我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
多租户 SaaS 应用程序中的托管数据库备份和恢复
导出数据或恢复到较早的时间点是客户在软件即服务 (SaaS) 产品中寻找的核心功能。数据库备份和恢复对于业务连续性和监管合规性至关重要。您应该了解您的多租户数据分区模型将如何影响 SaaS 解决方案的备份和还原功能。
在这篇文章中,我们将探讨SaaS多租户数据库分区模型如何影响备份和恢复、备份和恢复期间租户数据隔离的方法,以及在选择性恢复租户数据时如何降低成本。
这篇文章显示了基于
数据库分区模型概述
在这篇文章中,我们提到了筒仓、桥接和池 SaaS 架构和数据库分区模型。我们仅提供基本概述;有关更多信息,请参阅 PostgreSQL 的
思洛模型为每个租户提供数据库实例或集群,无需资源共享。网桥和池模型让租户共享数据库实例或集群上的资源。在桥接模型中,每个租户在实例或集群上都有自己的数据库或架构。在池模型中,所有租户在同一个数据库中共享相同的架构。
有关数据库分区模型的更多信息,请参阅
分区模型如何影响备份和恢复
多租户解决方案可能会使数据库备份和恢复变得复杂。亚马逊云科技 提供通用工具来帮助进行备份和恢复,但您可能必须利用数据库供应商提供的工具才能获得最佳结果。
除了非 SaaS 工作负载外,基于孤岛的 SaaS 部署模型没有独特的数据库备份和恢复限制。
池化和混合 SaaS 部署模型带来了挑战,我们通常可以通过在备份(提取)阶段对租户数据进行分离(分区)来应对这些挑战,也可以在恢复(加载)阶段隔离租户数据。
执行这种隔离的操作工作量和复杂性因数据库分区模型而异。资源共享越大,划分单个租户所需的精力就越多。
SaaS 提供商之所以选择池化模型,是因为它对许多租户来说更具成本效益且更易于操作,但是与筒仓模型(每个租户都有自己的数据库)相比,由于数据库中有其他租户,租户备份和恢复要复杂得多。
分区模型还会影响可用于隔离的工具。亚马逊云科技 服务功能,例如来自亚马逊 RDS、Aurora 或
我们更喜欢在恢复期间进行隔离,以便在备份期间利用 亚马逊云科技 服务功能,并且只在恢复过程中引入运营开销。但是,在备份期间也有隔离的用例。让我们更详细地比较这两种方法。
备份期间隔离租户数据(提取)
对于 SaaS 构建者而言,这种方法可提供更简单、更快捷的恢复以及按租户保留数据。这会在备份周期内产生每租户的运营开销,这可能使这种方法不适合拥有大量租户的 SaaS 提供商。
作为 SaaS 提供商,按租户保留数据提供了多种产品机会。您可以让客户能够管理自己的保留策略、按需导出历史数据以及使用自己的加密密钥加密备份。保留每个租户的数据还有助于改善您的安全和监管合规状况。
从运营角度来看,每个租户的数据保留为管理租户的数据提供了简单的机制。您可以直接从备份中恢复,如果租户离开或援引 “被遗忘权” 法律,SaaS 提供商可以轻松删除数据。
按租户保留的数据还为衡量每个租户的备份成本提供了一种简便的方法。
为了在备份期间进行分离,每个租户的数据都要在备份过程中隔离并独立存储,如下图所示。用于隔离租户数据的方法取决于分区模型,我们稍后将对此进行研究。
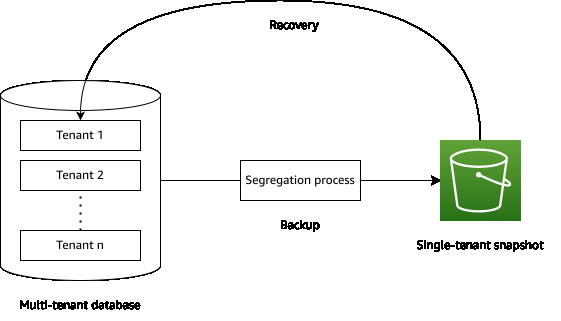
在备份期间隔离租户数据会增加每个备份周期的运营开销。对于拥有许多租户的SaaS提供商来说,这可能不切实际。随着时间的推移,您必须管理每个租户备份,而进行隔离所需的工作会给每个备份周期带来额外的性能和财务成本。
为确保备份中的数据一致性,请查阅所选关系数据库的最佳实践。这可能需要只读锁、使用预写缓冲区或服务停机。这些选择会影响租户的体验,并进一步增加备份过程的复杂性。
在恢复(加载)期间隔离租户数据
恢复过程中的隔离对于 SaaS 构建者来说很有吸引力,因为它可以提高运营效率,并且您可以将其整合到现有的备份流程中。
这种方法的好处是您可以使用 亚马逊云科技 服务功能进行备份。Aurora 备份本质 上是
仅在恢复过程中进行隔离会带来复杂性,并且在备份期间不需要停机服务。但是,这可能会在恢复过程中给租户增加性能和可用性问题。
在恢复期间进行隔离,您需要备份包含所有租户的整个数据库。您将整个多租户快照恢复到临时数据库,然后在其中隔离租户并将其数据恢复到实时数据库中。然后,您可以删除临时数据库。下图说明了这个过程。
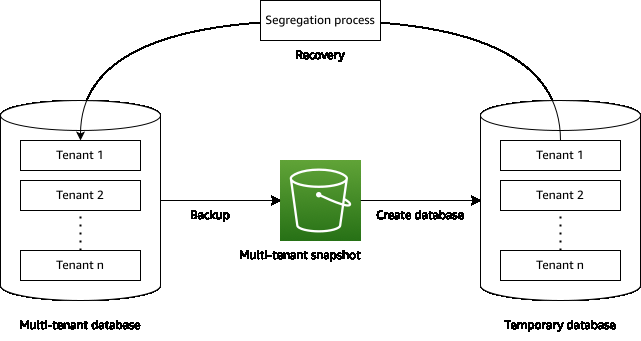
在恢复过程中需要考虑临时数据库的成本。您必须注意降低成本,尤其是大型数据库。我们将在本文的后面部分研究这些选项。
将租户数据恢复到实时数据库
在恢复过程中,您必须考虑如何处理现有租户数据以及如何将恢复的数据恢复回多租户数据库。
完全恢复到较早的时间点是最简单的方法。在恢复之前,删除所有现有的租户数据。在这种情况下,恢复的复杂性取决于分区模型,我们稍后将对此进行探讨。
要进行选择性恢复,您需要重写所有正在恢复的现有数据。您可以使用数据库引擎专用工具将隔离的租户数据导入实时数据库,覆盖现有文件。
现在,我们已经描述了备份和恢复多租户数据的两种主要方法的一些优势和挑战,让我们来看一些示例,说明如何使用 PostgreSQL 实现它们。
思洛模型中的备份和恢复
筒仓模型无需额外努力进行隔离,因为每个租户都有自己的实例或集群。
在完全时间点恢复 (PITR) 期间,将备份快照恢复到新数据库,然后将应用程序配置为连接到新还原的数据库实例或集群。然后,您可以清理旧的数据库实例或集群。有关更多信息,请参阅
或者,您可以使用数据库引擎特定的工具恢复到原始数据库集群或实例。该应用程序不需要更改配置,但还有额外的复杂性。在以下示例中,请注意,
桥接模型中的备份和恢复
由于多个租户存在于同一个数据库实例或集群上,因此每租户架构和每个租户的桥接模型带来了额外的复杂性。
数据库引擎专用工具可以隔离和恢复租户的数据库或架构。以下代码显示了隔离单个数据库或架构的示例:
池化模型中的备份和恢复
池化模型中的隔离是最复杂的,因为您在同一个表中共享租户数据,并且必须先从共享表中提取租户的数据,然后才能将其导出。
我们更倾向于在池化模型中恢复期间进行隔离,以便将隔离成本推迟到需要时再进行。由于池化数据库包含大量租户,因此性能成本和管理多个备份任务会降低运营效率。
应对隔离挑战的一种方法是将租户的数据导出到本地文件中。例如:
在恢复期间,我们会删除租户的现有数据,并将恢复的数据复制回多租户表中:
大多数数据库都有多个表,需要一种机制才能从所有表中导出租户数据。一种方法是遍历所有表,将租户的数据导出到临时表中,然后将其导出。您可以使用可重复的数据库特定函数来执行此操作,如以下代码所示:
导出多个表时,数据一致性至关重要。在恢复期间执行隔离可确保您从已经一致的备份快照中导出。
恢复期间隔离的一个缺点是,您必须恢复整个多租户数据库,对于大型数据库,这可能会产生可观的成本。导出租户数据后,请务必立即销毁所有已恢复的数据库。
在池化多租户数据库中进行选择性恢复
允许租户选择性恢复数据可能是一项有价值的产品功能。租户可能使用您的 SaaS 产品为多个客户提供服务,需要能够将单个客户恢复到较早的时间点,或者需要能够回滚不需要的更改。
允许租户选择要恢复的记录的方法取决于数据集的属性、可用记录的数量以及从中恢复的时间。与允许租户跨多个备份从大型数据集进行恢复相比,有选择地从单个备份中的小型数据集恢复要简单得多。
一种简单的方法是使用备份快照创建临时数据库,该数据库在租户选择记录时保持在线状态。这在选择期内会产生成本,我们研究了一些技术来最大限度地减少财务影响。
如果您要恢复多租户快照,则可以删除所有其他数据,但属于要恢复的租户的数据除外。当删除或重组底层数据库文件以减少空间时,Aurora 可以
为此,您可以将租户数据复制到临时表中,删除原始多租户表,然后将临时表重命名为原始多租户表名称。然后,租户可以选择要恢复的记录。参见以下示例代码:
如果恢复性能不重要,则选择成本最低的数据库产品可以降低成本。如果您预计数据库会长时间处于空闲状态,则
通过在选择过程中使用已恢复记录的临时缓存,您可以进一步降低成本,同时增加复杂性。
对于较小的数据集,您可以存储可恢复租户记录的完整副本,然后将其直接恢复到实时数据库中。这种方法可能不适用于跨多个表的大型复杂数据集。
另一种方法是使用记录元数据清单,租户使用该清单来选择要恢复的数据。合适的元数据将是主键、外键和其他与 SaaS 产品相关的列。您可以在恢复过程中生成临时清单,也可以保留一份永久库存,作为我们产品的一部分,并在备份过程中进行更新。
维护备份清单会增加复杂性和成本,但如果您的产品需要能够跨任何备份或大型数据集进行恢复,则可以提供卓越的用户体验。
结论
租户备份和恢复对于许多 SaaS 应用程序至关重要。在这篇文章中,我们研究了数据库分区模型如何影响我们执行备份和恢复的方式、每种模型中的隔离方法以及提供选择性恢复的方法。
在 SaaS 应用程序中备份和恢复托管数据库没有单一的最佳实践方法,分区模型的类型将影响此操作的复杂性。我们建议在恢复期间隔离租户数据,以降低备份期间的操作复杂性,但备份期间的隔离可以保留每个租户的数据,并降低恢复过程中的复杂性。
确定方法后,应全面测试备份恢复解决方案。无论做出何种选择,测试备份解决方案都应成为运营活动的常规部分。
有关更多信息,请参阅 PostgreSQL 的
作者简介
 戴夫·罗伯茨
是一名高级解决方案架构师,也是 SaaS Factory 团队的成员。他帮助指导和协助 亚马逊云科技 合作伙伴在 亚马逊云科技 上构建 SaaS 产品。Dave 在与大型客户合作的 IT 领域拥有超过 16 年的经验。他最初来自新西兰,现在与妻子和两个孩子一起生活在德国。
戴夫·罗伯茨
是一名高级解决方案架构师,也是 SaaS Factory 团队的成员。他帮助指导和协助 亚马逊云科技 合作伙伴在 亚马逊云科技 上构建 SaaS 产品。Dave 在与大型客户合作的 IT 领域拥有超过 16 年的经验。他最初来自新西兰,现在与妻子和两个孩子一起生活在德国。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。