可以在数据库还原后回收备份文件空间。
例如,如果您的数据库容量为 10TB,而备份文件总计为 5TB,则可以预配置 Amazon RDS Custom for SQL Server,并为其分配 15TB。然后,您可以将备份文件复制到 D: 驱动器并恢复数据库。但是,选择这种方法会产生更高的成本,因为您无法回收分配给备份文件的 5 TB 存储。这意味着您将为未使用的5TB付费。使用
下表显示了美国东部 1 地区的 Amazon RDS Custom for SQL Server 的当前存储成本差异:
| RDS Custom SQL Server Storage Cost (Single-AZ) | |
| Provisioned IOPS SSD (io1) | |
| Provisioning IOPs: 1000 | |
| Storage Amount | Monthly Cost |
| 10 TB | $ 1,277.60 |
| 15 TB | $ 1,866.40 |
解决方案概述
将多 TB 的本地 SQL Server 数据库迁移到适用于 SQL Server 的亚马逊 RDS Custom 的方法之一是使用
您不应在额外连接的 EBS 卷上托管数据库文件,以避免 RDS Custom for SQL Server 进入不支持的配置状态。要了解有关 RDS 自定义支持边界和不支持的配置监控的更多信息,请参阅
以下是迁移的高级架构图。
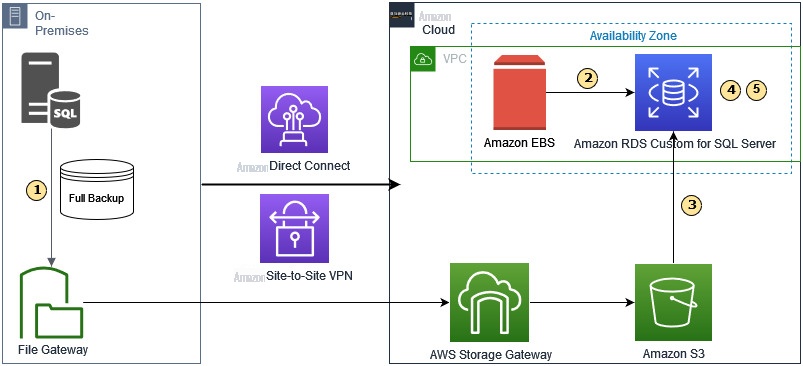
高级工作流程是:
- 将本地 SQL Server 数据库直接备份到 S3 文件网关文件共享。
- 向适用于 SQL Server 的亚马逊 RDS 定制版添加可选的 EBS 卷。
- 将备份文件从 S3 文件网关下载到 EBS 卷。
- 在适用于 SQL Server 的亚马逊 RDS 定制版上恢复备份文件。
- 移除 EBS 音量。
先决条件
我们假设您有以下先决条件:
-
有关
SQL Server 备份和恢复的 背景知识 。 -
如何为自定义 SQL Server 实例设置、启动和连接到 RDS。 -
配置为存储必要的数据库备份文件的 S3 存储桶。有关说明,请参阅
创建存储桶 。 -
S3 文件网关。有关参考,请参阅
创建和激活 Amazon S3 文件网关 。 -
S3 文件网关上的 SMB 文件共享已创建并安装到您的本地服务器上。请参阅使用
默认设置 创建 SMB 文件共享 和在客户端上 安装 SMB 文件共享 。 -
亚马逊弹性计算云 (亚马逊 EC2)和 亚马逊云科技 CLI 等 亚马逊云科技 服务。
由于此解决方案涉及设置和使用 亚马逊云科技 资源,因此会在您的账户中产生费用。有关更多信息,请参阅
将您的本地 SQL Server 数据库备份到 S3 文件网关文件共享
我们将非常大的本地数据库备份到多个备份文件以
在我们的示例中,我们备份到以下文件:
-
SampleTest_FullBackupCompressed01.bak -
SampleTest_FullBackupCompressed02.bak -
SampleTest_FullBackupCompressed03.bak -
SampleTest_FullBackupCompressed04.bak
向适用于 SQL Server 的亚马逊 RDS 定制版添加可选的 EBS 卷
创建足够大的存储卷以容纳备份文件,并确保它与 RDS Custom for SQL Server 数据库位于同一个可用区 (AZ) 中。
如果适用于 SQL Server 的 RDS 自定义部署在单可用区上,请在与 RDS 自定义相同的可用区创建 EBS 卷。
如果您的 RDS Custom for SQL Server 部署在多可用区上,要确定 RDS 自定义正在哪个可用区上运行,请按照以下步骤操作(这也可用于单可用区部署):
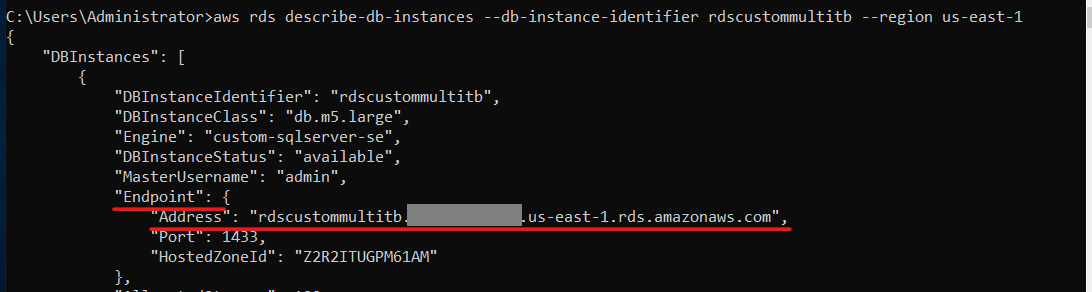
- 使用 亚马逊云科技 CLI 检索 RDS 自定义适用于 SQL 服务器的终端节点。该端点将位于 “端点”/“地址” 下 ,如下所示:
在我们的示例中:
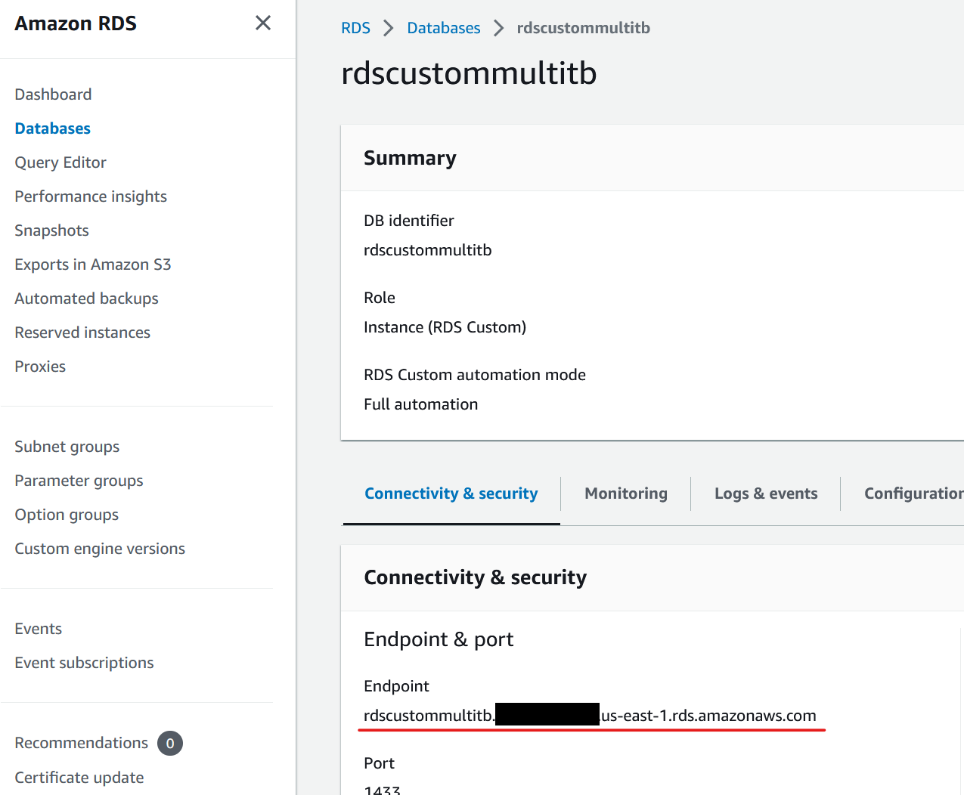
选择数据库实例后,也可以在 亚马逊云科技 RDS 控制台 的 “连接和安全” 选项卡中找到该终端节点。
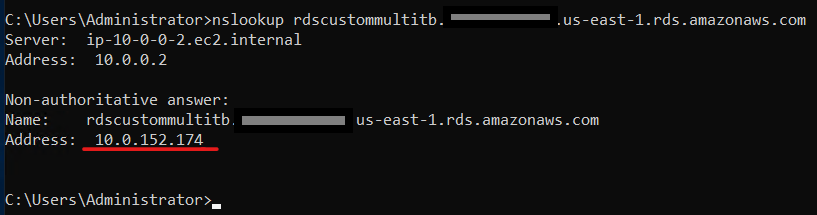
- 检索 SQL 服务器版 RDS 自定义的 IP 地址。在可以访问 RDS Custom for SQL Server 的盒子中(如果 RDS 是按照最佳实践建议在私有子网上创建的,则可能需要堡垒服务器),运行以下命令:
在我们的示例中:
-
将检索到的 IP 地址与为 RDS Custom for SQL Server 创建的 2 个 EC2 的地址进行比较,以确定哪个 EC2 处于活动状态,从而能够确定其运行的可用区域。这篇文章假设 RDS Custom for SQL Server 数据库是在
美国东部 1a可用区上创建的。
您可以使用 亚马逊云科技 控制台或 亚马逊云科技 CLI 创建 EBS 卷。有关分步说明,请参阅
-
在 Amazon EBS 控制台上,创建您的卷。在这篇文章中,我们在我们的 EBS 卷中添加了名称标签
rdscustombackupstorage。
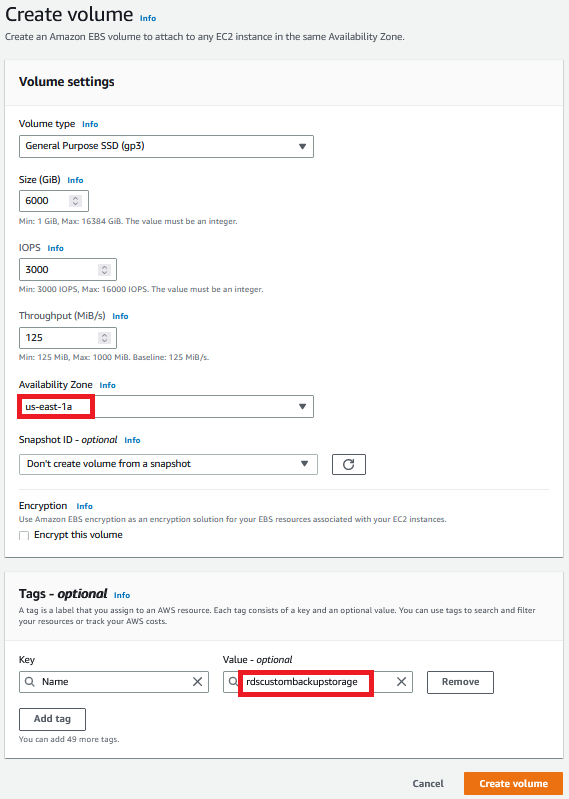
要使用 亚马逊云科技 CLI 创建 EBS 卷,请在 PowerShell 中发出类似于以下内容的命令:
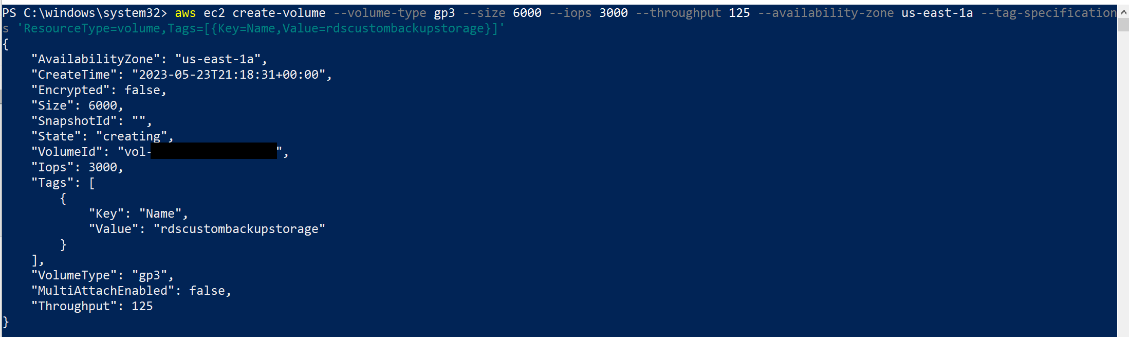
当存储卷可用时,您需要将其连接到 RDS Custom for SQL Server 实例。
- 选择您创建的 EBS 卷,然后在 “ 操作 ” 菜单上选择 “ 连接卷 ”。

- 选择 适用于 SQL 服务器的 RDS 自定义 实例。
- 选择 “ 附加音量 ” 。
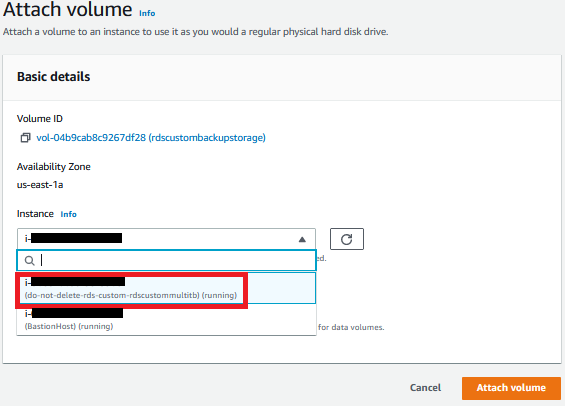
要使用 亚马逊云科技 CLI 将 EBS 卷连接到实例,请在 PowerShell 中发出类似于以下内容的命令:

将 EBS 卷连接到实例后,它将作为块储存设备公开,并在 Windows 中显示为可移动磁盘。
- 您可以使用任何文件系统格式化该卷,然后将其装载。
由于 EBS 卷大于 2 TiB,因此您必须使用 GPT 分区方案来访问整个卷。
-
要使 EBS 卷可供使用,您需要将 RDP 保存到 RDS 自定义数据库实例中。有关详细步骤,请参阅
使用 RDP 连接到 RD S 自定义数据库实例 。 -
将 RDP 转换到 RDS Custom for SQL Server 实例后,您可以使用 PowerShell、DiskPart 命令行工具或磁盘管理实用程序连接磁盘。有关更多信息,请参阅
使亚马逊 EBS 卷可供在 Windows 上使用 。
在我们的示例中,我们使用磁盘管理实用程序。
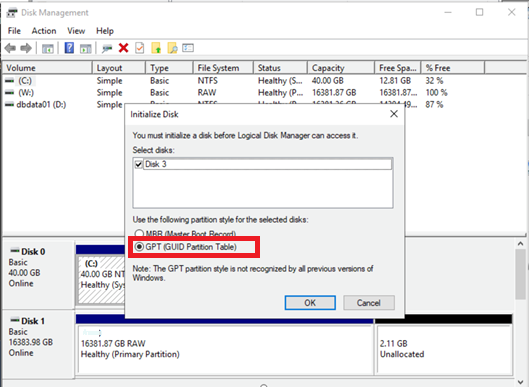
磁盘初始化后,必须创建一个卷并为其分配驱动器号。
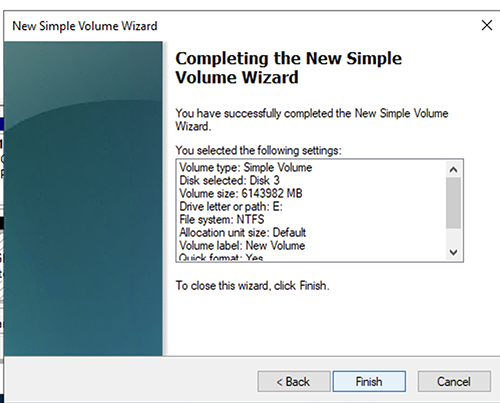
- 右键单击未分配的空间,然后选择 “ 新建简单卷 ”。
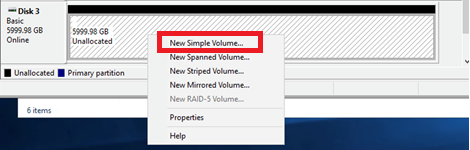
- 在欢迎页面 上选择 “ 下一步 ”。
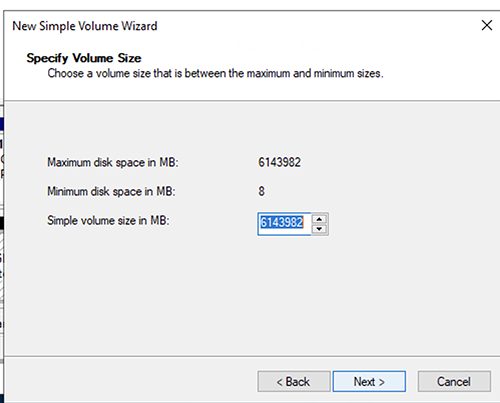
- 定义新的卷大小,然后选择 “ 下一步 ” 。
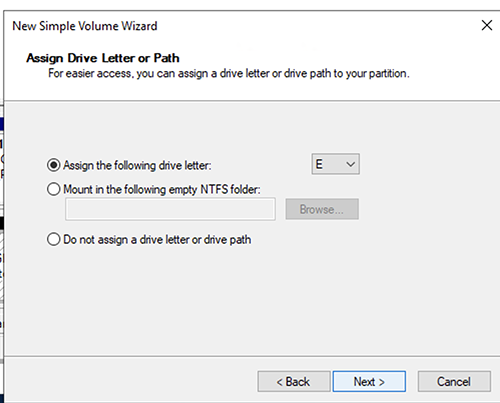
- 分配驱动器号,然后选择 Next 。
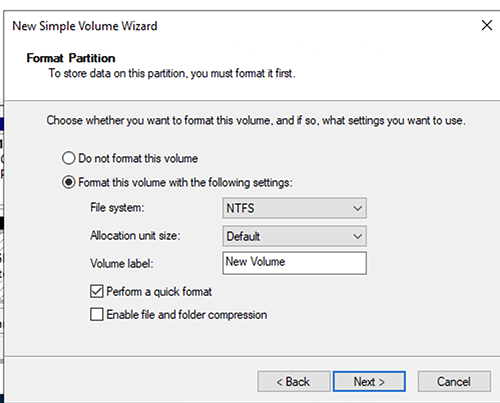
- 格式化分区,然后选择 “ 下一步 ” 。
- 查看您的设置并选择 “ 完成 ” 。
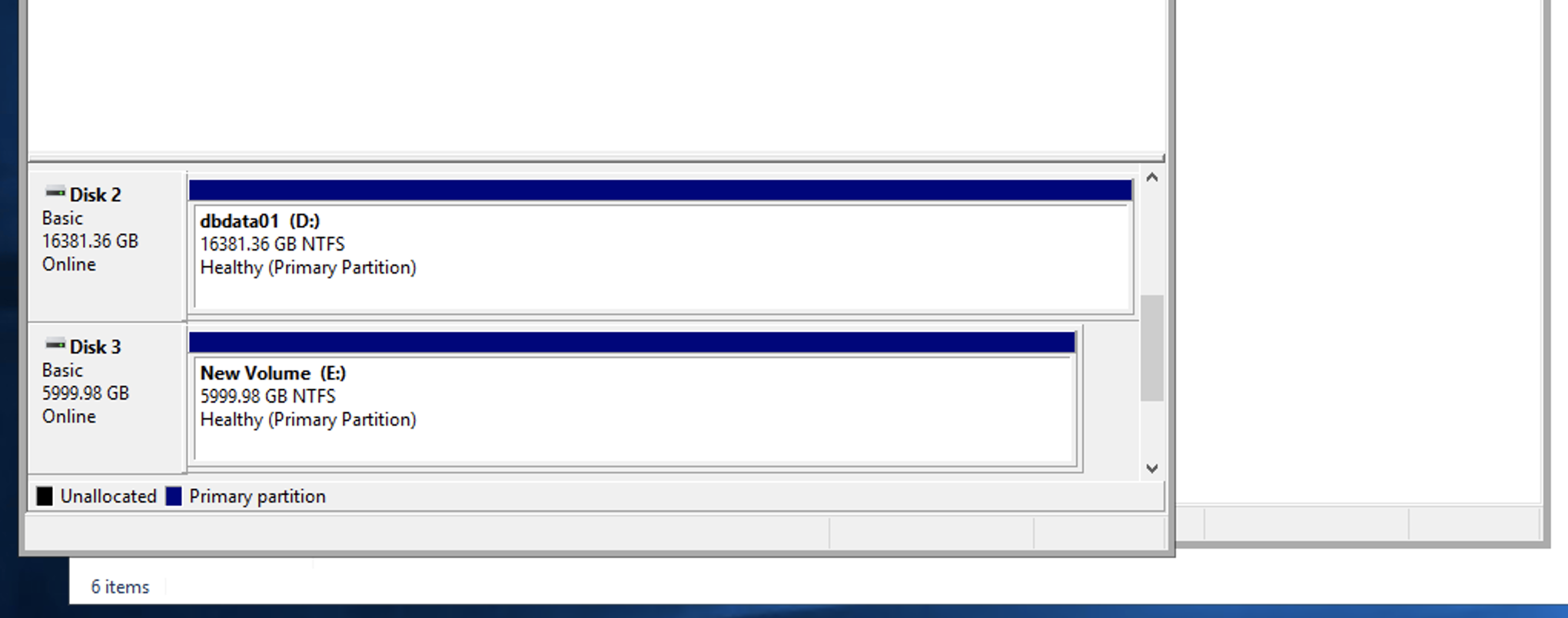
确保 E: 驱动器可通过文件资源管理器或磁盘管理实用程序使用。
要使带有原始分区的 EBS 卷可以使用 PowerShell 在 Windows 上使用,请发出与以下内容类似的命令:

将备份文件从 S3 文件网关下载到 EBS 卷
当磁盘处于联机状态且可供使用时,在安装 亚马逊云科技 CLI 后将备份从 S3 存储桶传输到新的 EBS 卷。有关将备份文件从亚马逊 S3 下载到
在目标 RDS Custom for SQL Server 实例上运行以下命令,将所有备份文件下载到在 E: 驱动器上创建的备份文件夹:
在适用于 SQL Server 的亚马逊 RDS 定制版上恢复备份文件
下载所有备份文件后,使用以下原生 SQL Server 命令恢复数据库,指向添加的 EBS 卷和备份文件的位置(在本例中
为 E:\Backup
)。数据库文件必须位于
D:\rdsdbdata\DATA
此外,使用 诸如
BLOCKSIZE 、
。
MAXT
RANSFERSIZE和B
UFFERCOUN
T之类的
移除 EBS 音量
恢复数据库后,如果您不打算再使用该卷,请务必先
要卸载该卷,请执行以下操作:
-
启动磁盘管理实用程序。
- (Windows Server 2012 及更高版本)在任务栏上,右键单击 Windows 徽标并选择 “ 磁盘管理 ”。
- Windows Server 2008) 选择 “ 开始 ” 、“ 管理工具 ” 、“ 计算机管理 ” 、“ 磁盘管理 ” 。
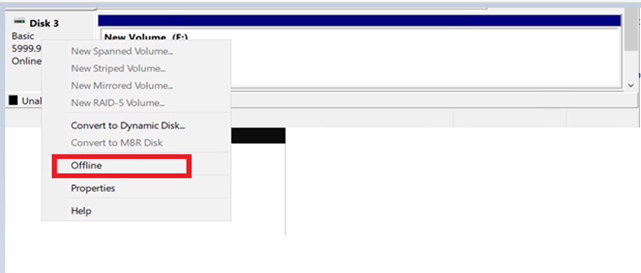
- 右键单击该磁盘,然后选择 “ 脱机 ” 。在打开 Amazon EC2 控制台 之前,请等待磁盘状态更改为 脱 机。
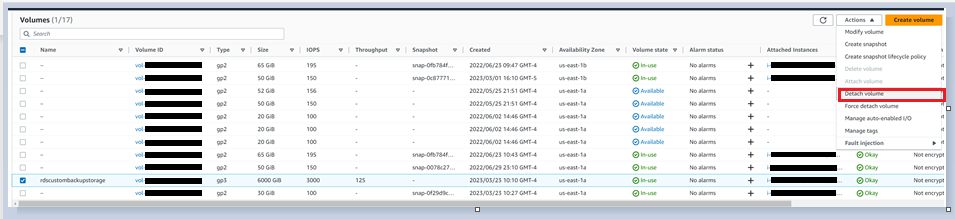
分离音量
您可以使用 亚马逊云科技 控制台分离该卷。选择 音量 ,单击 “ 操作 ”, 然后选择 “ 分离音量”。
要使用 亚马逊云科技 CLI 分离 EBS 卷,请在 Powershell 中发出与以下内容类似的命令:
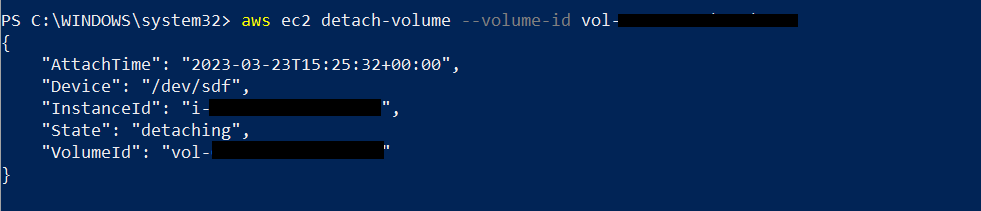
删除音量
您可以使用 亚马逊云科技 控制台删除该卷。选择音量,单击 “操作”,然后选择 “删除音量”。
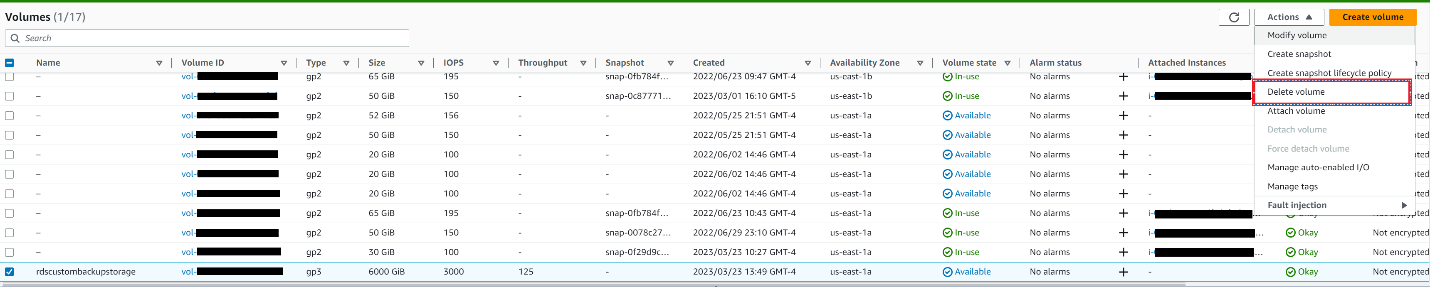
要使用 亚马逊云科技 CLI 删除 EBS 卷,请在 Powershell 中发出与以下内容类似的命令:
![]()
摘要
在这篇文章中,我们演示了如何在数据库和备份的总大小超过 16 TB 时成功迁移数据库。此方法还可以避免在传输超大型数据库时为 Amazon RDS Custom for SQL Server 预置存储空间,从而降低成本。
在本系列的第 2 部分中,我们将向您展示如何使用适用于
作者简介
 Jose Amado-Blanco
是一名数据库迁移高级顾问,在使用 亚马逊云科技 专业服务方面拥有超过 25 年的经验。他帮助客户将其数据库解决方案从本地迁移到 亚马逊云科技 并对其进行现代化改造。
Jose Amado-Blanco
是一名数据库迁移高级顾问,在使用 亚马逊云科技 专业服务方面拥有超过 25 年的经验。他帮助客户将其数据库解决方案从本地迁移到 亚马逊云科技 并对其进行现代化改造。
 Priya Nair 是 亚马逊云科技
的数据库顾问。她在使用不同数据库技术方面拥有 18 多年的经验。她是数据库迁移专家,帮助亚马逊客户将其本地数据库环境迁移到 亚马逊云科技 云数据库解决方案。
Priya Nair 是 亚马逊云科技
的数据库顾问。她在使用不同数据库技术方面拥有 18 多年的经验。她是数据库迁移专家,帮助亚马逊客户将其本地数据库环境迁移到 亚马逊云科技 云数据库解决方案。
 Suprith Krishnappa C
是亚马逊网络服务专业服务团队的数据库顾问。他与企业客户合作,为数据库项目提供技术支持和设计客户解决方案,并协助他们将现有数据库迁移到 亚马逊云科技 云并对其进行现代化改造。
Suprith Krishnappa C
是亚马逊网络服务专业服务团队的数据库顾问。他与企业客户合作,为数据库项目提供技术支持和设计客户解决方案,并协助他们将现有数据库迁移到 亚马逊云科技 云并对其进行现代化改造。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。