我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
通过从丰富的人工反馈中学习,改进 LLM 中的多跳推理
最近的大型语言模型 (LLM) 使自然语言理解取得了巨大进步。但是,它们容易产生自信但荒谬的解释,这给与用户建立信任构成了重大障碍。在这篇文章中,我们展示了如何整合人工对错误推理链的反馈以进行多跳推理,以提高这些任务的性能。我们不是通过询问人类从头开始收集推理链,而是使用LLM的提示能力从对模型生成的推理链的丰富的人类反馈中学习。我们以(更正、解释、错误类型)的形式为StrategyQA和体育理解数据集收集了两个这样的人类反馈数据集,并评估了几种常用算法以从此类反馈中学习。我们提出的方法与使用基础Flan-T5的思维链提示具有竞争力,而我们的方法更擅长判断其自身答案的正确性。
解决方案概述
随着大型语言模型的出现,该领域在各种自然语言处理 (NLP) 基准测试方面取得了巨大进展。其中,与需要推理的更艰巨的任务(例如多跳问答)相比,在相对简单的任务(例如简短的情境或事实问题回答)上取得了显著的进展。使用 LLM 执行某些任务的性能可能与较小比例下的随机猜测类似,但在较大比例下会显著提高。尽管如此,法学硕士的提示能力有可能提供一些回答问题所需的相关事实。
但是,这些模型可能无法可靠地生成正确的推理链或解释。当使用人类反馈强化学习 (RLHF) 对 LLM 进行训练时,这些自信但荒谬的解释就更加普遍了,在这种情况下可能会发生奖励黑客攻击。
受此启发,我们尝试解决以下研究问题:我们能否通过学习模型生成的推理链上的人类反馈来改进 LLM 的推理?下图概述了我们的方法:我们首先提示模型为多跳问题生成推理链,然后收集有关这些链的不同人类反馈以进行诊断,并提出训练算法以从收集的数据中学习。
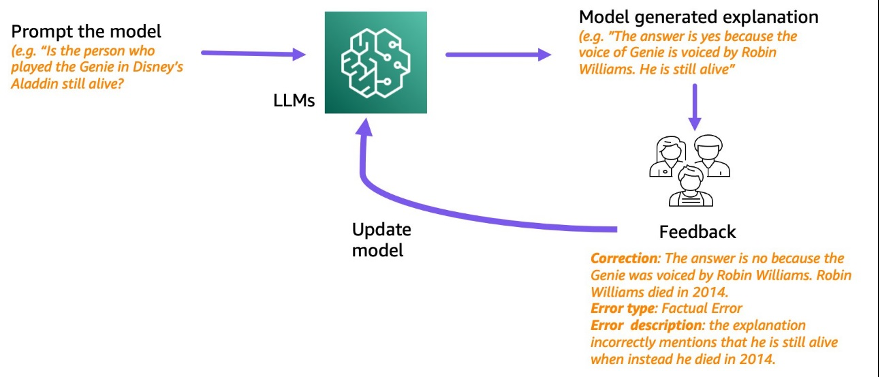
我们收集了关于两个多跳推理数据集(StrategyQA 和 BigBench 的体育理解)的不同的人类反馈。对于每个问题和模型生成的推理链,我们收集正确的推理链、模型生成的推理链中的错误类型以及对为何在提供的推理链中出现该错误的描述(用自然语言)。最终数据集包含来自StrategyQA的1,565个样本的反馈和796个体育理解示例的反馈。
我们提出了多种训练算法,以从收集的反馈中学习。首先,我们提出了一种思维链提示中自我一致性的变体,方法是考虑可以从反馈中学到的加权变体。其次,我们提出了迭代细化,即我们以迭代方式完善模型生成的推理链,直到其正确为止。我们在两个数据集上通过实证演示,微调 LLM(即使用所提议算法的 Flan-T5)的表现与情境内学习基准相当。更重要的是,我们表明,与基本的Flan-T5模型相比,经过微调的模型更能判断自己的答案是否正确。
数据收集
在本节中,我们将详细介绍我们收集的反馈以及数据收集期间遵循的注释协议。我们基于两个基于推理的数据集收集了模型生成的反馈:来自 BigBench 的 StrategyQA 和 Sports Indergence。我们使用 GPT-J 为 StrategyQA 生成答案,使用 Flan-T5 生成体育理解数据集的答案。在每种情况下,模型都会提示使用 k 个包含问题、答案和解释的上下文示例,然后是测试问题。
下图显示了我们使用的接口。向注释者提供问题、模型生成的答案以及分为几个步骤的解释。
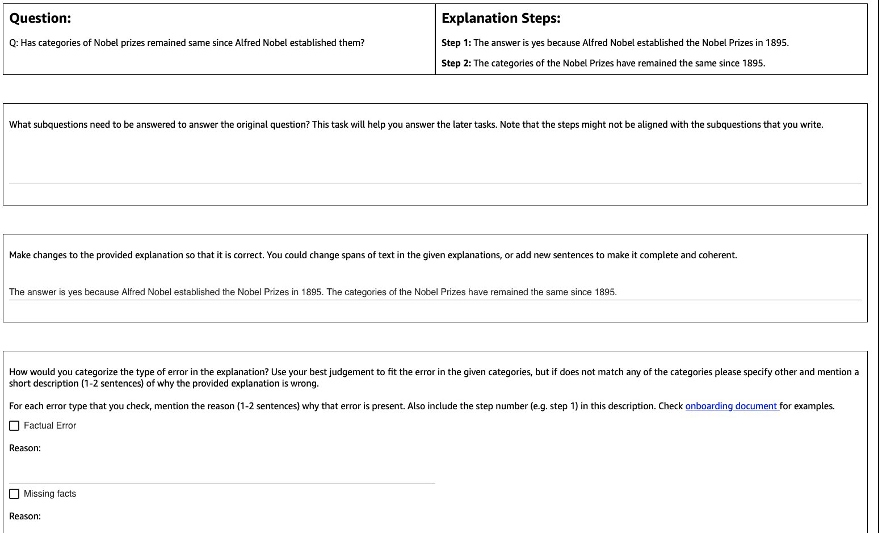
对于每个问题,我们收集了以下反馈:
- 子问题 — 注释者将原始问题分解为回答原始问题所需的更简单的子问题。此任务是在试点后添加的,我们发现添加此任务有助于让注释者做好准备并提高其余任务的质量。
- 更正 -为注释者提供一个预先填充了模型生成的答案和解释的自由格式文本框,并要求他们对其进行编辑以获得正确的答案和解释。
- 错误类型 — 我们在模型生成中发现的最常见的错误类型(事实错误、缺失的事实、不相关的事实和逻辑不一致)中,要求注释者选择一种或多种适用于给定答案和解释的错误类型。
- 错误描述 — 指示注释者不仅要对错误进行分类,还要为错误的分类提供全面的理由,包括查明错误发生的确切步骤以及错误如何适用于所提供的答案和解释。
我们在数据收集中使用了
我们收集了总共1,565个StrategyQA示例和796个体育理解示例的反馈。下表说明了在模型生成过程中没有错误的示例的百分比以及包含特定错误类型的示例的比例。值得注意的是,一些示例可能有多种错误类型。
| Error Type | StrategyQA | Sports Understanding |
| None | 17.6% | 31.28% |
| Factual Error | 27.6% | 38.1% |
| Missing Facts | 50.4% | 46.1% |
| Irrelevant Facts | 14.6% | 3.9% |
| Logical Inconsistency | 11.2% | 5.2% |
学习算法
对于每个问题 q 以及模型生成的答案和解释 m ,我们收集了以下反馈:正确答案和解释 c 、 m 中存在的错误类型 (用 t 表示 )以及错误描述 d ,如上一节所述。
我们使用了以下方法:
- 多任务学习 — 从可用的各种反馈中学习的简单基准是将每项任务视为单独的任务。更具体地说,我们 使用目标最大化 p (c|q) + p (t|q, m) + p (d|q, m) + p (d|q, m) 来微调 Flan-T5( 文本到文本)。 对于目标中的每个术语,我们使用适用于该任务的单独指令(例如,“预测给定答案中的错误”)。我们还将类别变量 t 转换为自然语言句子。在推理期间,我们使用术语 p (c|q) ( “预测给定问题的正确答案”)的指令来生成测试问题的答案。
- 加权自一致性 — 受思维链提示中成功实现自我一致性的激励,我们提出了一种加权变体。我们没有将模型中的每个抽样解释视为正确并考虑汇总投票,而是首先考虑解释是否正确,然后进行相应的汇总。我们首先以与多任务学习相同的目标对 Flan-T5 进行微调。 在推理过程中,给定一个测试问题 q ,我们使用 p (c|q) ) 的说明对多个可能的答案进行抽样:a 1 、 a2、.. 、an 。 对于每个抽样答案 ai ,我们使用术语 p (t|q, m) (“预测给定答案中的错误”) 的指令来识别它是否包含错误 t i = argmax p (t |q, a_i )。 如果答案正确,则 为每个答案 ai 分配权重 1,否则分配的权重小于 1(可调超参数)。最终答案是通过考虑对所有答案 a1 到 an 进行加权投票 来获得的 。
- 迭代细化 — 在先前提出的方法中,模型以问题 q 为 条件直接生成正确答案 。 在这里,我们建议完善模型生成的答案 m 以获得给定问题的正确答案。 更具体地说,我们首先 使用最大化 p (t; c|q, m) 微调 Flan-T5(文本到带有目标的文本) , 其中 ; 表示串联(错误类型 t 后是正确答案 c)。 看待这个目标的一种方法是,首先训练模型以识别给定第 m 代中的错误 ,然后移除该错误以获得正确答案 c 。在推理过程中,我们可以迭代使用模型,直到它生成正确的答案——给定测试问题 q ,我们首先获得初始模型生成 m (使用预训练的 Flan-T5)。然后,我们以迭代方式生成错误类型 ti 和潜在的正确答案 c i, 直到 ti = 没有错误 (实际上,我们为超参数设置了最大迭代次数),在这种情况下,最终的正确答案将为 ci-1 (从 p (ti; ci | q, ci-1) 获得)。
结果
对于这两个数据集,我们将所有提议的学习算法与情境内学习基线进行了比较。所有模型均在 StrategyQA 和 Sports Indegrance 的开发套件上进行评估。下表显示了结果。
| Method | StrategyQA | Sports Understanding |
| Flan-T5 4-shot Chain-of-Thought In-Context Learning | 67.39 ± 2.6% | 58.5% |
| Multitask Learning | 66.22 ± 0.7% | 54.3 ± 2.1% |
| Weighted Self Consistency | 61.13 ± 1.5% | 51.3 ± 1.9% |
| Iterative Refinement | 61.85 ± 3.3% | 57.0 ± 2.5% |
正如所观察到的,一些方法的表现与情境学习基准(StrategyQA 的多任务学习和运动理解的迭代细化)相当,这表明有可能收集人类对模型输出的持续反馈并使用这些反馈来改进语言模型。这与RLHF等最近的研究不同,后者的反馈仅限于分类反馈,通常是二进制的。
如下表所示,我们研究了根据人类对推理错误的反馈进行调整的模型如何有助于提高校准或对明显错误解释的认识。这是通过提示模型预测其生成是否包含任何错误来评估的。
| Method | Error Correction | StrategyQA |
| Flan-T5 4-shot Chain-of-Thought In-Context Learning | No | 30.17% |
| Multitask Finetuned Model | Yes | 73.98% |
更详细地说,我们使用自己生成的答案和推理链(我们为此收集了反馈)来提示语言模型,然后再次提示它预测生成过程中的错误。我们使用相应的任务指令(“识别答案中的错误”)。如果注释者将示例标记为没有错误,则模型预测生成中 “没有错误” 或 “正确”,或者当注释者将其标记为存在错误时,如果模型预测了生成中的任何错误类型(以及 “不正确” 或 “错误”),则该模型的评分是正确的。请注意,我们评估的不是模型正确识别错误类型的能力,而是评估是否存在错误。评估是根据StrategyQA开发集收集的另外173个示例进行的,这些示例在微调期间未被看到。其中四个示例保留用于提示语言模型(上表中的第一行)。
请注意,我们不显示 0 镜头的基线结果,因为模型无法生成有用的响应。我们观察到,使用人工反馈对推理链进行错误校正可以改善模型对是否出错的预测,从而提高对错误解释的认识或校准。
结论
在这篇文章中,我们展示了如何通过精细的错误校正来整理人类反馈数据集,这是提高法学硕士推理能力的另一种方法。实验结果证实,人类对推理错误的反馈可以改善具有挑战性的多跳问题的性能和校准。
如果你正在寻找人工反馈来改进大型语言模型,请访问
作者简介
 Erran Li
是亚马逊 亚马逊云科技 AI 人类在环服务(亚马逊云科技 AI)的应用科学经理。他的研究兴趣是三维深度学习以及视觉和语言表现学习。此前,他是 Alexa AI 的资深科学家、Scale AI 的机器学习负责人和 Pony.ai 的首席科学家。在此之前,他曾在Uber ATG的感知团队和优步的机器学习平台团队工作,致力于自动驾驶、机器学习系统和人工智能战略计划的机器学习。他的职业生涯始于贝尔实验室,曾是哥伦比亚大学的兼职教授。他在ICML'17和ICCV'19上共同教授教程,并在Neurips、ICML、CVPR、ICCV共同组织了多个研讨会,内容涉及自动驾驶的机器学习、三维视觉和机器人、机器学习系统和对抗性机器学习。他在康奈尔大学拥有计算机科学博士学位。他是 ACM 研究员和 IEEE 研究员。
Erran Li
是亚马逊 亚马逊云科技 AI 人类在环服务(亚马逊云科技 AI)的应用科学经理。他的研究兴趣是三维深度学习以及视觉和语言表现学习。此前,他是 Alexa AI 的资深科学家、Scale AI 的机器学习负责人和 Pony.ai 的首席科学家。在此之前,他曾在Uber ATG的感知团队和优步的机器学习平台团队工作,致力于自动驾驶、机器学习系统和人工智能战略计划的机器学习。他的职业生涯始于贝尔实验室,曾是哥伦比亚大学的兼职教授。他在ICML'17和ICCV'19上共同教授教程,并在Neurips、ICML、CVPR、ICCV共同组织了多个研讨会,内容涉及自动驾驶的机器学习、三维视觉和机器人、机器学习系统和对抗性机器学习。他在康奈尔大学拥有计算机科学博士学位。他是 ACM 研究员和 IEEE 研究员。
 Nitish Joshi
是亚马逊 亚马逊云科技 AI 的应用科学实习生。他是纽约大学库兰特数学科学研究所计算机科学博士生,由何教授提供咨询。他从事机器学习和自然语言处理方面的工作,他隶属于语言机器学习 (ML2) 研究小组。他对稳健的语言理解有着广泛的兴趣:既要构建能够抵御分布变化的模型(例如通过人机在环数据增强),也要设计更好的方法来评估/测量模型的稳健性。他还对情境学习及其运作原理的最新发展感到好奇。
Nitish Joshi
是亚马逊 亚马逊云科技 AI 的应用科学实习生。他是纽约大学库兰特数学科学研究所计算机科学博士生,由何教授提供咨询。他从事机器学习和自然语言处理方面的工作,他隶属于语言机器学习 (ML2) 研究小组。他对稳健的语言理解有着广泛的兴趣:既要构建能够抵御分布变化的模型(例如通过人机在环数据增强),也要设计更好的方法来评估/测量模型的稳健性。他还对情境学习及其运作原理的最新发展感到好奇。
 库马尔·切拉皮拉
是亚马逊网络服务的总经理兼总监,领导机器学习/人工智能服务的开发,例如人机交互系统、人工智能 DevOps、地理空间机器学习和 ADAS/自动驾驶汽车开发。在加入 亚马逊云科技 之前,Kumar 曾担任 Uber ATG 和 Lyft Level 5 的工程总监,带领团队使用机器学习开发感知和测绘等自动驾驶功能。他还致力于应用机器学习技术来改进LinkedIn、Twitter、Bing和微软研究院的搜索、推荐和广告产品。
库马尔·切拉皮拉
是亚马逊网络服务的总经理兼总监,领导机器学习/人工智能服务的开发,例如人机交互系统、人工智能 DevOps、地理空间机器学习和 ADAS/自动驾驶汽车开发。在加入 亚马逊云科技 之前,Kumar 曾担任 Uber ATG 和 Lyft Level 5 的工程总监,带领团队使用机器学习开发感知和测绘等自动驾驶功能。他还致力于应用机器学习技术来改进LinkedIn、Twitter、Bing和微软研究院的搜索、推荐和广告产品。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。