我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
推出适用于 Apache Spark 的云随机存储插件
Apache Spark 利用内存缓存和优化的查询执行来对您的数据集进行快速分析查询,这些数据集在不同的节点上分成多个 Spark 分区,因此您可以并行处理大量数据。在 Apache Spark 中,当需要在集群中重新分配数据时, 就会发生
器上剩余的磁盘空间不足且无法恢复时,Spark 经常会抛出 “设备上 没有
剩余空间” 或
MetadataFetchFailedException
错误。如果不增加额外的计算和附加存储,这样的 Spark 任务通常无法成功,在这种情况下,计算通常处于空闲状态,从而产生额外的成本。
2021 年,我们推出了 搭载 Spark 2.4 的
今天,我们很高兴发布适用于
我们还很高兴地宣布,在Apache 2.0许可下发布适用于Apache Spark的Cloud Shuffle存储插件的软件二进制文件。你可以
了解 Apache Spark 中的洗牌操作
在 Apache Spark 中,有两种类型的转换:
-
狭义转换
-这包括
地图、过滤器、联合和MapPartition ,其中每个输入分区仅贡献一个输出分区。 -
广泛转换
— 这包括
联接、GroupByKey、reduceByKey和重新分区 ,其中每个输入分区都构成许多输出分区。 包括联接、排序依据、分组依据在内的Spark SQL 查询 需要进行广泛的转换。
宽转换会触发洗牌,每当将数据重组为新分区并将每个密钥分配给其中一个分区时,就会发生洗牌。在洗牌阶段,所有 Spark 地图任务都会将洗牌数据写入本地磁盘,然后通过网络传输并由 Spark reduce 任务获取。在 Spark 用户界面中可以看到洗牌后的数据量。当 shuffle 写入占用的空间大于本地可用磁盘容量时,会导致 “
设备上 没有剩余空间
” 错误。
为了说明其中一个典型场景,让我们使用标准 TPC-DS 3 TB 数据集中的查询 q80.sql 作为示例。此查询尝试计算在特定时间段内实现的总销售额、回报和最终利润。
它涉及由
左外连接
和分组依据引起的多个宽变换(洗牌) 。
让我们在包含 10 个 G1.X 工作人员的 亚马逊云科技 Glue 3.0 任务上运行以下查询,其中总共有 640 GB 的可用本地磁盘空间:
以下屏幕截图显示了 Spark 用户界面 中的 “
执行器” 选项卡
。

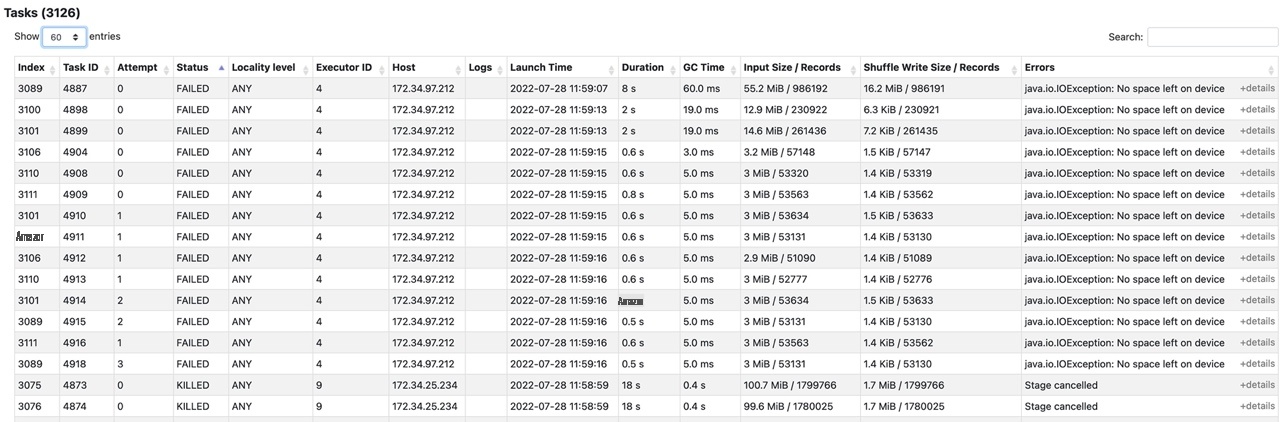
以下屏幕截图显示了 亚马逊云科技 Glue 任务运行中包含的 Spark 任务的状态。
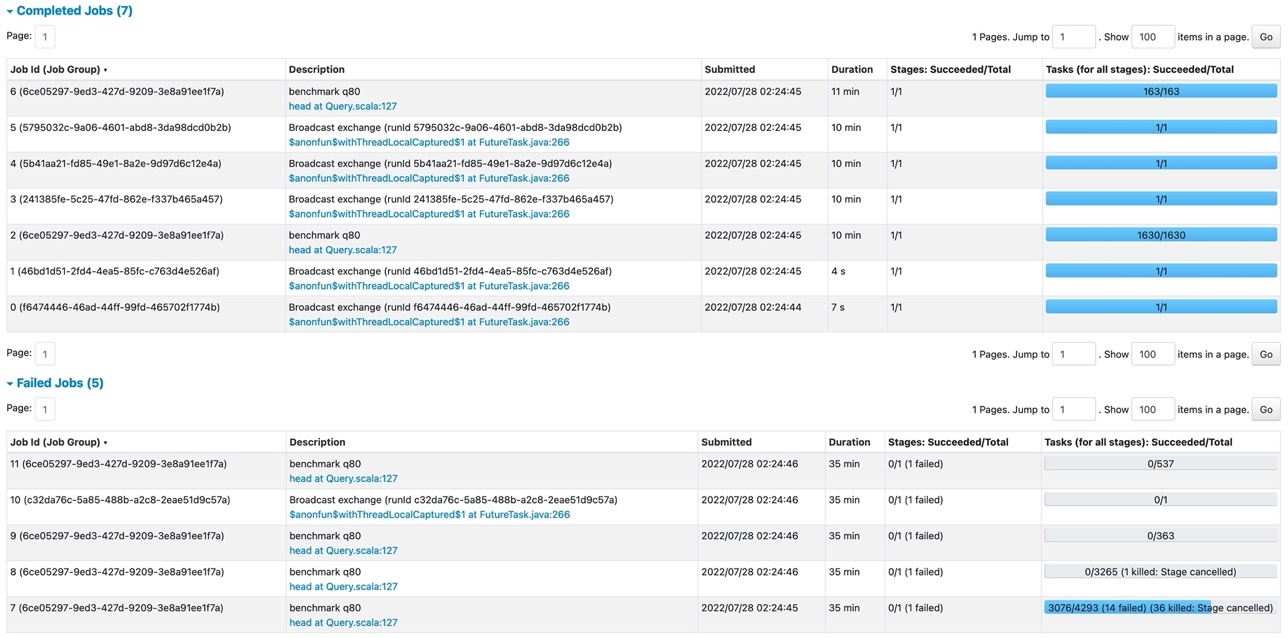
在失败的 Spark 作业(作业 ID=7)中,我们可以在 Spark 用户界面中看到失败的 Spark 阶段。

该阶段有 167.8Gib 随机写入,由于错误
java.io.ioException,有 14 个任务失败:由于主机 172.34.97.212 的本地空间用完,设备上没有剩余空间
磁盘。
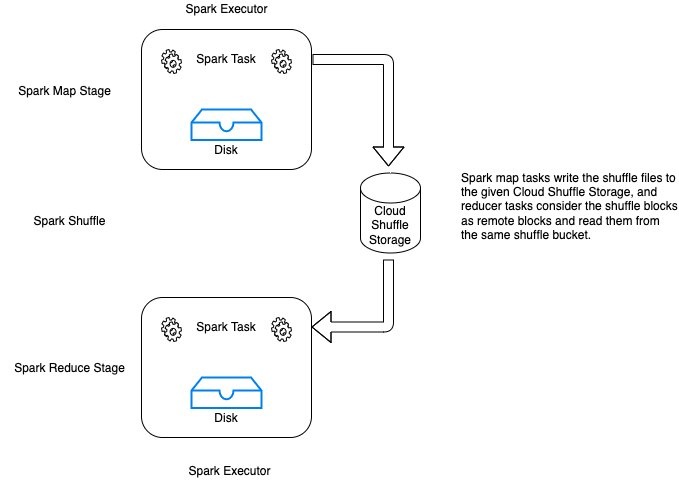
适用于 Apache Spark 的云端随机存储
适用于 Apache Spark 的 Cloud Shuffle Storage 允许您在亚马逊 S3 或其他云存储服务上存储 Spark 随机播放文件。这为 Spark 作业提供了完全的弹性,从而使您能够可靠地运行数据密集度最高的工作负载。下图说明了 Spark 地图任务如何将随机播放文件写入云随机存储。Reducer 任务将洗牌块视为远程块,并从同一个洗牌存储空间中读取它们。
此架构使您的无服务器 Spark 任务能够使用 Amazon S3,而无需运行、操作和维护额外的存储或计算节点的开销。
以下 Glue 作业参数允许和调整 Spark 以使用 S3 存储桶存储随机播放数据。在向 Amazon S3 写入 shuffle 数据时,您还可以使用
| Key | Value | Explanation |
|---|---|---|
--write-shuffle-files-to-s3
|
TRUE
|
This is the main flag, which tells Spark to use S3 buckets for writing and reading shuffle data. |
--conf
|
spark.shuffle.storage.path=s3://<shuffle-bucket>
|
This is optional, and specifies the S3 bucket where the plugin writes the shuffle files. By default, we use –TempDir/shuffle-data. |
shuffle 文件被写入该位置并创建如下文件:
s3:////[0-9]//shuffle_ _ _0.data
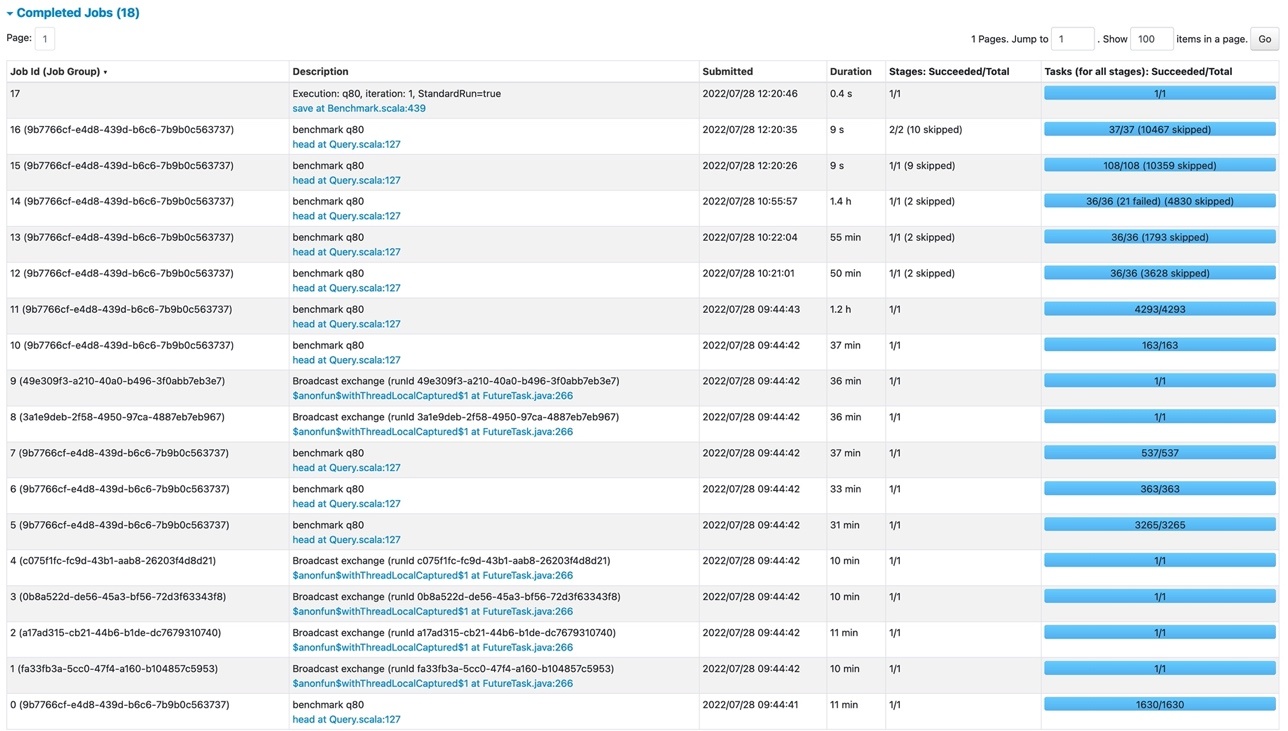
启用 Cloud Shuffle Storage 插件并使用相同的 亚马逊云科技 Glue 任务设置后,TPC-DS 查询现在可以成功完成,没有任何任务或阶段失败。
Cloud Shuffle 存储插件的软件二进制文件
现在,您还可以在自己的Spark环境和其他云存储服务中下载和使用该插件。插件二进制文件可在 Apache 2.0 许可下使用。
将插件与您的 Spark 应用程序捆绑在一起
在开发 Spark 应用程序时,您可以将插件与 Spark 应用程序捆绑在一起,方法是将其作为依赖项添加到 Maven pom.xml 中,如以下代码所示。有关插件和 Spark 版本的更多详细信息,请参阅
或者,您可以直接从 亚马逊云科技 Glue Maven 工件中下载二进制文件,并将它们包含在您的 Spark 应用程序中,如下所示:
通过在类路径中添加 JAR 文件并为插件指定两个 Spark 配置来提交 Spark 应用程序:
以下 Spark 参数允许和配置 Spark 使用外部存储 URI(例如 Amazon S3)来存储随机播放文件;URI 协议决定使用哪个存储系统。
| Key | Value | Explanation |
|---|---|---|
spark.shuffle.storage.path
|
s3://<shuffle-storage-path>
|
It specifies an URI where the shuffle files are stored, which much be a valid Hadoop FileSystem and be configured as needed |
spark.shuffle.sort.io.plugin.class
|
com.amazonaws.spark.shuffle.io.cloud.ChopperPlugin
|
The entry class in the plugin |
其他云存储集成
该插件为亚马逊 S3 提供开箱即用的支持,也可以配置为使用其他形式的云存储,例如
System 兼容的云存储服务,您只需为相应的服务方案添加存储 URI,例如为
, 为该服务添加文件系统 JAR 文件,然后设置相应的身份验证配置。
G
oogle Cloud Storage 添加存储 URI,而不是 Amazon S3 的 s3://
有关如何将插件与谷歌云存储和微软 Azure Blob 存储集成的更多信息,请参阅将
最佳做法和注意事项
请注意以下注意事项:
-
此功能用 Amazon S3 取代了本地随机播放存储。您可以使用它来解决常见故障,为您的无服务器分析任务和管道提供性价比优势。当你想要确保数据密集型工作负载可靠运行从而产生大量随机播放数据时,或者当你遇到 “
设备 上 没有剩余空间” 错误时,我们建议启用此功能。如果你的任务遇到提取失败org.apache.spark.shuffle.metadatafetchFailedException 或者你的数据存在偏差,你也可以使用这个插件。 -
我们建议在洗牌
存储 桶(sp ark.shuffle.storage.s3.path) 上设置 S3 存储桶生命周期策略 ,以便自动清理旧的洗牌数据。 -
默认情况下,Amazon S3 上的洗牌数据是加密的。您还可以使用自己的
亚马逊云科技 密钥管理服务 (亚马逊云科技 KMS) 密钥加密数据。
结论
这篇文章介绍了适用于 Apache Spark 的新的 Cloud Shuffle 存储插件,并描述了在不增加额外工作程序的情况下独立扩展 Spark 作业中的存储空间的好处。有了这个插件,你可以预期处理千兆字节数据的作业可以更可靠地运行。
该插件可在所有支持 亚马逊云科技 Glue 的区域的 亚马逊云科技 Glue 3.0 和 4.0 Spark 任务中使用。我们还将在 Apache 2.0 许可下发布该插件的软件二进制文件。你可以在 亚马逊云科技 Glue 或其他 Spark 环境中使用该插件。我们期待听到您的反馈。
作者简介





*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。