在线事务处理 (OLTP) 数据库是高可用性应用程序的关键组成部分。关键业务工作负载可以利用多可用区配置中的
A mazon Aurora
数据库集群来帮助延长其整体正常运行时间,并减少多可用区故障转移等可用性相关事件的影响。
在这篇文章中,我们将讨论 Amazon Aurora 在高可用性背景下与客户端连接和 DNS 终端节点相关的各个方面。我们使用故障转移场景来演示可能影响客户端应用程序的连接问题,并提供检测和避免这些问题的建议。本文中包含的示例使用
亚马逊Aurora MySQL兼容版本 ,但相同的一般概念适用于兼容
亚马逊
Aurora PostgreSQL的版本。
亚马逊 Aurora 中的客户连接
客户使用 DNS 终端节点连接到 Amazon Aurora 资源(数据库实例)。Aurora 数据库集群提供多种类型的终端节点,包括
写入器终端节点、
读取器终端节点
、
实例终端
节点和可选的客户定义的
自定义终端节点
。这些终端节点将客户端连接定向到集群中的相应实例,例如具有读取/写入功能的主实例和只读副本。有关更多信息,请参阅
Aurora 连接管理文档
。
Aurora 会在需要时自动更新 DNS 终端节点,例如在故障转移期间或添加、删除或重命名数据库实例时。当端点发生变化时,客户端应用程序必须尽快识别更改,以避免连接问题。Aurora 终端节点使用 5 秒
生存 时间
(TTL) 设置,但客户端环境配置可能会在 DNS 更改的传播中引入额外的延迟。故障转移是非常不希望出现这种延迟的典型示例,因为它会延长应用程序恢复时间并增加停机时间。
亚马逊 Aurora 故障转移机制
下图说明了具有单个主实例和一个或多个副本的典型设置中的 Aurora 的存储和计算架构。在这样的设置中,应用程序通常通过两个终端节点访问 Aurora 数据库实例:指向当前主实例(写入器)的写入器端点和包含所有可用副本的只读终端节点。
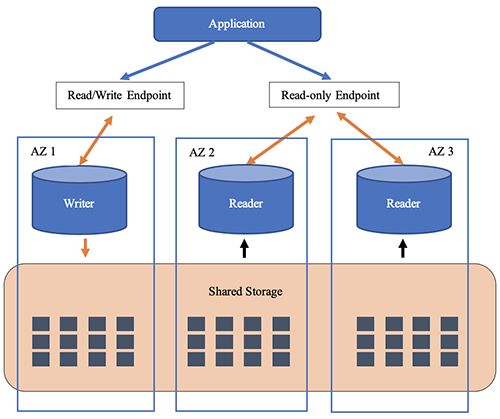
当问题影响主实例时,其中一个读取器实例会通过一个称为故障转移的过程接管。您也可以通过 RDS 管理控制台或使用 FailoverD
bCluster API 启动手动故障
转移。
发生故障转移时,Aurora 会执行以下步骤:
-
选择其中一个读取器实例作为新的主要读取器实例。选择过程基于多个因素,例如实例类型、可用区域和客户配置的故障转移优先级。有关详情,请参阅
Amazon Aurora 的高可用
性 文档部分。
-
以读/写模式重启所选实例。
-
以只读模式重新启动旧的主节点。
-
更新 writer 端点,使其指向新升级的实例。
-
更新读取器端点,使其包含重新启动的旧主实例(新的读取器实例)。
从头到尾,故障转移通常在 30 秒内完成。您可以通过访问 RDS 管理控制台中的事件选项卡或使用 Desc
ribeE
vents API 来了解有关故障转移步骤顺序和时间的更多信息。
例如,以下屏幕截图显示了从 aurora-testance-1 故障转移到 aurora-testance-2 之后
Aurora 集群 a
ur
ora-t
estance-2 的 RDS 事件。

在此示例中,故障转移操作是手动启动的,这使我们有机会以可控的方式衡量客户机影响。测试客户端的操作系统和网络设置不使用 DNS 缓存,为了使测试输出更具可读性,我们将以下设置放在
~/.my.cnf
文件中:
[mysql]
connect_timeout=1
[client]
user=USERNAME
password=PASSWORD
我们运行下面的 shell 命令每秒 ping 一次写入器端点,并报告实例角色(写入者或读取者)。
while true; do mysql -haurora-test.cluster-xxx.us-west-2.rds.amazonaws.com --batch --skip-column-names -e "select now(), if(@@innodb_read_only = 1, 'reader', 'writer')"; sleep 1; done;
命令运行后,我们启动手动故障转移并观察输出:
2022-12-09 18:57:01 writer
2022-12-09 18:57:02 writer
2022-12-09 18:57:03 writer
2022-12-09 18:57:04 writer
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
2022-12-09 18:57:12 reader
2022-12-09 18:57:13 reader
2022-12-09 18:57:14 writer
2022-12-09 18:57:15 writer
根据输出,可用性中断了大约 10 秒。在此期间,客户一直在尝试与这位老作家建立联系,包括在那位作家已经被降级为读者几秒钟之后。这说明了我们的第一个挑战:客户端必须等待 DNS 更新才能识别出新的写入者。
现在让我们运行同样的测试,但是这次通过在客户端系统的
/etc/
hosts 文件中对主服务器的 IP 进行硬编码来阻止客户端获取 DNS 更改。通过这样做,我们模拟了客户端无限期缓存 DNS 条目的情况:
# cat /etc/hosts
(...)
XX.XX.XX.XX aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com
现在,再次运行相同的命令并观察输出:
2022-12-09 19:12:43 writer
2022-12-09 19:12:44 writer
2022-12-09 19:12:45 writer
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
(... message repeats as previously ...)
2022-12-09 19:12:55 reader
2022-12-09 19:12:56 reader
2022-12-09 19:12:57 reader
2022-12-09 19:12:58 reader
(... the output continues to report “reader” instance status ...)
使用模拟 DNS 缓存,我们再次观察到大约 10 秒的停机时间,但随后客户端开始向 “读取器” 报告连接,并且从未切换到 “写入器”。它表明客户端没有关注 DNS 更新,而是无限期地向旧的主实例发送查询。如果旧的主服务器受到实际问题的影响,我们会看到连接错误,而不是实例以 “读取器” 的身份响应。这说明了我们的第二个挑战:受到 DNS 缓存约束的客户端可能迟迟无法识别新写入器,或者根本无法识别它。
由于应用程序堆栈中的 DNS 缓存,现实世界中的应用程序中可能会出现类似的问题。它可能是由网络设置中使用的缓存 DNS 解析器、在客户端操作系统中运行的 DNS 缓存,甚至是应用程序的执行环境设置(例如,
Java 虚拟机 中的 DNS TTL 设置
)引起的。
识别由 DNS 传播延迟造成的问题
在现实环境中,您可以通过观察涉及端点更改的事件期间的应用程序行为来识别由 DNS 传播延迟引起的潜在问题。如果涉及 DNS 延迟,您可能会看到以下症状:
-
故障转移后出现
错误消息,例如第 1 行的 “错误 1290 (HY000):MySQL 服务器正在使用 —readly 选项运行,因此无法执行此语句
”,表示应用程序正在尝试写入只读实例。
-
在 Aurora 发出 “
故障转移 已完成
” RDS 事件很久之后,就会出现
连接 错误,例如 “错误 2003 (HY000):无法连接到 MySQL 服务器
”。
-
即使 Aurora 发出 “
故障转移 已完成
” 事件,客户端在尝试打开连接时仍处于挂起状态。
-
重命名或删除实例后出现诸如 “
错误 2005 (HY000):未知的 MySQL 服务器主机
” 之类的错误。
-
如果使用包含所有副本的集群只读 DNS 终端节点,则可以在删除副本后观察到连接错误,或者在添加新闻副本后观察到工作负载分布不均匀。
要调查潜在的 DNS 连接问题,请查阅 RDS 事件记录以确认底层事件(例如故障转移)何时开始以及何时结束。然后,查看应用程序日志并确定应用程序出现匹配症状的时间范围。如果应用程序在事件开始时开始出现症状,但直到事件结束很久之后才恢复,则表明应用程序没有接受 DNS 更改。
解决由 DNS 传播延迟造成的问题
如果您认为您的应用程序可能会受到 DNS 传播延迟的影响,则可以考虑几种解决方案。
检查并调整客户端 DNS 缓存设置
如前所述,Aurora DNS 区域使用的生存时间 (TTL) 为 5 秒。你可以通过使用 dig 命令解析端点来确认这一点。响应的答案部分显示了端点的 IP 地址和记录的 TTL:
[ec2-user@ip-XX-XX-XX-XX ~]$ dig <Aurora read/write endpoint>
...
;; ANSWER SECTION:
<Aurora read/write endpoint>. 5 IN A XX.XX.XX.XX
...
;; SERVER: 172.31.0.2#53(172.31.0.2)
...
您还可以在输出底部找到 DNS 服务器地址。如果服务器不同于默认 VPC DNS 服务器(网络范围加两个,这里是
172.31.0.2
),则客户端正在使用自定义 DNS 服务器,这可能会在默认 TTL 之外引入延迟。你会注意到,当你多次运行命令时,TTL 将在重置为基准值之前倒计时为零。基值不同于 5 表示客户端的 DNS 服务器会覆盖默认 TTL。
例如,以下输出表明客户端使用本地 DNS 缓存(由服务器地址
127.0.0.1
表示 ),TTL 为 120 秒(2 分钟)。因此,在 Aurora 故障转移期间,该客户端可能会经历多达 2 分钟的额外停机时间:
[ec2-user@ip-XX-XX-XX-XX ~]$ dig <Aurora read/write endpoint>
...
;; ANSWER SECTION:
<Aurora read/write endpoint>. 120 IN A XX.XX.XX.XX
...
;; SERVER: 127.0.0.1#53(127.0.0.1)
...
使用缓存 DNS 解析器没有根本错误,甚至可能是防止 DNS 解
析限制
所必需的。也就是说,如果您必须使用 DNS 缓存,请将 TTL 保持在尽可能低的水平,并避免使用更高的自定义值覆盖默认 TTL。在调查 DNS 缓存问题时,请记住检查应用程序堆栈的所有层,包括虚拟环境(例如 JVM)和容器。
请记住,DNS 系统是分层的,因此在缓存层配置的任何 TTL 值都将计入 Aurora 区域的现有 5 秒 TTL。因此,调整客户端设置可以帮助避免在默认 DNS 行为之外出现额外的 DNS 延迟(从而避免额外的停机时间),但客户端仍将依赖 DNS 来识别实例角色的变化。
使用亚马逊 RDS 代理
亚马逊 RDS 代理
是亚马逊 Aurora 和
亚马逊关系数据库服务
(RDS) 的托管代理。除了连接池和多路传输等常见代理功能外,RDS 代理绕过集群 DNS 终端节点,直接连接到数据库实例,从而帮助最大限度地减少应用程序停机时间。
与 Aurora 配对时,RDS 代理提供读/写和只读 DNS 终端节点,可供使用,而不是 Aurora 集群可用的终端节点。关键区别在于,代理端点在数据库故障转移期间不会发生变化,因此客户端不会错过任何可能错过的 DNS 更新。代理继续接受同一 Endpoint/IP 下的客户端连接,监控数据库实例的状态,并自动将读取和写入查询定向到可用实例。它甚至可以在不中断空闲连接的情况下处理故障转移,这进一步减少了对应用程序可用性的影响。
使用 RDS 代理有助于避免前面列出的所有问题:
-
客户端不再需要识别实例角色的变化。RDS 代理根据集群元数据自动跟踪实例角色,无需使用 DNS。
-
代理提供不变的静态端点,因此客户端不会因 DNS 更改(例如添加、删除或重命名实例时)而看到延迟或连接错误。
-
在建立新的副本之前,代理会考虑每个副本的连接数,因此大大降低了工作负载分布不均匀的风险。
有关在 Aurora 集群中使用 RDS 代理的更多信息,请参阅
RDS 代理 入门
。
让我们使用前面介绍的客户端命令来演示 RDS 代理。这次,我们将使用两个同步的客户端会话进行并排比较。除 DNS 端点外,这些命令是相同的:其中一个会话 ping 集群的写入端点,另一个会话 ping 代理读/写端点。未使用 DNS 缓存,我们从/
et
c/hosts 中删除了经过硬编码的集群 IP。
使用内置集群写入器端点的示例命令:
while true; do mysql -haurora-test.cluster-xxx.us-west-2.rds.amazonaws.com --batch --skip-column-names -e "select now(), if(@@innodb_read_only = 1, 'reader', 'writer')"; sleep 1; done;
使用代理端点的示例命令:
while true; do mysql -htest-proxy.proxy-xxx.us-west-2.rds.amazonaws.com --batch --skip-column-names -e "select now(), if(@@innodb_read_only = 1, 'reader', 'writer')"; sleep 1; done;
在两个命令都运行的情况下,启动故障转移并观察输出。使用集群编写器端点的结果看起来很熟悉:
2022-12-13 02:22:41 writer
2022-12-13 02:22:42 writer
2022-12-13 02:22:43 writer
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 'aurora-test.cluster-xxx.us-west-2.rds.amazonaws.com:3306' (111)
2022-12-13 02:22:51 reader
2022-12-13 02:22:52 writer
2022-12-13 02:22:53 writer
以下是代理端点的输出,为了便于阅读,进行了注释:
2022-12-13 02:22:41 writer
2022-12-13 02:22:42 writer
2022-12-13 02:22:43 writer << downtime starts here
2022-12-13 02:22:45 writer << downtime ends here
2022-12-13 02:22:46 writer
2022-12-13 02:22:47 writer
2022-12-13 02:22:48 writer
2022-12-13 02:22:49 writer
2022-12-13 02:22:50 writer
2022-12-13 02:22:51 writer
由于代理能够快速检测实例角色的变化,而且不包括DNS更新,因此差异非常惊人。该客户端不仅避免了连接错误,而且停机时间仅为两秒钟,比 DNS 更改的停机时间(10 秒)少了 80%。
使用适用于 MySQL 和 PostgreSQL 的 亚马逊云科技
亚马逊云科技 数据库驱动程序旨在减少应用程序停机时间并避免 DNS 传播问题。适用于 MySQL 的开源
亚马逊云科技 JDBC 驱动程序 和适用于 PostgreSQ
L 的 亚马逊云科技 JDBC 驱动程序 是为
Java 应用程序构建的智能驱动程序的很好的例子。当驱动程序连接到 Aurora 集群时,它会从
复制状态表
中学习集群拓扑。然后,它会监视各个实例并相应地更新其拓扑元数据。拓扑元数据用于将客户端连接和查询定向到相应的实例。
下图描述了应用程序、适用于 MySQL 的 亚马逊云科技 JDBC 驱动程序和数据库之间的交互:
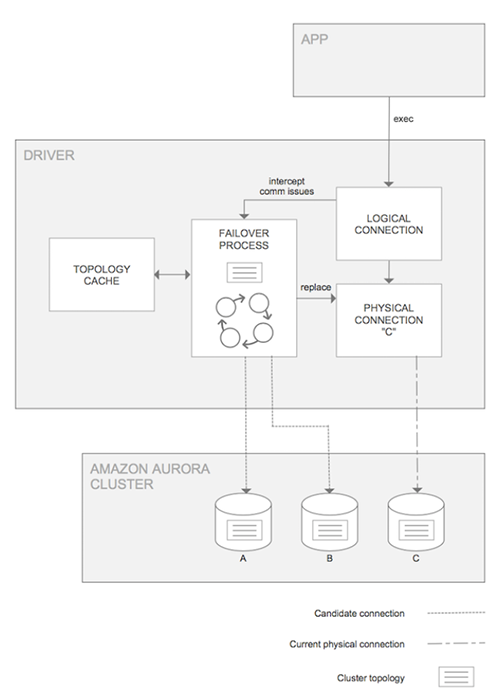
对于每个客户端会话,驱动程序都保持逻辑连接(应用程序到驱动程序)和物理连接(驱动程序到数据库)。如果物理连接因故障转移而失败,则驱动程序会注意到故障并启动自己的故障转移处理协议,同时保持逻辑连接处于活动状态。一经推广,它就会发现一个新的作者实例。检测到新的写入器后,驱动程序会打开新的物理连接并将控制权返回给客户端。
适用于 MySQL 的 亚马逊云科技 JDBC 驱动程序使用以 jdbc: mysql: aws 开头的连接字符串 URL,但除此以外,它可以用作其他 Java 的 MySQL 驱动程序的直接替代品:
jdbc:mysql:aws://<cluster name>.<cluster id>.<region>.rds.amazonaws.com:3306/<database name>?useSSL=<true>&characterEncoding=<utf-8>
Aurora 的更快故障转移处理在默认情况下处于启用状态,可以通过调整驱动程序参数来禁用。请注意,适用于 MySQL 的 亚马逊云科技 JDBC 驱动程序主要用于减少故障转移的影响,但不支持当前 RDS 代理提供的连接多路传输或负载平衡。由于驱动程序分别在每台客户端计算机上运行,因此最终结果将部分取决于客户端架构和行为。
要详细了解 亚马逊云科技 JDBC 驱动程序与其他驱动程序相比的故障转移性能,请阅读我们的文章:
使用适用于 Amazon Aurora MySQL 的 亚马逊云科技 JDBC 驱动程序 提高应用程序可用性
。
如果您的客户端不使用 JDBC 接口,您仍然可以使用驱动程序的故障转移处理逻辑作为灵感,在应用程序中构建类似的功能。这样做时,你可以使用以下构件:
-
用于学习集群拓扑的
复制状态表
。
-
用于确定实例角色(作者或
读者)的 innodb_read_
only 变量。
-
运行状况检查查询的超时时间足够短,可以快速发现问题,但不够短,不足以导致假阴性结果。
在出现连接问题时改善应用程序响应
上述选项可以通过解决客户端配置问题来解决可用性和 DNS 传播问题,或者更广泛地说,通过在客户端和数据库之间引入智能抽象层来解决可用性和 DNS 传播问题。如果你无法使用这些选项中的任何一个,仍然有办法改善应用程序对故障转移和其他连接相关事件的响应。
示例:
-
对查询错误引入显式异常处理,这些错误表明连接上重复出现了预期可写的只读错误。检测到错误后,应用程序可以尝试修复步骤,例如重新打开连接或重新启动应用程序容器。
-
通过订阅
RDS
事件来检测故障转移和其他可用性事件。 事件订阅可用于为数据库操作员生成警报,或调用自动化例程,例如应用程序重启。
-
定期分析应用程序日志,以检测和调查意外连接关闭、超时和其他错误,这些错误表明实际数据库状态与应用程序假定的状态不一致。
结论
通过充分利用 Aurora 的快速故障转移功能,可以极大地提高关键业务工作负载的可用性。在这篇文章中,我们讨论了故障转移期间可能延长应用程序停机时间的问题,并提出了许多解决方案。总的来说,RDS Proxy 是最完整的解决方案,应该可以很好地适用于各种应用程序和客户端类型。如果您的应用程序使用 Java 编程语言,亚马逊云科技 JDBC 驱动程序是一个不错的选择。最后,在没有诸如代理之类的抽象层的情况下,有针对性地改进应用程序的错误处理逻辑可能会有所帮助。
如果您有任何意见或问题,请将其留在评论部分。
作者简介
 Lili Ma
是 亚马逊云科技 的数据库解决方案架构师,在数据库行业拥有超过 10 年的经验。Lili 参与了 Hadoop/Hive NoSQL 数据库、企业级数据库 DB2、分布式数据仓库 Greenplum/Apache HAWQ 以及亚马逊 Aurora、亚马逊 ElastiCache 和亚马逊 MemoryDB 等亚马逊云原生数据库的研发。
Lili Ma
是 亚马逊云科技 的数据库解决方案架构师,在数据库行业拥有超过 10 年的经验。Lili 参与了 Hadoop/Hive NoSQL 数据库、企业级数据库 DB2、分布式数据仓库 Greenplum/Apache HAWQ 以及亚马逊 Aurora、亚马逊 ElastiCache 和亚马逊 MemoryDB 等亚马逊云原生数据库的研发。
 Szymon Komendera
是 亚马逊云科技 的数据库解决方案架构师,在数据库、软件开发和应用程序可用性方面拥有近 20 年的经验。他在亚马逊云科技任职的8年大部分时间里都在开发Aurora MySQL,并为亚马逊 Redshift 和亚马逊 ElastiCache 等其他 亚马逊云科技 数据库提供支持。
Szymon Komendera
是 亚马逊云科技 的数据库解决方案架构师,在数据库、软件开发和应用程序可用性方面拥有近 20 年的经验。他在亚马逊云科技任职的8年大部分时间里都在开发Aurora MySQL,并为亚马逊 Redshift 和亚马逊 ElastiCache 等其他 亚马逊云科技 数据库提供支持。