我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 Kinesis Data Firehose 将丰富的物联网数据摄入亚马逊 S3
简介
将数据从物联网 (IoT) 设备发送到数据湖时,您可能需要在云中使用额外的元数据来丰富设备数据负载,以进行进一步的数据处理和可视化。这些数据可能不存在于设备负载中有多种原因,例如在有限的带宽环境中最大限度地减少设备负载,或者使用云中的业务输入对其进行修改。例如,工厂车间的一台机器可能会在白天分配给不同的操作员。这个可变的业务数据将存储在数据库中。在数据湖中,您可能需要将这些信息与负载一起存储。
在这篇博客文章中,您将学习如何近乎实时地将丰富的 IoT 数据提取到数据湖中。
先决条件
- 一个 亚马逊云科技 账户
-
亚马逊云科技 命令行接口 (亚马逊云科技 CLI)。有关配置,请参阅 亚马逊云科技 CLI
快速设置 。
用例定义
假设在您的物流公司中,您的集装箱配备了支持传感器的物联网设备。将集装箱装入船舶时,集装箱编号与船舶编号相关联。您需要将带有船舶 ID 的 IoT 设备负载存储在数据湖中。
在这样的用例中,传感器有效载荷来自连接到容器的物联网设备。但是,相关的船舶编号仅存储在元数据存储中。因此,在将有效载荷放入数据湖之前,必须使用船舶 ID 进行丰富。
解决方案架构
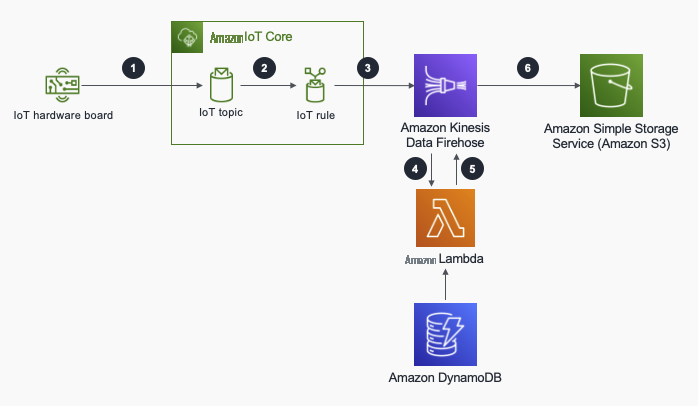
在架构图中,
-
物联网设备将有效负载传输到
亚马逊云科技 IoT Core 消息代理到特定的 MQTT 主题 device/d ata/DEVICE_ID。 亚马逊云科技 IoT Core 消息代理允许设备使用支持的协议发布和订阅消息。 -
当 A
WS IoT 规则 的主题中有负载时,就会触发。在本用例中,它使用亚马逊 Kinesis Data Firehose 操作进行了配置。您可以使用 亚马逊云科技 IoT 规则与 亚马逊云科技 服务进行交互,方法是在特定 MQTT 主题中有消息时调用这些服务,也可以直接使用 Basic Ingest 功能。 -
Amazon Kinesis Data Firehose 会先缓冲设备有效负载,然后再根据大小或时间(以先发生者为准)将其交付到数据存储。Kinesis Data Firehose 将实时流数据传输到目的地进行存储或处理。 -
一旦缓冲区达到大小或时间阈值,Kinesis Data Firehose 就会调用
亚马逊云科技 Lam bda 函数,使用从 Amazon DynamoDB 中检索的元数据批量丰富设备负载亚马逊云科技 L ambda 是一项 无服务器计算服务,可为任何类型的应用程序运行您的代码。Amazon DynamoDB 是一个完全托管的 NoSQL 数据库,可提供快速性能。 - 充实的有效载荷将返回到 Kinesis Data Firehose,然后运送到目的地。
-
丰富的有效负载作为目标放入
亚马逊简单存储服务(Amazon S3) 存储桶中。Amazon S3 是一种对象存储服务,可为一系列用例存储任意数量的数据。
亚马逊云科技 CloudFormation 模板
从
亚马逊云科技 CloudFormation 模板部署了运行此示例用例所需的所有资源。让我们仔细看看 亚马逊云科技 IoT 规则、Kinesis Data Firehose 和 亚马逊云科技 Lambda 函数资源。
亚马逊云科技 物联网规则资源
IoTToFirehoseRule:
Type: AWS::IoT::TopicRule
Properties:
TopicRulePayload:
Actions:
-
Firehose:
RoleArn: !GetAtt IoTFirehosePutRecordRole.Arn
DeliveryStreamName: !Ref FirehoseDeliveryStream
Separator: "\n"
AwsIotSqlVersion: ‘2016-03-23’
Description: This rule logs IoT payloads to S3 Bucket by aggregating in Kinesis Firehose.
RuleDisabled: false
Sql: !Ref IotKinesisRuleSQL亚马逊云科技 IoT 规则采用 SQL 参数,该参数定义了用于触发规则和从负载中提取数据的物联网主题。
- 在示例中,默认情况下,SQL 参数设置为 SELECT*,主题 (3) 设置为 containerId 来自 “设备/数据/+”。SELECT* 表示整个负载保持原样,ContainerId 由 MQTT 主题中的第二项生成并包含在负载中。
- 来自 “device/data/+” 描述了将触发 亚马逊云科技 IoT 规则的物联网主题。+ 是 MQTT 主题的通配符,物联网设备会将数据有效载荷发布到设备/数据/设备_ID 主题以触发此规则。
亚马逊云科技 IoT 规则还定义了操作。在示例中,您可以看到一个 Kinesis Data Fire
Kinesis Data Firehose 交付流资源
FirehoseDeliveryStream:
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
ExtendedS3DestinationConfiguration:
BucketARN: !GetAtt IoTLogBucket.Arn
BufferingHints:
IntervalInSeconds: 60
SizeInMBs: 1
Prefix: device-data/
RoleARN: !GetAtt FirehosePutS3Role.Arn
ProcessingConfiguration:
Enabled: true
Processors:
- Type: Lambda
Parameters:
- ParameterName: LambdaArn
ParameterValue: !Sub '${FirehoseTransformLambda.Arn}:$LATEST'
- ParameterName: RoleArn
ParameterValue: !GetAtt FirehoseLambdaInvokeRole.Arn
Kinesis Data Firehose 传送流必须定义传输流的目的地。它支持不同类型的目的地。您可以在本
示例交付流资源定义了以下属性:
- BucketArn:用于存储聚合数据的目标存储桶。目标存储桶由 CloudFormation 堆栈创建。
- bufferingHints:数据缓冲的大小和时间阈值。在此示例中,它们分别设置为 1MB 和 60 秒,以便更快地查看结果。可以根据业务需求进行调整。将这些阈值保持在较低水平将导致更频繁地调用 Lambda 函数。如果阈值很高,则数据被提取到数据存储的频率会降低,因此,需要时间才能看到数据存储中的最新数据。
-
前缀:创建的对象将置于此前缀下。默认情况下,Kinesis Data Firehose 会根据时间戳对数据进行分区。在此示例中,对象将放在 device-data/yyyy/mm/dd/HH 文件夹下。Kinesis Data Firehose 具有用于数据分区的高级功能,例如动态分区。查询数据湖时,数据的分区很重要。例如,如果您需要使用 Amazon Athena 按设备查询数据,则仅扫描相关设备 ID 的分区将显著减少扫描时间和成本。您可以在本
文档 中找到有关分区的详细信息。 - RoLearn:这是 IAM 角色,它向 Kinesis Data Firehose 授予 PutObject 权限,使其能够将聚合的数据放入亚马逊 S3 存储桶。
-
处理配置:如用例中所述,转换 Lambda 函数将使用元数据丰富物联网数据。处理配置定义了处理器,该处理器是示例中的 Lambda 函数。对于每批数据,Kinesis Data Firehose 将调用此 Lambda 函数来转换数据。您可以在本
文档 中阅读有关数据处理的更多信息 。
转换 Lambda 函数
正如你在以下 Python 代码中看到的那样,Kinesis Data Firehose 会返回一批记录,其中每条记录都是来自物联网设备的有效载荷。首先,对 base64 编码的有效载荷数据进行解码。然后,相应的船舶编号来自基于容器 ID 的 DynamoDB 表。有效载荷中包含飞船 ID 并编码回 base64。最后,记录列表返回到 Kinesis Data Firehose。
Kinesis Data Firehose 收到记录后,它会将它们作为聚合文件放入亚马逊 S3 存储桶中。
import os
import boto3
import json
import base64
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(os.environ['METADATA_TABLE'])
records = []
def function_handler(event, context):
for record in event["records"]:
# Get data field of the record in json format. It is a base64 encoded string.
json_data = json.loads(base64.b64decode(record["data"]))
container_id = json_data["containerId"]
# Get corresponding shipId from the DynamoDB table
res = table.get_item(Key={'containerId': container_id})
ddb_item = res["Item"]
ship_id = ddb_item["shipId"]
# Append shipId to the actual record data
enriched_data = json_data
enriched_data["shipId"] = ship_id
# Encode the enriched record to base64
json_string = json.dumps(enriched_data).encode("ascii")
b64_encoded_data = base64.b64encode(json_string).decode("ascii")
# Create a record with enriched data and return back to Firehose
rec = {'recordId': record["recordId"], 'result': 'Ok', 'data': b64_encoded_data}
records.append(rec)
return {'records': records}部署
在终端中运行以下命令来部署堆栈。
aws cloudformation deploy --stack-name IoTKinesisDataPath --template-file IoTKinesisDataPath.yml --parameter-overrides IotKinesisRuleSQL="SELECT *, topic(3) as containerId FROM 'device/data/+'" --capabilities CAPABILITY_NAMED_IAM部署完成后,在终端中运行以下命令以查看部署的输出。
aws cloudformation describe-stacks --stack-name IoTKinesisDataPath注意 iotLogs3BucketName、metadatableName 的输出参数。
正在测试
部署完成后,您需要做的第一件事是创建用于丰富数据的元数据项目。运行以下命令在 DynamoDB 表中创建项目。它将创建一个以 cont1 作为集装箱 ID,ship1 作为 shipID 的物品。将 iotkinesisdatapath-metadatable-Sample 参数替换为 CloudFormation 堆栈部署中的 DynamoDB 表 输出 参数。
aws dynamodb put-item --table-name IoTKinesisDataPath-MetadataTable-SAMPLE --item '{"containerId":{"S":"cont1"},"shipId":{"S":"ship1"}}'在现实场景中,设备将有效负载发布到特定的 MQTT 主题。在此示例中,您将使用 亚马逊云科技 CLI 向 MQTT 主题发布有效负载,而不是创建物联网设备。在终端中运行以下命令以发布示例数据负载 亚马逊云科技 IoT Core。注意命令的有效载荷字段,设备提供的唯一数据是动态数据。
aws iot-data publish --topic "device/data/cont1" --payload '{"temperature":20,"humidity":80,"latitude":0,"longitude":0}' --cli-binary-format raw-in-base64-out
现在,从
{“温度”:20,“湿度”:80,“纬度”:0,“经度”:0,“容器 ID”:“cont1”,“ShipID”:“ship1”}
故障排除
如果系统出现故障,以下资源可用于分析问题的根源。
要监控 亚马逊云科技 IoT Core 规则引擎,您需要启用
如果出现故障,Kinesis Data Firehose 将在 亚马逊云科技 物联网规则引擎操作中的设备数据前缀下创建一个处理失败的文件夹,转换 Lambda 函数或 Amazon S3 存储桶。失败的详细信息可以作为 json 对象读取。您可以在此
清理
要清理已创建的资源,请先清空 Amazon S3 存储桶。使用由 CloudFormation 堆栈部署 的存储 分区名称更改存储分区名称来运行以下命令。 重要:此命令将不可逆转地删除存储桶中的所有数据。
aws s3 rm s3://bucket-name --recursive然后,您可以通过在终端中运行以下命令来删除 CloudFormation 堆栈。
aws cloudformation delete-stack --stack-name IoTKinesisDataPath结论
在这篇博客中,您了解了一种常见模式,即使用元数据丰富 IoT 有效负载,并使用 亚马逊云科技 IoT 规则引擎和亚马逊 Kinesis Data Firehose 交付流,经济高效地将数据存储在数据湖中。提议的解决方案和CloudFormation模板可用作可扩展物联网数据采集架构的基准。
你可以进一步阅读有关

Ozan Chihangir
Ozan 是 亚马逊云科技 的原型设计工程师。他帮助客户在云端为其新兴技术项目构建创新解决方案。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。