在这篇文章中,我将演示如何使用适用于适用于 Oracle 的
亚马逊关系数据库服务 (Amazon RDS) 上运行的工作负载的 Oracle 数据库内存选项在不影响在线事务处理 (OLTP)
的情况下提高实时分析和混合工作负载的性能。
对实时分析的需求要求分析查询与在线事务处理 (OLTP) 在专为事务处理而设计的同一个数据库上同时运行。诸如封装的EPR、CRM和HCM应用程序(例如Siebel、PeopleSoft和JD Edwards)之类的企业 OLTP 系统就是一些例子。索引、物化视图和 OLAP 多维数据集等其他对象是作为一种被动方法创建的,目的是改善分析工作负载性能的恶化,从而降低 OLTP 性能。索引越多,每次修改基础表时更新索引的开销就越大。这会导致内存争用增加和事务处理时间缩短,这在极其繁忙的 OLTP 系统中是一个瓶颈。
什么是 Oracle 数据库内存中?
Oracle 数据库将行存储在数据块中,每行的数据中包含与该块相关的列数据。此模式针对 OLTP 进行了优化,因为更新少量行中的所有列会导致修改少量块。另一方面,Analytics 访问的列较少,但跨行很多,通常会扫描整个数据集。如果我们使用行格式扫描多 TB 的堆组织表,但没有特定顺序,则结果集可能会分布在整个磁盘上的多个块中。将这些块提取到缓存所涉及的 I/O 可能会让人不知所措。使用列格式可以避免这种情况,这种格式可以访问所需的列并避免扫描不必要的数据。
Oracle 推出了
Oracle 数据库内存功能
,可在不牺牲 OLTP 性能的情况下将分析查询速度提高几个数量级。它在系统全局区域(也称为 SGA)中使用一个名为 In-Memory Area 的单独的基于列格式的
内存区域
,该区域与基于行格式的旧数据库缓冲区缓存一起存在。因此,它可以在同一个数据库中以行和列格式将数据存储在块中。Oracle 基于成本的优化器 (CBO) 知道这两种内存格式的存在。在 Amazon RDS for Oracle 上运行 Oracle 工作负载的客户可以从此功能中受益,该功能仅适用于企业版自带许可证 (BYOL),并且作为需要单独
许可
的额外费用选项提供。
Oracle 数据库内存中的好处
Oracle 数据库内存中 (IM) 具有以下优点:
-
更快地扫描大量行并应用使用运算符(如 =、<、> 和 IN)的筛选器
-
更快地查询表中列的子集;例如,从 200 列中选择 7 列
-
使用 In-Memory 联接组 、将小维度表上的谓词转换为较大事实表上的过滤器以及使用布隆过滤器增强联接性能
-
使用
VECTOR GROUP BY 变换进行高效的
内存聚合
-
减少了索引、实例化视图和 OLAP 多维数据集,从而减少了存储和带宽需求
-
由于能够以压缩格式扫描列数据,因此可以使用
In-Memory 混合压缩
降低存储成本并加速扫描
-
使用存储索引和更快的处理进行数据修剪,以及 使用带有片上软件的最新先进处理器的
SIMD(单指令多数据)
功能进行
内存算术
IM 列存储
以压缩的列格式 维护表、分区和单个列的副本,该格式针对快速扫描进行了优化。
IM 列存储按列存储每个表或视图的数据,而不是按行存储。每列都分为单独的行子集。名为
内存压缩单元 (IMCU)
的容器将行子集的所有列 存储在表段中。
IM 列存储位于
内存区域
,这是系统全局区域 (SGA) 的可选部分。IM 列存储不是取代基于行的存储或数据库缓冲区缓存,而是对其进行补充。该数据库使数据能够以基于行和列的格式存储在内存中,提供两全其美的效果。IM 列存储区提供了额外的交易一致性表数据副本,该副本与磁盘格式无关。
确定合适的工作负载
您可以利用
RDS for Oracle 数据库实例的 Amazon RDS 性能洞察
来了解数据库工作负载概况及其性能。在调查数据库工作负载中是否存在任何缓慢或性能问题时,您可能会发现复杂的 SQL 查询,例如 SELECT 访问多个表或视图以使用多种联接方法对大量数据进行聚合、筛选和排序,这些查询位于 Performance Insights 控制面板的 Top SQL 部分。你会注意到这些 SQL 的执行计划通常很复杂,并且包含嵌套循环或哈希连接等联接方法。此外,你会看到不超过几行的 DML(插入/更新和删除)语句。他们的执行计划通常包含诸如
索引唯一扫描 、索引快速完全扫描
、 索引跳过扫描
和通过 索引
ROWID 访问 表
之类的访问方法, 以实现较低的基数或访问更少的行。混合工作负载就是这样呈现的。
进一步调查,您需要确定数据库系统是否受到 IO 的约束,IO 可以是物理的,也可以是逻辑的。例如, 对于磁盘 IO 类型的指标,您经常会在
操作系统计数器
下发现峰值上升,
-
os.diskio。
.readiosps,
-
os.diskio。
.writeiosps 和
-
os.diskio。
.avgQueuelen
同样值得注意的是,例如,
适用于 Oracle 的 RDS 本机计数器的
值会更高,
-
db.sql.sorts
(磁盘)
-
db.cache.p
hysical 读取和
-
db.cache.db 区块从缓存
中获取
你可能还会注意到
每秒 SQL 统计数据的
增加
,例如,
-
db.sql.stats.elapsed_time_per_sec
,
-
db.sql.stats.rows_processed_per_sec
,
-
db.sql.stats.buffer_gets_per_sec 和
-
db.sql.stats.physical_read_requests_per_sec
。
值得注意的是,其中一些 SQL 语句(通常称为联机事务处理或 OLTP)的
每次呼叫统计信息
将包含
-
每秒执行次数很高(
db.sql_tokenized.stats.executions_per_sec
),
-
每次执行所用时间的子秒值(db.sql.stats.elapsed_time_per_exec)
-
而且每次执行处理的行数也更少(
db.sql.stats.rows_processed_per_exec
)
与每秒执行次数相对较少 但每次
执行所用时间 和
每秒
处理 行数 (通常称为联机分析处理或 OL A
P)的其
他 SQL 相比。当比较在两种类型的 SQL 语句中访问的表或基于表构建的表时,您会注意到相似之处。通常,您会发现 OLAP 查询执行缓慢,并且在此过程中会影响 OLTP 工作负载。您可以从执行计划中获取表和访问方法,可以从 “
性能洞察” 仪表板上的 “ 数据库负载” 部分
查看执行计划 ,在那里您可以按计划对平均活跃会话 (AAS) 图表进行切片。作为 OLAP 查询一部分的基础表是填充到内存列存储中的理想候选表。
建议在将已识别的表加载到内存列存储区后重新运行相同的工作负载时捕获这些指标。比较前期和事后指标将揭示内存选项是否对您的工作负载有益。
在适用于 Oracle 的亚马逊 RDS 上启用 19c 及更高版本的内存中
基本标准是将
INMEMORY_SIZE 设置为大 于零的值,这将启用 In-Memor
y 列存储。
INMEMOR
Y 区域是一个单独的内存块,由分配给实例的可用 SGA 中划分出来。
编辑您的
自定义参数组
,将
INMEMORY_SIZE 设置 为所需的大小
。将
INMEMORY_SIZE
设置 为最小值 100 MB。
兼容
的 初始化参数必须设置为 12.1.0 或更高版本。
内存区域大小指南
所需的内存区域取决于存储在其中的数据库对象以及 应用于每个对象的
压缩方法
。要获得最高压缩率,请选择 “
容量高
” 或 “
容量低
” ;但是,它们需要额外的 CPU 才能解压缩。为了获得最佳查询性能,建议选择 FOR QU
ERY HIGH
或 FOR
QUERY LOW
压缩方法。尽管与其他两个选项相比,它们消耗更多的内存,但无需解压缩即可扫描和筛选数据。您可以选择使用
压缩顾问中的 DBMS_COMPRESSIO
N 接口。当您在磁盘上已经压缩的对象上运行顾问时,建议的压缩比可能不正确。在这种情况下,使用所需的压缩将对象加载到内存中,然后查询
V$IM_SEGMENTS 以找到
压缩率。您可以为此目的使用以下查询:
select segment_name, bytes disk, inmemory_size, populate_status, inmemory_compression COMPRESSION, bytes/inmemory_size_comp_ratio from v$im_segments where segment_name='<TABLE_NAME>';
对于每个存储的对象,估计其消耗的内存。例如,如果您针对表的分析工作负载查询 200 列中的 10 列,并且几乎扫描了整个数据集,则根据该列的数据类型和表中的总行数,您可以估计它可能消耗的大致内存量。您可以选择对缓冲区缓存(未启用内存选项)运行相同的分析查询,验证缓存的块(
v$bh.block# ),然后与
dba_table
s 中的块
进行比较, 以查看加载到缓存中的块占总数的百分比。您可以为此目的使用以下查询:
select obj.owner, obj.object_name, obj.object_type,
count(buf.block#) as cached_blocks,
tab.blocks as total_blocks
from v$bh buf
inner join dba_objects obj
on buf.objd = obj.data_object_id
inner join dba_tables tab
on tab.owner = obj.owner
and tab.table_name = obj.object_name
and obj.object_type = 'TABLE'
where buf.class# = 1
and buf.status != 'free'
and obj.owner = '<TABLE_OWNER>'
and obj.object_name = '<TABLE_NAME>'
and obj.object_type = 'TABLE'
group by obj.owner, obj.object_name, obj.object_type, tab.blocks;
然后,您可以根据使用的压缩类型,按压缩顾问建议的压缩比系数减去最终估计值。
如果您对表中的
数字 类型列运行算术函数
,则谨慎的做法是启用
in_memory_optimized_alithmetic 参数,并在双存储
的估计大小基础上再增加 15%。启用后,优化器使用单指令多数据 (SIMD) 向量处理来加快对
数字
格式列的算术运算,否则这将产生显著的性能开销,因为它们无法在硬件中本地执行。
适用于甲骨文的亚马逊 RDS 上的内存人群
当您使用 DDL 将对象指定为
IN
MEMORY 时 ,它们有资格存放在 IM 列存储中,但您需要在存储中填充这些对象才能实际移动它们。在填充期间,数据库从磁盘读取现有的行格式数据,将其转换为列格式,然后将其存储在 IM 列存储中。将新数据(例如,插入、更新或删除后表中修改的行)转换为列格式称为
再
填充。人口要么是按需的,要么是基于优先级的。
按需人群
DDL 语句包含
INMEMORY PRI ORITY 子句,该子句为填充队列
提供更多控制。默认情况下,对象的
INMEM ORY 优先级
设置为
无
。数据库仅在通过
全表扫描
访问对象时才会填充该对象 ,因此,任何通过索引或通过
rowid 提取
的访问都 不会在 IM 列存储中填充该对象。此外,如果磁盘上的分段不超过 64 KB,则不会将其填充到 IM 存储区中;因此,一些启用 IM 存储区的小对象也可能无法填充。
基于优先级的人口
您可以 为要填充到 IM 存储中的对象选择优先级 “
关键
” 、“
高
” 和 “
低
”,然后数据库会使用内部管理的优先级队列自动填充这些对象。在这种情况下,全面扫描不是人口的必要条件。
在这种情况下,数据库会执行以下操作:
-
数据库实例重新启动后,自动在 IM 列存储中填充列式数据。
-
根据指定的优先级对
INMEMOR
Y 对象的总体进行排队。例如,使用 I
NMEMORY PRIOR
ITY CRITICAL 更改的表 优先于以
INMEMORY 优先级为高
而更改的表 ,而后者又优先于以
INMEMOR
Y 优先级低更改的表。 如果 IM 列存储空间不足,则在空间可用之前,Oracle 数据库不会填充其他对象。
-
等待从
ALTER TABLE 或 ALTER
MAT
ERIALIZED VIEW
语句中返回,直到对对象的更改记录在 IM 列存储中。
您可以将特定对象或实例化视图中的表空间、表和列的子集填充到 IM 列存储中。但是,以下对象不符合使用 IM 列存储的条件:
-
索引
-
按索引排列的表格
-
哈希集群
-
系统用户拥有并存储在 SYSTEM 或 SYSAUX 表空间中的对象
在 IM 列存储中填充区段后,数据库仅在该区段被删除或移动,或者使用
NO IN
MEMORY 属性更新区段时才会将其逐出。您可以手动或使用
ADO 策略
驱逐分段。
如何在内存中填充数据库对象
可以使用
DBMS_
INM EMOR
Y 程序单元或 DBMS_INMEMORY_ADMIN
Y.POPULATE_WAIT 过程填充数据库,也可以使用 SELECT 强制对表进行全表扫描(/*FULL (table_
name) NO_PARALLEL(表名)*/)提示。
如何在内存中重新填充数据库对象
由于针对已在 IM 列存储中的对象或其依赖对象发出 DML 或 DDL,因此需要定期刷新修改过的对象。这个过程被称为再种群。
由于内存压缩单元 (
IMCU
) 是只读结构,因此任何数据更改都将在
交易日志中作为快照元数据进行跟踪。
重新填充是自动完成的(可以使用初始化参数或
DBMS_INMEMOR
Y 包手动控制),有以下两种形式之一:
-
基于阈值的再填充
— 当交易日志中陈旧条目数量的阈值或陈旧阈值被突破时,会自动触发重新填充
-
涓流再填充
— 无论陈旧阈值如何,IMC0(内存协调器)进程都会定期检查交易日志中是否存在陈旧行,并补充基于阈值的再填充
适用于 Oracle 的亚马逊 RDS 上的其他可配置内存参数
以下内存参数也可在适用于 Oracle 的亚马逊 RDS 上使用:
-
INMEMORY_CLAUSE_DEFAULT
— 你可以将此参数设置为 INMEMORY 或 NOINMEMORY。
然后,默认情况下,此设置适用于所有新表和实例化视图,无需明确指定。
-
INMEMORY_EXPRESSIONS_USAGE — 它控制哪些内存表达式被填充到 IM 列存储中以供查询使用
。
可接受的值为 “
启
用” 、
“禁用” 、“
仅限
静态” 和 “仅限
动态”。
默认为 ENAB
L
E,这意味着静态和动态表达式都填充在 IM 列存储中。
-
INMEMORY_FOR
C E — 这只允许两个设置:
默认
和关闭。
其他设置,例如
BASE_LEVEL 和
CELLMEMORY
_LE
VEL (仅限 exadata 功能),不适用于适用于 Oracle 的亚马逊 RDS。
-
INMEMORY_QUERY
— 这会在系统或会话级别启用或禁用整个数据库的内存功能。它对于测试带有 In-Memory 功能和没有 In-Memory 功能的工作负载都很有用。
-
INMEMORY_TRICKLE_REPOPULATE_SERVERS_PERCENT — 这控制了用于涓流再填充的后台
进程的数量。
在适用于 Oracle 的 Amazon RDS 中启用内存数据库之前需要考虑的事项
在适用于 Oracle 的 Amazon RDS 中启用此功能之前,请考虑以下事项:
-
截至撰写本文时 ,适用于 Oracle 的 Amazon RDS 尚不可用 In-Memory
基本级别功能
和
自动内存
功能,但您仍然可以选择手动填充内存。
-
如果不重启适用于 Oracle 的 Amazon RDS,就不可能动态调整
INMEMORY_SIZE 参数的大小
。
甲骨文文档
提到,
INMEMORY_S
IZE 可以在不重新启动的情况下从当前设置中动态增加。但是,使用适用于 Oracle 的 Amazon RDS,您可以在关联的参数组中增加、减少或完全禁用它,但需要重新启动。
-
请务必注意,数据库内存选项仅作为额外费用选项适用于企业版,因此 LI(含许可证)模式不适用。您需要拥有 BYOL(自带许可证)模型。建议与
亚马逊云科技 License Manager
集成 ,以监控 BYOL 模式下的许可证使用情况。许可管理器与
亚马逊云科技 Systems Manager 集成,
可 帮助发现安装在您的 亚马逊云科技 资源上的任何软件。您可以配置许可证管理器,以帮助您在 RDS 上增加数据库占用空间时自动跟踪 Oracle 数据库引擎版本、选项和包的许可证。
有时,决定是否应将表填充到 IM 列存储中可能很困难,尤其是当您在 IM 存储中已经有多个表并且受到所选实例类型可用内存的限制时。然后建议使用
内存优化的实例类型
,为相同数量的 vCPU 提供更大的内存。例如,通用
型 db.m5.12xl
arge 提供 192 GiB 内存和 48 个 vCPU,而经过内存优化的
db.r5.12xlarge 为相同的 48 个 vCPU 提供 384 GB
的内存。内存优化实例旨在为处理内存中大型数据集的工作负载提供快速性能,因此是内存工作负载的理想实例类型。内存优化实例可用的更大内存也将使您不必做出艰难的选择,即驱逐一些预先填充的表,以便为较新的表腾出空间。请参阅
Amazon RDS Oracle 实例类型
以查找可用的实例类型及其配置。
在以下部分中,我们将讨论如何实现 Oracle 数据库内存功能,并展示在 Amazon RDS for Oracle 上运行的同类企业混合工作负载所获得的优势。
环境设置
我们选择了带有 db.r5b.4x
large 实例类的 19c (19.0.0.ru-2023-01.rur-2023-01. r1
) 企业版 Oracle 数据库,我们正在使用安装在亚马逊弹性计算云(亚马逊 EC2)实例上的 SQL*Plus 客户端进行连接。
完成以下步骤来设置环境:
-
在名为管理员的架构 中创建名为
ORDERS_TAB
的表。
此表包含客户及其订单详细信息以及日期或订单、城市、地区、供应成本、部件订购及其供应商详细信息以及折扣和配送模式。
-
创建名为
ORDERS_SUMMARY_V
的视图 ,其中包含订单日期、客户详情、订单详情和生成的收入。
-
使用 PL/SQL 过程和函数将一些随机记录插入表中,该过程和函数遍历随机计数并插入预定义的记录数组。
参见以下内容:
SQL> select count (*) from ORDERS_TAB;
COUNT(*)
7934395
SQL>PROMPT ******************************************
PROMPT Show table size/usage
PROMPT ******************************************
col segment_name format a20;
col size heading 'Size (MB)' format 999,999,999;
select segment_name, bytes/1024/1024 "size" from user_segments
where segment_name = 'ORDERS_TAB';
SEGMENT_NAME Size (MB)
-------------------- ------------
ORDERS_TAB 1,408
-
编辑自定义参数组以将
INMEMORY_
SIZE 设置为 11 GB ,然后重启实例。11GB 的
INMEMORY_
SIZE 是使用上述内存区域大小调整指南得出的。确定的大小足够容纳正在填充到 In Memory 存储区中的表。
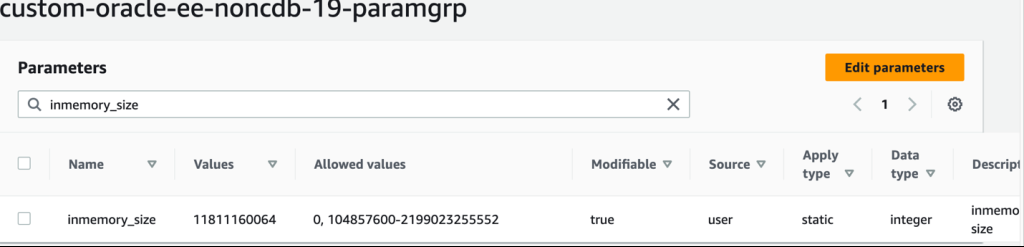
验证数据库上的
inmemory_ siz
e 参数设置。
SQL> show parameter inmemory_size
NAME TYPE VALUE
------------------------------------
inmemory_size big integer 11G
SQL>PROMPT ******************************************
PROMPT Show size and populated status in memory
PROMPT ******************************************
col owner format a20;
col segment_name format a20;
col bytes format 999,999,999,999;
col inmemory_size format 999,999,999,999;
col bytes_not_populated heading 'BYTES NOT|POPULATED' format 999,999,999;
col inmemory_priority format a9
select
owner,
segment_name,
bytes,
populate_status as "POP STATUS",
inmemory_size,
bytes_not_populated,
inmemory_priority
from
v$im_segments
where
segment_name in ('ORDERS_TAB')
order by
segment_name;
no rows selected
SQL>
-
使用完整表格扫描提示填充表格。这是必要的,因为该表尚未填充到内存区域。
如果你选择使用 SELECT 语句填充对象,它可能并不总是强制进行
全表扫描
;优化器可能会选择
索引扫描
,但填充不会发生。因此,建议使用如下的
/*FULL(表名)NO_PARALLEL(表名)*/ 提示来强制进行全
表扫描:
select /*FULL (orders_tab) NO_PARALLEL(orders_tab) */ count(*) from orders_tab;
您也可以使用 INM
EMORY_POPULATE 过程填充内存中的表,如下
所示:
PROMPT ******************************************
PROMPT Populate ORDERS_TAB table
PROMPT ******************************************
ALTER TABLE orders_tab INMEMORY PRIORITY HIGH;
Table altered.
EXEC DBMS_INMEMORY.POPULATE(USER,'ORDERS_TAB');
PL/SQL procedure successfully completed.
-
现在,你可以使用
DBMS_INMEMORY_ADMIN.POPULATE_WAIT 函数等待 IM 填充
,然后使用 以下 PL/SQL 块来捕捉成功或失败的情况:
SET SERVEROUTPUT ON;
PROMPT
PROMPT Wait for IM Population
PROMPT
--
DECLARE
--
— populate_wait query
--
— Return code:
— -1 = POPULATE_TIMEOUT
— 0 = POPULATE_SUCCESS
— 1 = POPULATE_OUT_OF_MEMORY
— 2 = POPULATE_NO_INMEMORY_OBJECTS
— 3 = POPULATE_INMEMORY_SIZE_ZERO
--
co_wait_timeout CONSTANT NUMBER := 3; — Wait up to 3 minutes
co_priority CONSTANT VARCHAR2(8) := 'HIGH';
co_pop_percent CONSTANT NUMBER := 100;
co_pop_timeout CONSTANT NUMBER := 60;
--
v_rc NUMBER;
v_wait NUMBER := 0;
v_done BOOLEAN := FALSE;
--
POP_ERROR EXCEPTION;
PRAGMA EXCEPTION_INIT(POP_ERROR, -20000);
POP_TIMEOUT EXCEPTION;
PRAGMA EXCEPTION_INIT(POP_TIMEOUT, -20010);
BEGIN
WHILE NOT v_done AND v_wait <= co_wait_timeout LOOP
select dbms_inmemory_admin.populate_wait(
priority=>co_priority, percentage=>co_pop_percent, timeout=>co_pop_timeout )
INTO v_rc
from dual;
--
IF v_rc = 0 THEN
v_done := TRUE;
ELSIF v_rc = -1 THEN
v_wait := v_wait + 1;
ELSE
RAISE_APPLICATION_ERROR(-20000, 'Error populating IM column store');
END IF;
--
IF v_wait >= co_wait_timeout THEN
RAISE_APPLICATION_ERROR(-20010, 'Timeout populating IM column store');
END IF;
END LOOP;
EXCEPTION
WHEN POP_ERROR THEN
DBMS_OUTPUT.PUT_LINE(TO_CHAR(SQLERRM(-20000)));
RAISE;
WHEN POP_TIMEOUT THEN
DBMS_OUTPUT.PUT_LINE(TO_CHAR(SQLERRM(-20010)));
RAISE;
END;
/
PROMPT
PROMPT In-memory population complete
PROMPT
PL/SQL procedure successfully completed.
SQL> **********************************************
SQL> In-memory population complete
SQL> **********************************************
SQL> Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0
[ec2-user@ip-xxx-xx-xx-xxx inmem]$
-
检查表是否已填充到内存中:
PROMPT ******************************************
PROMPT Show size and populated status in memory
PROMPT *****************************************
col owner format a20;
col segment_name format a20;
col bytes format 999,999,999,999;
col inmemory_size format 999,999,999,999;
col bytes_not_populated heading 'BYTES NOT|POPULATED' format 999,999,999;
col inmemory_priority format a9
select
owner,
segment_name,
bytes,
populate_status as "POP STATUS",
inmemory_size,
bytes_not_populated,
inmemory_priority
from
v$im_segments
where
segment_name in ('ORDERS_TAB')
order by
segment_name;
******************************************
SQL> Show size and populated status in memory
SQL> ******************************************
BYTES NOT
OWNER SEGMENT_NAME BYTES POP STATUS INMEMORY_SIZE POPULATED INMEMORY_STATUS
------ ------------ --------- ---------- -------------- --------- ---------------
ADMIN ORDERS_TAB 1,470,988,288 COMPLETED 411,959,296 0 HIGH
运行企业工作负载
让我们运行一个查询,尝试使用之前创建的视图
orders_summary_v 来查找产生最低收入 的订单
。这迫使优化器使用一些联接过滤器、排序和聚合,这通常更像是 OLAP 类型的查询。这是 Oracle 数据库内存大放异彩的地方。
启用 Oracle 数据库内存中
以下查询启用了 Oracle 数据库内存功能:
SQL> set timing on
SQL> set echo on
SQL> alter session set statistics_level = all;
Session altered.
Elapsed: 00:00:00.00
SQL> alter session set inmemory_query = enable;
Session altered.
SQL> select
order_key, min(order_revenue)
from orders_summary_v
where order_key IN ( select order_key from ORDERS_TAB where line_supplycost = (select max(line_supplycost)
from ORDERS_TAB where line_quantity > 10 and order_shipmode LIKE 'SHIP%' and order_discount between 5 and 8)
and order_shipmode LIKE 'SHIP%' and order_discount between 5 and 8 ) group by order_key;
ORDER_KEY MIN(ORDER_REVENUE)
---------- ------------------
1504170 828412365
Elapsed: 00:00:00.01
SQL> set lines 500 pages 500;
SQL> set echo off
SQL> set timing off
select * from table(dbms_xplan.display_cursor(NULL, NULL, 'TYPICAL IOSTATS LAST'));
PLAN_TABLE_OUTPUT
----------------------------------------
SQL_ID 183svsjkyysc4, child number 0
----------------------------------------
select order_key, min(order_revenue) from orders_summary_v where
order_key IN ( select order_key from ORDERS_TAB where line_supplycost = (select max(line_supplycost)
from ORDERS_TAB where line_quantity > 10 and order_shipmode LIKE 'SHIP%' and order_discount between 5 and 8)
and order_shipmode LIKE 'SHIP%' and order_discount between 5 and 8) group by order_key
Plan hash value: 80309288
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | E-Rows |E-Bytes| Cost (%CPU)| E-Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 5872 (100)| |
| 1 | HASH GROUP BY | | 1 | 19 | 5872 (8)| 00:00:01 |
| 2 | VIEW | VM_NWVW_1 | 1 | 19 | 5872 (8)| 00:00:01 |
| 3 | HASH GROUP BY | | 1 | 76 | 5872 (8)| 00:00:01 |
|* 4 | HASH JOIN | | 1 | 76 | 3933 (9)| 00:00:01 |
| 5 | JOIN FILTER CREATE | :BF0000 | 1 | 33 | 1945 (8)| 00:00:01 |
|* 6 | TABLE ACCESS INMEMORY FULL | ORDERS_TAB | 1 | 33 | 1945 (8)| 00:00:01 |
| 7 | SORT AGGREGATE | | 1 | 18 | | |
|* 8 | TABLE ACCESS INMEMORY FULL| ORDERS_TAB | 573K| 9M| 1937 (7)| 00:00:01 |
| 9 | JOIN FILTER USE | :BF0000 | 7934K| 325M| 1968 (9)| 00:00:01 |
|* 10 | TABLE ACCESS INMEMORY FULL | ORDERS_TAB | 7934K| 325M| 1968 (9)| 00:00:01 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("ORDER_KEY"="ORDER_KEY")
6 - inmemory(("ORDER_DISCOUNT">=5 AND "ORDER_SHIPMODE" LIKE 'SHIP%' AND
"ORDER_DISCOUNT"<=8 AND "LINE_SUPPLYCOST"=))
filter(("ORDER_DISCOUNT">=5 AND "ORDER_SHIPMODE" LIKE 'SHIP%' AND
"ORDER_DISCOUNT"<=8 AND "LINE_SUPPLYCOST"=))
8 - inmemory(("ORDER_DISCOUNT">=5 AND "ORDER_SHIPMODE" LIKE 'SHIP%' AND
"LINE_QUANTITY">10 AND "ORDER_DISCOUNT"<=8))
filter(("ORDER_DISCOUNT">=5 AND "ORDER_SHIPMODE" LIKE 'SHIP%' AND
"LINE_QUANTITY">10 AND "ORDER_DISCOUNT"<=8))
10 - inmemory(SYS_OP_BLOOM_FILTER(:BF0000,"ORDER_KEY"))
filter(SYS_OP_BLOOM_FILTER(:BF0000,"ORDER_KEY"))
53 rows selected.
禁用 Oracle 数据库内存中
为了比较不使用 In-Memory 的同一查询的性能,我们可以将 ORD
ERS_TAB 表设置为 NO INMEMOR
Y。
这会禁用此表的 In-Memory 使用,但也会将该表从 IM 列存储中删除。如果我们想为该表重新启用 In-Memory,则需要再次将其填充到 IM 存储中,这在非常繁忙的企业系统中可能具有挑战性,尤其是对于非常大的表。因此,建议使用 inm
emory_query 参数在会话级别禁用 In
-Memory 以进行工作负载测试。现在,让我们在禁用 In-Memory 的情况下运行相同的查询:
SQL> set timing on
SQL> set echo on
SQL> alter session set statistics_level = all;
Session altered.
Elapsed: 00:00:00.00
SQL> alter session set inmemory_query = disable;
Session altered.
SQL> select
order_key, min(order_revenue)
from orders_summary_v
where order_key IN ( select order_key from ORDERS_TAB where line_supplycost = (select max(line_supplycost)
from ORDERS_TAB where line_quantity > 10 and order_shipmode LIKE 'SHIP%' and order_discount between 5 and 8)
and order_shipmode LIKE 'SHIP%' and order_discount between 5 and 8 ) group by order_key;
ORDER_KEY MIN(ORDER_REVENUE)
---------- ------------------
1504170 828412365
Elapsed: 00:00:02.49
SQL> set lines 500 pages 500;
SQL> set echo off
SQL> set timing off
select * from table(dbms_xplan.display_cursor(NULL, NULL, 'TYPICAL IOSTATS LAST'));
PLAN_TABLE_OUTPUT
----------------------------------------
SQL_ID 183svsjkyysc4, child number 1
----------------------------------------
select order_key, min(order_revenue) from orders_summary_v where
order_key IN ( select order_key from ORDERS_TAB where line_supplycost = (select max(line_supplycost)
from ORDERS_TAB where line_quantity > 10 and order_shipmode LIKE 'SHIP%' and order_discount between 5 and 8)
and order_shipmode LIKE 'SHIP%' and order_discount between 5 and 8) group by order_key
Plan hash value: 2606829073
---------------------------------------------------------------------------------------
| Id | Operation | Name | E-Rows |E-Bytes| Cost (%CPU)| E-Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 146K(100)| |
| 1 | HASH GROUP BY | | 1 | 19 | 146K (1)| 00:00:06 |
| 2 | VIEW | VM_NWVW_1 | 1 | 19 | 146K (1)| 00:00:06 |
| 3 | HASH GROUP BY | | 1 | 76 | 146K (1)| 00:00:06 |
|* 4 | HASH JOIN | | 1 | 76 | 97571 (1)| 00:00:04 |
|* 5 | TABLE ACCESS FULL | ORDERS_TAB | 1 | 33 | 48782 (1)| 00:00:02 |
| 6 | SORT AGGREGATE | | 1 | 18 | | |
|* 7 | TABLE ACCESS FULL| ORDERS_TAB | 573K| 9M| 48795 (1)| 00:00:02 |
| 8 | TABLE ACCESS FULL | ORDERS_TAB | 7934K| 325M| 48768 (1)| 00:00:02 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
--------------------------------------------------
4 - access("ORDER_KEY"="ORDER_KEY")
5 - filter(("ORDER_DISCOUNT">=5 AND "ORDER_SHIPMODE" LIKE 'SHIP%' AND
"ORDER_DISCOUNT"<=8 AND "LINE_SUPPLYCOST"=))
7 - filter(("ORDER_DISCOUNT">=5 AND "ORDER_SHIPMODE" LIKE 'SHIP%' AND
"LINE_QUANTITY">10 AND "ORDER_DISCOUNT"<=8))
45 rows selected.
启用 In-Memory 功能后,查询在一秒钟内运行,而没有该功能则需要 2 分 49 秒。这是大约 99.94% 的改进!这是因为启用 In-Memory 后,
使用 Bloom 过滤器可以 提高联接性能
。
使用企业工作负载进行基准测试
为了进一步理解 Oracle 数据库内存的好处,让我们生成一个真实的应用程序工作负载。我们使用 Benchmark Factory 通过运行 TPC-C 和 TPC-H 基准测试来模拟企业应用程序负载。我们设计了基于 OLTP(TPC-C 比例:40)和 OLAP(TPC-H 比例:4)事务的混合工作负载。比例定义架构大小。OLTP 和 OLAP 架构的容量均在 4.5 GB 左右。OLTP 表较小,因此需要更高的比例值,而 OLAP 表是较大的事实表,因此需要较小的比例。缩放系数已根据 RDS 实例 定义的
INMEMORY_SIZ
E 进行了调整。用于以下测试的数据库与之前的测试用例相同。
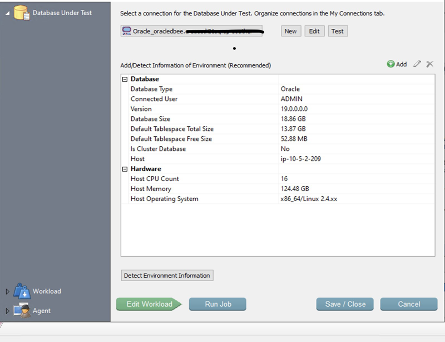
以下屏幕截图显示了将混合工作负载测试所需的对象加载到数据库后数据库的大小。
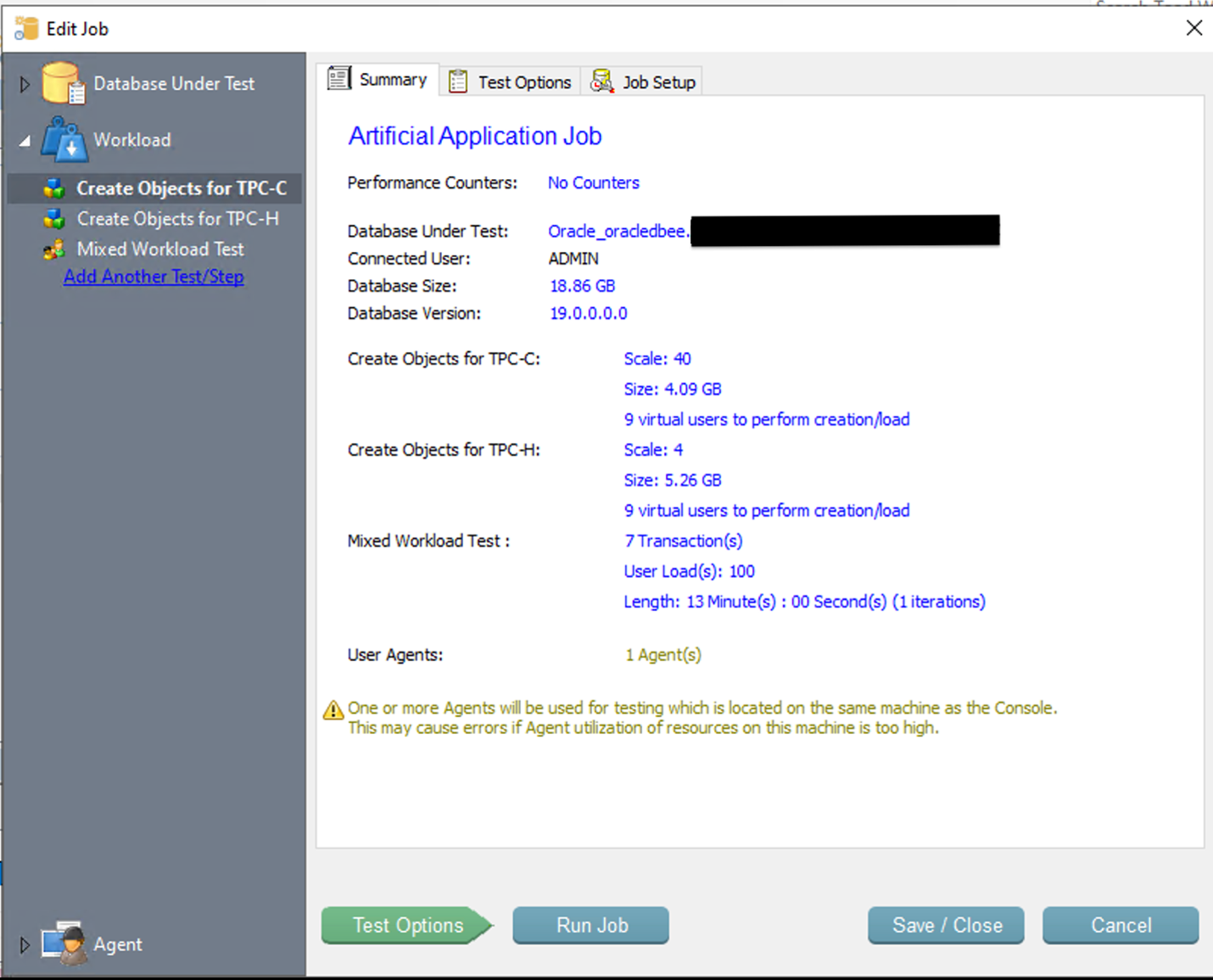
以下屏幕截图显示了作为该基准测试的一部分运行的混合工作负载的详细信息。
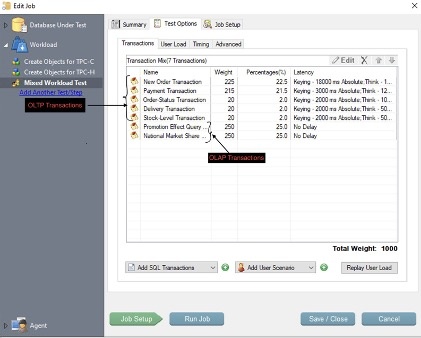
OLTP 和 OLAP 工作负载分布均匀,如以下屏幕截图所示。TPCC 用于 OLTP 工作负载,而 TPCH 用于数据仓库和分析。
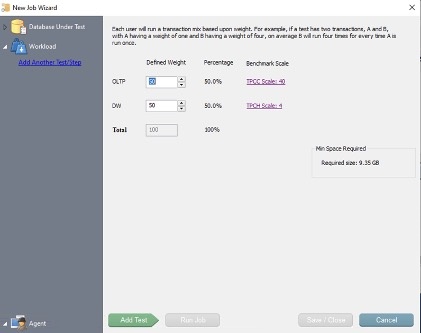
作为本次测试的一部分将运行的七个事务混合使用 OLTP 和 OLAP。
在禁用 In-Memory 的情况下进行真实企业工作负载测试
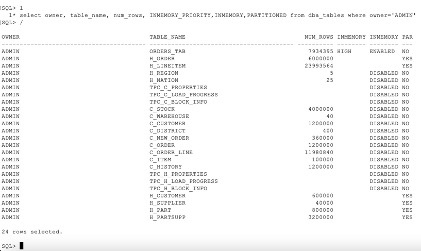
这些表已禁用 In-Memory。这包括一些分区表,其
内存状态反映在
dba_tab_
par tit
ions 视图中,如以下屏幕截图所示。
我们在禁用 In-Memory、100 个并行用户以及同时随机运行的 OLTP 和 OLAP 工作负载的情况下启动测试。
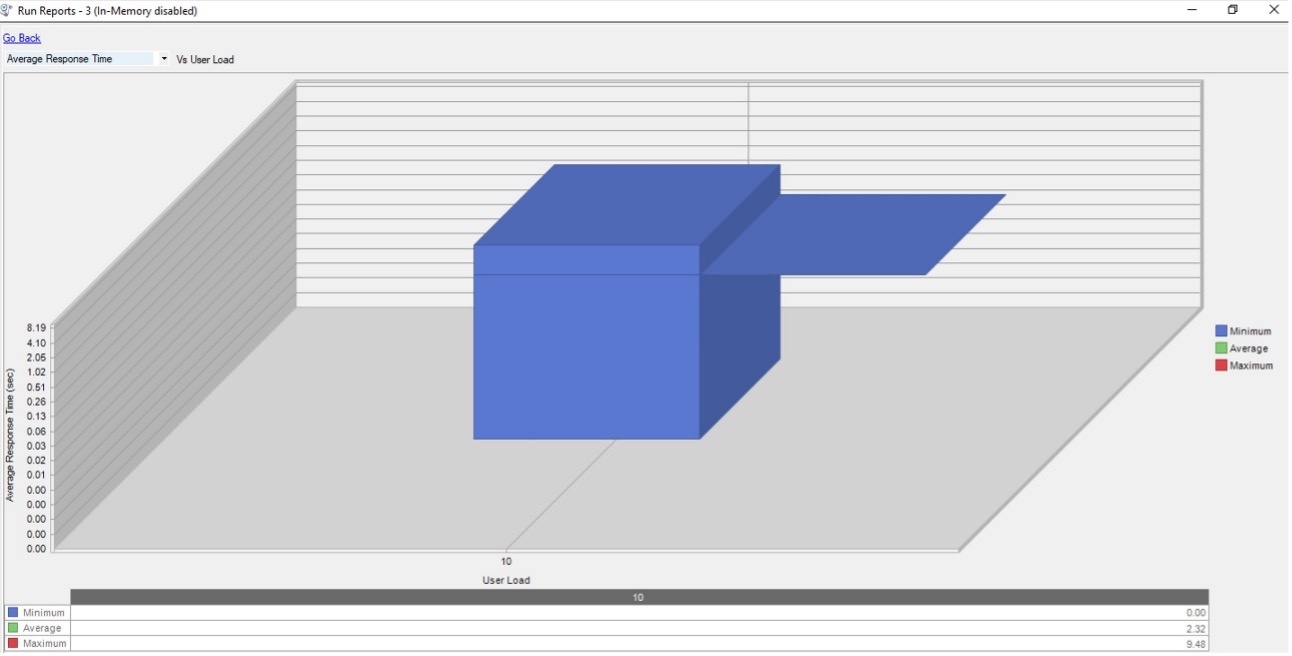
响应时间
下图(以秒为单位的时间尺度)显示响应时间峰值为 9.48 秒,而平均值约为 2.32 秒。
下图以毫秒为单位的时间尺度显示了每秒 0.88 笔交易,其中每笔交易的平均响应时间约为 1,999 毫秒(大约 2 秒)。

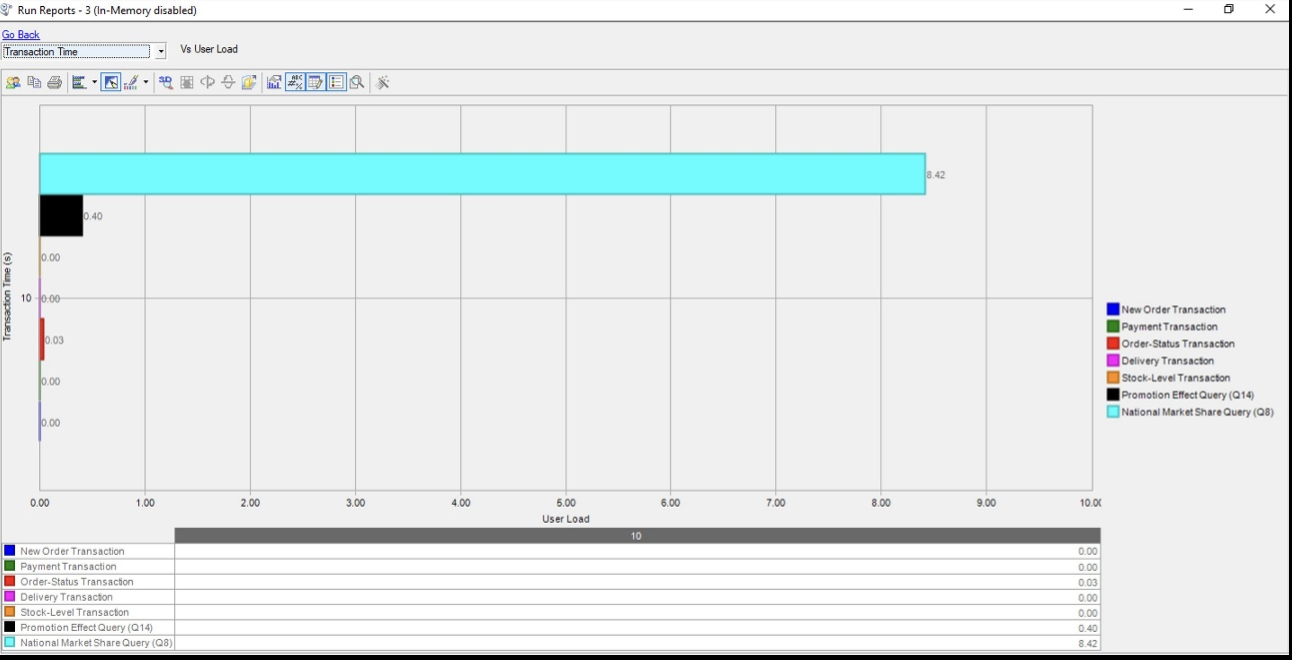
交易时间
图表(以秒为单位的时间尺度)是 OLTP 和 OLAP 事务的明细。像全国市场份额查询(Q8)这样的OLAP查询的每次运行交易时间为8.42秒,而促销效果查询(Q14)的每次运行交易时间为0.40秒。OLTP 事务的事务时间不到一秒。
启用 In-Memory 的真实企业工作负载测试
以下表已填充到列存储中,优先级为关键。
以下屏幕截图显示了非分区表。
以下屏幕截图显示了分区表。

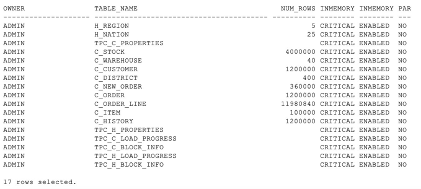
随后,这些表已加载到 IM 列存储中并已完全填充。我们没有在 IM 群体中使用任何压缩;因此,表大小是可比的。
您可以选择使用 参数文件或根据需要对特定表使用 COMPRESS 选项。
**********************************************
Show table size/usage
**********************************************
SEGMENT_NAME Size (MB)
-------------------- ------------
C_ORDER_LINE 816
C_CUSTOMER 752
C_ORDER 47
C_ITEM 9
C_NEW_ORDER 6
TPC_H_PROPERTIES 0
C_HISTORY 72
C_WAREHOUSE 0
H_NATION 0
TPC_C_LOAD_PROGRESS 0
TPC_H_LOAD_PROGRESS 0
C_DISTRICT 0
C_STOCK 1,408
H_REGION 0
TPC_C_BLOCK_INFO 0
TPC_C_PROPERTIES 0
TPC_H_BLOCK_INFO 0
17 rows selected.
**********************************************
Show size and populated status in memory
**********************************************
BYTES NOT
OWNER SEGMENT_NAME BYTES/1024/1024 POP STATUS INMEMORY_SIZE(MB) POPULATED
-------------------- -------------------- --------------- ------------- -----------
ADMIN C_CUSTOMER 748.257813 COMPLETED 733.625 0
ADMIN C_DISTRICT .1015625 COMPLETED 1.25 0
ADMIN C_HISTORY 70.9140625 COMPLETED 33.625 0
ADMIN C_ITEM 8.796875 COMPLETED 9.25 0
ADMIN C_NEW_ORDER 5.84375 COMPLETED 2.25 0
ADMIN C_ORDER 46.203125 COMPLETED 9.625 0
ADMIN C_ORDER_LINE 812.007813 COMPLETED 253 0
ADMIN C_STOCK 1402.84375 COMPLETED 1258.5625 0
8 rows selected.
使用完全相同的参数再次运行了相同的测试。
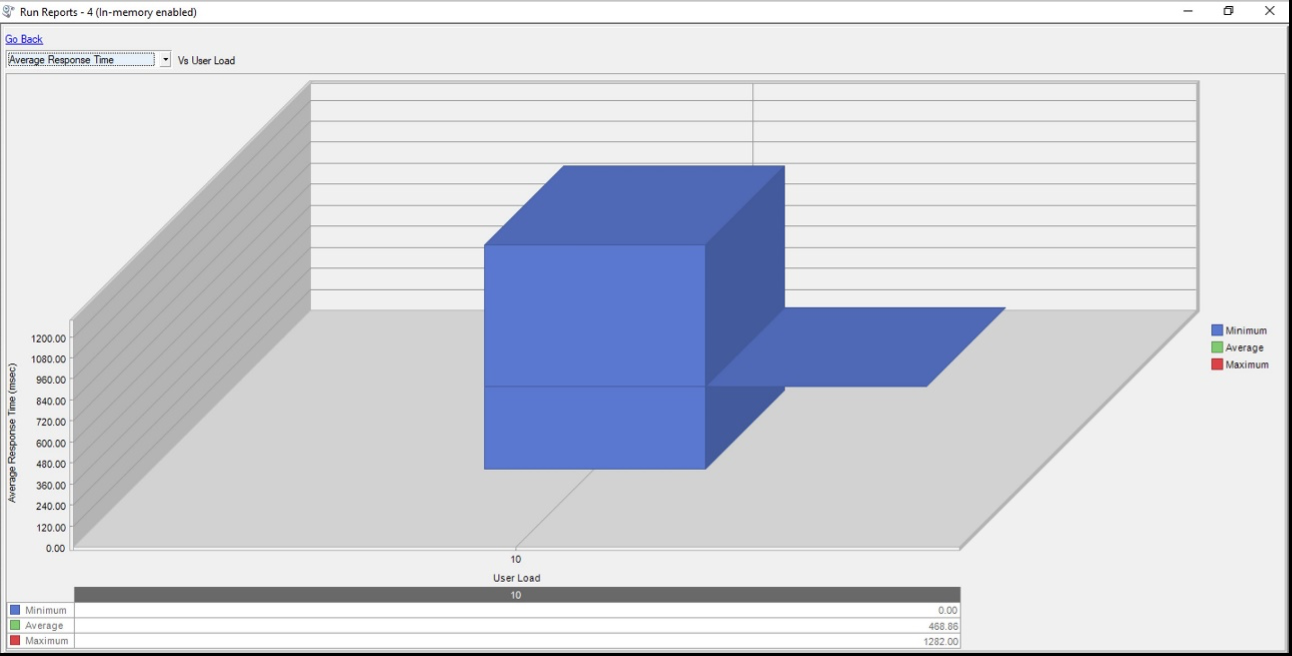
响应时间
下图以毫秒为单位显示响应时间峰值为 1.28 秒,而平均值约为 0.46 秒。
下图的时间尺度以毫秒为单位,显示每秒有 1.02 笔交易,其中每笔交易的平均响应时间约为 563 毫秒(大约 0.56 秒)。
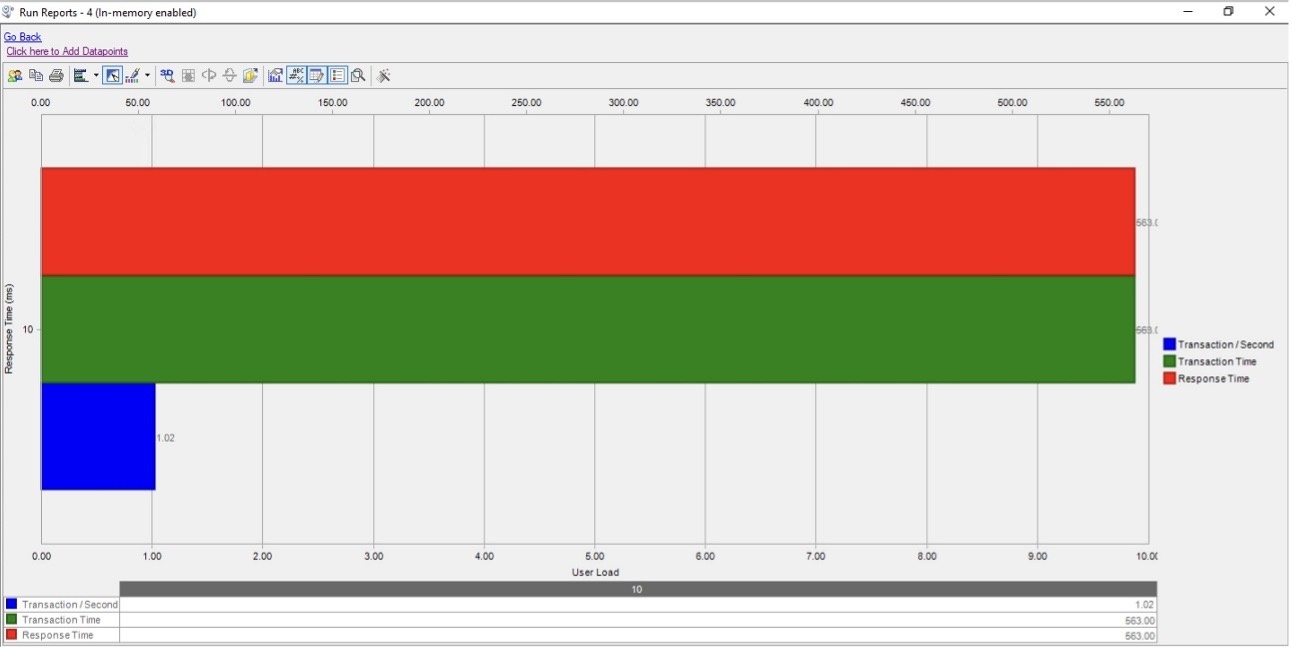
交易时间
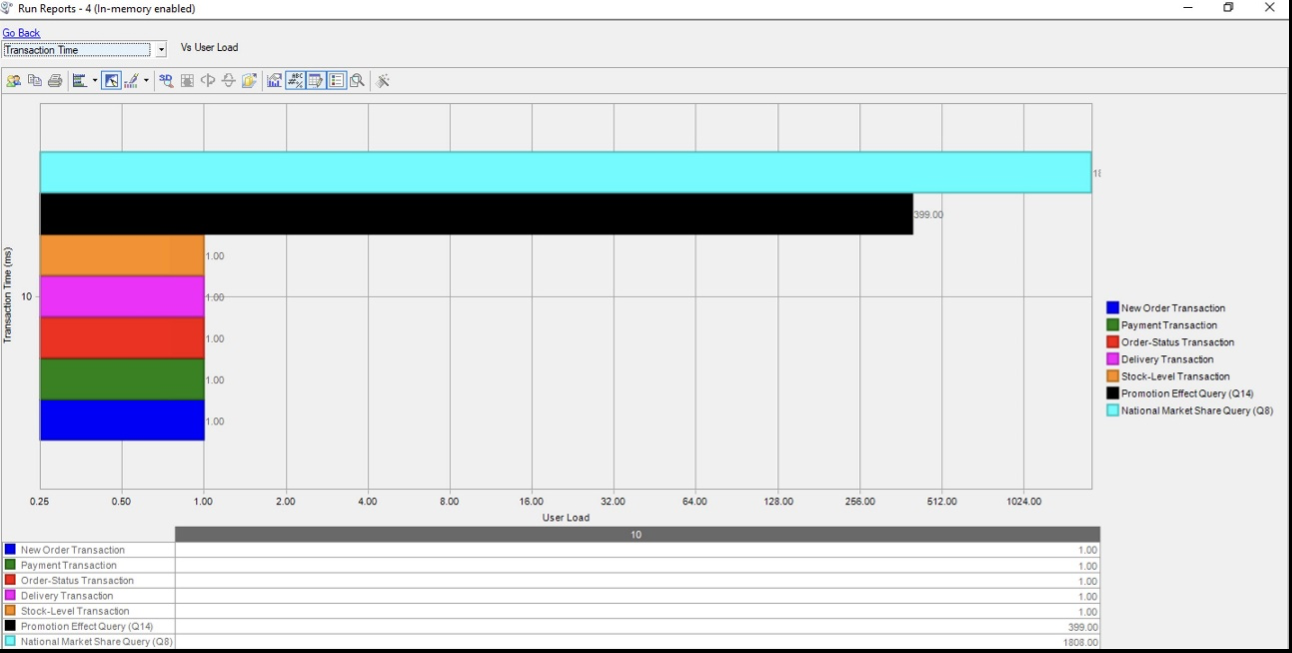
下图(以毫秒为单位的时间尺度)是 OLTP 和 OLAP 事务的明细。像全国市场份额查询(Q8)这样的OLAP查询的每次运行交易时间为1.8秒,而促销效果查询(Q14)的每次运行交易时间为0.39秒。但是,值得注意的是,OLTP 事务不受影响,响应时间不到一秒(1 毫秒)。
结果摘要
OLAP 查询速度提高了 78.62%,而 OLTP 事务保持不变,交付的事务时间仍不到一秒。响应时间缩短了 86.49%,平均每秒 1.02 笔交易,而禁用 In-Memory 时每秒 0.88 笔交易。
真正的好处在于,启用 In-Memory 不需要在应用程序级别进行任何更改。这就像修改一些内存参数和一些表属性一样简单。它不会影响 OLTP,并且可以显著提高 OLAP 性能。
结论
在这篇文章中,我们通过实时分析介绍了这些挑战,以及如何使用 Amazon RDS for Oracle 上的 Oracle 数据库内存选项来修复这些挑战。我们进一步演示了如何实现此功能,并使用并发用户运行一些企业级实时混合工作负载,并重点介绍了其优点。
我们鼓励您评估您的工作负载,并确定其是否适合利用 Oracle 数据库内存选项提供的好处。对此帖子发表评论,提出任何问题或提供反馈。
作者简介
 拉维·基兰
是亚马逊云科技的高级数据库专家,主要研究甲骨文和PostgreSQL数据库引擎。他与企业客户合作,帮助他们在 亚马逊云科技 上运行经过优化的工作负载。他还指导他们使用设计和架构数据库的最佳实践,帮助他们优化成本并提供技术咨询。
拉维·基兰
是亚马逊云科技的高级数据库专家,主要研究甲骨文和PostgreSQL数据库引擎。他与企业客户合作,帮助他们在 亚马逊云科技 上运行经过优化的工作负载。他还指导他们使用设计和架构数据库的最佳实践,帮助他们优化成本并提供技术咨询。