我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
直接从亚马逊 SageMaker Pipelines 中启动亚马逊 SageMaker Autopilot 实验,轻松实现 mLOP 工作流程的自动化
在这篇文章中,我们将介绍如何使用流水线中新推出的AutoML步骤创建端到端的机器学习工作流程来训练和评估SageMaker生成的机器学习模型,并将其注册到SageMaker模型注册表中。性能最佳的机器学习模型可以部署到 SageMaker 端点。
数据集概述
我们使用公开的
该数据集包含 32,561 行用于训练和验证,16,281 行用于测试,每行 15 列。这包括有关个人和
阶级
的人口统计信息 ,以此作为指示收入阶层的目标列。
| Column Name | Description |
| age | Continuous |
| workclass | Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked |
| fnlwgt | Continuous |
| education | Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool |
| education-num | Continuous |
| marital-status | Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse |
| occupation | Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces |
| relationship | Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried |
| race | White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other, Black |
| sex | Female, Male |
| capital-gain | Continuous |
| capital-loss | Continuous |
| hours-per-week | Continuous |
| native-country | United-States, Cambodia, England, Puerto-Rico, Canada, Germany, Outlying-US(Guam-USVI-etc), India, Japan, Greece, South, China, Cuba, Iran, Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal, Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia, Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador, Trinadad&Tobago, Peru, Hong, Holand-Netherlands |
| class | Income class, either <=50K or >50K |
解决方案概述
我们使用流水线来协调训练自动驾驶
此端到端自动驾驶训练过程需要执行以下步骤:
-
使用 AutomlStep 创建和监控自动驾驶训练作业。 -
使用 ModelStep 创建 SageMaker 模型。此步骤获取最佳模型的元数据和上一步中由自动驾驶仪渲染的伪像。 -
使用 TransformStep 在测试数据集上评估经过训练的自动驾驶仪模型。 -
使用 P
rocessingStep 将之前运行的 Transfor mStep的输出与实际目标标签进行比较。 -
如果先前获得的评估指标超过 ConditionStep 中的预定义阈值 ,则 使用ModelStep 将机器学习模型注册到 SageMaker 模型注册表。 - 将机器学习模型作为 SageMaker 端点进行部署以用于测试目的。
架构
下面的架构图说明了将所有步骤打包成可重现、自动化和可扩展的 SageMaker Autopilot 训练管道所需的不同工作流步骤。从 S3 存储桶读取数据文件,并按顺序调用管道步骤。
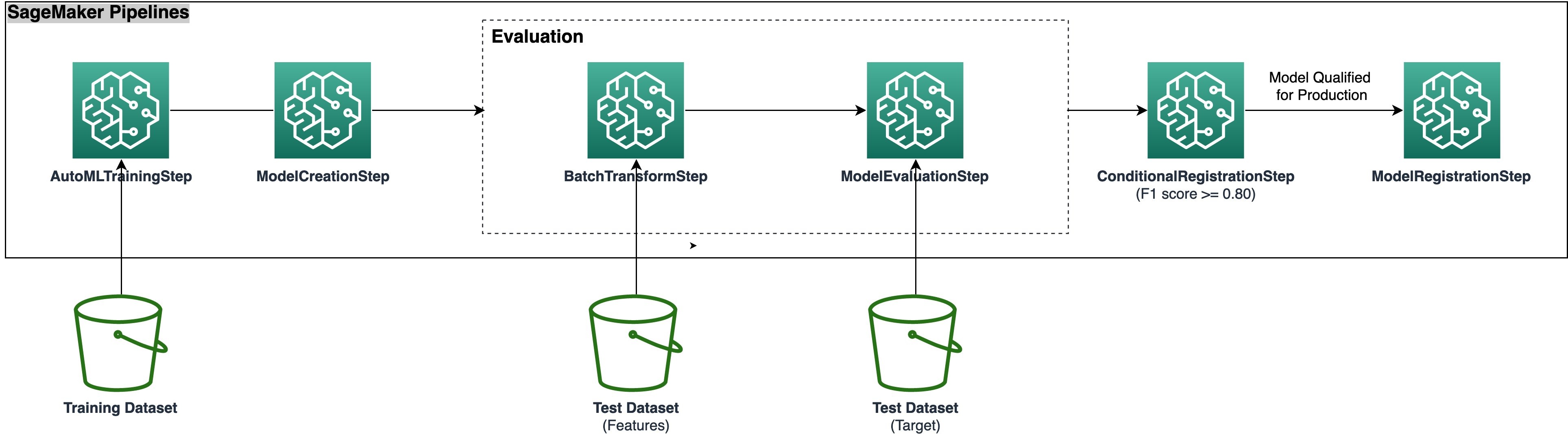
草率排练
这篇文章详细解释了管道步骤。我们将审查代码并讨论每个步骤的组成部分。要部署解决方案,请参阅
先决条件
完成以下先决条件:
-
设置一个
亚马逊云科技 账户 。 -
创建
亚马逊 Sage Maker Stu dio 环境。 -
创建 A
WS 身份和访问管理 (IAM) 角色。有关说明,请参阅创建向 IAM 用户委派权限的角色 。具体而言,您需要创建一个SageMaker 执行角色 。 你可以将AmazonsagemakerFullAcces s 托管 IAM 政策附加到其中,用于演示。但是,为了提高安全性,应进一步缩小范围。 -
导航到 Studio 并从
GitHub 上的 笔记本示例目录 中上传文件 。 -
打开 SageMaker 笔记本电脑
sagemaker_autopilot_pipelines_native_auto_ml_step.ipynb 然后按顺序运行单元格。按照有关如何初始化笔记本并获取示例数据集的说明进行操作。
当数据集准备就绪可供使用时,我们需要设置流水线以建立可重复的流程,使用自动驾驶仪自动构建和训练机器学习模型。我们使用
管道步骤
在以下部分中,我们将介绍 SageMaker 管道中的不同步骤,包括 AutoML 训练、模型创建、批量推断、评估和最佳模型的条件注册。下图说明了整个管道流程。
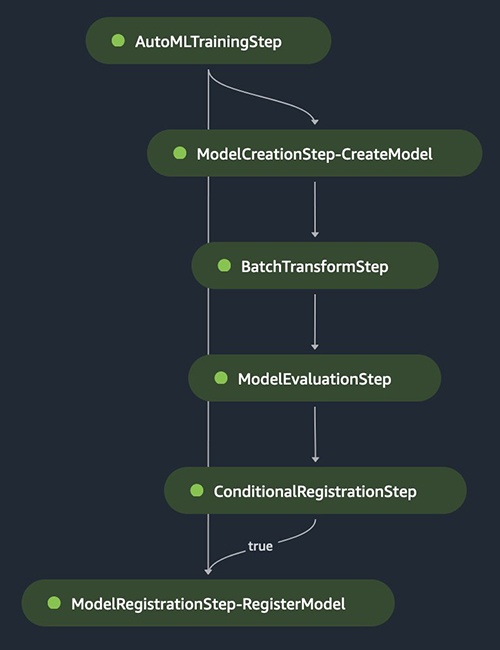
AutoML 训练步骤
utoMLStep
类将其添加到 SageMaker 管道中,如以下代码所示。需要指定组合训练模式,但可以根据需要调整其他参数。例如,与其让 AutoML 作业自动推断机器学习
ML 对象的问题类型
和目标指标对它们进行硬编码
。
模型创建步骤
AutoML 步骤负责生成各种 ML 候选模型,将它们组合起来,并获得最佳的 ML 模型。模型工件和元数据会自动存储,可以通过在 AutoML 训练步骤中调用
get_best_auto_ml_mol_model ()
方法来获取。 然后,它们可用于创建 SageMaker 模型,这是 “模型” 步骤的一部分:
批量转换和评估步骤
我们使用 Tr
有条件的注册步骤
在此步骤中,如果新的 Autopilot 模型超过预定义的评估指标阈值,我们会将其注册到 SageMaker 模型注册表中。
创建并运行管道
定义步骤后,我们将它们合并为一个 SageMaker 管道:
这些步骤按顺序运行。该管道使用自动驾驶仪和流水线运行 AutoML 作业的所有步骤,以进行训练、模型评估和模型注册。
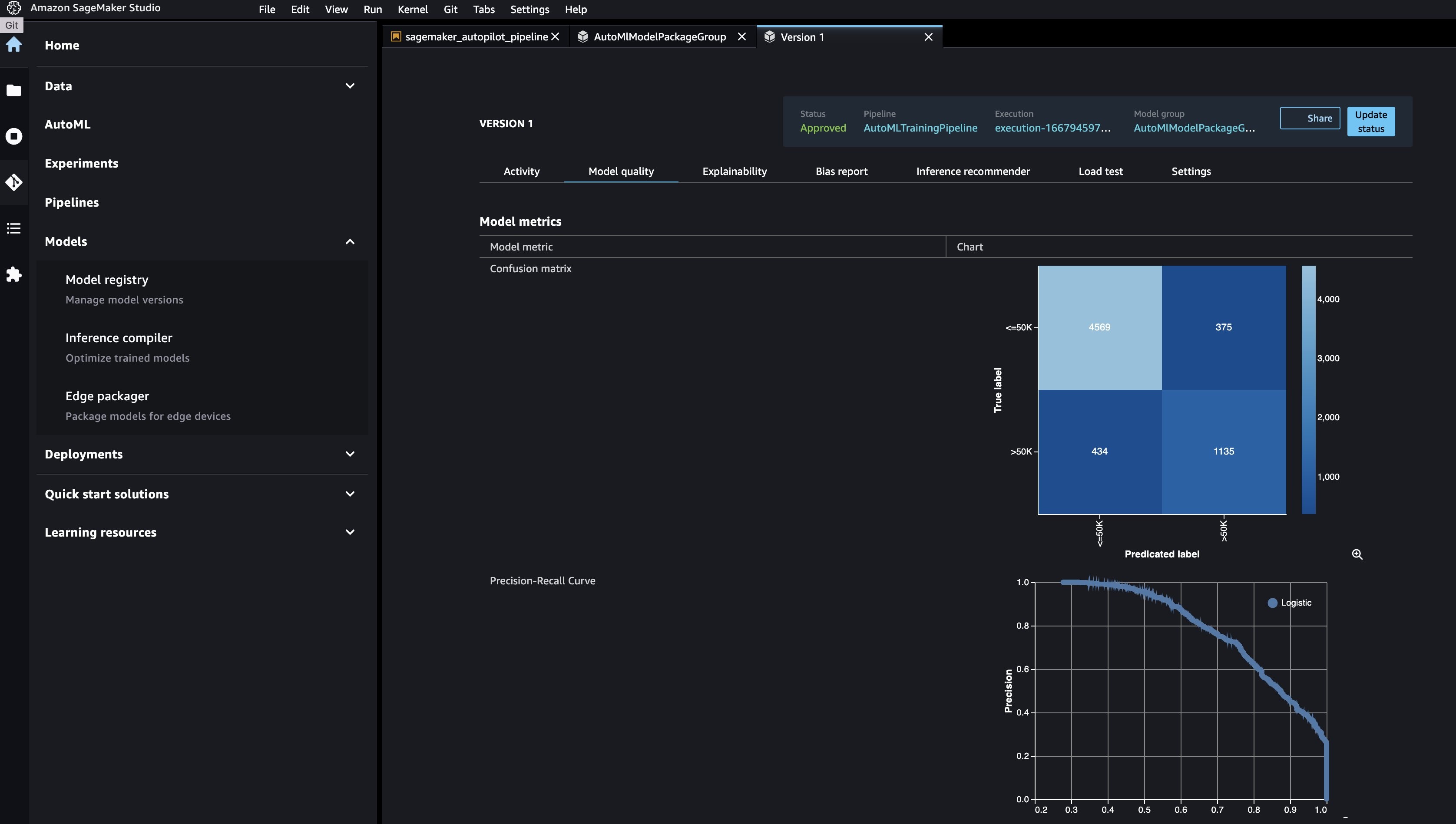
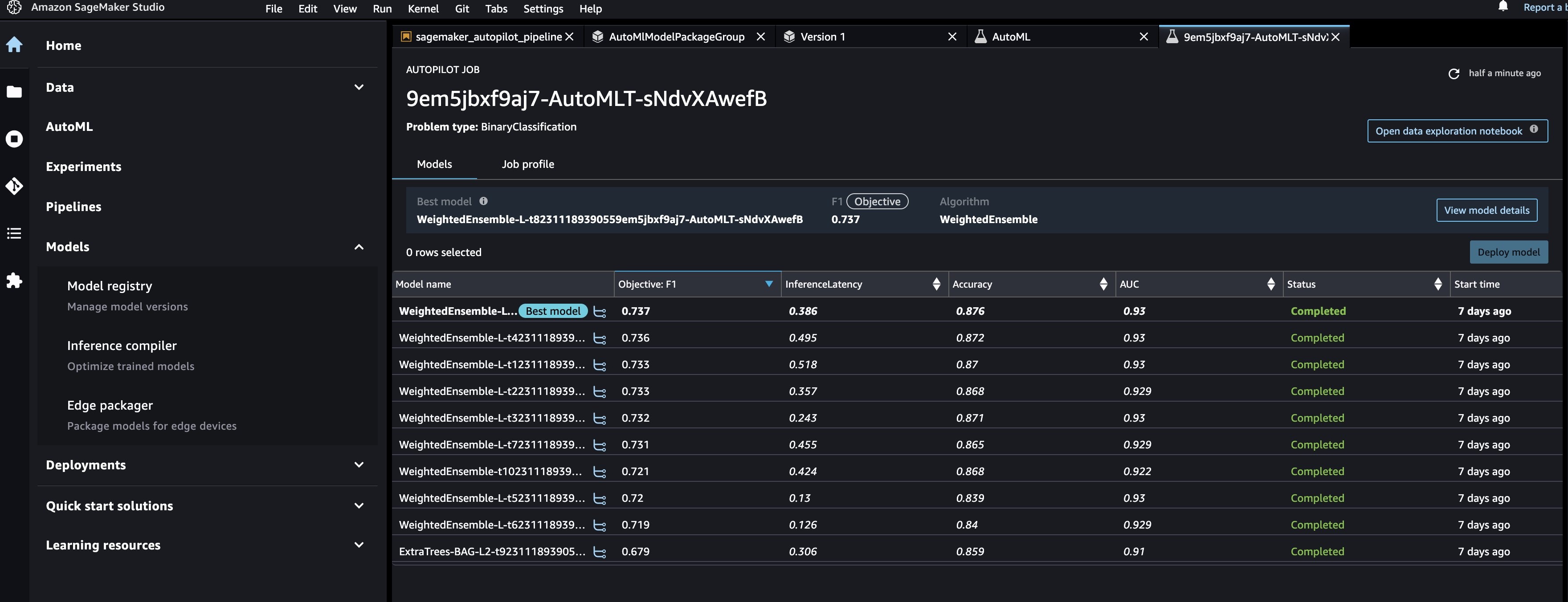
你可以通过导航到 Studio 控制台上的模型注册表并打开 A
utoml
ModelPackageGroup 来查看新模型。选择任意版本的训练作业以在
模型质量
选项卡上查看目标指标。
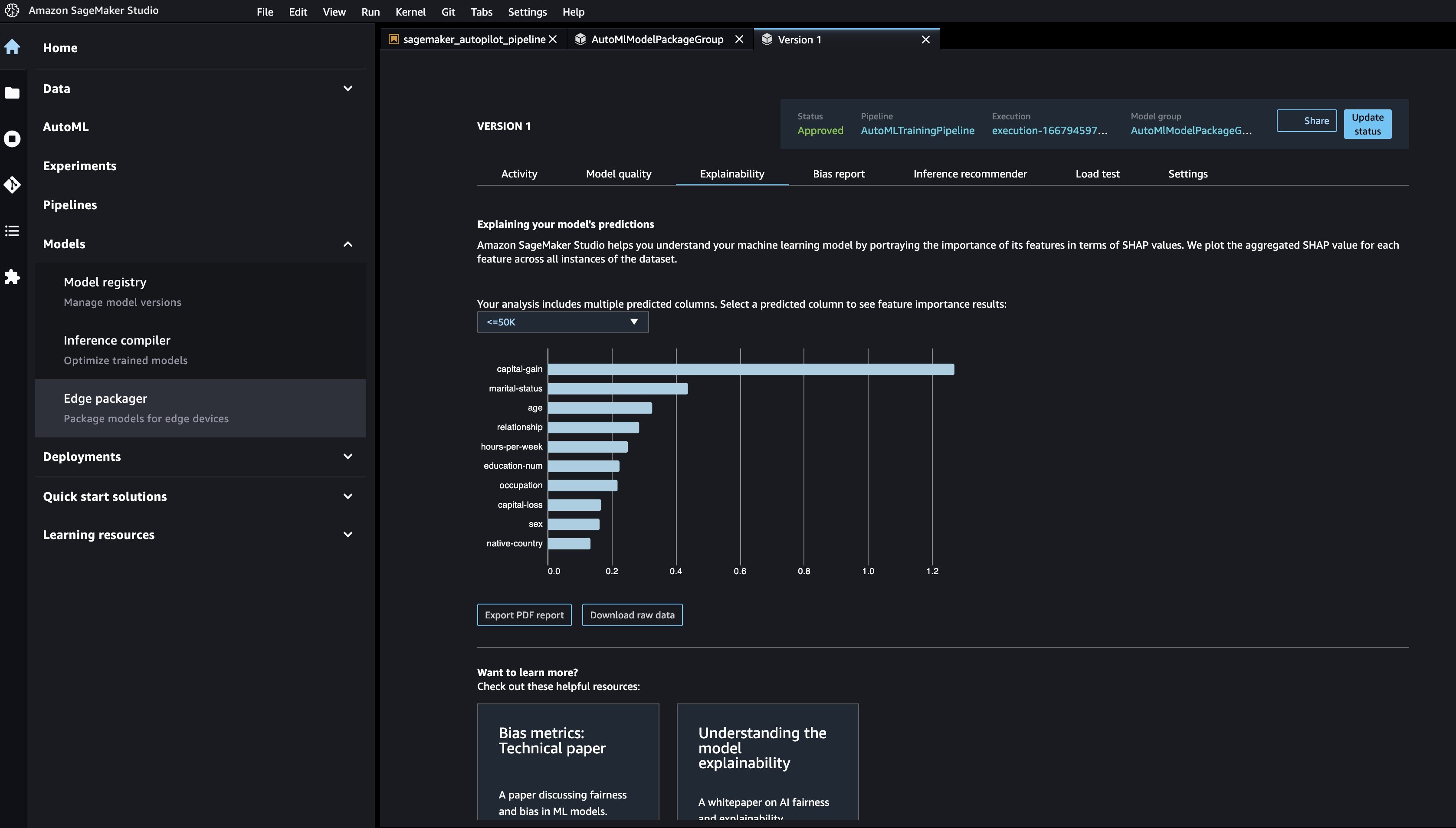
您可以在 “可解释性 ” 选项卡上查看可 解释性 报告,以了解模型的预测。
要查看在 AutoM
LStep 中创建的所有模型的基础自动
驾驶实验 ,请导航到 A
utoML
页面并选择作业名称。
部署模型
在我们手动查看机器学习模型的性能之后,我们可以将新创建的模型部署到 SageMaker 端点。为此,我们可以使用保存在SageMaker模型注册表中的模型配置运行笔记本中创建模型端点的单元。
请注意,共享此脚本是出于演示目的,但建议遵循更强大的 CI/CD 管道进行机器学习推理的生产部署。有关更多信息,请参阅
摘要
这篇文章介绍了一种易于使用的机器学习流水线方法,该方法使用自动驾驶仪、流水线和 Studio 自动训练表格机器学习模型 (AutoML)。AutoML 提高了机器学习从业者的效率,无需大量的机器学习专业知识即可加快从机器学习实验到生产的路径。我们概述了创建、评估和注册机器学习模型所需的相应管道步骤。首先尝试使用
特别感谢所有为发布会做出贡献的人 :岳胜华、何健、郭奥、涂新路、秦天、胡燕达、陆占奎和齐德文。
作者简介




*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。