我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Life360 迈向多集群 Amazon EKS 架构以提高弹性的旅程
这篇文章由员工现场可靠性高级经理杰西·冈萨雷斯和Life360可靠性工程高级工程经理Naveen Puvvula共同撰写
简介
Life360 的使命是简化安全,让家庭能够过上充实的生活。仅在2022年,Life360就给紧急调度员打了超过34,000次电话,并收到了来自会员的近220万次应用内SOS警报。Life360 碰撞检测系统行驶了 2230 亿英里,从而拯救了全球会员的生命。为家庭安全网增加了260亿条安全抵达通知。我们服务的任何中断都会直接影响家庭成员在紧急情况下派遣救护车的能力。我们的应用程序编程接口 (API) 的全天候可用性至关重要,这需要越来越稳定和可扩展的基础架构。
解决方案架构
在我们当前的架构中,我们遵循 亚马逊云科技 高可用性最佳实践,将工作负载分散到多个可用区 (AZ),并使用 A
总体而言,我们在边缘使用由 亚马逊云科技 应用程序负载均衡器 (
我们的目标是建立
借助 Amazon EC2 中的工作负载,我们可以更好地控制流量路由,并且可以使用 Consul 和 HAProxy 中的优先权重来防止我们的交易跨越亚利桑那州边界。如今,在我们的 Amazon EC2 工作负载中,最佳交易一旦进入我们的环境就会停留在可用区。在我们的多可用区 Amazon EKS 集群中,因为我们不使用 HAProxy 或 Consul,它会崩溃,因为不能保证与另一个
我们选择采用基于单元的多集群 Amazon EKS 架构来提高弹性。通过将集群限制为单可用区,我们还避免了可用区间的数据传输成本。在这篇文章中,我们分享了我们的多集群 Amazon EKS 架构和运营改进,以解决 Amazon EKS 的扩展和工作负载管理问题,并为整个可用区的故障提供静态稳定的弹性基础设施。
Life360 的未来状态:多集群亚马逊 EKS 架构
为了确保静态稳定的设计,我们选择实施隔板架构(也称为基于单元的架构),以限制故障在单个可用区内的影响。让我们更多地讨论一下隔板架构。
隔板架构
舱壁图案的名字来自于海军工程实践,船舶的内部舱室用于隔离船体,因此,如果物体要破裂,水就无法扩散到整艘船,导致其沉没。有关可视化说明,请参见图 1。
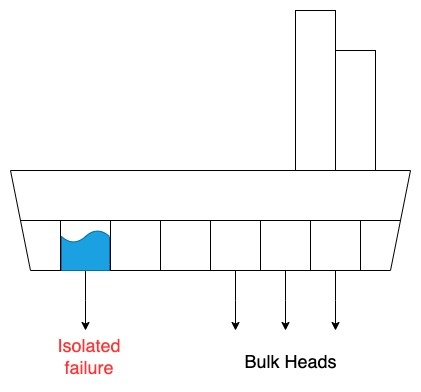
图 1。隔板图案
就像船上的舱壁一样,这种模式可确保一小部分请求或客户机出现故障,从而限制受损请求的数量,并且大多数请求可以毫无错误地继续进行。数据的隔板通常被称为分区,而服务的隔板被称为信元。
在 基于单元的架构 中 ,每个单元都是服务的一个完整、独立的实例,并且具有固定的最大大小。随着负载的增加,通过添加更多单元来增加工作负载。任何故障都包含在其发生的单个单元中,因此受损请求的数量受到限制,因为其他单元会继续正常运行。
Life360 基于细胞的架构
在评估如何设计 Amazon EKS 环境的下一次迭代时,我们使用了隔板设计原则。我们的设计实质上使我们从多可用区 Amazon EKS 集群解决方案转向了单一可用区 Amazon EKS 集群解决方案,即每个区域内有多个 Amazon EKS 集群。这实质上将每个 Amazon EKS 集群变成了隔板模式的单元。我们将这些单独的单个 AZ Amazon EKS 集群称为 细 胞 , 将每个区域中的细胞聚合称为 超级单元。
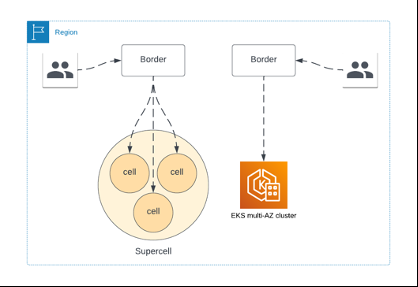
图 2:从 Amazon EKS 多可用区过渡到超级蜂窝架构
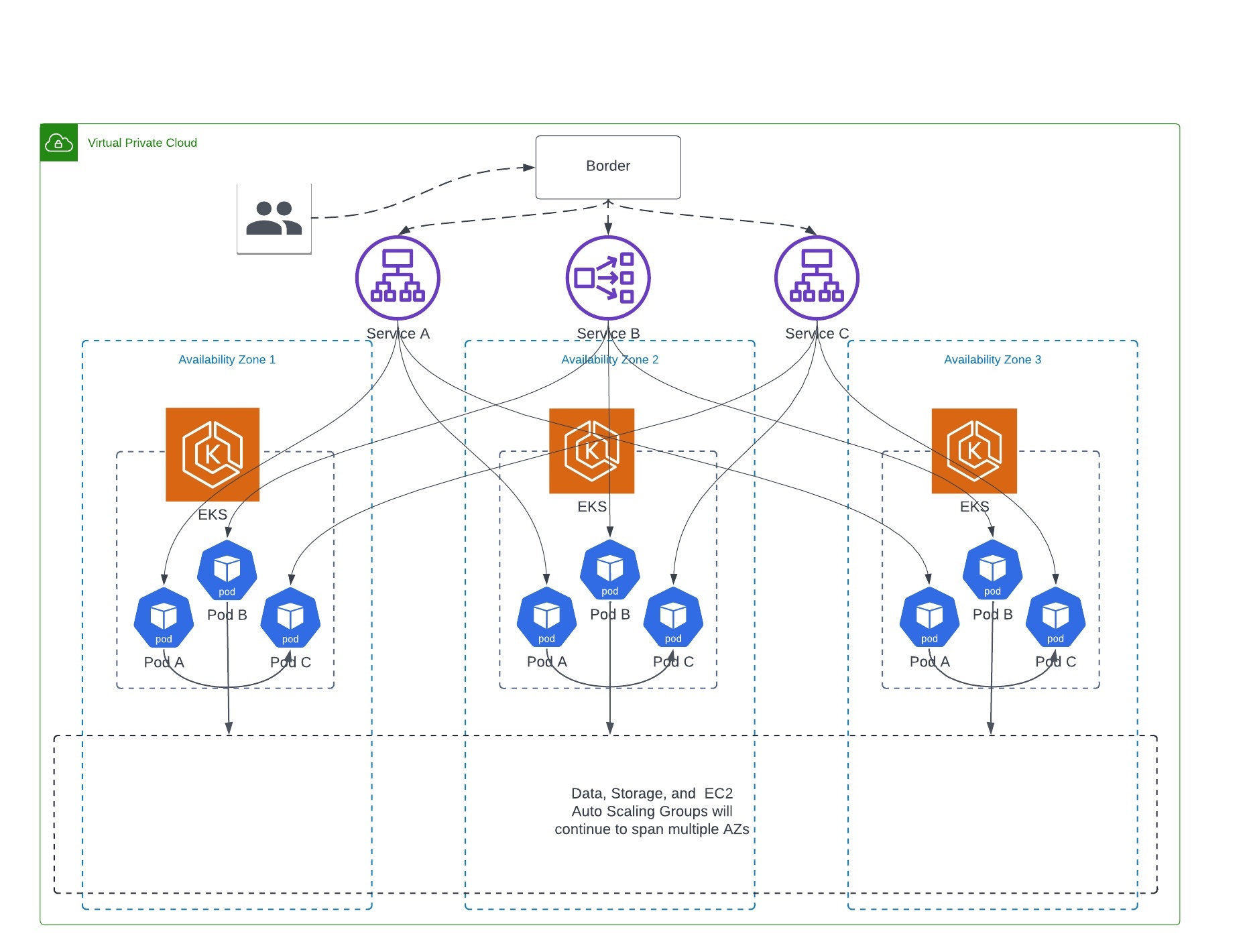
图 3:可用区边界的基于单元的多集群 Amazon EKS
如图 3 所示,完整的服务堆栈在每个单元中都可用,一旦请求被转发到一个单元,它就会保留在该单元中。这降低了我们在可用区间的数据传输成本,并为我们提供了可用区故障恢复能力,因为现在我们可以相对简单地禁用出现问题的单元的边境流量。在我们推出此功能时,我们最初将同时拥有基于单元的 Amazon EKS 集群和我们的传统多可用区 EKS 集群,如图 2 所示。

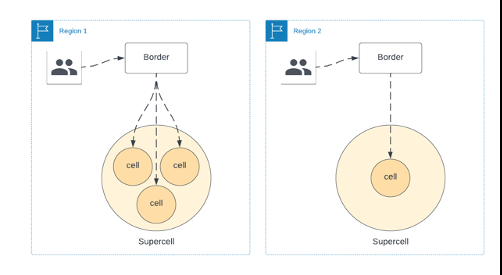
图 4:超级电池架构
将来,通过我们的 超级单体 架构,我们可以在单个区域 内拥有多个 超级单元 ,如图 4 所示。这使我们能够在蜂窝因维护而停机或新功能推出缓慢时路由流量。随着向多区域部署的过渡,我们将继续采用这种模式。
对于 Kubernetes 集群级别的自动扩展要求,我们使用的是集群自动扩缩器;但是,当我们使用多个 Amazon EC2 实例类型和大小时,我们遇到了限制。
使用 Karpenter 改善了亚马逊 EKS 的扩展
对于我们的 Amazon EKS 工作负载,我们将继续使用
Karpenter 能够高效地处理 亚马逊云科技 提供的各种实例类型和容量。使用 Karpenter,你可以定义预配器,以 CRD(自定义资源定义)的形式提供给 Kubernetes。这些 CRD 是可变的,这为我们的运营团队在需要修改我们的实例类型、大小等时提供了更好的用户体验。它还通过在最高效的 Amazon EC2 实例类型上装箱待处理的 Pod 来提高我们的节点利用率,从而显著优化成本。
亚马逊 EKS 中的工作负载管理
在项目的设计阶段,我们发现需要改进在 Amazon EKS 中管理应用程序的方式。一段时间以来,我们一直在使用 yaml 清单的组合来定义 Kubernetes 资源,并依靠 Terraform 和 Jenkins 自定义管道的组合来管理 Amazon EKS 集群中的资源部署。使用Terraform进行工作负载管理侧重于 核心基础设施附加组件,例如用于日志和指标聚合的可观察性应用程序、用于管理负载均衡器和Rout e53条目等亚马逊云科技资源的控制器,以及由大部分Life360服务共享的其他中间件类型的工作负载。使用带有原始 yaml 的 Jenkins 管道主要用于 Life360 开发的服务。虽然这两个解决方案都很实用,但无法通过基于单元的设计进行扩展,因此我们决定整合到一个单一的解决方案上,使我们能够管理 核心基础架构 插件和Life360开发的工作负载。
我们选择 ArgoCD 来帮助管理我们在亚马逊 EKS 中的工作负载。我们希望我们的工程师有一个易于使用的界面来管理他们在多个集群上的工作负载。随着我们从在单个 Amazon EKS 集群中运行的工作负载转移到在多个 Amazon EKS 集群中运行的工作负载,每个集群都隔离在一个可用区内,这一点变得越来越重要。
我们的 ArgoCD git 存储库已经进行了几次迭代,但我们已经确定了一个现在对我们非常有效的解决方案。我们当前的解决方案大量使用了 ArgoCD ApplicationSet CRD
我们在上面定义了由 ApplicationSet 图表模板使用的默认对象。这里的一些值是作为 helm 全局值传入的。例如,如果需要,这允许我们在自定义应用程序图表模板的窗格注释中使用值 Global.clusterName。接下来,我们有了集群细胞。我们在图表模板中对这个对象进行迭代,以创建支持
其他字段用于定义由 ApplicationSet 模板生成的应用程序配置。该字段名称与 Clustercell.Cluster 结合使用,为 ArgoCD 应用程序生成一个唯一的名称。在此示例中,ArgoCD 总共将有三个由 ApplicationSet 生成的应用程序(即 env-use1-az2-custom-app、env-use1-az4-custom-app 和 env-use1-az6-custom-app)。ArgoCD 应用程序使用字段 repourl 和 path 来定义其管理的头盔图表的源存储库和相对路径。
结论
在这篇文章中,我们向您展示了如何通过实施多集群 Amazon EKS 架构来提高灵活性。我们的新方法采用了隔板结构,使用电池来确保一个电池的故障不会影响其他单元。这种方法使 Life360 能够降低可用区间的数据传输成本,改进 EKS 扩展和工作负载管理,并为整个可用区的故障创建静态稳定的基础架构。凭借超级电池架构,Life360 提供了不间断的服务,并继续简化全球家庭的安全。

杰西·冈萨雷斯,《人生 360》
杰西·冈萨雷斯(l

Naveen Puvvula,Life 360
纳文(l
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。