我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
通过亚马逊 OpenSearch Service 的背压和准入控制提高弹性
现在,我们很高兴为 OpenSearch 服务推出搜索反压和基于 CPU 的准入控制,这进一步增强了集群的弹性。这些改进适用于所有 OpenSearch 1.3 或更高版本。
搜索背压
背压可防止系统因工作而不堪重负。它通过控制流量速率或减少过多的负载来做到这一点,以防止崩溃和数据丢失,提高性能并避免系统完全故障。
搜索反压是一种在节点受到胁迫时识别和取消正在运行的资源密集型搜索请求的机制。它可以有效应对资源使用率异常高的搜索工作负载(例如复杂的查询、慢的查询、大量点击或大量聚合),否则这些工作负载可能会导致节点崩溃并影响集群的运行状况。
Search Backpressure 建立在任务资源跟踪框架之上,该框架提供了易于使用的 API 来监控每个任务的资源使用情况。Search Backpressure 使用后台线程定期测量节点的资源使用情况,并根据 CPU 时间、堆分配和经过的时间等因素为每个正在运行的搜索任务分配取消分数。取消分数越高对应资源密集型搜索请求。搜索请求按取消分数的降序取消,以快速恢复节点,但取消次数有速率限制,以避免浪费工作。
下图说明了 “搜索背压” 工作流程。
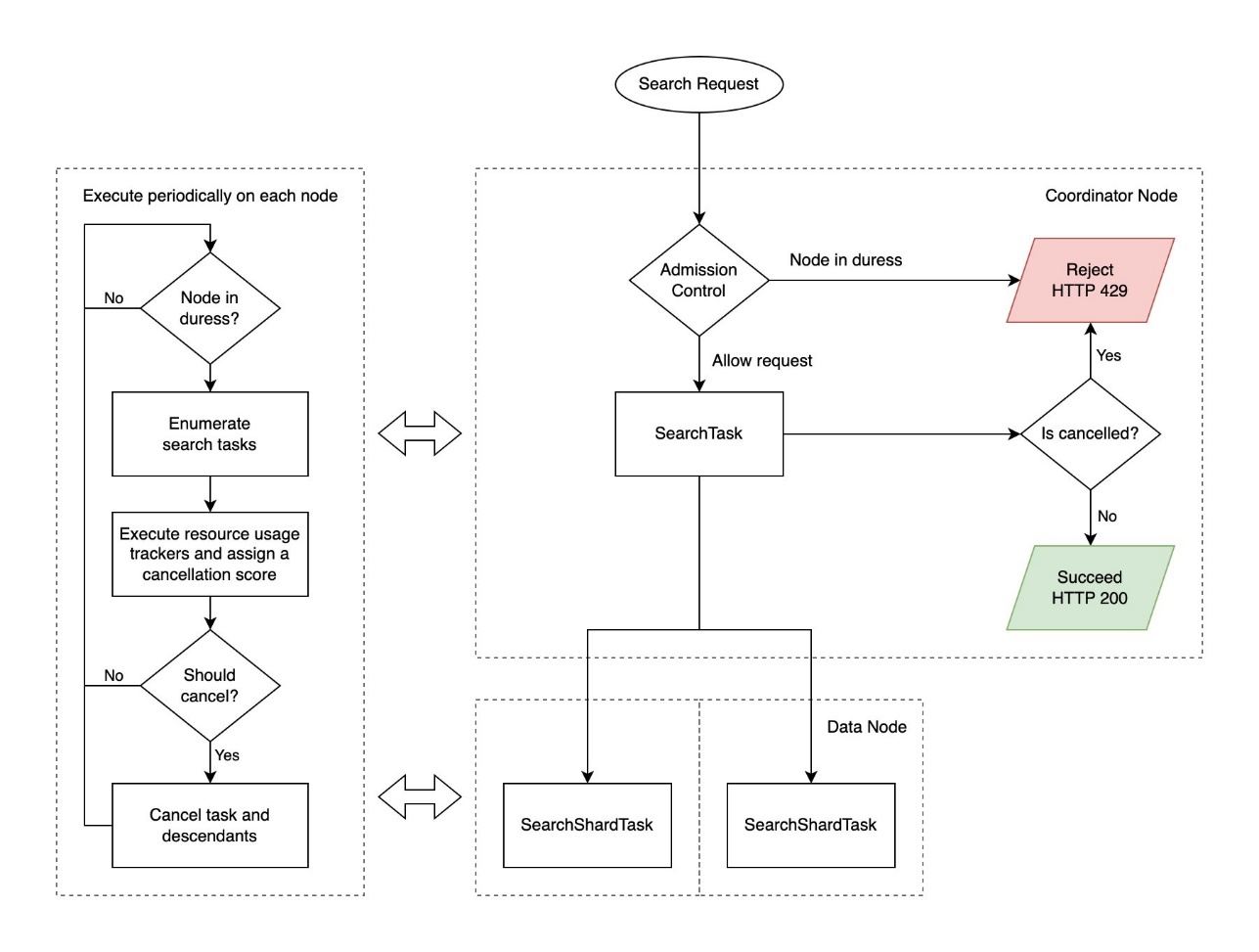
搜索请求取消后返回 HTTP 429 “请求过多” 状态码。如果只有部分分片失败并且允许部分结果,OpenSearch 会返回部分结果。参见以下代码:
监控搜索背压
你可以使用节点统计 API 监控详细的搜索反压状态:
- searchTaskC anceld — 取消 协调节点的次数
- searchShardTaskCanceled — 取消 数据节点的次数
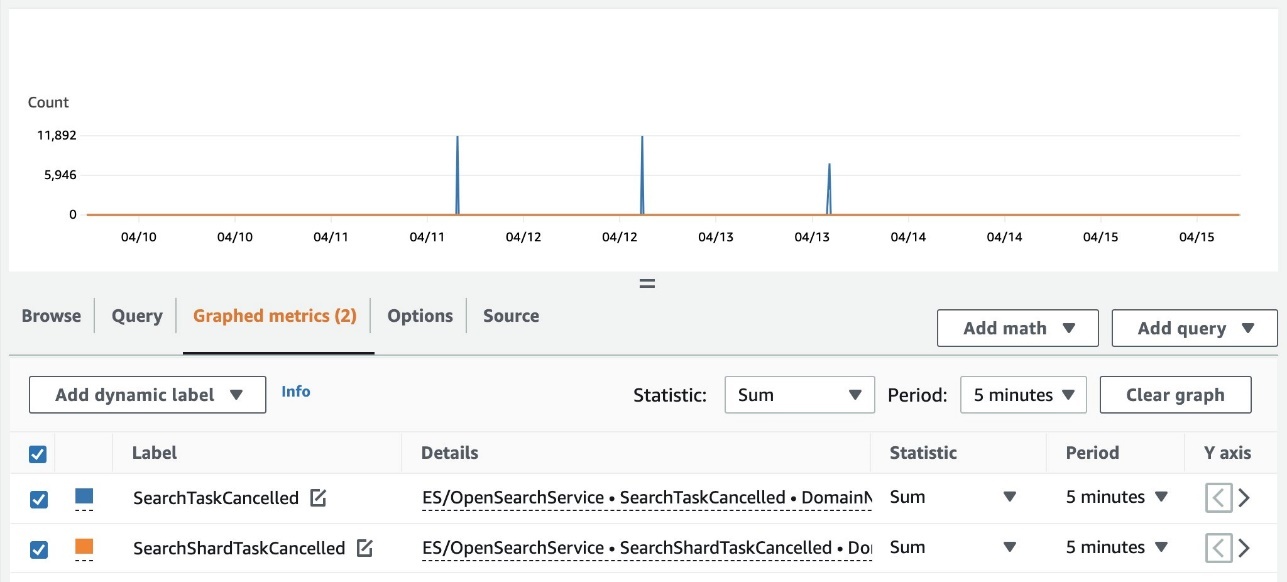
以下屏幕截图显示了在 CloudWatch 控制台上跟踪这些指标的示例。
基于 CPU 的准入控制
准入控制是一种门控机制,可根据节点的当前容量主动限制对节点的请求数量,以应对自然增长和流量激增。
除了 JVM 内存压力和请求大小阈值外,它现在还监视每个节点的滚动平均 CPU 使用率,以拒绝传入的 _searc
h 和
k 请求。它可以防止过多的请求使节点不堪重负,从而导致热点、性能问题、请求超时和其他级联故障。过多的请求在被拒绝时返回 HTTP 429 “请求过多” 状态码。
_
bul
处理 HTTP 429 错误
如果您向节点发送过多的流量,则会收到 HTTP 429 错误。这表示集群资源不足、资源密集型搜索请求或工作负载意外激增。
Search Backpressure 提供了拒绝的原因,这有助于微调资源密集型搜索请求。对于流量高峰,我们建议使用指数退避和抖动来进行客户端重试。
您也可以按照以下故障排除指南来调试过多的拒绝:
-
如何解决 OpenSearch 服务中的搜索或写入拒绝问题? -
如何解决我的亚马逊 OpenSearch Service 集群中出现的搜索延迟峰值?
结论
Search Backpressure 是一种缓解过度负载的被动机制,而准入控制是一种主动机制,用于限制对超出其容量的节点的请求数量。两者协同工作以提高 OpenSearch 集群的整体弹性。
作者简介
 Ketan Verma
是一名高级软件开发人员,负责亚马逊 OpenSearch Service 的开发。他热衷于构建大规模分布式系统、提高性能以及用简单的抽象来简化复杂的想法。工作之余,他喜欢阅读和提高自己的家庭咖啡师技能。
Ketan Verma
是一名高级软件开发人员,负责亚马逊 OpenSearch Service 的开发。他热衷于构建大规模分布式系统、提高性能以及用简单的抽象来简化复杂的想法。工作之余,他喜欢阅读和提高自己的家庭咖啡师技能。
 Suresh N S
是一名高级软件开发人员,负责亚马逊 OpenSearch Service 的开发。他热衷于解决大规模分布式系统中的问题。
Suresh N S
是一名高级软件开发人员,负责亚马逊 OpenSearch Service 的开发。他热衷于解决大规模分布式系统中的问题。
 Pritkumar Ladani 是一名 SDE-2,正在亚马逊
OpenSearch Service 上工作。他喜欢为开源软件开发做出贡献,并且对分布式系统充满热情。他是一名业余羽毛球运动员,喜欢徒步旅行。
Pritkumar Ladani 是一名 SDE-2,正在亚马逊
OpenSearch Service 上工作。他喜欢为开源软件开发做出贡献,并且对分布式系统充满热情。他是一名业余羽毛球运动员,喜欢徒步旅行。
 布赫塔瓦尔·汗
是亚马逊 OpenSearch Service 的首席工程师。他对构建分布式和自主系统感兴趣。他是一名维护者,也是 OpenSearch 的积极贡献者。
布赫塔瓦尔·汗
是亚马逊 OpenSearch Service 的首席工程师。他对构建分布式和自主系统感兴趣。他是一名维护者,也是 OpenSearch 的积极贡献者。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。