我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 SageMaker 终端节点和 AWS Lambda 扩展 YOLOv5 推理
在数据科学家仔细想出令人满意的机器学习 (ML) 模型之后,必须部署该模型,以方便组织的其他成员进行推断。但是,在优化成本和计算效率的情况下大规模部署模型可能是一项艰巨而繁琐的任务。 Amazon SageMaker 终端节点为模型部署提供了一种易于扩展且成本优化的解决方案。根据GPLv3许可分发的YOLOv5模型是一种流行的物体检测模型,以其运行效率和检测精度而闻名。在这篇文章中,我们演示了如何在 SageMaker 终端节点上托管预先训练的 YOLOv5 模型,以及如何使用 AWS Lambda 函数调用这些终端节 点。
解决方案概述
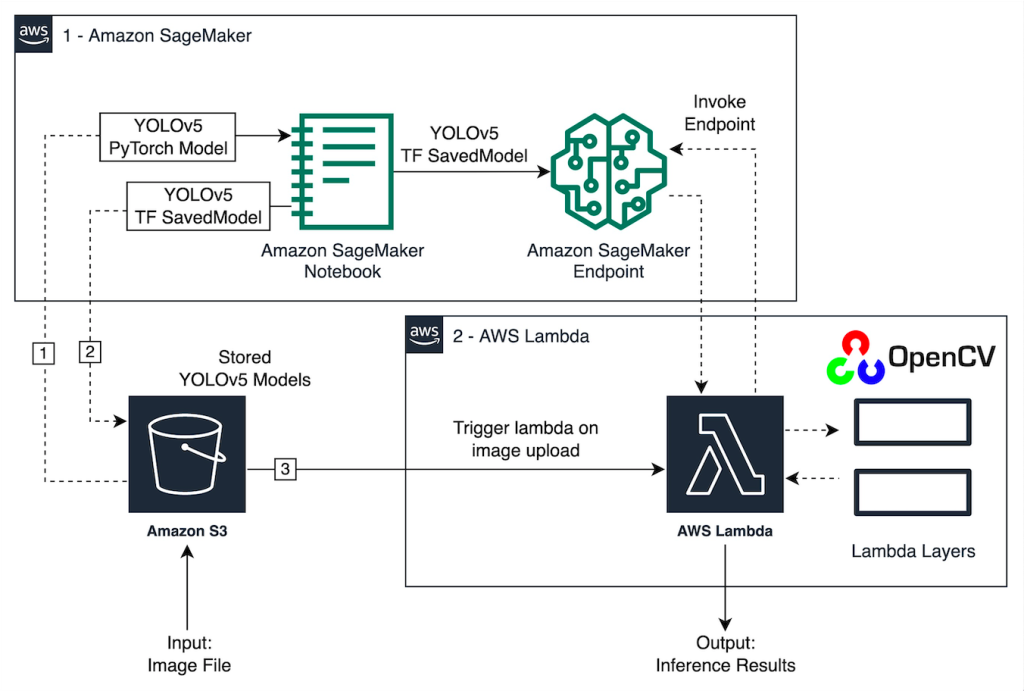
下图概述了用于使用 SageMaker 终端节点托管 YOLOv5 模型以及使用 Lambda 调用终端节点的 AWS 服务。SageMaker 笔记本从 Amazon Simple Storage Service
(
Amazon S3) 存储桶访问 YOLOv5 PyTorch 模型,将其转换为 YOLOv5 TensorF
SavedModel
low 格式,然后将其存储回 S3 存储桶。然后在托管端点时使用此模型。当图像上传到 Amazon S3 时,它会充当运行 Lambda 函数的触发器。该函数利用 OpenCV
Lambda 层读
取上传的图像并使用终端节点运行推理。运行推理后,您可以根据需要使用从中获得的结果。
在这篇文章中,我们将介绍在PyTorch中使用YoloV5默认模型并将其转换为TensorFlow的过程。
SavedModel
该模型使用 SageMaker 端点托管。然后,我们创建并发布一个 Lambda 函数,该函数调用终端节点来运行推理。预训练的 YOLOv5 模型可在 GitHub 上找到。
出于本文的目的,我们使用了
yolov5l模型
。
先决条件
作为先决条件,我们需要设置以下 AWS 身份和访问管理 (IAM) 角色,为 SageMaker、Lambda 和 Amazon S3 设置适当的 访问策略 :
-
SageMaker IAM 角色
— 这需要附加
AmazonS3FullAccess策略来在 S3 存储桶中存储和访问模型 -
Lambda IAM 角色
— 此角色需要多个策略:
-
要访问存储在 Amazon S3 中的图像,我们需要以下 IAM 策略:
-
s3:GetObject -
s3:ListBucket
-
-
要运行 SageMaker 终端节点,我们需要访问以下 IAM 策略:
-
sagemaker:ListEndpoints -
sagemaker:DescribeEndpoint -
sagemaker:InvokeEndpoint -
sagemaker:InvokeEndpointAsync
-
-
要访问存储在 Amazon S3 中的图像,我们需要以下 IAM 策略:
您还需要以下资源和服务:
- AWS 命令行接口 (AWS CLI),我们使用它来创建和配置 Lambda。
-
一个 SageMaker 笔记本实例。它们预装了 Docker,我们用它来创建 Lambda 层。要设置笔记本实例,请完成以下步骤:
- 在 SageMaker 控制台上,创建一个笔记本实例并提供笔记本名称、实例类型(在本文中,我们使用 ml.c5.large)、IAM 角色和其他参数。
- 克隆 公共存储库 并添加 Ultralytics 提供的 YOLOv5 存储库。
在 SageMaker 端点上托管 YOLOv5
在我们在 SageMaker 上托管预训练的 YOLOv5 模型之前,我们必须将其导出并打包到正确的目录结构中。
model.tar.gz
在这篇文章中,我们将演示如何以这种格式托管 YOLOv5。
saved_model
YoloV5 存储库提供了一个可以以多种不同方式导出模型的
export.py
文件。克隆 YOLOv5 并从命令行进入 YOLOv5 目录后,可以使用以下命令导出模型:
$ cd yolov5
$ pip install -r requirements.txt tensorflow-cpu
$ python export.py --weights yolov5l.pt --include saved_model --nms
此命令在目录
yolov5l_saved_model
内创建一个名为的新
yolov5
目录。在
yolov5l_saved_model
目录中,我们应该看到以下项目:
要创建
model.tar.gz
文件,请将的内容移
yolov5l_saved_model
至
export/Servo/1
。在命令行中,我们可以通过运行以下命令来压缩
export
目录并将模型上传到 S3 存储桶:
$ mkdir export && mkdir export/Servo
$ mv yolov5l_saved_model export/Servo/1
$ tar -czvf model.tar.gz export/
$ aws s3 cp model.tar.gz "<s3://BUCKET/PATH/model.tar.gz>"然后,我们可以通过运行以下代码从 SageMaker 笔记本中部署 SageMaker 端点:
import os
import tensorflow as tf
from tensorflow.keras import backend
from sagemaker.tensorflow import TensorFlowModel
model_data = '<s3://BUCKET/PATH/model.tar.gz>'
role = '<IAM ROLE>'
model = TensorFlowModel(model_data=model_data,
framework_version='2.8', role=role)
INSTANCE_TYPE = 'ml.m5.xlarge'
ENDPOINT_NAME = 'yolov5l-demo'
predictor = model.deploy(initial_instance_count=1,
instance_type=INSTANCE_TYPE,
endpoint_name=ENDPOINT_NAME)前面的脚本大约需要 2-3 分钟才能将模型完全部署到 SageMaker 端点。您可以在 SageMaker 控制台上监控部署状态。成功托管模型后,模型就可以进行推理了。
测试 SageMaker 端点
模型成功托管在 SageMaker 端点上后,我们可以对其进行测试,使用空白图像进行测试。测试代码如下:
import numpy as np
ENDPOINT_NAME = 'yolov5l-demo'
modelHeight, modelWidth = 640, 640
blank_image = np.zeros((modelHeight,modelWidth,3), np.uint8)
data = np.array(blank_image.astype(np.float32)/255.)
payload = json.dumps([data.tolist()])
response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME,
ContentType='application/json',
Body=payload)
result = json.loads(response['Body'].read().decode())
print('Results: ', result)使用层和触发器设置 Lambda
我们使用 OpenCV 通过传递图像并获得推理结果来演示模型。Lambda 没有预先构建的 OpenCV 等外部库,因此我们需要先构建它,然后才能调用 Lambda 代码。此外,我们希望确保每次调用 Lambda 时都不会构建像 OpenCV 这样的外部库。为此,Lambda 提供了创建 Lambda 层的功能。我们可以定义这些层中的内容,并且每次调用 Lambda 代码时都可以使用它们。我们还演示了如何为 OpenCV 创建 Lambda 层。在这篇文章中,我们使用 亚马逊弹性计算云 (Amazon EC2) 实例来创建图层。
在我们准备好各层之后,我们创建
app.py
脚本,即使用各层、运行推理并获得结果的 Lambda 代码。下图说明了此工作流程。

使用 Docker 为 OpenCV 创建 Lambda 层
按如下方式使用 Dockerfile 使用 Python 3.7 创建 Docker 镜像:
FROM amazonlinux
RUN yum update -y
RUN yum install gcc openssl-devel bzip2-devel libffi-devel wget tar gzip zip make -y
# Install Python 3.7
WORKDIR /
RUN wget https://www.python.org/ftp/python/3.7.12/Python-3.7.12.tgz
RUN tar -xzvf Python-3.7.12.tgz
WORKDIR /Python-3.7.12
RUN ./configure --enable-optimizations
RUN make altinstall
# Install Python packages
RUN mkdir /packages
RUN echo "opencv-python" >> /packages/requirements.txt
RUN mkdir -p /packages/opencv-python-3.7/python/lib/python3.7/site-packages
RUN pip3.7 install -r /packages/requirements.txt -t /packages/opencv-python-3.7/python/lib/python3.7/site-packages
# Create zip files for Lambda Layer deployment
WORKDIR /packages/opencv-python-3.7/
RUN zip -r9 /packages/cv2-python37.zip .
WORKDIR /packages/
RUN rm -rf /packages/opencv-python-3.7/
编译并运行 Docker,并将输出 ZIP 文件存储在当前目录下
layers
:
$ docker build --tag aws-lambda-layers:latest <PATH/TO/Dockerfile>
$ docker run -rm -it -v $(pwd):/layers aws-lambda-layers cp /packages/cv2-python37.zip /layers现在我们可以将 OpenCV 层构件上传到 Amazon S3 并创建 Lambda 层:
$ aws s3 cp layers/cv2-python37.zip s3://<BUCKET>/<PATH/TO/STORE/ARTIFACTS>
$ aws lambda publish-layer-version --layer-name cv2 --description "Open CV" --content S3Bucket=<BUCKET>,S3Key=<PATH/TO/STORE/ARTIFACTS>/cv2-python37.zip --compatible-runtimes python3.7成功运行上述命令后,您在 Lambda 中有一个 OpenCV 层,您可以在 Lambda 控制台上查看该层。

创建 Lambda 函数
我们利用
app.py
脚本创建 Lambda 函数并使用 OpenCV。在以下代码中,将
BUCKET_NAME
和
IMAGE_LOCATION
的值更改为访问图像的位置:
import os, logging, json, time, urllib.parse
import boto3, botocore
import numpy as np, cv2
logger = logging.getLogger()
logger.setLevel(logging.INFO)
client = boto3.client('lambda')
# S3 BUCKETS DETAILS
s3 = boto3.resource('s3')
BUCKET_NAME = "<NAME OF S3 BUCKET FOR INPUT IMAGE>"
IMAGE_LOCATION = "<S3 PATH TO IMAGE>/image.png"
# INFERENCE ENDPOINT DETAILS
ENDPOINT_NAME = 'yolov5l-demo'
config = botocore.config.Config(read_timeout=80)
runtime = boto3.client('runtime.sagemaker', config=config)
modelHeight, modelWidth = 640, 640
# RUNNING LAMBDA
def lambda_handler(event, context):
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
# INPUTS - Download Image file from S3 to Lambda /tmp/
input_imagename = key.split('/')[-1]
logger.info(f'Input Imagename: {input_imagename}')
s3.Bucket(BUCKET_NAME).download_file(IMAGE_LOCATION + '/' + input_imagename, '/tmp/' + input_imagename)
# INFERENCE - Invoke the SageMaker Inference Endpoint
logger.info(f'Starting Inference ... ')
orig_image = cv2.imread('/tmp/' + input_imagename)
if orig_image is not None:
start_time_iter = time.time()
# pre-processing input image
image = cv2.resize(orig_image.copy(), (modelWidth, modelHeight), interpolation = cv2.INTER_AREA)
data = np.array(image.astype(np.float32)/255.)
payload = json.dumps([data.tolist()])
# run inference
response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME, ContentType='application/json', Body=payload)
# get the output results
result = json.loads(response['Body'].read().decode())
end_time_iter = time.time()
# get the total time taken for inference
inference_time = round((end_time_iter - start_time_iter)*100)/100
logger.info(f'Inference Completed ... ')
# OUTPUTS - Using the output to utilize in other services downstream
return {
"statusCode": 200,
"body": json.dumps({
"message": "Inference Time:// " + str(inference_time) + " seconds.",
"results": result
}),
}使用以下代码部署 Lambda 函数:
$ zip app.zip app.py
$ aws s3 cp app.zip s3://<BUCKET>/<PATH/TO/STORE/FUNCTION>
$ aws lambda create-function --function-name yolov5-lambda --handler app.lambda_handler --region us-east-1 --runtime python3.7 --environment "Variables={BUCKET_NAME=$BUCKET_NAME,S3_KEY=$S3_KEY}" --code S3Bucket=<BUCKET>,S3Key="<PATH/TO/STORE/FUNCTION/app.zip>"将 OpenCV 层连接到 Lambda 函数
在我们准备好了 Lambda 函数和层之后,我们可以按如下方式将该层连接到该函数:
$ aws lambda update-function-configuration --function-name yolov5-lambda --layers cv2我们可以通过 Lambda 控制台查看图层设置。

将图像上传到 Amazon S3 时触发 Lambda
我们使用上传到 Amazon S3 的图像作为触发器来运行 Lambda 函数。有关说明,请参阅 教程:使用 Amazon S3 触发器调用 Lambda 函数 。
您应该在 Lambda 控制台上看到以下函数的详细信息。

运行推断
设置 Lambda 和 SageMaker 终端节点后,您可以通过调用 Lambda 函数来测试输出。我们使用上传到 Amazon S3 的图像作为触发器来调用 Lambda,Lambda 反过来调用终端节点进行推理。例如,我们将以下图像上传到上一节中
<S3 PATH TO IMAGE>/test_image.png
配置的 Amazon S3 位置。

上传图像后,将触发 Lambda 函数来下载和读取图像数据,并将其发送到 SageMaker 终端节点进行推断。SageMaker 端点的输出结果由该函数以 JSON 格式获取和返回,我们可以通过不同的方式使用该结果。下图显示了叠加在图像上的示例输出。

清理干净
根据实例类型的不同,SageMaker 笔记本电脑可能需要大量的计算使用量和成本。为避免不必要的成本,我们建议在不使用笔记本电脑实例时将其停止。此外,Lambda 函数仅在调用时才会产生费用。因此,无需为此进行清理。但是,SageMaker终端节点在 “服务中” 时会产生费用,应将其删除以避免额外费用。
结论
在这篇文章中,我们演示了如何在 SageMaker 终端节点上托管预先训练的 YOLOv5 模型,以及如何使用 Lambda 调用推理和处理输出。详细代码可在 GitHub上找到 。
要了解有关 SageMaker 终端节点的更多信息,请查看 创建您的终端节点并部署您的模型, 以及 构建、测试您的亚马逊 SageMaker 推理模型并将其部署到 AWS Lambda ,其中重点介绍了如何自动化部署 YOLOv5 模型的过程。