我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
通过在 EKS 上的 Amazon EMR 上进行垂直自动扩展,提高可靠性并降低 Apache Spark 工作负载的成本
Apache Spark 允许您配置任务将使用的内存和 vCPU 内核量。但是,调整这些值是一个手动过程,可能很复杂且存在陷阱。例如,分配的内存太少会导致内存不足异常和作业可靠性差。另一方面,过多会导致闲置资源的超支、较差的集群利用率和高成本。此外,由于缺乏对未来需求的可见性,很难为交互式分析等某些用例调整这些设置的大小。对于经常性作业,考虑到负载模式的变化(例如外部季节性因素),保持这些设置处于最新状态仍然是一项挑战。
为了解决这个问题,EKS 上的 Amazon EMR 最近宣布支持
垂直自动缩放与现有自动缩放解决方案的对比
垂直自动扩展是对现有的 Spark 自动扩缩解决方案(例如动态资源分配 (DRA) 和 Kubernetes 自动扩展解决方案(如 Karpenter)的补充。
诸如 DRA 之类的功能通常在水平轴上运行,其中负载的增加会导致处理负载的 Kubernetes 容器数量增加。就Spark而言,这会导致数据被其他执行器处理。启用 DRA 后,Spark 从初始执行器数量开始,如果发现有任务在等待执行器运行,则会将其扩大。DRA 在 Pod 级别运行,需要底层集群级自动扩展器(例如 Karpenter)来引入更多节点或缩小未使用的节点,以响应这些 Pod 被创建和删除。
但是,对于给定的数据配置文件和查询计划,有时无法轻易更改并行度和执行者的数量。例如,如果你尝试联接两个存储已按联接键排序和分区的数据的表,Spark 可以通过使用固定数量的执行器(等于源数据中存储桶的数量)来高效地联接数据。由于无法更改执行者的数量,垂直自动扩展可以通过提供更多资源或在执行者级别缩减未使用的资源来提供帮助。这有几个优点:
- 如果 Pod 大小最佳,Kubernetes 调度器可以高效地将更多 Pod 打包到单个节点中,从而更好地利用底层集群。
-
E
KS uplift 上的 亚马逊 EMR 是根据 Kubernetes Pod 消耗的 vCPU 和内存资源收费的。这意味着最佳大小的容器更便宜。
垂直自动缩放的工作原理
在提交 EKS 作业的 EMR 时,您可以选择使用垂直自动缩放功能。启用后,它会使用 VPA 来跟踪您的 EMR Spark 作业的资源利用率,并根据这些数据得出 Spark 执行器容器的资源分配建议。这些数据从 Kubernetes 指标服务器中获取,输入到 VPA 构建的统计模型中,以便生成建议。
当属于启用了垂直自动缩放的作业的新执行器容器启动时,它们会根据此建议自动缩放,而忽略了通过 Spark 的执行器内存配置(由 spark.executor.memory Spark 设置控制)完成的通常大小调整。
垂直自动缩放不会影响正在运行的 pod,因为从 Kubernetes 版本 1.26(截至撰写
数据跟踪和建议
回顾一下,垂直自动扩展使用 VPA 来跟踪 EMR 任务的资源利用率。要深入了解这些功能,请参阅 VPA
器容器容器_memory_working_set_bytes
指标。
实时指标数据从 Kubernetes 指标服务器获取。默认情况下,垂直自动缩放会跟踪每个 Pod 的峰值内存工作集大小,并根据峰值的 p90 提出建议,并增加 40% 的安全余量。它还监听 Pod 事件(例如 OOM 事件)并对这些事件做出反应。对于 OOM 事件,VPA 会自动将推荐的资源分配增加 20%。
统计模型也代表历史资源利用率数据,作为自定义资源对象存储在您的 EKS 集群上。这意味着删除这些对象也会清除旧的建议。
通过工作签名定制推荐
垂直自动扩展的主要用例之一是聚合不同运行的 EMR Spark 作业的使用数据,以得出资源建议。为此,您需要提供工作签名。这可以是您在提交作业时配置的唯一名称或标识符。如果您的作业按固定的时间表(例如每天或每周)重复,则务必不要为该作业的每个新实例更改作业签名,以便 VPA 汇总和计算不同作业运行中的建议。
如果你认为不同的职位会有相似的资源概况,那么即使在不同的职位上,工作签名也可能相同。因此,您可以使用该签名将跟踪和资源建模结合起来,对您期望表现相似的不同作业。相反,如果作业行为在某个时间点发生变化,例如由于上游数据或查询模式的变化,则可以通过更改签名或删除该签名的 VPA 自定义资源(如本文后面所述),轻松清除旧推荐。
监控模式
您可以在实际不执行自动缩放的监控模式下使用垂直自动缩放。如果您的集群上有这样的设置,则会向 Prometheus 报告建议,并且您可以通过 Grafana 仪表板监控建议,并使用它来调试和手动更改资源分配。监控模式是默认模式,但您也可以在提交任务时覆盖和使用支持的自动缩放模式之一。 有关用法和入门指南,请参阅
通过 kubectl 监控垂直自动缩放
你可以使用 Kubernetes 命令行工具
kubectl
列出集群上的有效推荐,查看所有正在跟踪的作业签名,以及清除与不再相关的签名相关的资源。在本节中,我们提供了一些示例代码来演示列出、查询和删除推荐。
列出集群上的所有垂直自动扩展建议
你可以使用
kubectl
获取
verticalpodautoscaler
资源, 以便查看当前状态和建议。以下示例查询列出了您的 EKS 集群上当前处于活动状态的所有资源:
这会产生类似于以下内容的输出
查询和删除推荐
你也可以使用
kubectl
根据签名清除任务推荐。或者,您可以使用
--all
标志并跳过指定签名来清除集群上的所有资源。请注意,在这种情况下,你实际上要删除 EMR 垂直自动扩缩作业运行资源。这是由 EMR 管理的自定义资源,删除它会自动删除跟踪和存储推荐的关联 VPA 对象。参见以下代码:
你可以使用--al
l 和 --all-namespace 来删除所有
与垂直自动扩
缩相关的资源
通过 Prometheus 和 Grafana 监控垂直自动缩放
您可以使用 Prometheus 和 Grafana 来监控 EKS 集群上的垂直自动扩展功能。这包括查看针对不同任务签名的推荐、监控自动扩展功能等。对于此设置,我们假设已经使用官方 Helm 图表在您的 EKS 集群上安装了 Prometheus 和 Grafana。否则,请参阅 “在 A
修改 Prometheus 以收集垂直自动缩放指标
默认情况下,Prometheus 不跟踪垂直自动缩放指标。要启用此功能,您需要开始从集群上的 VPA 自定义资源对象收集指标。这可以通过使用以下
在这里,
您可以通过对新创建的自定义指标运行以下 Prometheus 查询来验证此设置是否正常运行:
-
kube_customresource_vpa_spark_rec_memory_target -
kube_customresource_vpa_spark_rec_memory_lower -
kube_customresource_vpa_spark_rec_memory_upper
它们代表启用了垂直自动缩放的 EMR Spark 作业的下限、上限和目标内存。可以使用与以下 Prometheus 查询类似的签名标签对查询进行分组或筛选:
使用 Grafana 可视化推荐和自动缩放功能
您可以通过将
结果按你的 Kubernetes 命名空间和作业签名进行分类。当你选择特定的命名空间和签名组合时,你会看到一个窗格。该窗格显示了属于所选签名的作业的垂直自动扩展建议与该作业的实际资源利用率和为该作业预配置的 Spark executor 内存量的比较。如果启用了自动扩展,则预期 Spark 执行器内存将跟踪推荐。但是,如果你处于监控模式,两者将不匹配,但你仍然可以在此仪表板上查看建议,或者使用它们来更好地了解工作的实际利用率和资源概况。
配置的内存、利用率和建议的示意图
为了更好地说明不同工作负载的垂直自动缩放行为和使用情况,我们对5次迭代执行了
监控模式
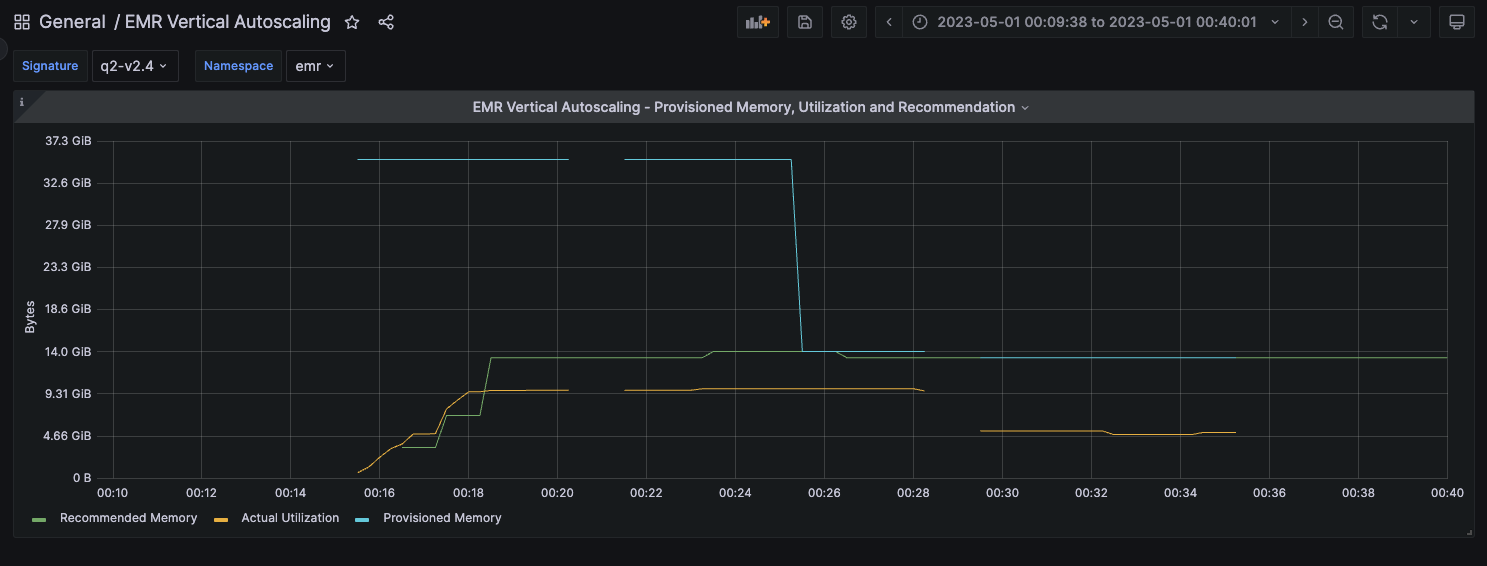
此特定作业被配置为使用 32GB 的执行器内存(图像中的蓝线)运行,但实际利用率徘徊在 10 GB 左右(黄线)。垂直自动缩放根据此次运行计算出大约 14 GB 的推荐值(绿线)。该建议基于实际利用率,并增加了安全余地。
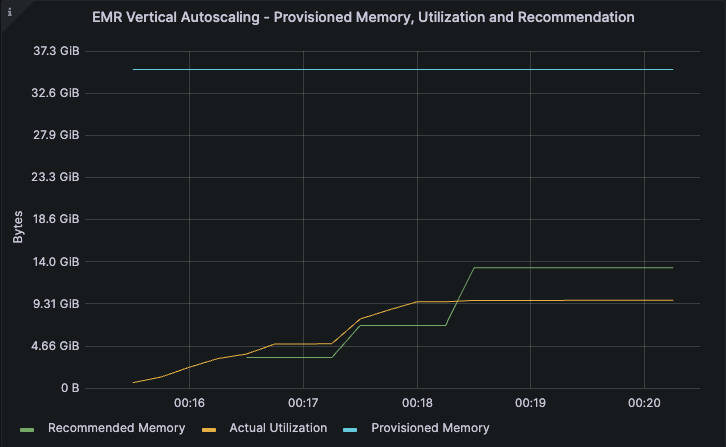
该作业的第二次迭代也在监控模式下运行,利用率和建议保持不变。
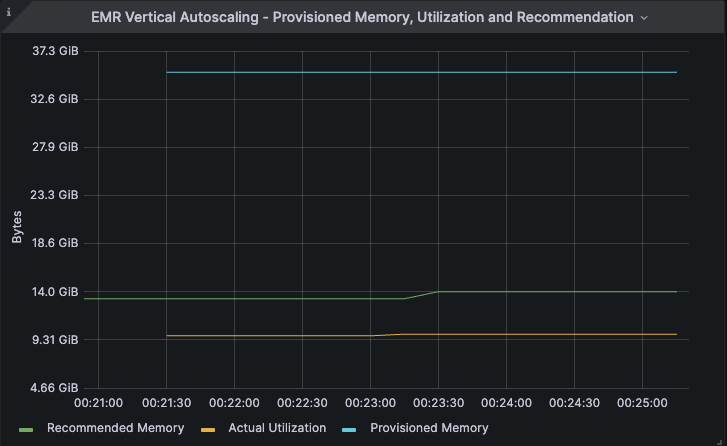
自动缩放模式
迭代 3 到 5 是在自动缩放模式下运行的。在这种情况下,配置的内存从 32GB 降至与建议值 14GB(蓝线)相匹配。
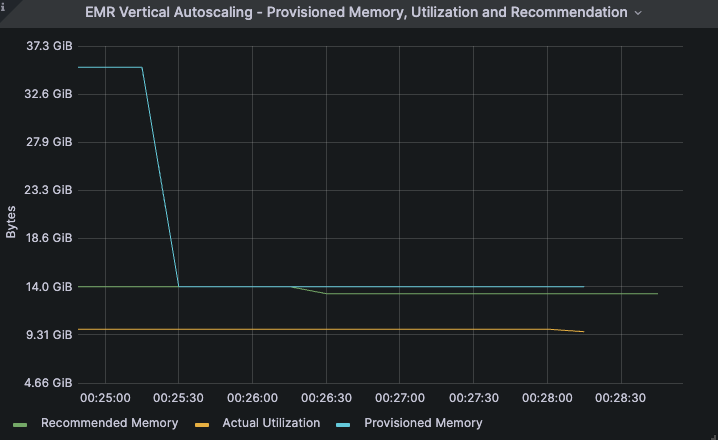
在本示例中,后续迭代的利用率和建议保持不变。此外,我们观察到,无论是否使用自动扩展,该任务的所有迭代都在大约 5 分钟内完成。此示例说明了成功地将作业的执行器内存分配缩减了大约 56%(从 32 GB 降至大约 14 GB),这也意味着作业的 EMR 内存提升成本同等降低,对作业性能没有影响。
自动 OOM 恢复
在前面的示例中,由于自动缩放,我们没有观察到任何 OOM 事件。在极少数情况下,自动缩放会导致 OOM 事件,通常应自动向上扩展作业。另一方面,如果启用了自动扩展功能的任务配置不足,因此遇到 OOM 事件,则垂直自动扩缩可以扩展资源以促进自动恢复。
在以下示例中,任务配置了 2.5 GB 的执行器内存,并在执行过程中遇到 OOM 异常。垂直自动缩放通过在重新启动失败的执行器时自动将其放大来响应 OOM 事件。如下图所示,当代表内存利用率的琥珀色线开始接近代表已配置内存的蓝线时,垂直自动缩放开始以增加为重新启动的执行器预置的内存量,从而可以在没有任何干预的情况下自动恢复并成功完成作业。在任务完成之前,推荐的内存已聚合到大约 5 GB。
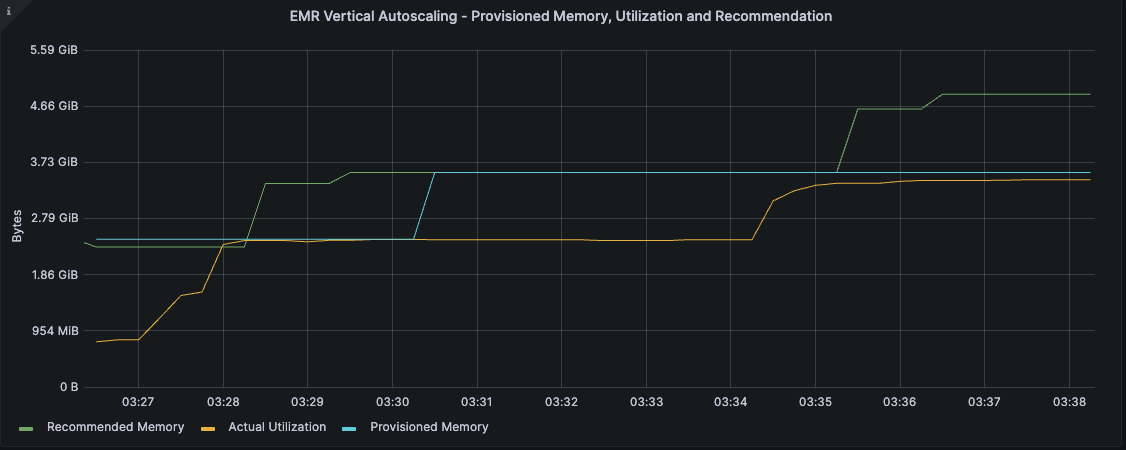
现在,所有具有相同签名的作业都将使用先前计算的推荐设置启动,从而防止从一开始就发生 OOM 事件。
清理
有关从集群中清理垂直自动扩展相关资源的信息,请参阅
结论
您可以使用垂直自动扩展来轻松监控 EKS 作业上一个或多个 EMR 的资源利用率,而不会对您的生产工作负载产生任何影响。你可以使用包括 Prometheus、Grafana 和 kubectl 在内的标准 Kubernetes 工具与集群上的垂直自动缩放进行交互和监控。您还可以使用根据作业需求得出的建议自动扩展 EMR Spark 作业,从而节省成本、优化集群利用率并增强应对内存不足错误的能力。 此外,您可以将其与现有的自动扩展机制(例如动态资源分配和Karpenter)结合使用,以轻松实现最佳 的垂直资源分配。 展望未来,当 Kubernetes 完全支持就地调整 Pod 大小时,垂直自动缩放将能够利用它无缝地向上或向下扩展您的 EMR 任务,进一步促进最佳成本和集群利用率。
作者简介

*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。