Amazon
DynamoDB 是一个键值和文档数据库,可在任何规模下提供个位数毫秒的性能。它是一个完全托管、多区域、多活动、持久的数据库,具有内置安全性、备份和恢复功能,以及适用于互联网规模应用程序的内存缓存。
2020 年,DynamoDB 推出了一项无需编写代码即可将 DynamoDB 表数据导出到
亚马逊简单存储服务
(Amazon S3)的功能。它无需管理服务器或集群即可运行,并允许您以每秒的粒度将数据导出到过去 35 天内的任何时间点。另外,它不会影响生产表的读取容量或可用性。
将数据以
DynamoDB JSON 或 Amazon Ion 格式导出到亚马逊 S3 后, 您可以使用自己喜欢的工具(例如亚马逊 A
thena
、Amazon S
ageMaker 、亚马逊云科技 Lake Form at
ion 和亚马逊 Reds
hift)对其进行查询或重塑。
今天,我们推出了一项新功能:
增量导出到 Amazon S3
。
在这篇文章中,我们将介绍如何使用增量导出,您可以使用增量导出仅使用更改后的数据定期更新下游系统。您不再需要每次需要新数据时都进行完整导出。增量导出功能仅导出在两个指定时间点之间插入、更新或删除的数据项。现在,您可以更高效、更具成本效益地构建变更数据捕获 (CDC) 管道。
入门
首先,请确保您的表启用了时间点恢复 (PITR),这是任何完整或增量导出所必需的。然后,您可以使用
亚马逊云科技 管理控制台
、
亚马逊云科技 命令行接口
(亚马逊云科技 CLI) 或软件开发工具包启动增量导出。选择要导出更改数据的导出时段,从 15 分钟到 24 小时不等。以下屏幕截图显示了在 DynamoDB 控制台上启动增量导出时的选项。
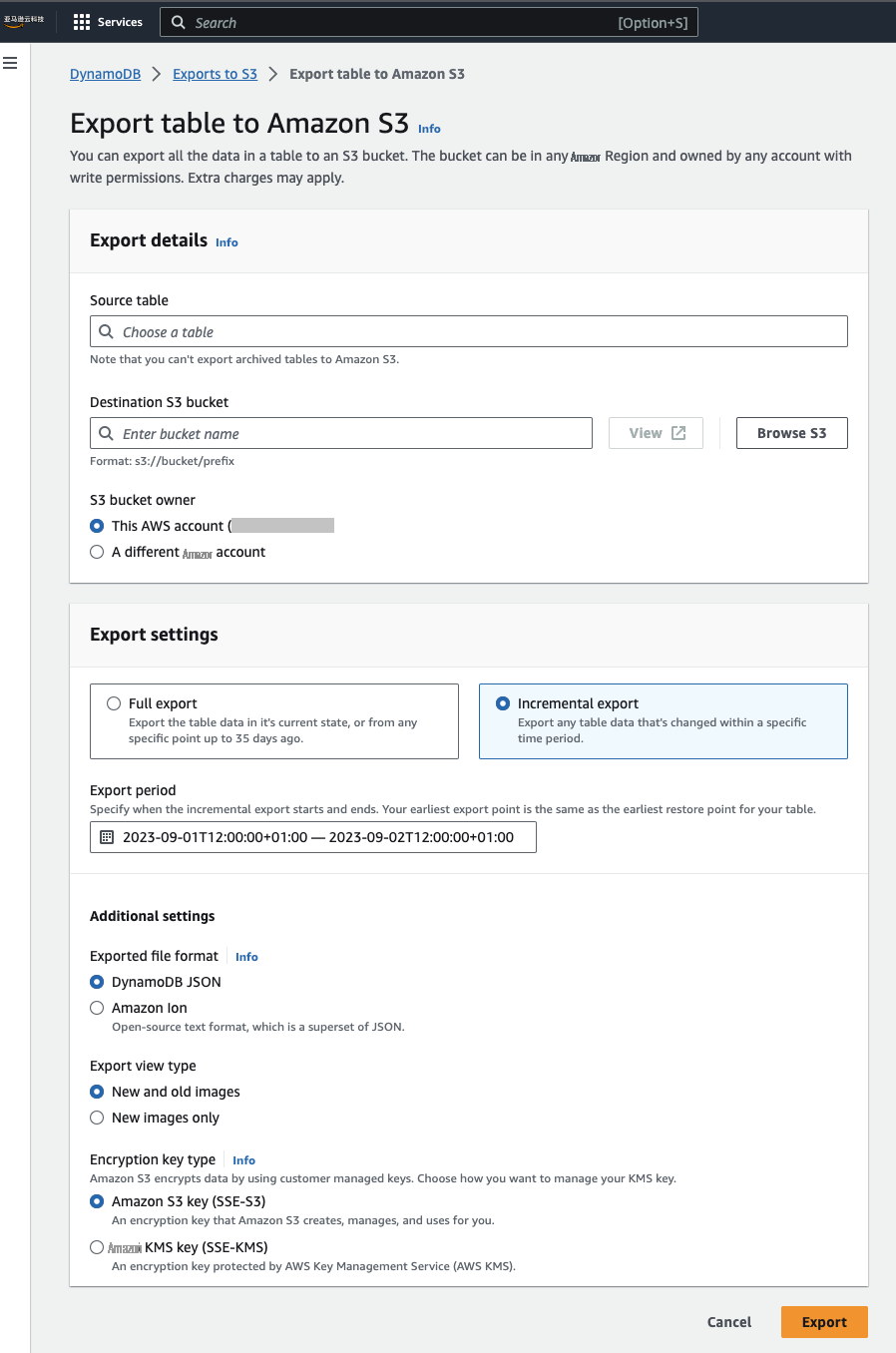
对导出进行了压缩,因此在选定时间段内更改的每个项目最多只能导出一次,从而提供项目的最终视图。每个项目的输出包括一个表示该项目何时被修改的时间戳,以及一个表示修改是插入、更新还是删除的数据结构。在输出中,您可以选择仅查看新图像或同时查看新图像和旧图像。对于更新,如果您想查看项目是如何更改的,这可能会很有用。如果您需要旧图像在下游系统中查找项目,它也可能很有用。
如果您使用的是 亚马逊云科技 CLI,则可以通过提供新的--export-type 和
--incremental-export
-sectiment 来执行增量导出,如以下代码所示
。在占位符中替换你自己的值。时间被指定为自纪元以来的秒数。
# full export
aws dynamodb export-table-to-point-in-time \
--table-arn arn:aws:dynamodb:REGION:ACCOUNT:table/TABLENAME \
--s3-bucket BUCKET --s3-prefix PREFIX \
--export-time 1693569600
# incremental export, starting at the end time of the full export
aws dynamodb export-table-to-point-in-time \
--table-arn arn:aws:dynamodb:REGION:ACCOUNT:table/TABLENAME \
--s3-bucket BUCKET --s3-prefix PREFIX \
--incremental-export-specification ExportFromTime=1693569600,ExportToTime=1693656000,ExportViewType=NEW_AND_OLD_IMAGES \
--export-type INCREMENTAL_EXPORT
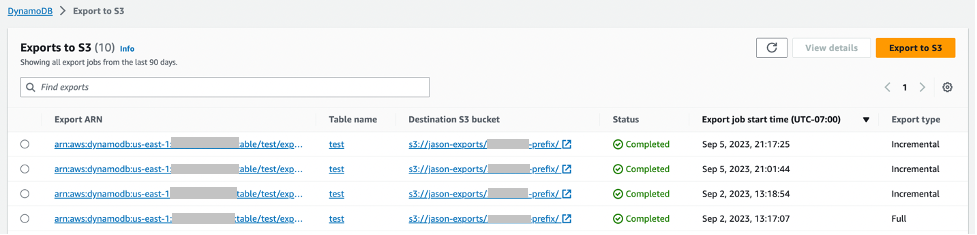
您可以使用 DynamoDB 控制台或
列表导出 和
描述
导出 AWS CLI API 来检查导出
状态。以下屏幕截图显示了控制台上最近导出的列表。
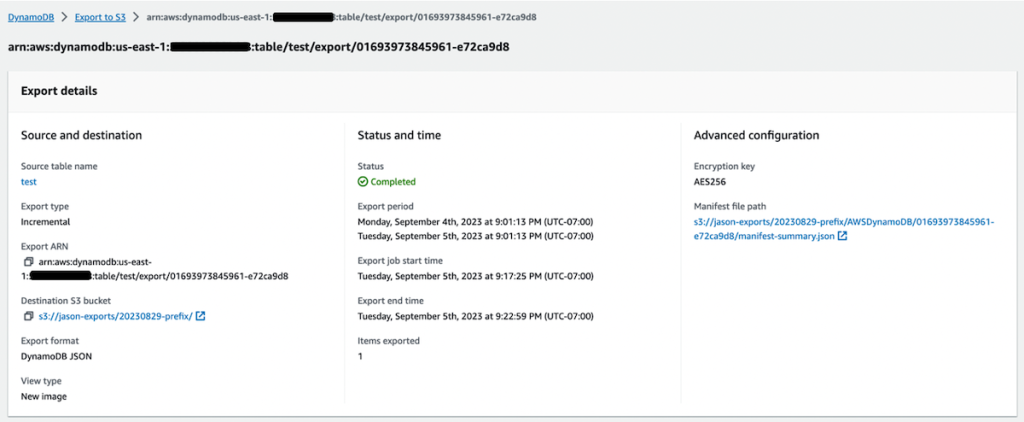
以下屏幕截图显示了控制台中单个导出的详细描述。
文件布局
以下是包含一次完整导出和两次后续增量导出的 S3 文件夹示例:
DestinationBucket/DestinationPrefix
.
└── AWSDynamoDB
├── 01693685827463-2d8752fd # the single full export
│ ├── manifest-files.json # manifest points to files under 'data' subfolder
│ ├── manifest-files.checksum
│ ├── manifest-summary.json # stores metadata about request
│ ├── manifest-summary.md5
│ ├── data # full exports hold their data files internally
│ │ ├── 25xwjjhpziyvjb6lcaj2dqinta.json.gz
│ │ ├── ...
│ └── _started # empty file for permission check
├── 01693685934212-ac809da5 # an incremental export
│ ├── manifest-files.json # manifest points to files under 'data' outer folder
│ ├── manifest-files.checksum
│ ├── manifest-summary.json # stores metadata about request
│ ├── manifest-summary.md5
│ └── _started # empty file for permission check
├── 01693686034521-ac809da5
│ ├── manifest-files.json
│ ├── manifest-files.checksum
│ ├── manifest-summary.json
│ ├── manifest-summary.md5
│ └── _started
├── data # single 'data' folder holding all incremental data
│ ├── sgad6417s6vss4p7owp0471bcq.json.gz
│ ...
原始的完整导出文件夹包括其自己的元数据和数据子文件夹。增量导出包括它们自己的元数据和所有增量导出的共享数据子文件夹。元数据文件夹中列出了为该导出编写的内容。
出口不相互依赖。例如,您可以在没有完成完整导出的情况下请求增量导出,也可以请求涵盖相同时间段的多次增量导出,前提是开始时间和结束时间在 PITR 窗口内(从启用 PITR 时开始,最多可回溯到 35 天)。使用相同时间参数的导出将始终在输出中包含相同的数据。要生成连续视图,您通常希望导出从完整导出开始,然后进行一系列共享时间边界的增量导出。
数据文件格式不同于完整导出,包含更多元数据。以下代码是增量导出数据文件的一部分。每个项目都提供在增量导出窗口中上次更改项目的时间戳(以微秒为单位)、项目的主键、新图像(用于插入和更新)和旧图像(如果您还选择包括旧图像,则用于更新和删除)。如果项目在增量时间窗口内经历了多次修改,则旧图像是开始导出之前的项目图像,新图像是最新图像,时间戳是制作项目以匹配新图像的时间。
可以从结构中推断出更改是插入、更新还是删除。如果您选择了仅包含新图像的增量导出,则插入和更新的时间戳、主键和新图像看起来相同,删除时将不包含任何新图像。如果您选择了新图像和旧图像,则插入内容将包含新图像,更新将包含旧图像和新图像,而删除的图像将仅包含旧图像。下表汇总了每项操作的输出结构。
|
Operation
|
New Images Only
|
New and Old Images
|
|
Insert
|
Keys + new image
|
Keys + new image
|
|
Update
|
Keys + new image
|
Keys + old image + new image
|
|
Delete
|
Keys
|
Keys + old image
|
|
Insert + Delete
|
No output
|
No output
|
以下是新图像和旧图像的输出示例:
// Ex 1: Insert
// An insert means the item did not exist before the incremental export window
// and was added during the incremental export window
{
"Metadata": {
"WriteTimestampMicros": "1680109764000000"
},
"Key": {
"PK": {
"S": "CUST#100"
}
},
"NewImage": {
"PK": {
"S": "CUST#100"
},
"FirstName": {
"S": "John"
},
"LastName": {
"S": "Don"
}
}
}
// Ex 2: Update
// An update means the item existed before the incremental export window
// and was updated during the incremental export window.
// The OldImage would not be present if choosing "New images only".
{
"Metadata": {
"WriteTimestampMicros": "1680109764000000"
},
"Key": {
"PK": {
"S": "CUST#200"
}
},
"OldImage": {
"PK": {
"S": "CUST#200"
},
"FirstName": {
"S": "Mary"
},
"LastName": {
"S": "Grace"
}
},
"NewImage": {
"PK": {
"S": "CUST#200"
},
"FirstName": {
"S": "Mary"
},
"LastName": {
"S": "Smith"
}
}
}
// Ex 3: Delete
// A delete means the item existed before the incremental export window
// and was deleted during the incremental export window
// The OldImage would not be present if choosing "New images only".
{
"Metadata": {
"WriteTimestampMicros": "1680109764000000"
},
"Key": {
"PK": {
"S": "CUST#300"
}
},
"OldImage": {
"PK": {
"S": "CUST#300"
},
"FirstName": {
"S": "Jose"
},
"LastName": {
"S": "Hernandez"
}
}
}
// Ex 4: Insert + Delete
// Nothing is exported if an item is inserted and deleted within the
// incremental export window.
注意事项
出口时间段包括开始时间,不包括结束时间。这意味着,要生成每小时的增量导出,你可以在任意的清理时间(例如某一天的 6:00:00)进行一次性引导完全导出,并在 6:00:00 到 7:00:00、7:00:00 到 8:00:00 等的未来每个小时启动持续的增量导出,并且没有重叠之处。您可以使用
亚马逊 Ev ent
Bridge 来安排这些增量操作。
定价基于为创建每次增量导出而处理的数据量。此大小基于表生成的更改日志的数量。如果您的表非常活跃,写入次数很多,则会有更多的更改日志,并且增量导出成本将与该活动成正比。有关定价,请参阅
亚马逊 DynamoDB
定价。
请注意,任何为读取完整导出格式而构建的工具自然都无法读取完整导出和一系列增量导出的组合。为了便于下游访问,您可以将一系列导出转换为单一目标格式,例如 Apache Iceberg 表。你可以使用
亚马逊 EMR
和 Apache Spark 来批量处理导出并使 Iceberg 表格保持最新状态。
结论
DynamoDB 增量导出到 Amazon S3 功能使您能够仅使用增量更改的数据定期更新下游系统。这项新功能可在所有商用 亚马逊云科技 区域和 GovCloud 中使用。
作者简介
 杰森·亨特
是加州的首席解决方案架构师,专门研究亚马逊 DynamoDB。自 2003 年以来,他一直在使用 NoSQL 数据库。他以对 Java、开源和 XML 的贡献而闻名。
杰森·亨特
是加州的首席解决方案架构师,专门研究亚马逊 DynamoDB。自 2003 年以来,他一直在使用 NoSQL 数据库。他以对 Java、开源和 XML 的贡献而闻名。
 Shahzeb Farrukh
是 亚马逊云科技 DynamoDB 驻西雅图的高级产品经理。他致力于开发 DynamoDB 的数据保护功能,例如备份和恢复,以及帮助客户将其数据与其他服务集成的数据移动功能。自2010年以来,他一直从事数据库和分析工作。
Shahzeb Farrukh
是 亚马逊云科技 DynamoDB 驻西雅图的高级产品经理。他致力于开发 DynamoDB 的数据保护功能,例如备份和恢复,以及帮助客户将其数据与其他服务集成的数据移动功能。自2010年以来,他一直从事数据库和分析工作。