我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
为 亚马逊云科技 Glue 数据目录引入混合访问模式,以便使用 亚马逊云科技 Lake Formation、IAM 和 Amazon S3 策略进行安全访问
在引入 Lake F
为了简化数据湖权限从 IAM 和 S3 模型向湖组成的过渡,我们为 亚马逊云科技 Glue 数据目录引入了混合访问模式。请参阅
混合访问模式允许在同一个数据库和表中同时存在两种权限模型,从而在管理用户访问方面提供了更大的灵活性。虽然此功能为数据目录资源打开了两扇门,但 IAM 用户或角色只能使用这两种权限中的一种访问该资源。为 IAM 委托人启用 Lake Formation 权限后,授权将完全由 Lake Formation 管理,现有的 IAM 和 S3 策略将被忽略。
在这篇博客文章中,我们将向您介绍如何在混合访问模式下为选定用户加入 Lake Formation 权限的说明,同时其他用户已经可以通过 IAM 和 S3 权限访问数据库。我们将查看在 亚马逊云科技 账户内和两个账户之间设置混合访问模式的说明。
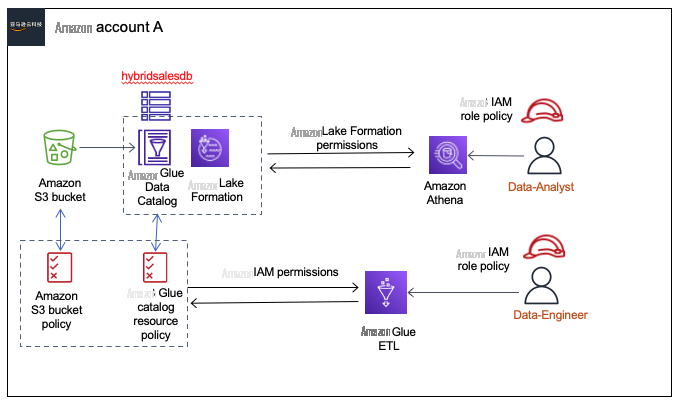
场景 1 — 亚马逊云科技 账户内的混合访问模式
在这种情况下,我们将引导您完成以下步骤,开始为使用 IAM 和 S3 策略权限访问的数据目录中的数据库添加具有 Lake Formation 权限的用户。举例来说,我们使用两个角色:
数据工程师
,他拥有使用 IAM 策略和运行 亚马逊云科技 Glue ETL 任务的 S3 存储桶策略的粗粒度权限,以及
数据分析师
,我们将为其提供使用 Amazon Athena 查询数据库的细粒度湖组权限。
场景 1 如下图所示,其中,
数据工程师
角色 使用 IAM 和 S3 权限访问数据库 hyb
ridsalesdb
,而
数据分析师
角色将使用 Lake Formation 权限访问数据库。
先决条件
要为具有混合访问模式的数据目录数据库设置 Lake Formation 以及 IAM 和 S3 权限,您必须具备以下先决条件:
- 不用于生产应用程序的 亚马逊云科技 账户。
-
Lake Formation已经在账户中设置了Lake Formation管理员角色或类似角色,供您按照本文中的说明进行操作。例如,我们正在使用名为 LF-Admin 的数据湖管理员角色。要了解有关为数据湖管理员角色设置权限的更多信息,请参阅
创建数据湖管理员 。 -
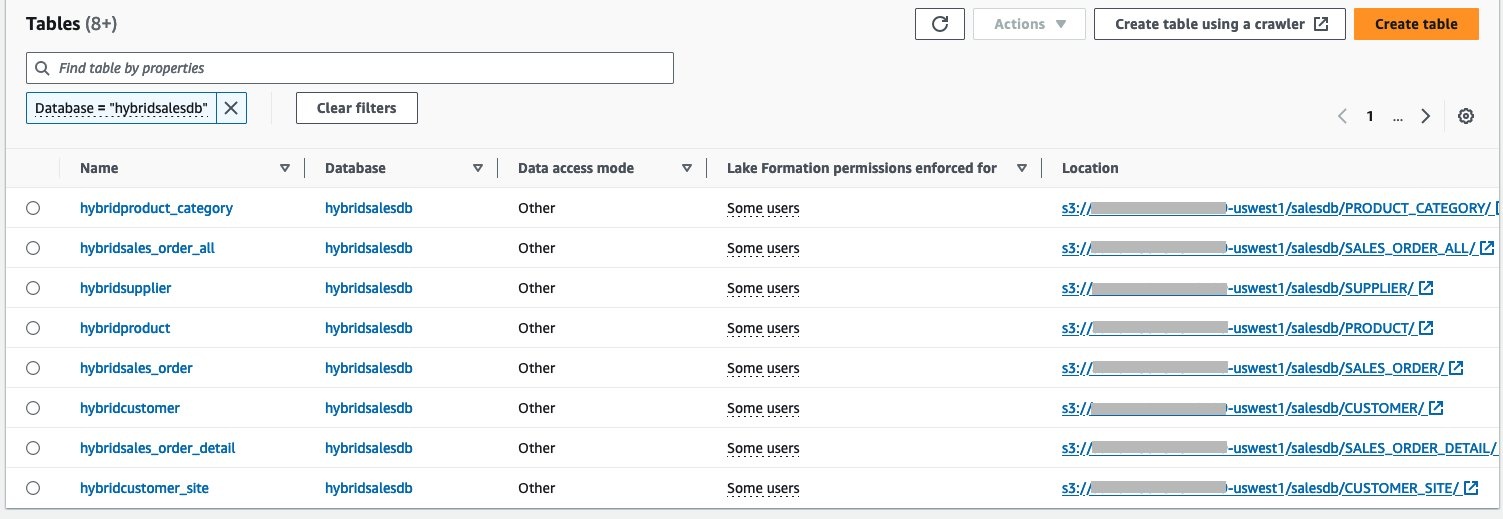
数据目录中包含几个表的示例数据库。例如,我们的示例数据库名为
hybridsalesdb,它有一组八个表,如以下屏幕截图所示。你可以使用任何数据集来跟进。
角色及其 IAM 策略设置
账户中有两个角色是 IAM 角色:
他们的 IAM 策略和访问权限如下所述。
数据工程师 和数据分析师
。
以下 IAM 关于
数据工程师
角色的策略允许访问数据目录中的数据库和表元数据。
以下 IAM 关于数据工程师角色的策略授予对数据库和表底层 Amazon S3 位置的数据访问权限。
数据工程师
还可以使用 AWS 管理策略 arn
: aws: iam:: aws: policy/awsglueConsoleFullAccess 和回归型 iam: PassRole 访问 AWS Glue 控制台,运行如下所示 AWS Glue ETL 脚本
。
以下策略也已添加到
数据工程师
角色的信任策略中,以允许 亚马逊云科技 Glue 代入该角色代表该角色运行 ETL 脚本。
有关运行
数据分析师
角色拥有数据湖基本用户权限,如向 Lake Format
此外,
数据分析师
有权使用亚马逊云科技管理策略 arn: aws: iam:: aws: P
ol
icy/AmazonaAthenaFullAccess 将雅典娜查询结果写入不由Lake Formation和雅典娜控制台完全访问权限管理的S3存储桶。
为数据分析师设置湖泊形成权限
完成以下步骤,在混合访问模式下使用 Lake Formation 配置您在 Amazon S3 中的数据位置,并授予对
数据分析师
角色的访问权限。
- 以 Lake Formation 管理员角色登录 亚马逊云科技 管理控制台。
- 前往 Lake Formation。
- 从左侧导航栏的 “ 管理 ” 下选择 “ 数据湖位置 ” 。
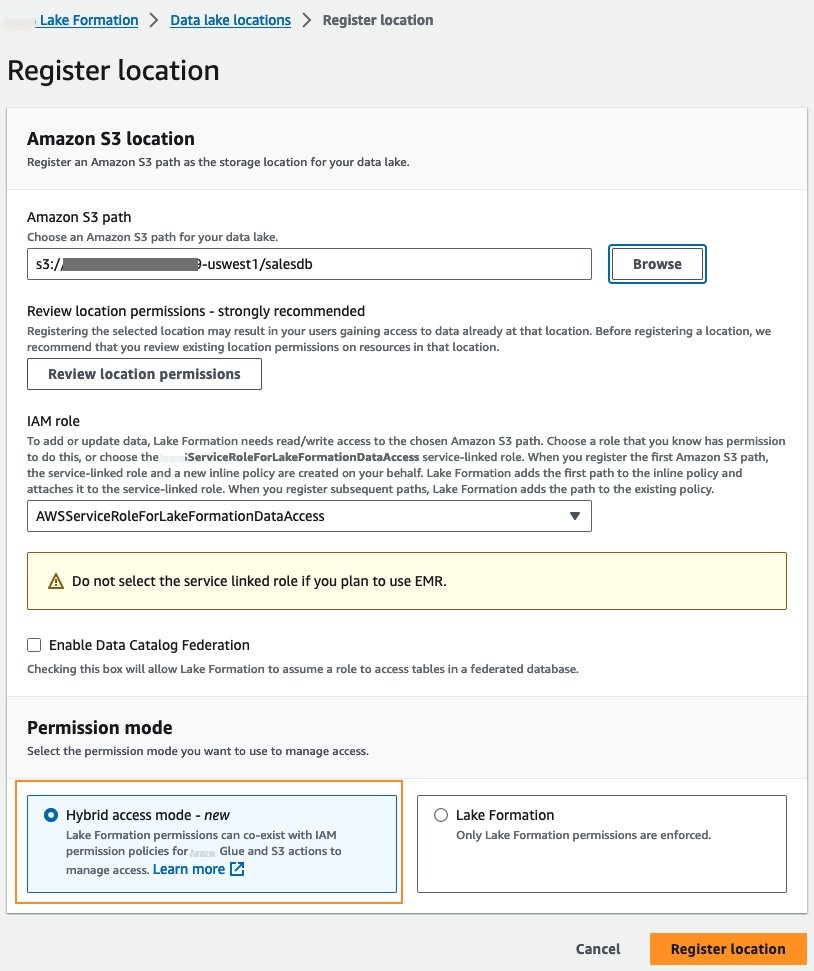
-
选择
注册位置
并提供您的数据库和表的 Amazon S3 位置。提供有权访问 S3 位置数据的 IAM 角色。有关更多详细信息,请参阅
用于注册地点的角色 要求 。 -
在 “
权限”
模式 下选择 “ 混合访问
模式
” ,然后选择 “
注册位置
” 。
-
在左侧导航栏的 “
管理
” 下选择 “
数据湖位置
”。检查注册位置是否显示 为
权限
模式的 混合访问
模式
。

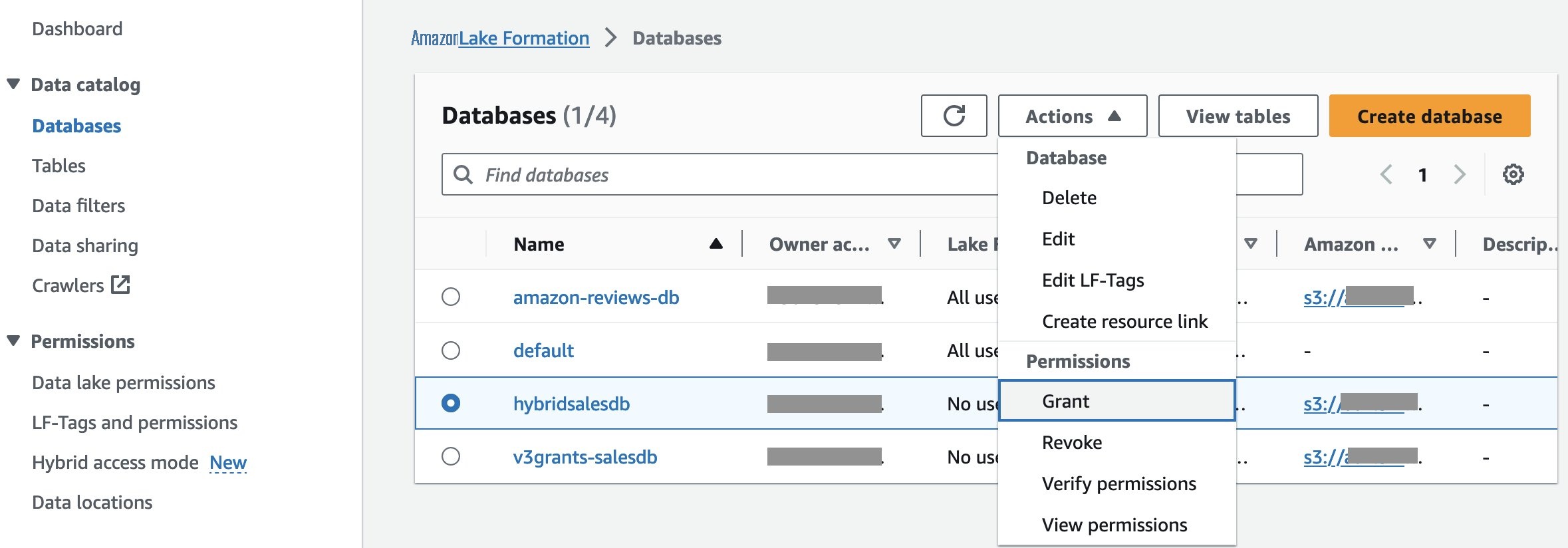
-
在左侧导航栏 上 从
目录
中选择
数据库
。选择
hybridsalesdb。您将选择在前面的步骤中注册的 S3 位置中包含数据的数据库。从 “ 操作 ” 下拉菜单中,选择 “ 授予 ” 。
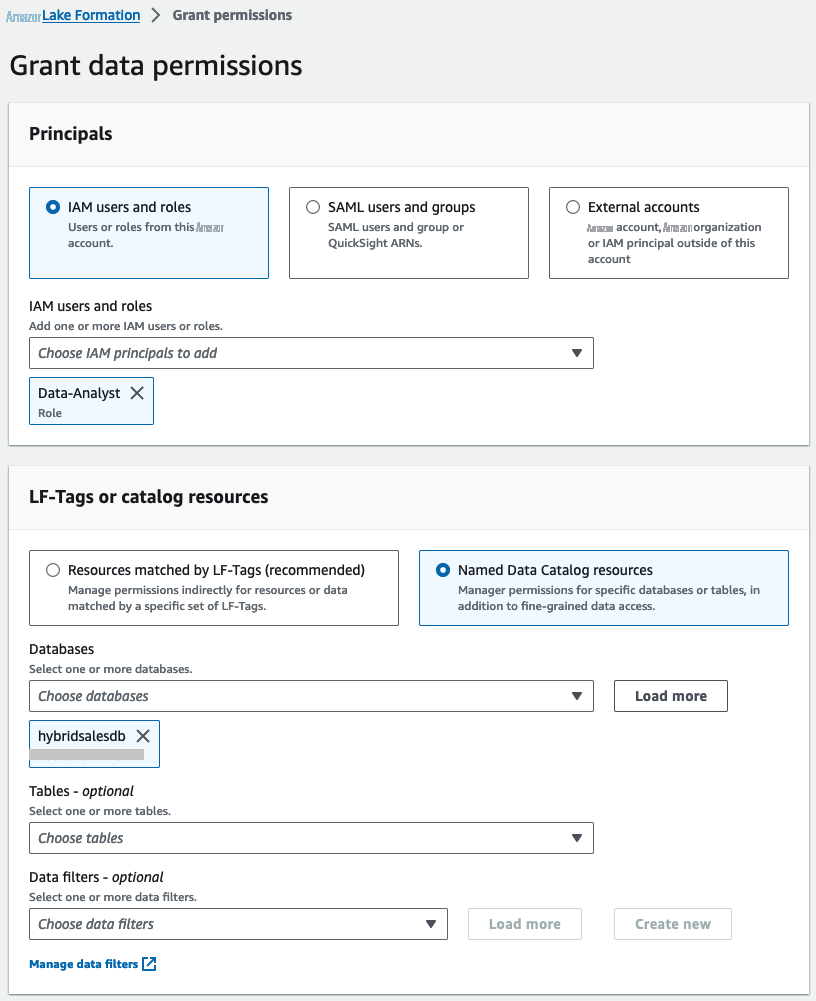
-
为
IAM 用户和角色
选择
数据分析师。 在 LF-tags 或目录资源下 ,选择 命名数据目录资源 ,然后为数据库 选择hybridsalesdb。
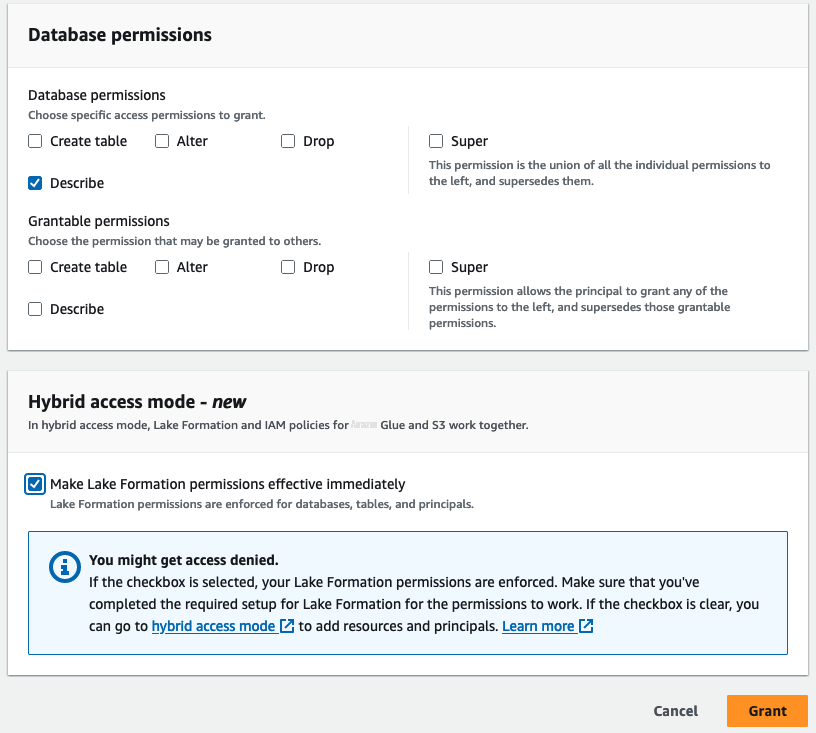
-
在
数据库权限
下 ,选择
描述
。在
混合访问模式
下 ,选中 “
使湖组建权限立即生效
” 复选框 。选择 “
授予
” 。
-
同样,在左侧导航栏 上 从 “
目录
” 中选择 “
数据库
”。选择
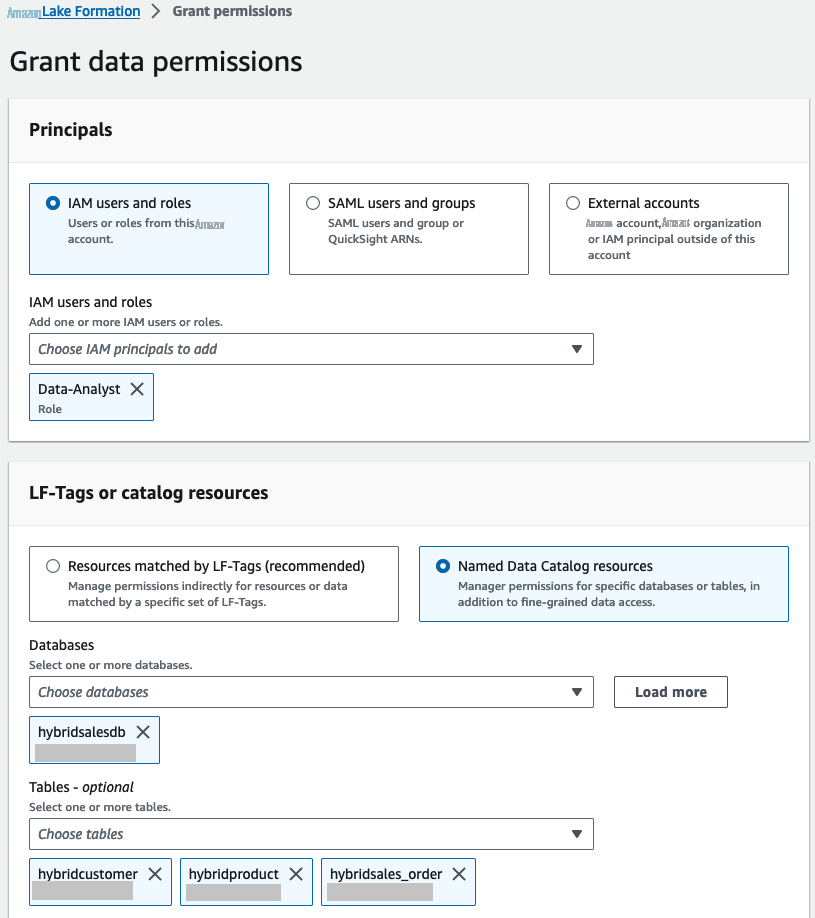
hybridsalesdb。 从 “ 操作 ” 下 拉菜单中选择 “ 授予 ”。 -
在授权窗口中,为
IAM 用户和
角色选择
数据分析。 在 LF-tags 或目录资源下 ,选择 命名数据目录资源 ,然后为数据库 选择hybridsalesdb。 -
在 “
表格
” 下 ,从下拉列表中选择名为 “混合
客户” 、“混合 产品” 和 “hybridsales_order” 的三个表。
- 在 “ 表权限 ” 下 , 选择 “选择 和 描述 表的 权限”。
-
选中
混合访问模式
下的复选框 以使 Lake Formation 权限立即生效。
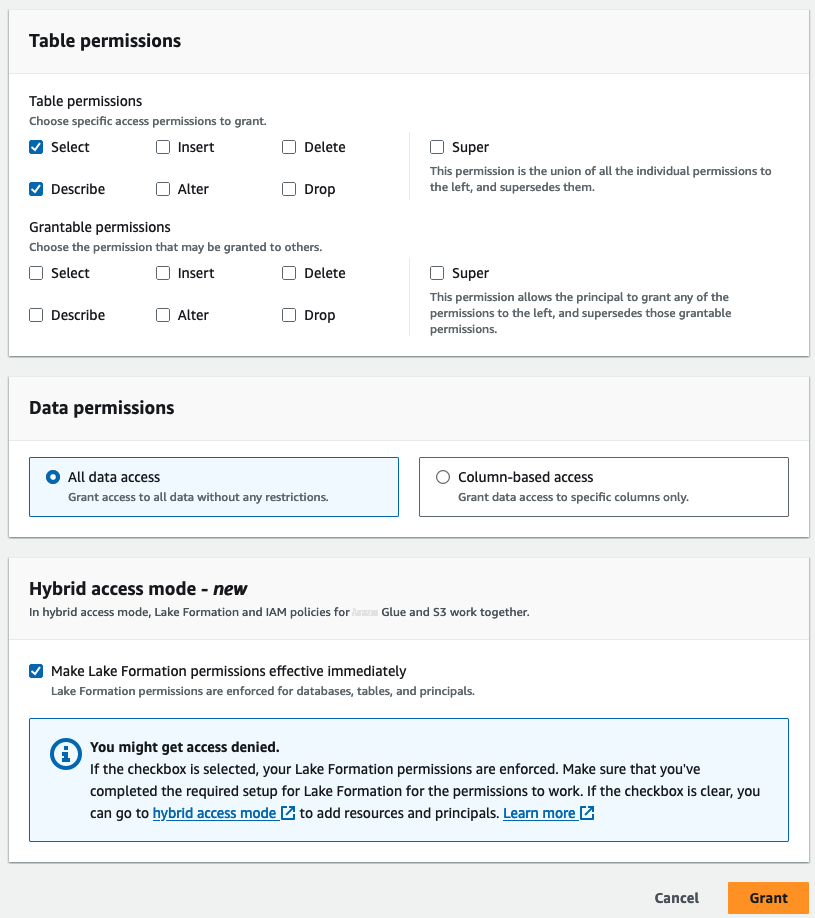
- 选择 “ 授予 ” 。
-
选择左侧导航栏 上的 “权限” 下的 “
数据湖
”
权限
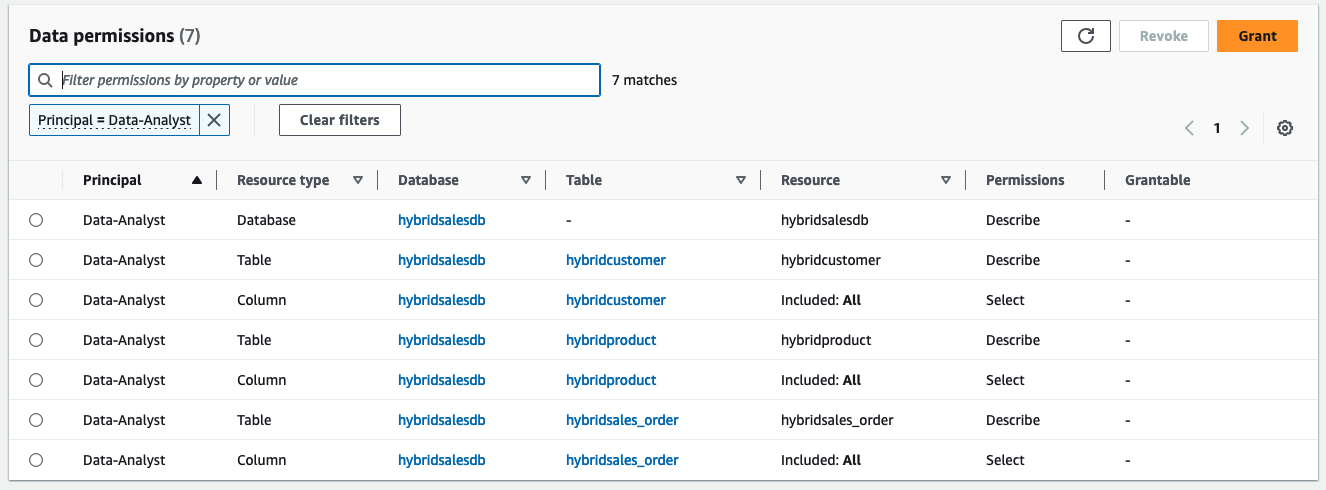
,查看授予的权限。 按 “
主体 =
数据
分析师” 筛选数据权限 。
-
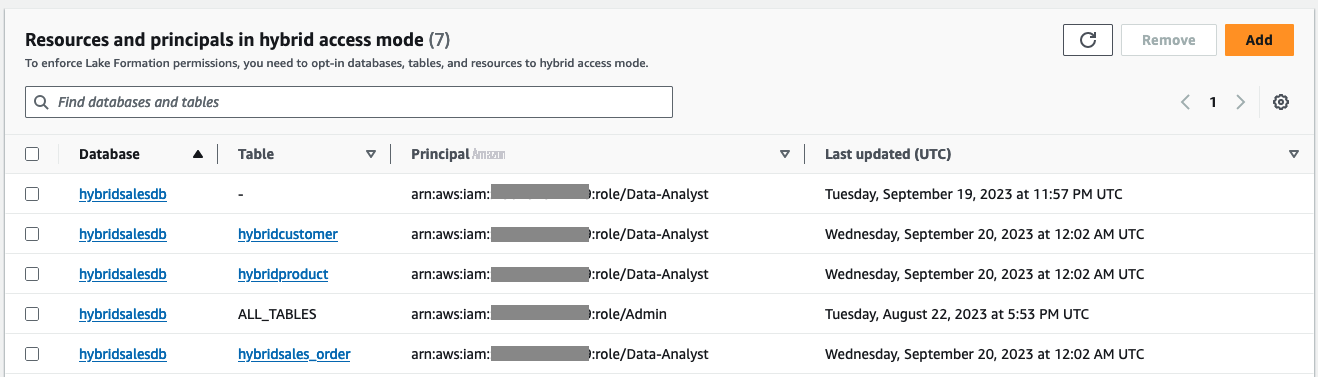
在左侧导航栏上,选择
混合访问模式
。验证选择的数据分析器是否显示在 hy
bridsalesdb数据库和三个表中。
- 以 Lake Formation 管理员角色注销控制台。
验证数据分析师的湖泊形成权限
-
以
数据分析师身份登录控制台。 -
转到雅典娜控制台。如果您是首次使用 Athena,请按照
指定查询结果位置中所述设置您的 S3 存储桶的查询结果位置 。
-
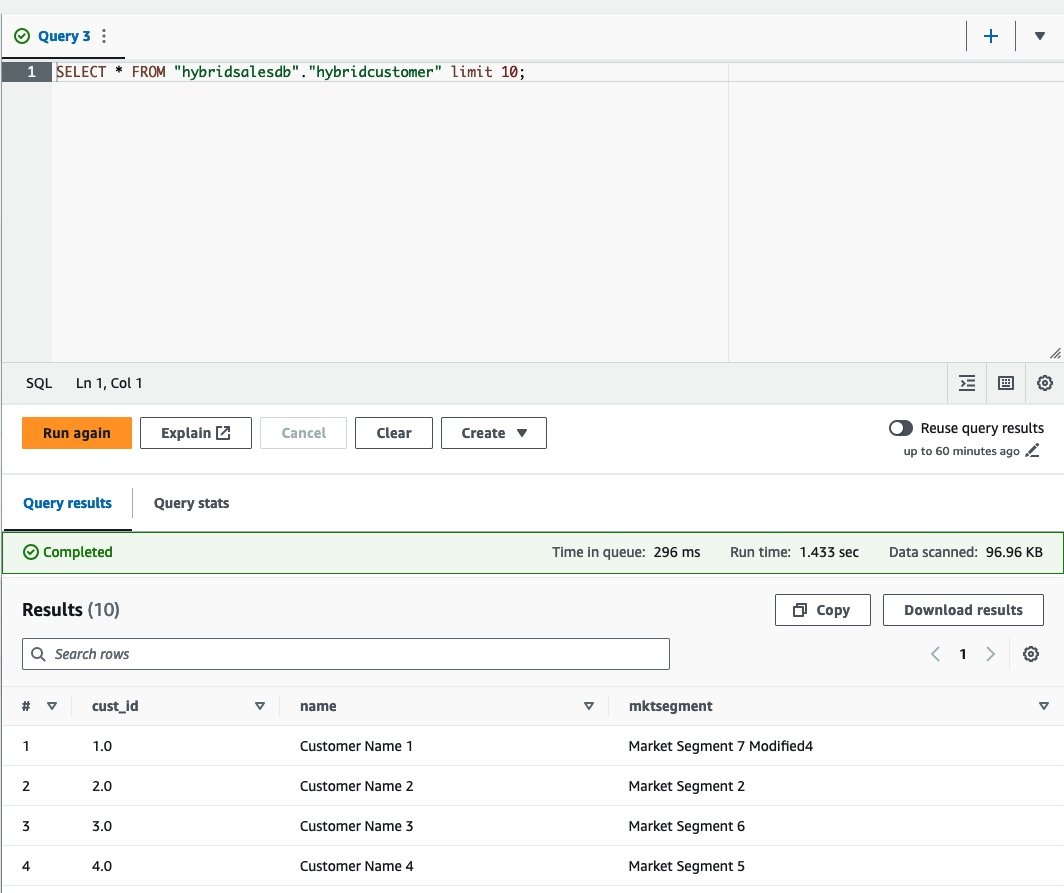
通过 Athena 查询编辑器在表格上运行预览查询。
验证数据工程师的 IAM 和 S3 权限
-
以数据分析师身份注销并以
数据工程师身份重新登录控制台。 - 打开 亚马逊云科技 Glue 控制台,然后 从左侧导航栏中选择 ETL 任务 。
- 在 “ 创建作业 ” 下 ,选择 Spark 脚本编辑器 。选择 “ 创建”。
-
下载并打开
此处提供的 示例脚本 。 - 将脚本作为一项新任务复制并粘贴到工作室脚本编辑器中。
-
编辑
目录 ID、数据库和表名以适合您的示例。 -
通过提供数据工程师的 IAM 角色来
运行任务,
保存
并运行
您的 亚马逊云科技 Glue ETL 脚本。
-
ETL 脚本成功运行后,您可以从 ETL 脚本的 “
运行
” 选项卡中选择输出日志链接。
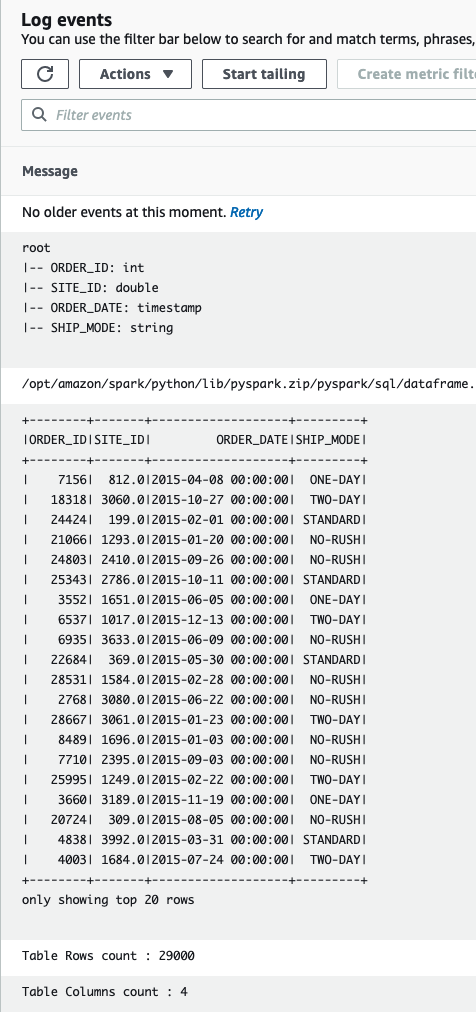
-
查看该表的架构、前 20 行以及
亚马逊云科技 CloudWatch 日志中的总行数和列数。
因此,您可以向新角色添加 Lake Formation 权限以访问数据目录数据库,而不会干扰通过 IAM 和 S3 权限访问同一数据库的另一个角色。
场景 2 — 在两个 亚马逊云科技 账户之间设置混合访问模式
这是一种跨账户共享场景,其中数据生产者与消费者账户共享数据库及其表。生产者为使用者账户上的 亚马逊云科技 Glue ETL 工作负载提供完整的数据库访问权限。同时,生产商使用Lake Formation与消费者账户共享同一数据库的几张表。我们将向您介绍如何使用混合访问模式来支持这两种访问方法。
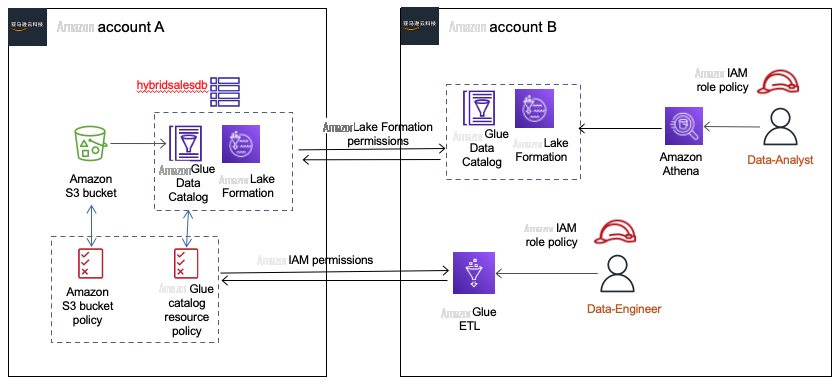
先决条件
- 在混合访问模式下注册的数据库或表位置的跨账户共享要求生产者或授予者账户处于目录设置中的跨账户共享版本 4,才能授予对混合访问模式资源的权限。从跨账户共享的版本 3 迁移到版本 4 时,对于已经注册到 Lake Formation(Lake Formation 模式)的数据库和表位置,现有的 Lake Formation 权限不会受到影响。要在混合访问模式下注册新的数据集位置以及对该目录资源的新 Lake Formation 权限,您将需要版本 4 的跨账户共享。
-
消费者或收款人账户可以使用其他版本的跨账户共享。如果您的账户使用的是跨账户共享的版本 1 或版本 2,并且想要升级,请按照
更新跨账户数据共享版本设置 操作,首先 将跨账户共享的目录设置升级到版本 3,然后再升级到版本 4。
生产者账户的设置与场景 1 类似,我们将在下一节中讨论场景 2 的额外步骤。
在制作人账户 A 中设置
使用生产者的 S3 存储桶策略向消费者
数据工程师
角色授予 Amazon S3 数据访问权限,使用生产者的数据目录资源策略授予数据目录访问权限。
生产者账户中的 S3 存储桶策略如下:
生产者账户中的数据目录资源策略如下所示。您还需要获得 A
资源访问管理器 (AWS RA M) 的 glue: share
Resource IAM
设置跨账户版本并注册 S3 存储桶
-
以 IAM 管理员角色或具有
PutDatalakeSettings () API IAM 权限的角色身份登录 Lake Formation 控制台。 选择在 S3 存储桶中存储示例数据集的 亚马逊云科技 区域,并在数据目录中选择相应的数据库和表。 -
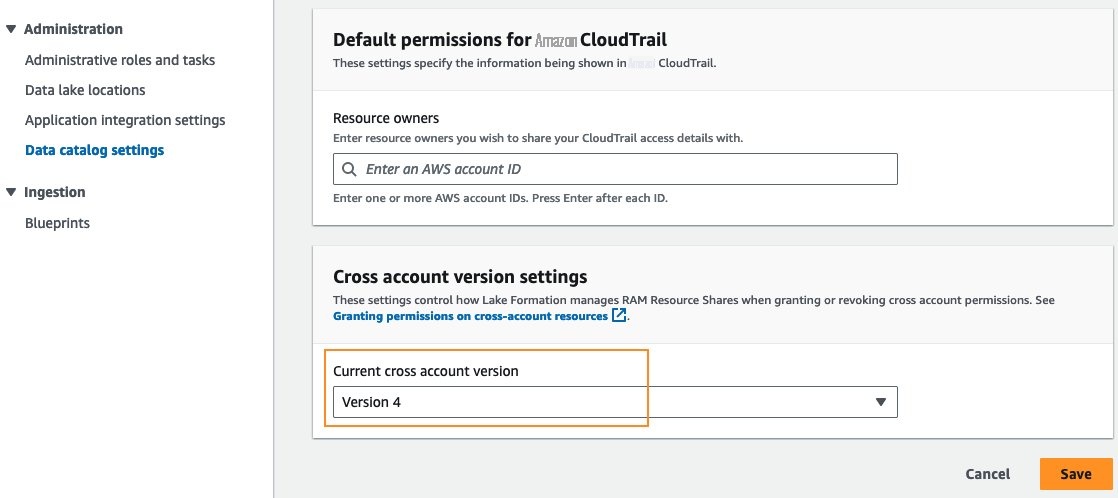
从左侧导航栏的 “
管理
” 下选择 “
数据目录设置
” 。 从
跨账户 版本设置的下拉菜单中选择版本
4
。选择 “
保存”
。
注意: 如果您的环境中还有其他账户通过 Lake Formation 将目录资源共享到您的生产者账户,则升级共享版本可能会对它们产生影响。有关更多信息,请参见。
- 以 IAM 管理员身份注销,然后以 Lake Formation 管理员角色重新登录 Lake Formation 控制台。
- 从左侧导航栏的 “ 管理 ” 下选择 “ 数据湖位置 ” 。
- 选择 注册位置 并提供数据库和表的 S3 位置。
-
提供有权访问 S3 位置数据的 IAM 角色。有关此角色要求的更多详细信息,请参阅
用于注册位置的角色 要求 。 -
在 “
权限”
模式 下选择 “ 混合访问
模式
” ,然后选择 “
注册位置
” 。

-
在左侧导航栏的 “
管理
” 下选择 “
数据湖位置
”。确认注册位置显示 为
权限
模式的 混合访问
模式
。

授予跨账户权限
与消费者账户共享数据库
hybridsalesdb
的步骤与设置场景 1 的步骤类似。
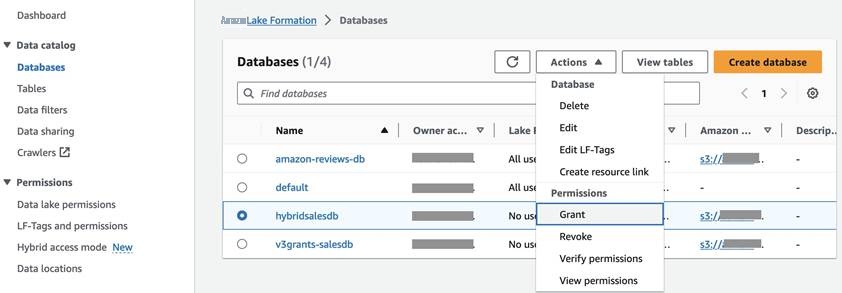
-
在 Lake Formation 控制台中,选择左侧导航栏 上的
目录
中的
数据库
。选择
hybridsalesdb。选择在您之前注册的 S3 位置中包含数据的数据库。从 “ 操作 ” 下拉菜单中,选择 “ 授予 ” 。
-
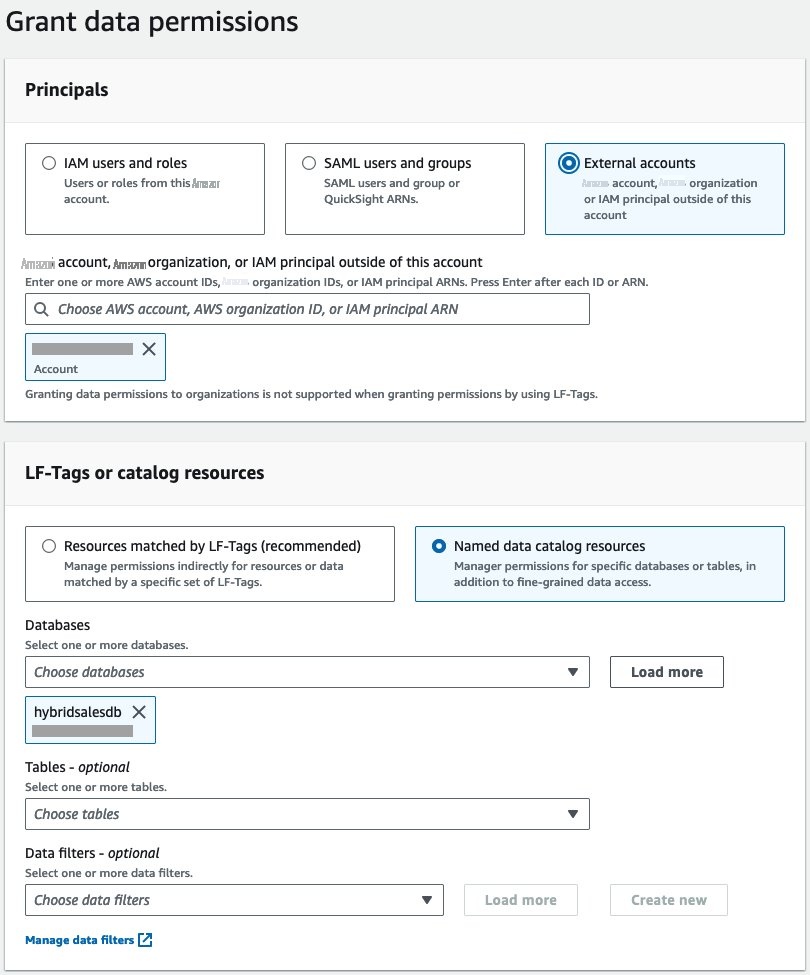
在 “
主人
” 下选择 “
外部账户
” 并提供消费者账户 ID。在
LF 标签或
目录资源 下选择 命名
目录
资源。
为数据库选择
hybridsalesdb
。
- 为 数据库权限 和 可授予的权限 选择 描述 。
-
在
混合访问模式
下 ,选中 “
使湖组建权限立即生效
” 复选框 。选择 “
授予
” 。
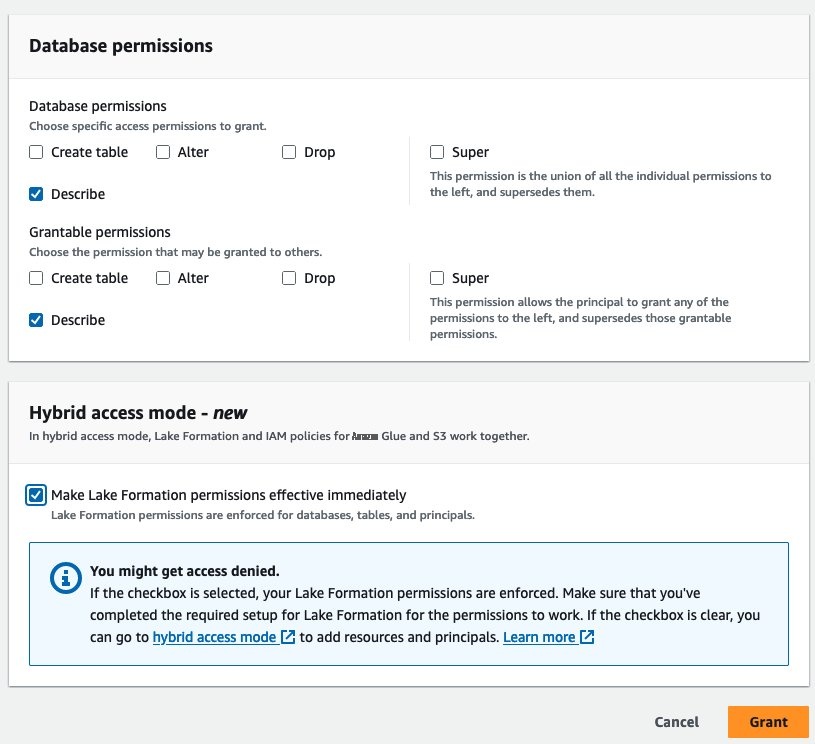
注意: 选中该复选框会 选择使用消费者账户 Lake Formation 管理员角色以使用 Lake Formation 权限,而不会中断消费者账户对同一数据库的 IAM 和 S3 访问权限。
-
重复步骤 2,直到选择数据库,向消费者账户 ID 授予表级别权限的权限。从 “表” 下拉菜单中选择任意三个表以获得
表
级权限 。
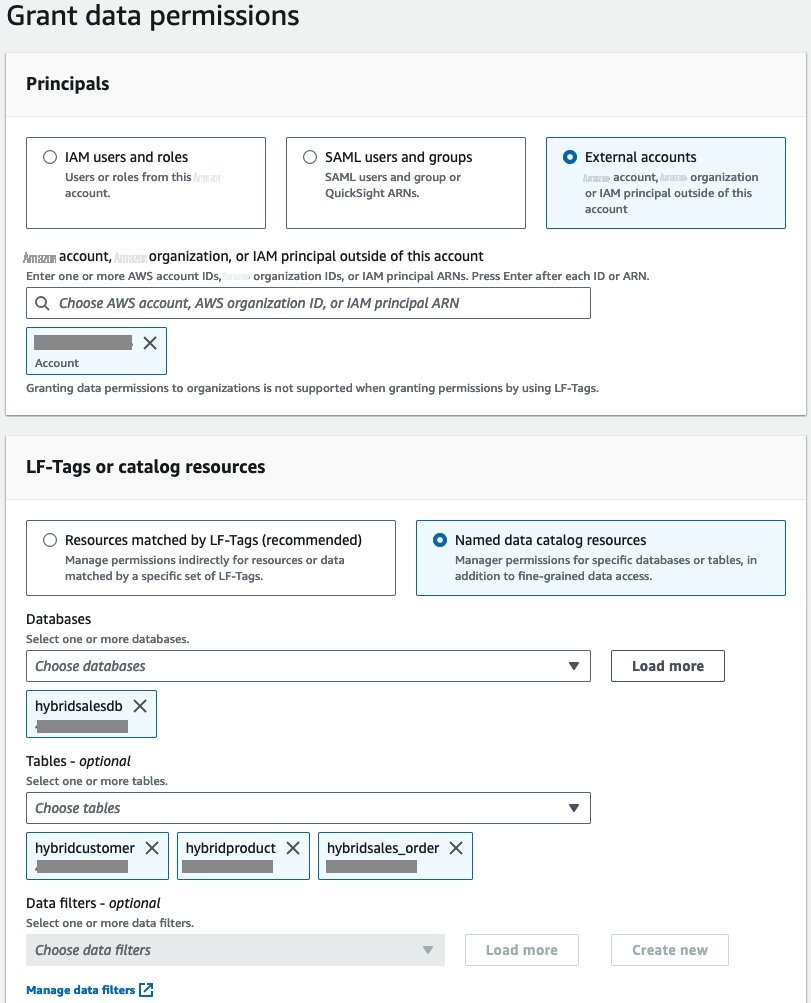
-
在 “
表权限” 和 “可授予权限
” 下选择 “选择
”
。在
混合访问模式
下,选中 “
使湖组建权限立即生效
” 复选框 。选择 “
授予
” 。
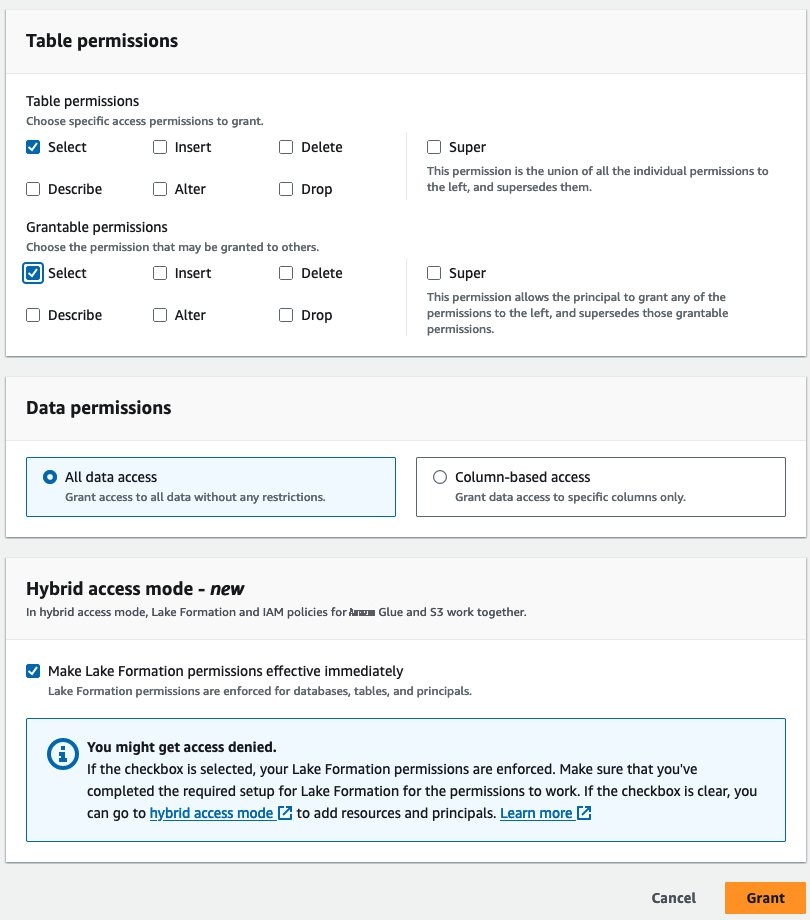
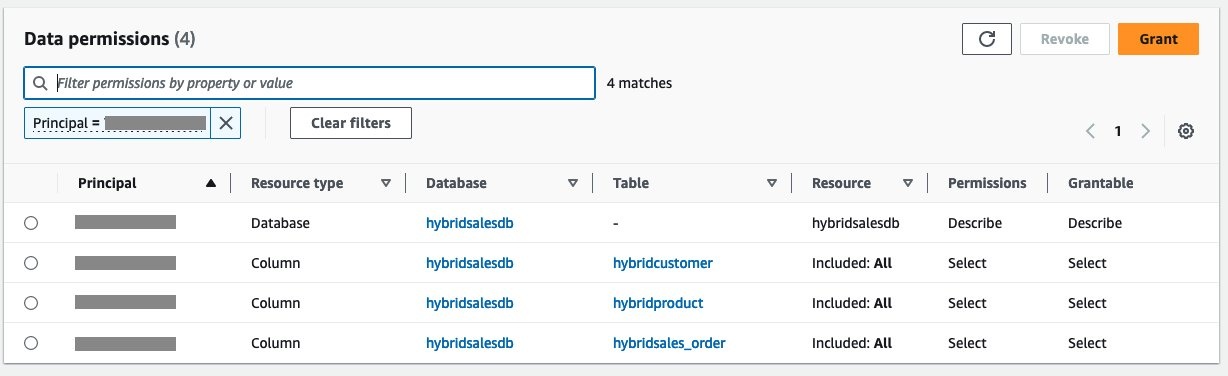
-
在左侧导航栏 上选择
数据湖权限
。验证消费者账户的授予权限。
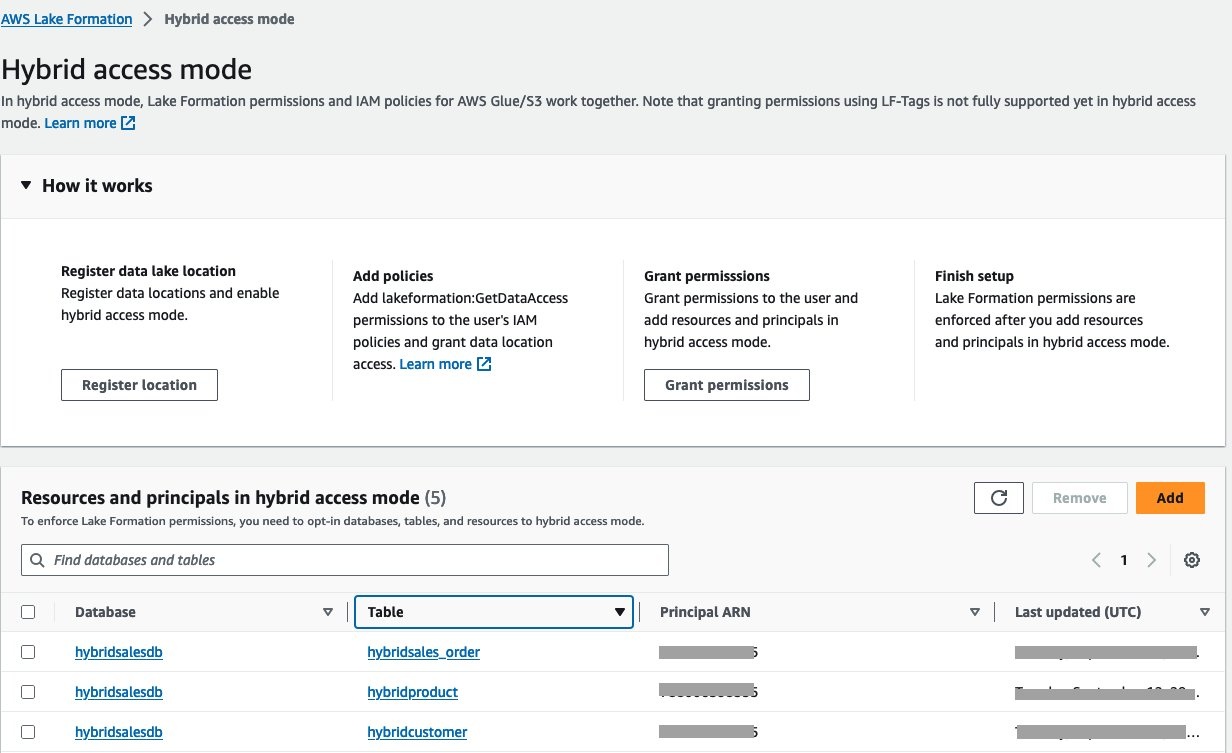
-
在左侧导航栏 上选择
混合访问模式
。验证已选择加入的资源和委托人。
现在,您已经使用 Lake Formation 权限启用了跨账户共享,而无需撤消对
iamallowedPrincip
al 虚拟组的访问权限。
在消费者账户 B 中设置
在场景 2 中,
数据分析师
和
数据工程师
角色是在消费者账户中创建的,与场景 1 类似,但这些角色访问从生产者账户共享的数据库和表。
s: iam:: aws: policy/awsglueConsoleFullAccess 和 arn: aws: iam:: policy/cloudwatchFullAccess 之外,数据工程师角色还有权在 A WS G
lue Studio 中创建 和运行 Apache Spark 任务
。
数据工程师
具有以下 IAM 策略,该策略授予对生产者账户的 S3 存储桶的访问权限,该存储桶以混合访问模式在 Lake Formation 中注册。
数据工程师
具有以下 IAM 策略,该策略授予对消费者账户的整个数据目录和生产者账户的数据库 hyb
ridsalesdb
及其表的访问权限。
数据分析师
具有与场景 1 相同的 IAM 策略,授予基本的数据湖用户权限。有关其他详细信息,请参阅向
接受 亚马逊云科技 RAM 邀请
- 以 Lake Formation 管理员角色登录到 Lake Formation 控制台。
-
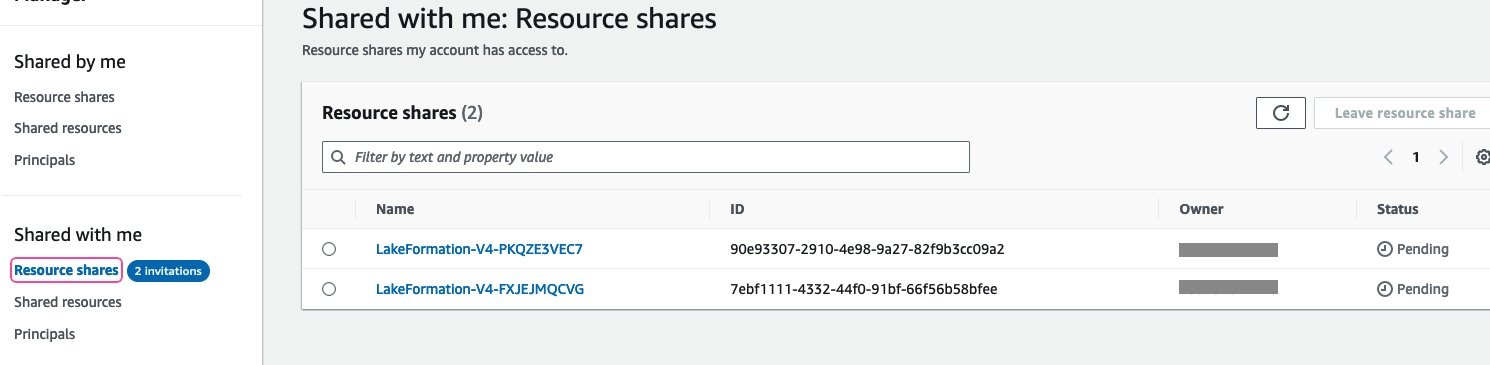
打开 亚马逊云科技 RAM 控制台。 从左侧导航栏 上的 “
与我 共享
” 中选择 “
资源
共享”。您应该看到来自制作人账户的两个邀请,一个用于数据库级共享,另一个用于表格级共享。
-
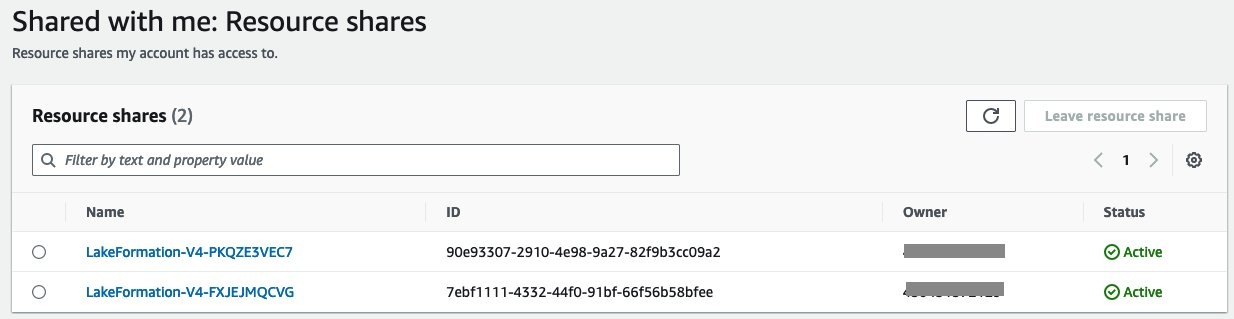
选择每个邀请,查看生产者账户 ID,然后选择 “
接受资源共享
” 。
向数据分析师授予湖泊形成权限
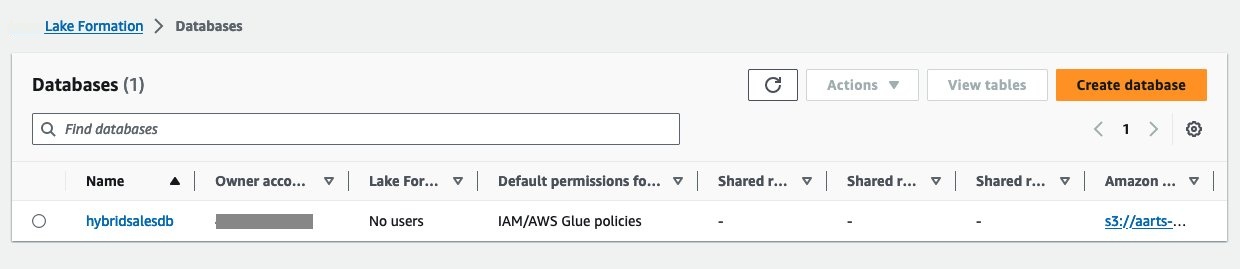
-
打开 Lake Formation 控制台。作为 Lake Formation 管理员,您应该看到来自消费者账户的共享数据库和表。
-
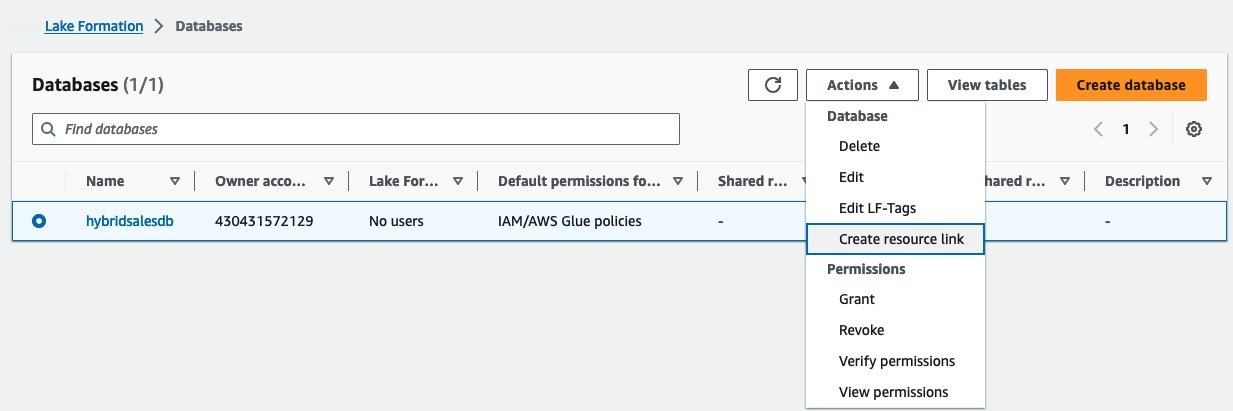
从左侧导航栏
的数据目录
中选择
数据库
。选择数据库
hybridsalesdb上的单选按钮, 然后 从 “ 操作 ” 下拉菜单中选择 “ 创建资源链接 ”。
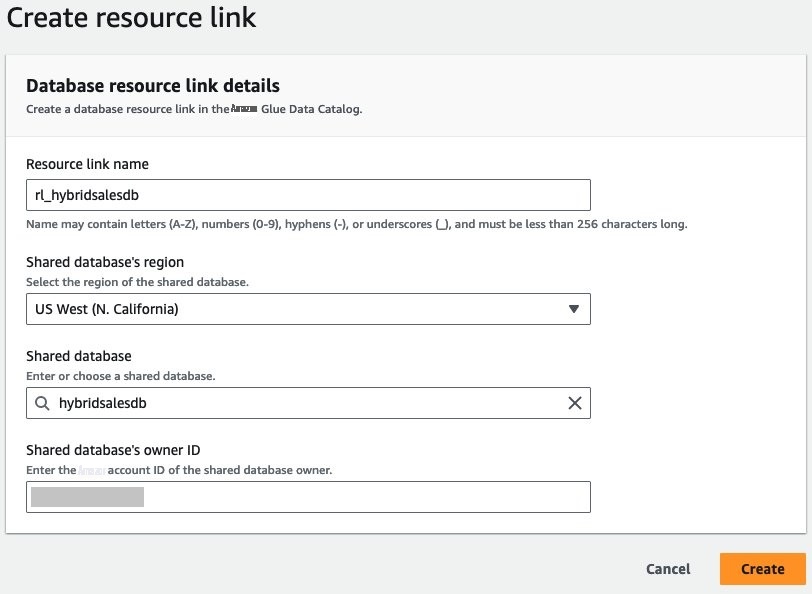
-
输入
rl_hybridsalesdb作为资源链接的名称,其余选项保持不变。选择 “ 创建 ” 。
-
选择
rl_hybridsalesdb 的单选按钮。 从 “ 操作 ” 下 拉菜单中选择 “ 授予 ”。
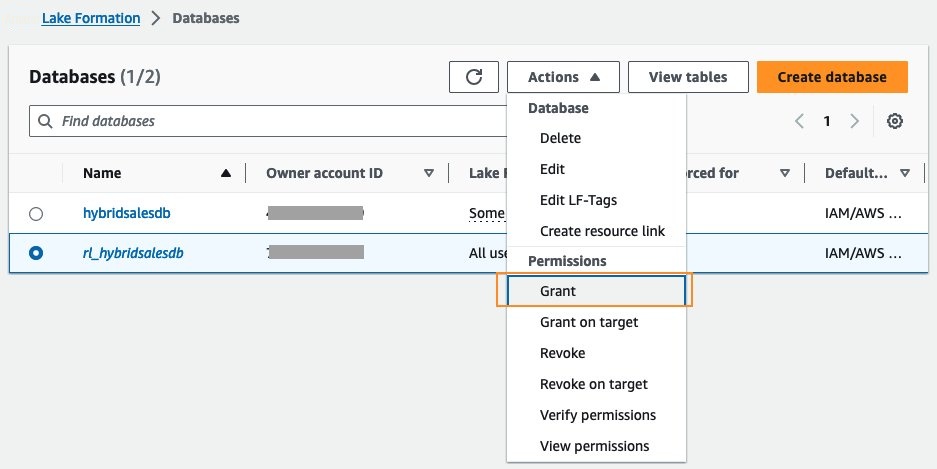
-
向
数据分析师授予资源链接的 描述 权限。

-
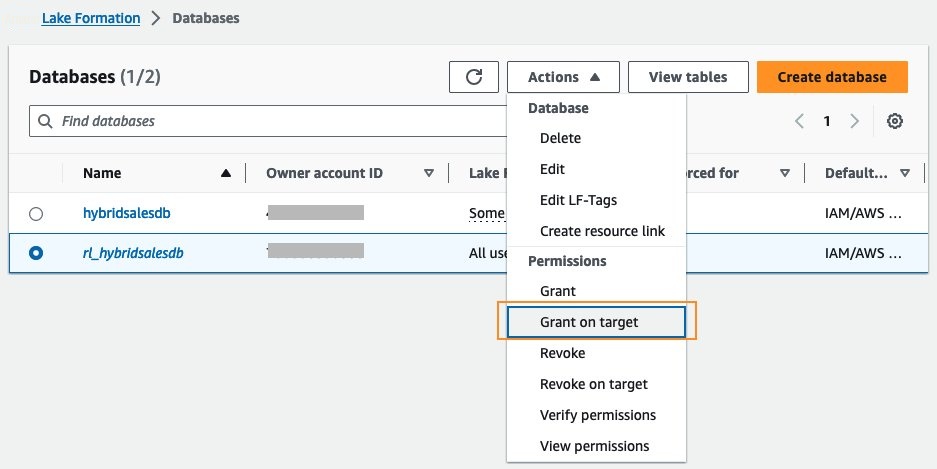
同样, 从左侧导航栏中 “
目录
” 下的 “
数据库
” 中选择
rl_hybridsalesdb上的单选按钮 。从 “ 操作 ” 下 拉菜单 中选择 “向 目标 授权 ”。
-
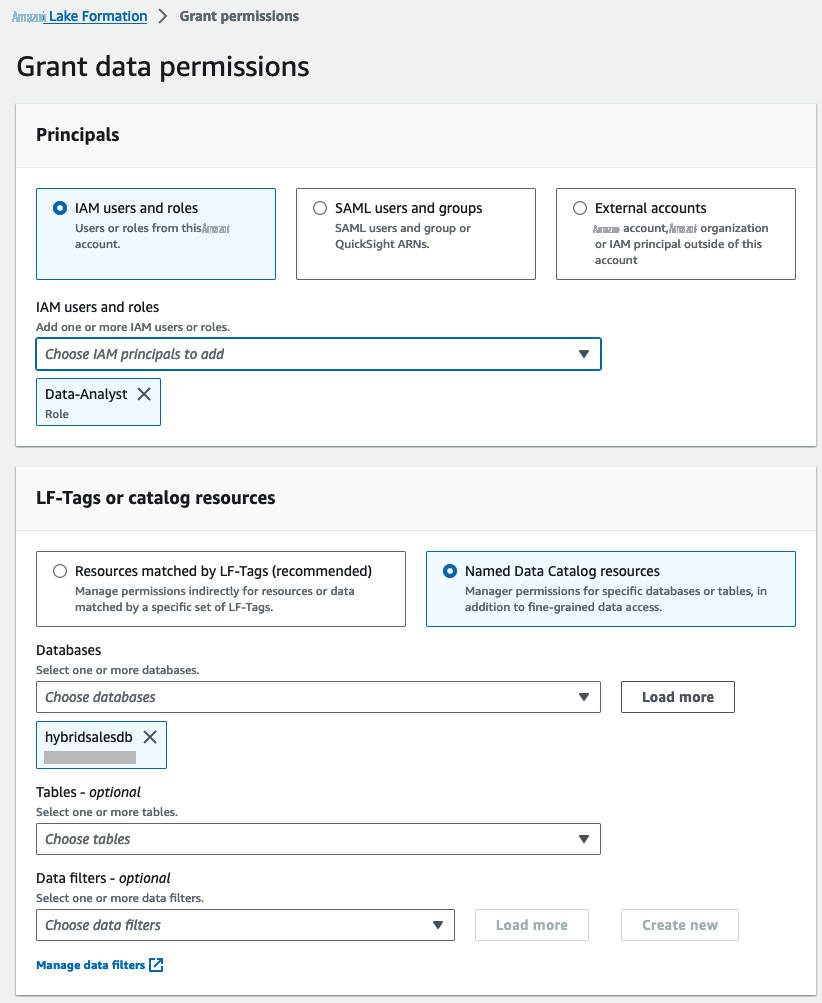
为 IAM 用户和角色选择 Data-Analys t,保留已经选择的数据库 hybridsalesdb。
-
在 “
数据库权限” 下选择 “
描述
”
。在
混合访问模式
下,选中 “
使湖组建权限立即生效
” 复选框 。选择 “
授予
” 。
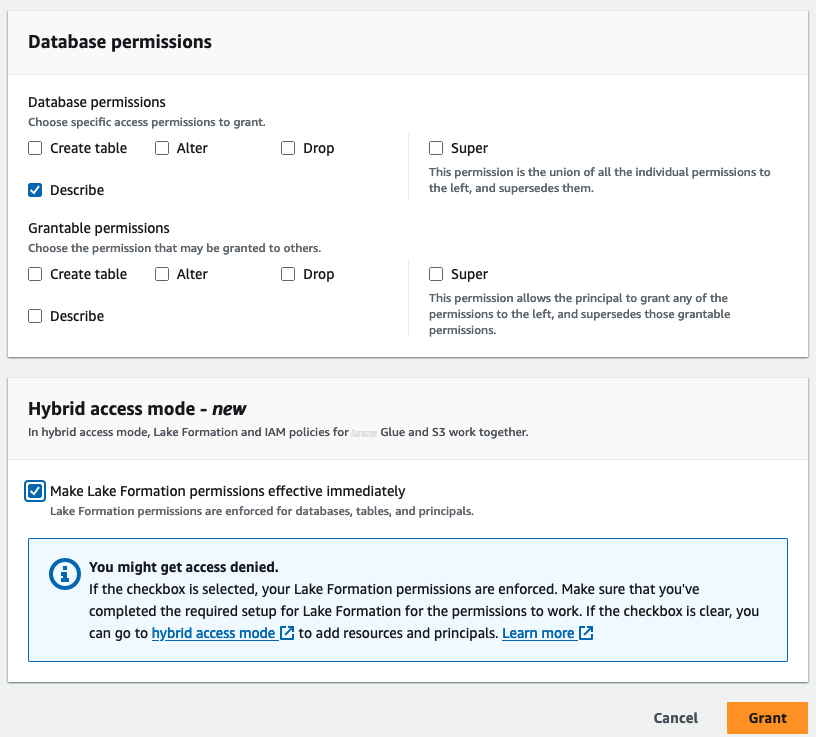
-
从左侧导航栏中 “
目录
” 下的 “
数据库
” 中选择
rl_hybridsalesdb上的单选按钮 。从 “ 操作 ” 下 拉菜单 中选择 “向 目标 授权 ”。 -
为 IAM 用户和角色选择
数据分析师。选择 hybridsalesdb 数据库的所有表。在 “ 表格权限 ” 下选择 “选择 ” 。 -
在
混合访问模式
下,选中 “
使湖组建权限立即生效
” 复选框 。
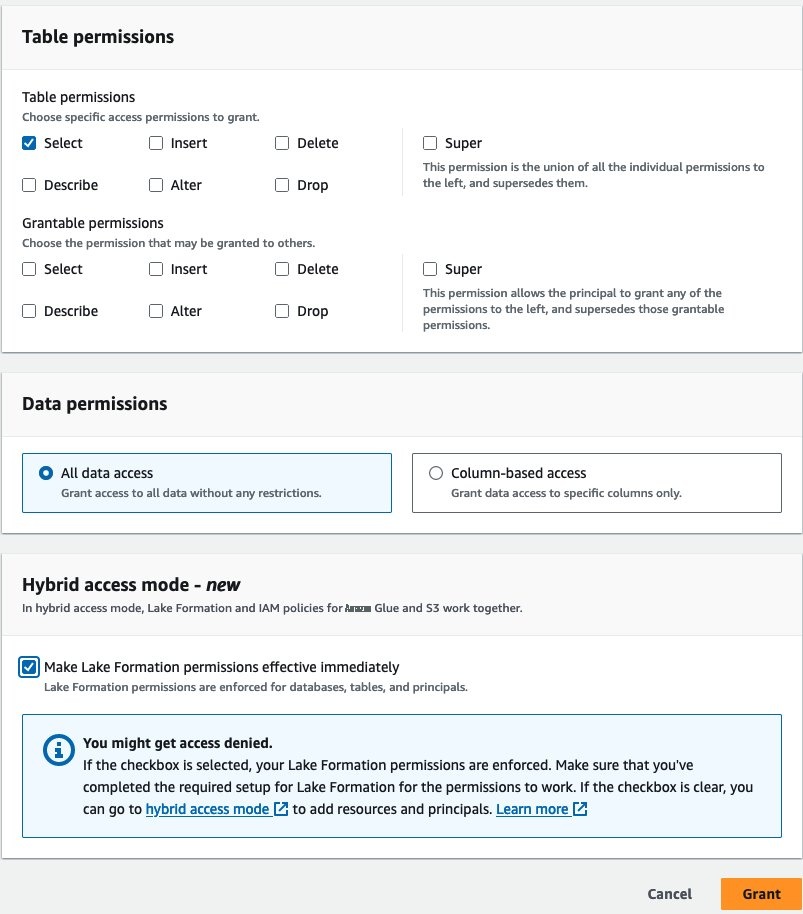
-
通过左侧导航栏上的数据
湖权限 选项卡查看和验证授予 数据分析师的权限
。
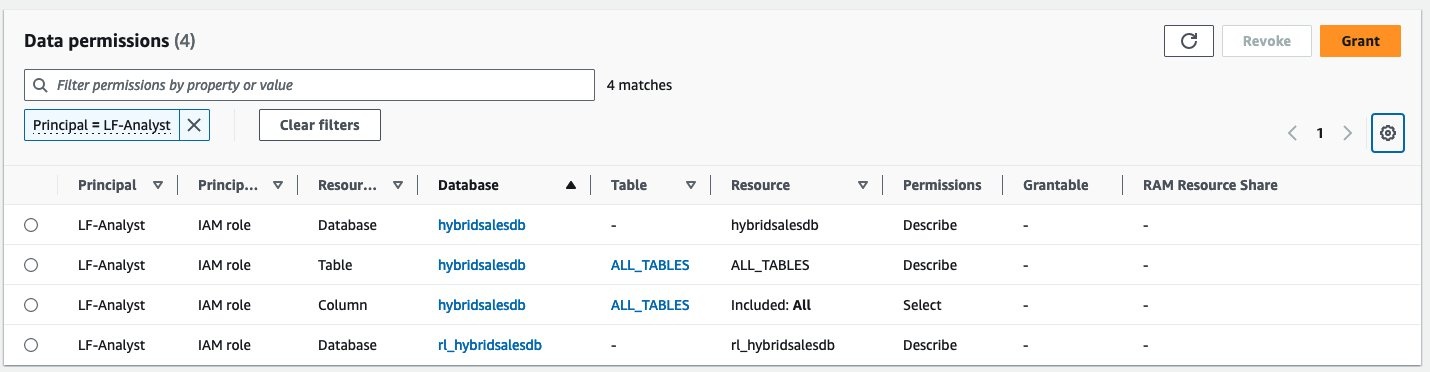
- 以 Lake Formation 管理员角色登出。
以数据分析师身份验证湖泊形成权限
-
以
数据分析师身份重新登录控制台。 -
打开雅典娜控制台。如果您是首次使用 Athena,请按照
指定查询结果位置中所述设置您的 S3 存储桶的查询结果位置 。-
在
查询编辑器
页面
的数据下,为数据
源选择
AWSDataDatalog。 对于 表格 ,选择任意表格名称旁边的三个点。选择 “ 预览表 ” 以运行查询。
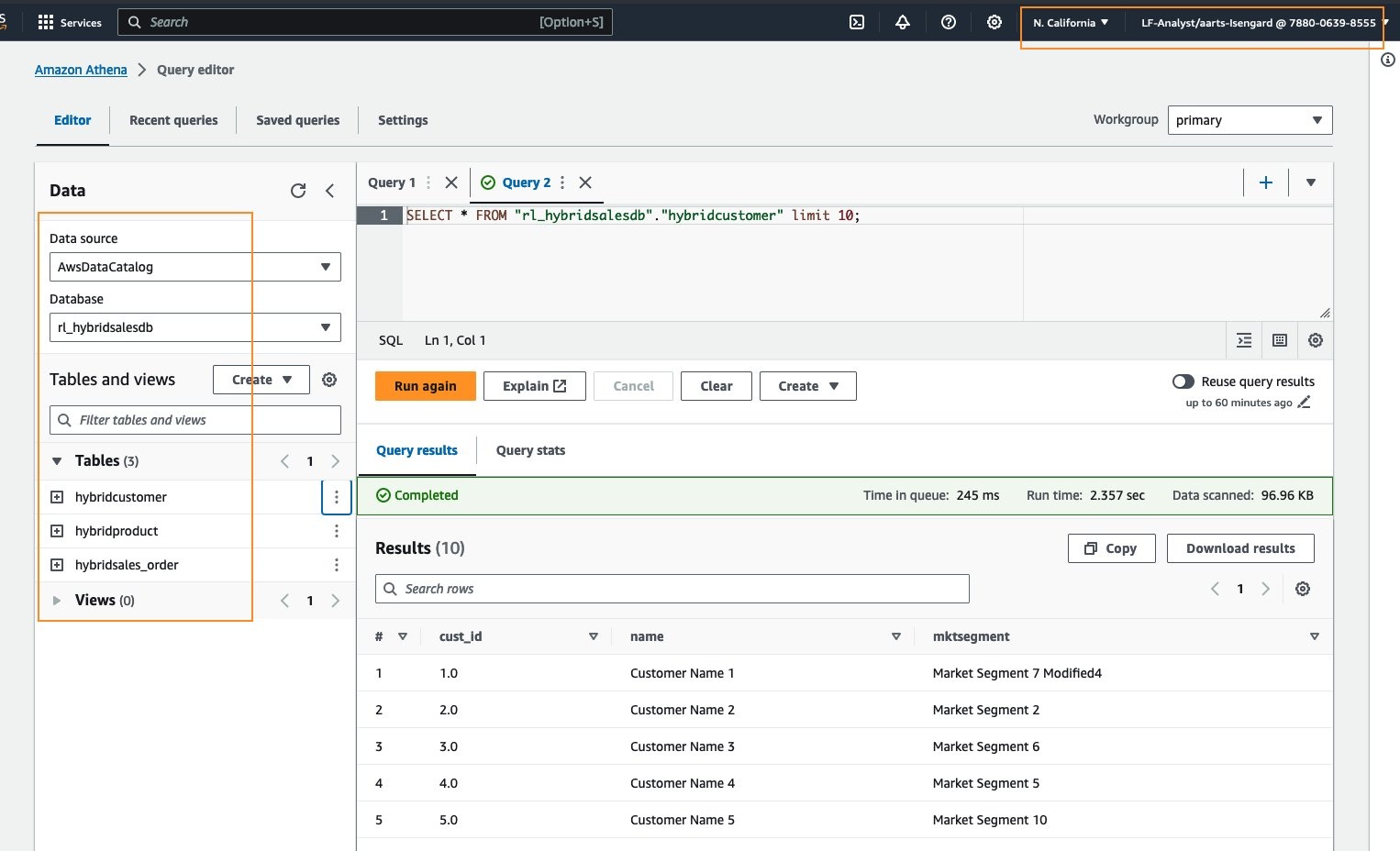
-
在
查询编辑器
页面
的数据下,为数据
源选择
- 以数据分析师身份登录。
验证数据工程师的 IAM 和 S3 权限
-
以
数据工程师身份重新登录控制台。 - 使用与场景 1 相同的步骤,通过在 亚马逊云科技 Glue Studio 中运行 亚马逊云科技 Glue ETL 脚本来验证 IAM 和 S3 的访问权限。
您已向新角色
数据分析师
添加了 Lake Formation 权限 ,而无需中断跨账户共享用例 对
数据工程师
的现有 IAM 和 S3 访问权限。
清理
如果您在本博客文章中使用了 S3 中的示例数据集,我们建议您移除数据库中数据分析师角色和跨账户授予的相关 Lake Formation 权限。您还可以移除混合访问模式选择加入并从 Lake Formation 中删除 S3 存储桶注册。删除生产者和消费者账户的所有 Lake Formation 权限后,您可以删除数据分析师和数据工程师 IAM 角色。
注意事项
目前,只有 Lake Formation 管理员角色可以选择让其他用户使用资源的 Lake Formation 权限,因为使用 Lake Formation 或 IAM 和 S3 权限选择用户访问权限是一项管理任务,需要充分了解您的组织数据访问设置。此外,您可以仅使用命名资源方法授予权限并同时选择加入,而不是 LF-tags。如果您使用 LF 标签来授予权限,我们建议您在授予权限后使用左侧导航栏上的
混合访问模式
选项选择加入(或使用 亚马逊云科技 开发工具包或 亚马逊云科技 CLI 的等效的
createLakeformationOptin ()
API)作为后续步骤。
结论
在这篇博客文章中,我们介绍了为数据目录设置混合访问模式的步骤。您学习了如何有选择地让用户加入 Lake Formation 权限模型。通过 IAM 和 S3 权限进行访问的用户可以继续不受干扰地进行访问。您可以使用 Lake Formation 添加对数据目录表的细粒度访问权限,使您的业务分析师能够使用亚马逊 Athena 和亚马逊 Redshift Spectrum 进行查询,而您的数据科学家则可以使用 Amazon Sagemaker 浏览相同的数据。数据工程师可以继续使用他们对相同数据的 IAM 和 S3 权限,使用 Amazon EMR 和 亚马逊云科技 Glue 运行工作负载。数据目录的混合访问模式支持对数据进行各种分析用例,而无需重复数据。
要开始使用,请参阅
作者简介
 Aarthi Srinivasan
是 亚马逊云科技 Lake Formation 的高级大数据架构师。她喜欢为 亚马逊云科技 客户和合作伙伴构建数据湖解决方案。不使用键盘时,她会探索最新的科学和技术趋势,并与家人共度时光。
Aarthi Srinivasan
是 亚马逊云科技 Lake Formation 的高级大数据架构师。她喜欢为 亚马逊云科技 客户和合作伙伴构建数据湖解决方案。不使用键盘时,她会探索最新的科学和技术趋势,并与家人共度时光。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。