我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 CloudWatch 和 亚马逊云科技 X-Ray 降低 MTTR
在无服务器环境中运行基于微服务的工作负载的客户经常会遇到故障排除问题,因为他们需要的数据可以分布在成百上千个组件上。
了解你的依赖关系
CloudWatch ServiceLens 可帮助您可视化分布式环境并了解服务之间的依赖关系。它将指标、日志和跟踪汇总到服务地图中,因此您可以
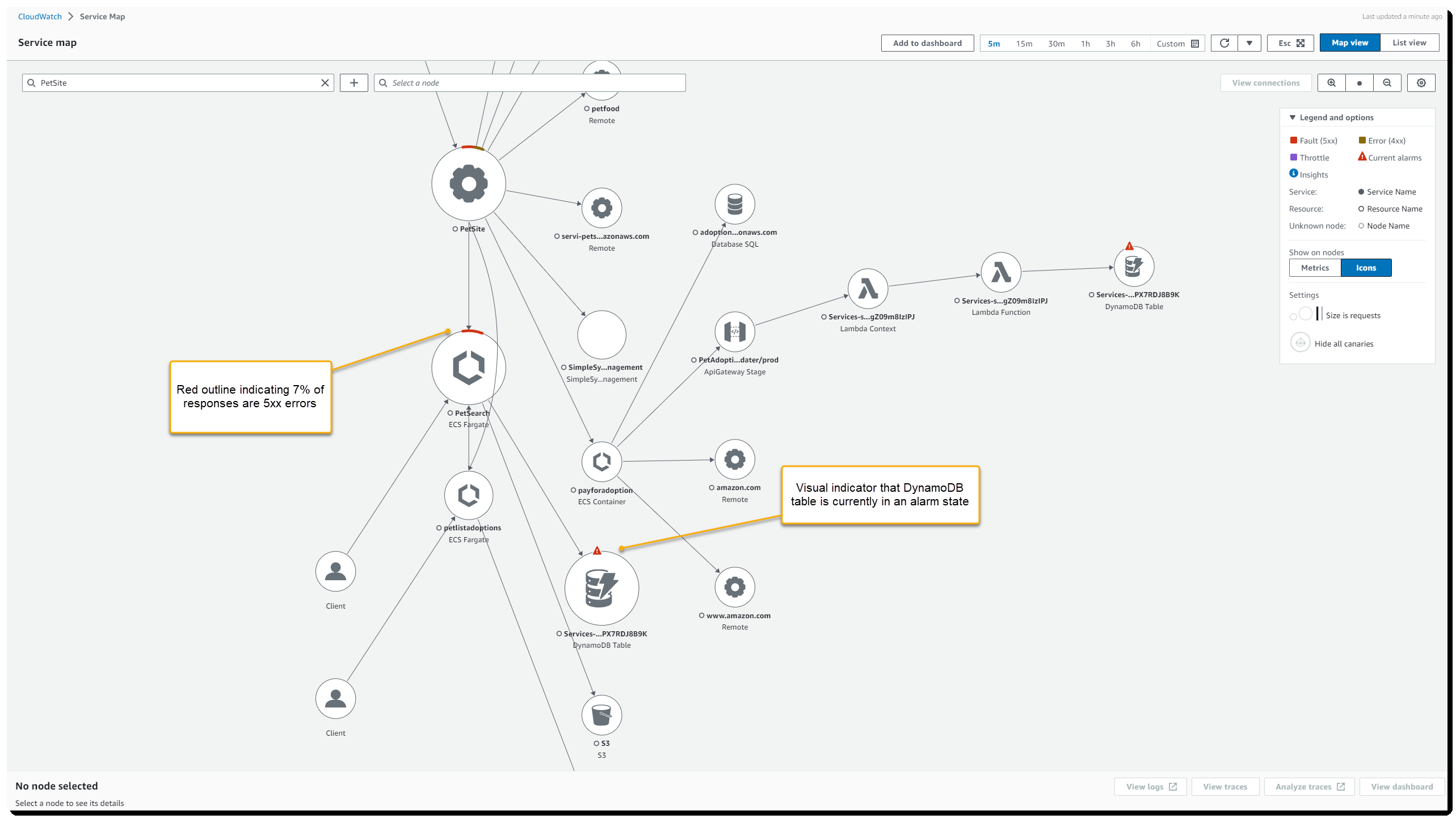
图 1:CloudWatch 服务镜头地图
默认情况下,每个节点的大小及其之间的边缘代表它们正在接收的请求数。可以通过选择齿轮图标加载 “ 首选项 ” 对话框并选择其他衡量标准(例如 延迟 )来更改此设置 。选择节点将打开一个面板,其中包含更多指标,显示一段时间内的延迟、请求和故障,并提供指向您的日志、跟踪和更详细的仪表板的链接。
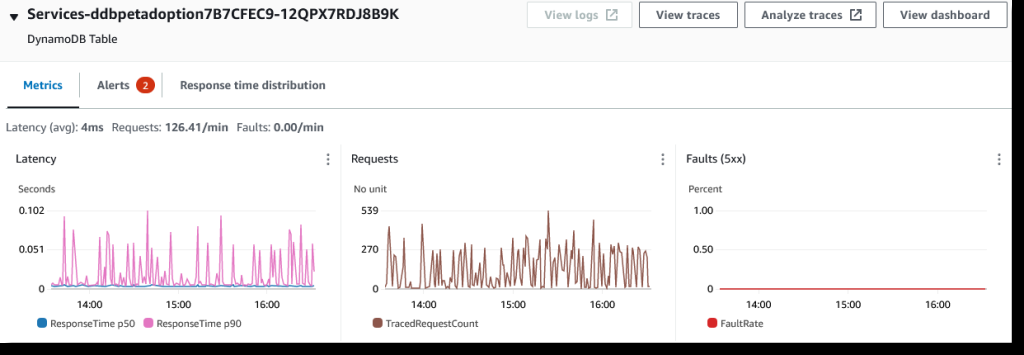
图 2:DynamoDB 表指标
该面板还将显示与资源相关的所有警报。在上图中,您可以看到 DynamoDB 表的两个警报当前处于警报状态。
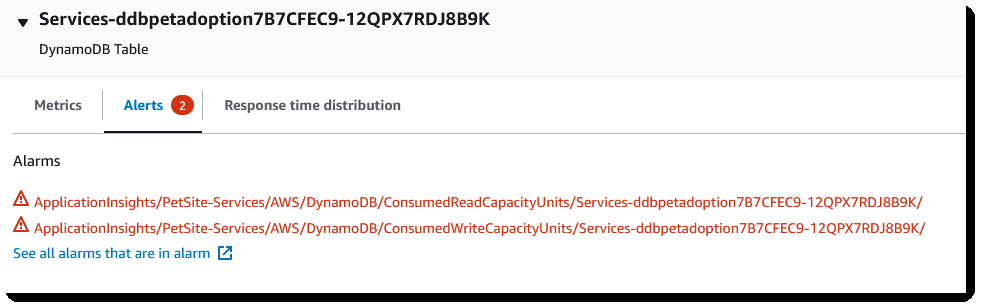
图 3:DynamoDB 表警报
回到服务地图,让我们看一下其中一个出现故障的节点,然后选择 “
查看连接
”,重点关注该特定资源的所有传入和传出请求。或者,您可以使用
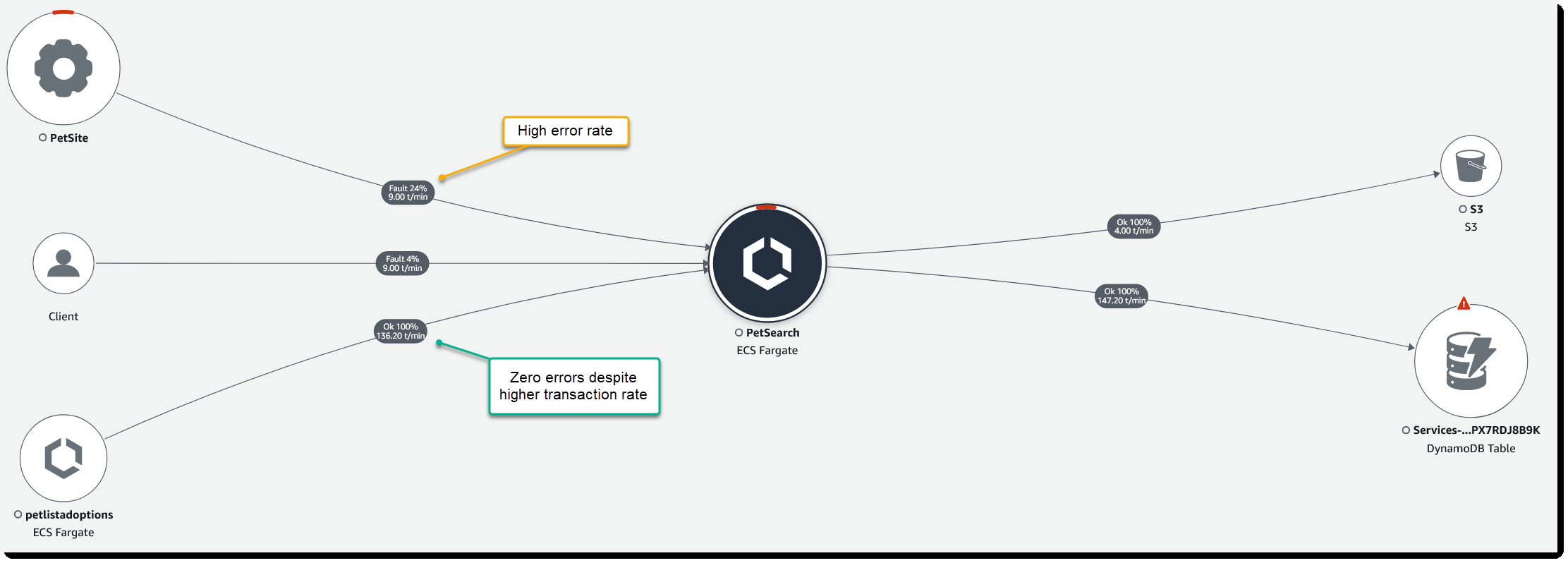
图 4:PetSearch 微服务的传入和传出请求
从前面的图片中,你可以看到有三个节点向后端 PetSearch 微服务发出请求,其中只有两个节点遇到了问题。选择其中一条边会出现一个面板,该面板上有一个 响应时间分布图 , 汇总了该路径上的流量。如果要排除延迟故障,可以突出显示图表中显示响应时间较慢的部分,然后打开 “ 查看筛选的跟踪 ” 按钮以获取所选时间窗口内的跟踪列表。 在这种情况下,我更关心来自前端 PetSite 服务的 24% 错误率,因此我选中 24% 故障 (5xx) 旁边的复选框 并打开 “查看筛选的跟踪记录”。
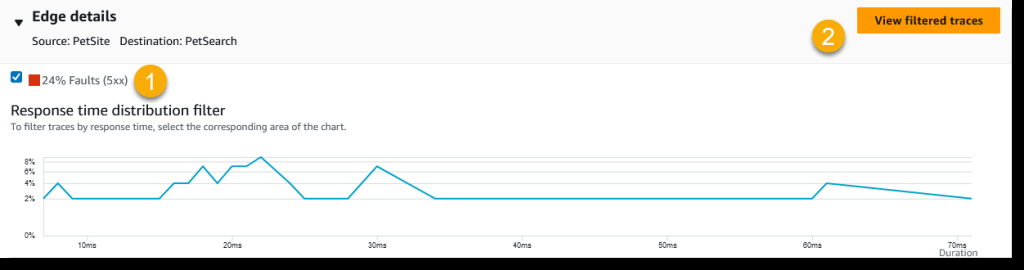
图 5:响应时间分布
这将加载一个新页面,如果需要,你可以在其中进一步细化查询。从表中选择第一条追踪信息,您将进入 跟踪详细信息 页面。
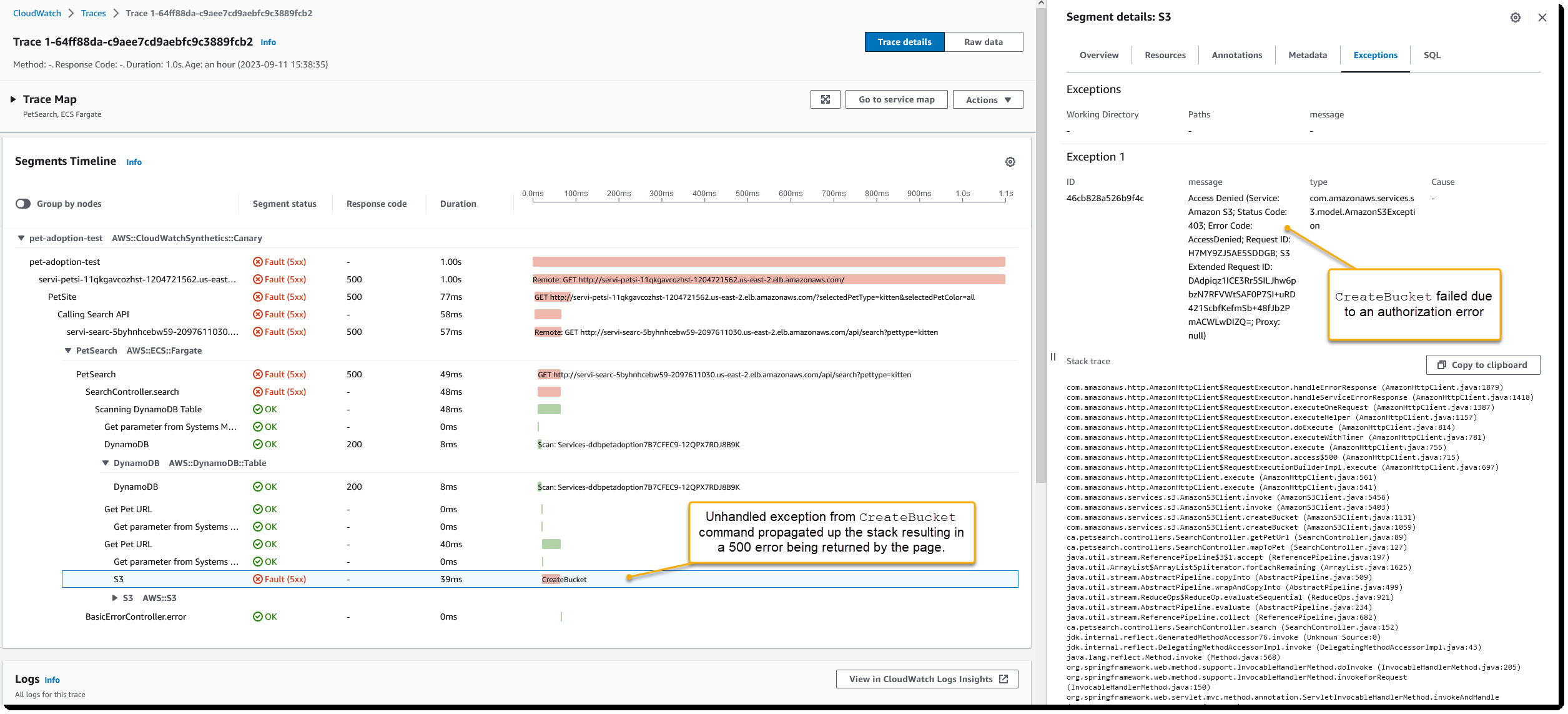
图 6:追踪详情
使用 区段时间表 ,您可以清楚地了解分布式系统中发生的事情,并可以清楚地看到每个响应的状态以及请求需要多长时间才能得到答复。从时间轴中选择一个区段会加载一个包含其他详细信息的面板,这样您就可以 在 “ 异常 ” 选项卡上看到失败的根本原因是导致授权错误的权限问题。该页面还显示与跟踪相关的所有服务的关联日志消息列表,使您可以在一个地方查看来自不同日志组的日志。
与 亚马逊云科技 X-Ray 集成
ServiceLens 使用来自 X-Ray 的跟踪来构建其服务地图,以了解服务之间的依赖关系。虽然您想要捕获的某些互动需要对
为您的 亚马逊云科技 Lambda 函数启用 X-Ray
-
打开
亚马逊云科技 Lambda 控制台 - 从列表中选择您的函数函数
- 选择 “ 配置 ” 选项卡,然后选择 “ 监控和操作工具 ”
- 选择 “ 编辑” ,然后在 亚马逊云科技 X- Ray 下切换 “ 活动跟踪 ”
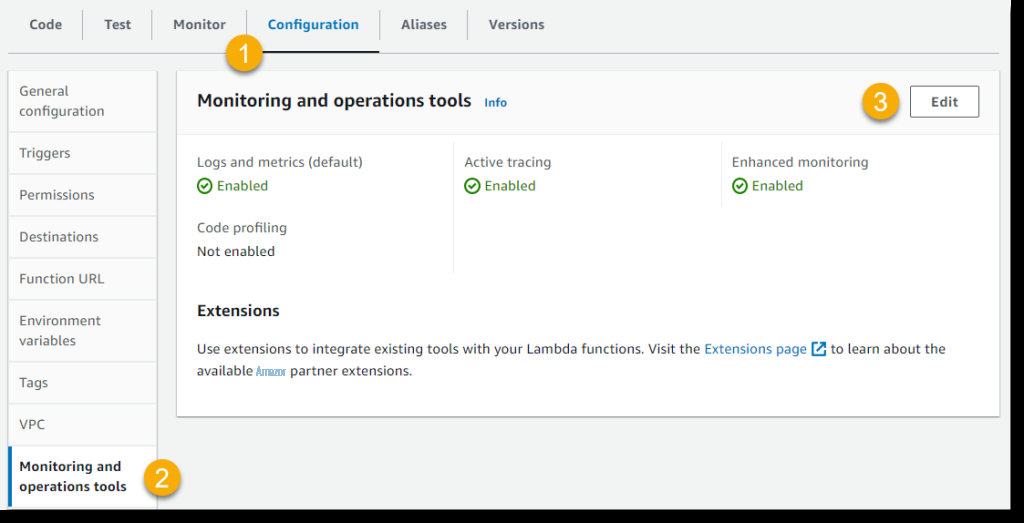
图 7:亚马逊云科技 Lambda 配置工具
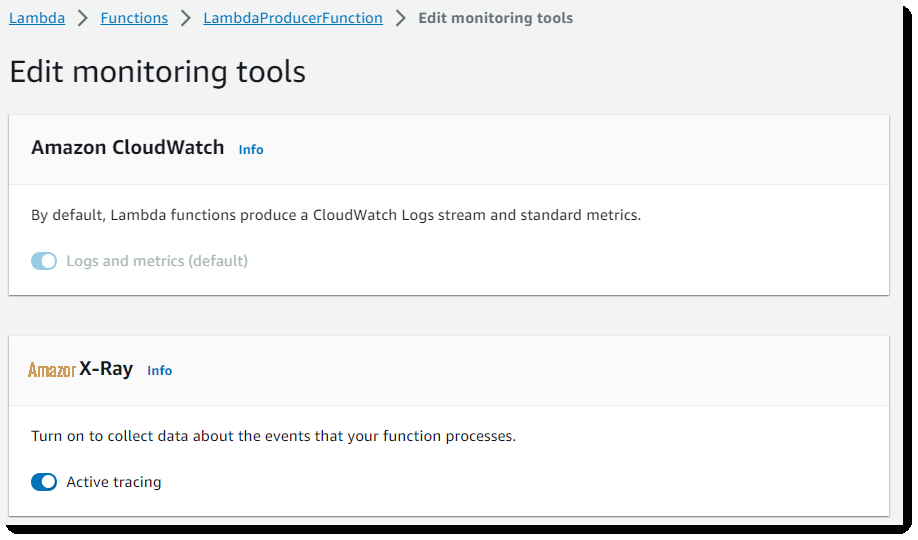
图 8:启用 亚马逊云科技 X-Ray
在为您的 Lambda 函数启用主动跟踪的页面上,您还将在增强监控标题 下看到启用
结论
在这篇文章中,我回顾了一些可以使用 CloudWatch ServiceLens 和 亚马逊云科技 X-Ray 来监控和观察分布式工作负载的方法,重点是服务之间的集成。收到问题警报后,ServiceLens可以帮助您深入研究相关痕迹,以便您可以诊断故障并开始制定恢复正常业务运营的计划。
有兴趣进一步了解监控和可观测性吗?查看
作者简介
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。