我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
在亚马逊 Aurora 和亚马逊 RDS 上管理 PostgreSQL 中的排序规则更改
在这篇文章中,我们将探讨文本排序规则在
数据库中的一项基本功能是能够对数据进行排序。例如,应用程序可能需要从最早的日期到最晚的日期对计划数据进行排序,或者按名称列表进行排序。排序数字的规则由数学属性决定,但是数据库如何决定如何对文本进行排序呢?例如,数据库如何决定这些文本字符中哪一个排在最前面:
A
、
a
还是
ä
?这是数据库依赖排序规则的地方。
排序规则是一组定义文本排序方式的规则。归类与字符编码(例如 UTF-8)一起使用,以定义每个字符的排序方式。归类规则可能因区域而异。例如,在德语中,
o
字符等同于
ö
进行排序,但在土耳其语中,
o
和
ö
的排序方式不同。归类是计算机系统的基本组成部分,作为操作系统的一部分包含在内。在 Linux 中,对排序规则的支持通常来自
在关系数据库中,比较两个字符串时使用排序规则,例如在 JOI
N
子句中,当 ORDER B Y 子句中有文本列时,以及在构建和维护文本数据的索引时。
请注意土耳其语排序规则是如何将
以下示例使用带有德语排序规则(“
de_DE”)和土耳其语排序规则( “ tr_
tr
”)的 PostgreSQL 来演示这两种归类如何区别对待 o 和 ö字符。
öb
字符串排序在列表最后的:
返回:
和:
返回:
由于在语言中添加了新字符或修改了订购规则,排序规则可能会随着时间的推移而发生变化。这些更改可能会产生影响数据存储的后果,尤其是在索引方面,在索引方面,值可能不再按预期顺序存储。
排序规则在 PostgreSQL 中的工作原理
初始化新的 PostgreSQL 集群时,它会检查操作系统以查看有哪些归类提供程序可用:glibc、ICU 或两者兼而有之。根据 PostgreSQL 的发现,它使用操作系统上可用的归类填充 名为
pg_collation
的
除非另行指定,否则在此集群中创建的任何数据库都将使用此归类。
这可能来自环境变量
LC_COLLATE 和 LC_CTYPE,也可以来自将参数 -- lc-collate
和--lc-ctyp
e 传递给 initd
b(或者,这些值可以从
--locale 选项
中派生)。
en_us.UTF-
8 归类,但你可以选择使用其他可用的归类。您可以使用以下查询查看可用归类的完整列表:
要获取您当前连接的数据库的默认排序规则,请运行以下查询:
在 PostgreSQL 中可以在不同的级别上设置排序规则。例如,PostgreSQL 用户可以将数据库配置为使用特定的排序规则,或者选择对列或索引使用特定的排序规则。实际上,可以指定在每个查询的基础上使用的排序规则,尽管这可能会根据数据集的大小以及整理后的数据是否存在于索引中而影响性能。
让我们探讨一下 PostgreSQL 在构建和维护文本列的索引时如何使用排序规则。在本练习中,我们使用具有以下定义的表格:
请注意,我们没有在 animal_name 列上指定排序规则,因此这将使用数据库的默认排序规则。您可以使用以下查询来验证 animal_name 是否使用了该数据库的默认排序规则:
在此示例中,应将
collation_name
字段设置为默认值:
现在,让我们用几个动物的名字填充这个表格。您可以使用以下查询来执行此操作:
在 an
imal_n
ame 列上创建索引。以下查询创建了一个名为 animals_an
imal
_name_idx 的索引:
当你运行前面的命令时,PostgreSQL 会为 animal_name 列中的值创建一个
构建 B 树索引的一部分是按顺序排列值。为了对
文本
列执行此操作,PostgreSQL 使用排序规则来确定如何比较和排序每个文本字段的每个字符,并使用它在索引中适当地放置值。
以下查询向您展示了用于构建和维护 animals_
animal
_name_idx 索引的归类:
在此示例中,应将
collation_name
字段设置为默认值:
同样,我们没有为该索引指定排序规则,因此 PostgreSQL 使用了该数据库的默认排序规则。
现在我们已经了解了排序规则在 PostgreSQL 中的工作原理,让我们来探讨索引是如何使用排序规则的。
B 树索引如何使用归类
本节简要介绍了 B 树索引的工作原理。与 PostgreSQL B 树索引实现相比,这已经简化了。有关更多详细信息,请参阅
B 树索引由旨在高效搜索数据的节点组成。叶节点包含索引数据并按顺序存储。叶节点指向相邻的叶节点,这有助于提高检索重复值、一系列值或对使用索引的查询进行排序时的性能。B 树索引使用内部节点来查找存储在叶节点中的值。内部节点会跟踪在其叶节点中找到的值范围,无论内部节点是直接指向它们还是将其作为后代。
排序的关键属性是不变性。确定排序的不变性意味着确定两个值顺序的函数在给定相同的输入时必须返回相同的结果。排序中的不变性有助于提高索引的可维护性和性能,因为它限制了我们在插入更多值时需要对索引进行更新的次数,并允许我们有效地搜索叶节点。
为文本数据构建 B 树索引时,它依靠排序规则来确定字符的排序方式。让我们通过在 B 树索引中搜索文本值来看看实际情况。下图显示了根据一组动物名称创建的 B 树索引。让我们使用这个索引来找出
狗
的价值 。
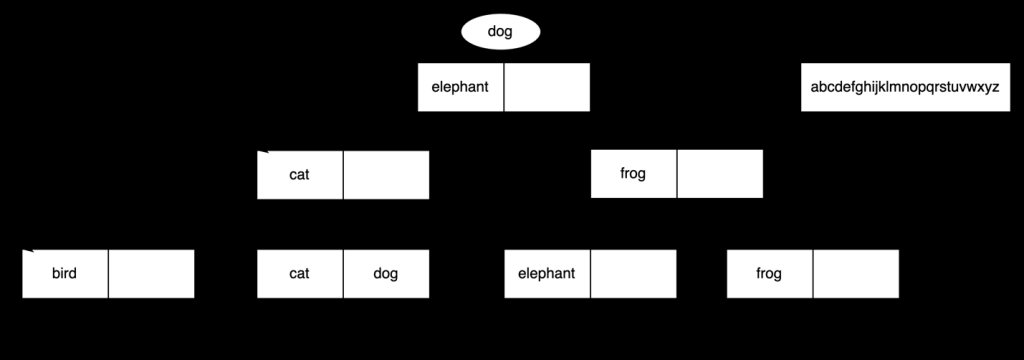
首先,我们需要将
狗
与
大象
进行比较 。查看排序规则,我们看到
d
位于
e
之前 ,如下图所示。
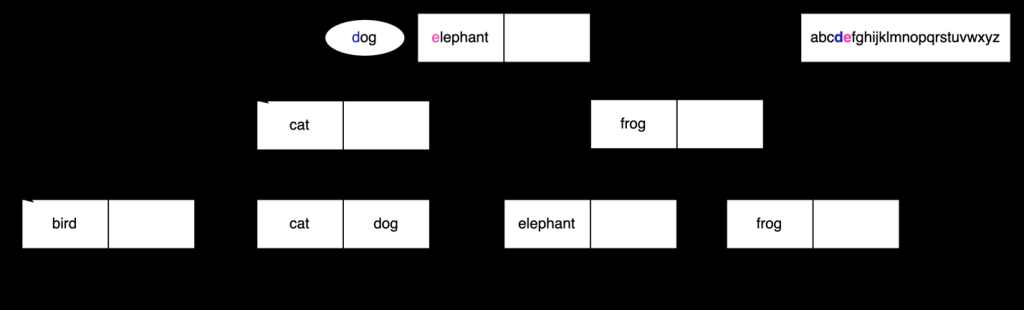
这告诉我们,我们可以继续在这个 B 树索引的左边寻找
狗
。下一个比较是
狗
和
猫
。再一次,我们看一下排序规则,发现
d 位于
c
之后 ,如下图所示。
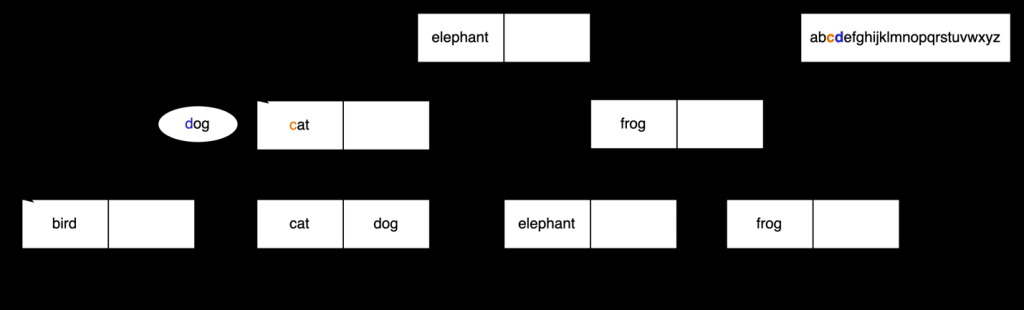
利用这个结果,我们知道我们可以从包含
cat
的叶子节点开始搜索 。从归类中我们知道
d
位于
c
之后 ,但我们确实看到这个叶子节点中有
dog
的值 可用。
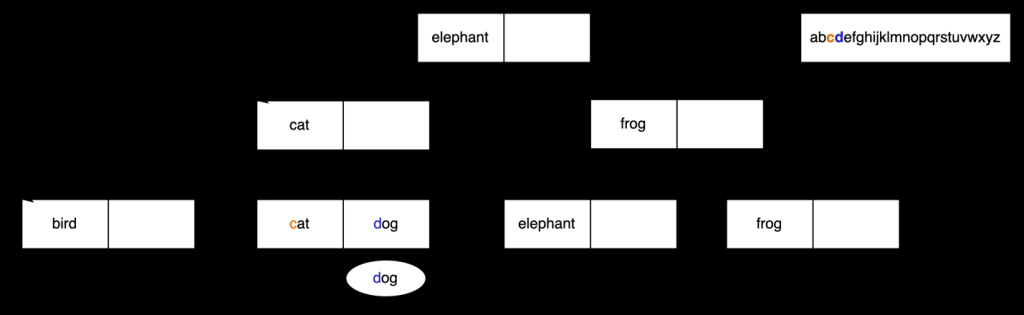
现在,我们继续遍历叶节点,直到找不到更多匹配的值。在这个例子中,我们可以看到
狗
和
大象
不匹配,我们可以结束搜索。
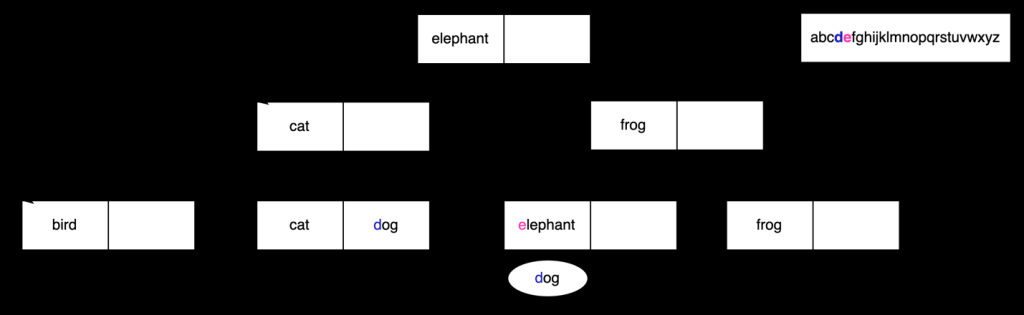
这是一个简化的示例,演示了如何使用排序规则搜索带有文本值的 B 树索引。现在让我们看看在使用内置索引时如果排序规则发生变化会发生什么。
归类发生变化时会发生什么
回想一下,B 树索引需要使用不可变函数来确定值的排序方式。对于文本数据,这意味着使用排序规则。但是,如果排序规则中的顺序发生变化,会发生什么?
使用上一节中的示例,归类库进行了更新,使
e
位
于 d
之前。如果我们尝试在索引 上搜索
狗
会怎样?正如我们在之前的搜索中所做的那样,我们将
狗
与
大象
进行了比较 。
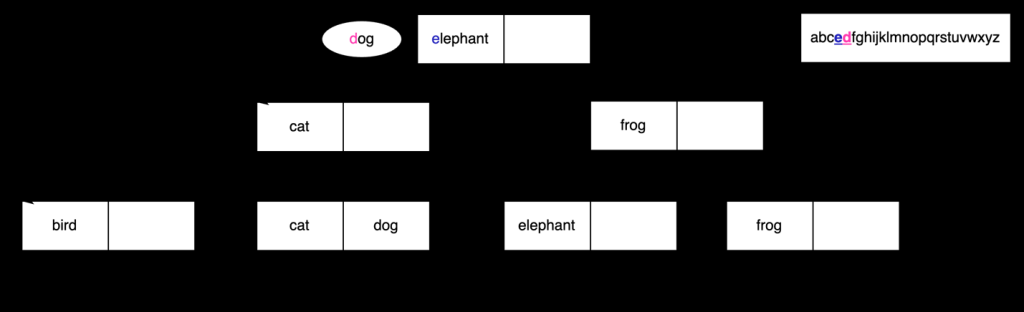
但是,由于我们的归类库说
d
位于
e
之后 ,因此我们必须继续在 B 树的右侧进行搜索。我们现在必须比较
狗
和
青蛙
。
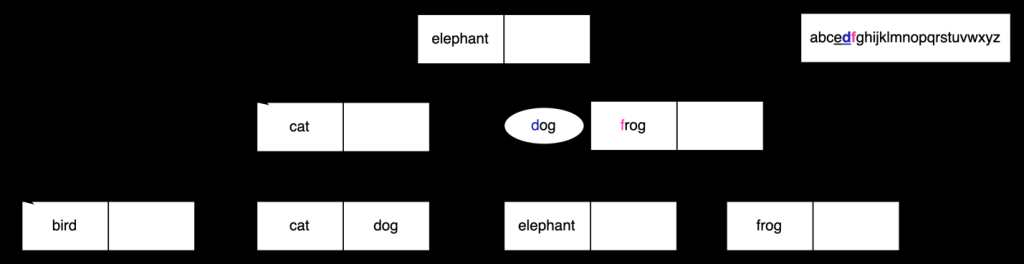
使用归类库,
d
仍然位于
f
之前 ,因此我们可以继续使用包含 e
lephant
的叶节点。
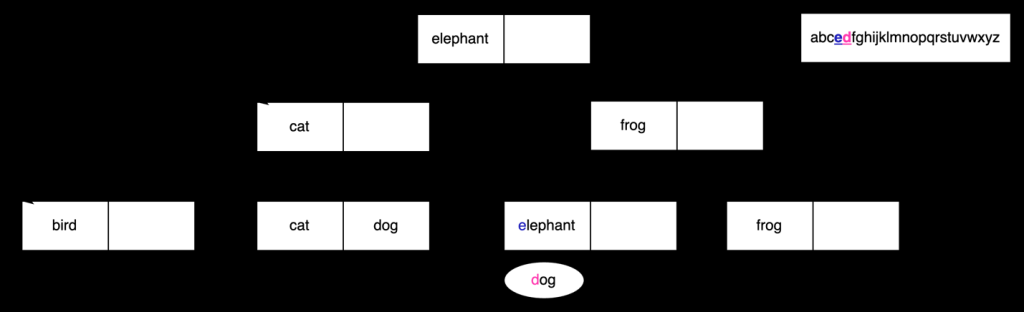
但是,由于归类库的更新,
e
位
于 d
之前 ,因此我们必须继续在下一个叶节点中搜索。
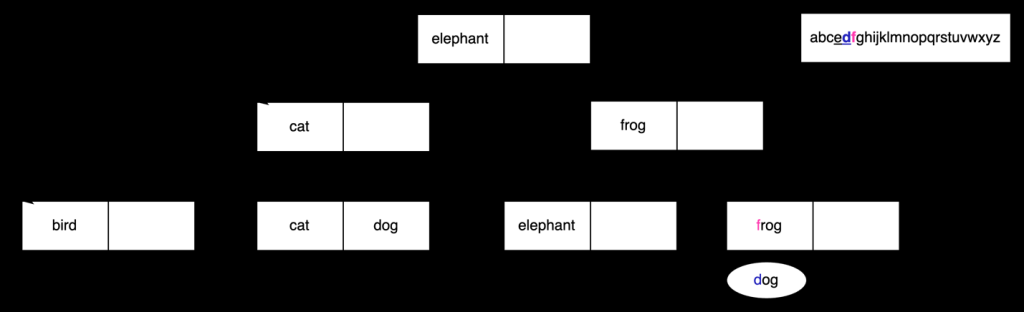
正如我们之前看到的,在此归类 中,
d
位于
f
之前,因此搜索停止并且我们不会从该索引返回任何结果。这是不正确的:我们应该找到存储在此索引中的
狗
的价值!
归类中的顺序是用于比较和排序索引中字符串的不变性函数。此示例表明,在重建索引之前,更改正在使用的归类可能会导致错误的结果。
在底层操作系统上更新 glibc 或 ICU 时,PostgreSQL 中可能会发生排序规则更改。从 PostgreSQL 15 及更早版本开始,PostgreSQL 仅允许在给定时间使用单个版本的归类提供程序。如果新版本的归类提供程序更改了先前构建的索引中使用的字符顺序,则索引中的持久顺序可能不再与归类库指定的顺序相匹配。为了避免查询结果不正确,你必须重建该索引。
glibc 的主要版本更新通常包含对现有归类的更新。glibc 中排序规则变化影响 PostgreSQL 的一个已知例子是 glibc 2.28。PostgreSQL 社区提供的文档表明 g
现在我们已经看到了排序规则更改如何影响 PostgreSQL 中索引的文本数据,让我们学习如何检测排序规则更改并解决与之相关的问题。
检测和管理 PostgreSQL 中的排序规则更改
以下示例说明如何检测来自 glibc 提供程序的归类版本更改。我们之所以选择使用它,是因为它是亚马逊 Aurora 和 Amazon RDS 上的 PostgreSQL 数据库中最常用的归类提供程序。使用 ICU 时,您可以按照类似的步骤来检测归类版本的变化。
首先,你应该确定在你的 PostgreSQL 实例上使用的是哪个版本的 glibc。从 PostgreSQL 13 开始,你可以通过以下查询来确定这一点:
在运行 PostgreSQL 版本 14.5 的亚马逊 RDS PostgreSQL 实例上,前面的查询返回以下结果:
如果您认为正在使用的 glibc 归类版本发生了变化,则需要识别使用此归类的文本索引。以下查询提供了可能受到归类版本更改影响的 B 树文本索引列表:
以下是此查询的输出示例。输出被截断以显示在前面示例中创建的
animals_animal_name_idx 索引包含
在此列表中:
此时,您有一个可能需要重建的索引列表。PostgreSQL 提供了一个名为
的扩展程序 和一个名为
k 的命令行工具 ,它可以检测 B 树索引是否受到归类版本变化的影响。我们在这个示例中使用
amcheck
扩展程序,因为它在亚马逊 Aurora PostgreSQL 兼容版和适用于 PostgreSQL 的亚马逊 RDS 中可用。您可以使用以下命令将
amcheck
扩展名添加到数据库中:
以下查询检查在前面的示例中创建的 animals_
animal_name_idx
索引是否受到归类版本变化的影响:
如果索引没有问题,则前面的查询将返回空结果:
但是,如果索引确实存在问题,
bt_index_check
会抛出错误。以下是索引受到归类更改影响时您可能会看到的错误类型的示例:
必须重建受影响的索引。你可以使用
REIN
DEX 时使用并
发
选项 ,这样可以减轻锁定对可用性的影响。
但是,如果 glibc 归类版本更改为特定索引所产生的影响使其无法使用,例如您的查询持续出错或崩溃,则您必须在没有 CONCONCURLRENTY 选项的情况下重建索引。
以下查询显示了如何重建在前面示例中创建的
animals_animal_name_idx 索
引:
此示例提供了一个基本的工具包,用于检测 PostgreSQL 归类提供程序的更改、确定哪些索引受到影响以及解决与排序规则更改相关的问题。现在让我们来了解一下亚马逊 Aurora 和 Amazon RDS 正在采取哪些措施来简化归类的管理。
亚马逊 Aurora 和亚马逊 RDS 如何简化归类的管理
随着兼容亚马逊 Aurora PostgreSQL 的版本 14.6、13.9、12.13 和 11.18 版本以及适用于 PostgreSQL 14.6、13.9、12.13、11.18 和 10.23 的亚马逊 RDS 版本,亚马逊 Aurora 和亚马逊 RDS 推出了一个独立的默认归类库,将 glibc 归类版本冻结为 2.26-59。这并不是 glibc 本身的冻结——亚马逊 Aurora 和亚马逊 RDS 将继续更新 glibc。归类将保持不可变,而 glibc 将继续获得安全和错误修复。
如果你要更新到兼容亚马逊 Aurora PostgreSQL 的版本和适用于 PostgreSQL 的亚马逊 RDS 的更新版本,在极少数情况下,你可能会受到 glibc 版本变更的影响。您可以使用前面的指南来确定索引是否受到影响并重建索引。一旦你使用了兼容亚马逊 Aurora PostgreSQL 的版本和适用于 PostgreSQL 的 Amazon RDS 的最新版本,你的 glibc 归类版本将冻结在 2.26-59,你应该不会再受到本文中描述的问题的影响。
清理
如果您安装了
amcheck
扩展程序但不再需要它,则可以使用以下命令将其删除:
如果您在本文中使用了示例,则可以使用以下命令删除数据:
结论
在这篇文章中,我们了解了归类如何成为计算机中文本数据排序的基本组成部分。我们还学习了数据库如何使用排序规则以及使用数据库索引时排序规则不变性的重要性。我们探讨了 PostgreSQL 如何使用排序规则、如何检测排序规则的变化、哪些 PostgreSQL 索引可能会受到排序规则更改的影响,以及如何解决任何问题。最后,我们了解了亚马逊 Aurora PostgreSQL 兼容版和适用于 PostgreSQL 的亚马逊 RDS 正在采取哪些措施来简化归类管理。
PostgreSQL 开发社区正在努力改善归类管理和使用。这包括能够在同一 PostgreSQL 集群中使用多个版本的 ICU,以及支持管理归类提供程序版本的扩展。
有关如何在亚马逊 Aurora 和亚马逊 RDS 中管理 PostgreSQL 归类的更多信息,请参阅 Aurora PostgreSQL
我们邀请您在这篇文章的评论部分留下反馈。
作者简介

*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。