我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
通过将查询 PostgreSQL 传送到亚马逊 RDS 和亚马逊 Aurora PostgreSQL 来提高应用程序性能
目前,有相当一部分的 OLTP 和 OLAP 应用程序使用 PostgreSQL 并经常运行数据查询。查询可用于插入、更新、删除或提取信息。时间至关重要,最终用户期望毫不拖延地从这些查询中获得结果。在这
在这篇文章中,我们回顾了一家零售公司的示例,该零售公司拥有多家门店,需要分析其销售数据。数据可以存储在适用于 PostgreSQL 的 RDS 或 Aurora 数据库中。该公司希望计算每家商店的总销售额,并生成一份报告,其中包括商店名称、总销售额以及每家商店对总销售额的贡献百分比。我们展示了 PostgreSQL 中的管道模式如何通过最大化单个网络交易中发送的数据量来优化报告的生成。
解决方案概述
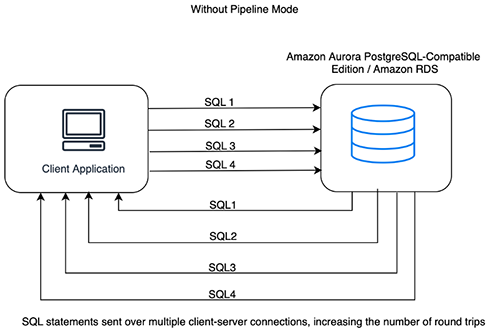
在我们开始使用管道模式之前,了解客户端和 PostgreSQL 服务器如何相互通信非常重要。向数据库发出查询时,该语句将作为请求传输到 PostgreSQL 服务器,这构成了第一次网络旅行。服务器获得结果后,将其传回客户端,分两步完成此请求的整个网络旅行。
假设我们必须向网络延迟为 200 毫秒的服务器发送 50 个请求。在这种情况下,仅网络旅行,整个查询序列就需要 10 秒。管道模式可以减少网络延迟,但它可以在客户端和服务器上使用更多的内存。但是,可以通过谨慎管理发送/接收队列来缓解这种情况。下图说明了这个工作流程。
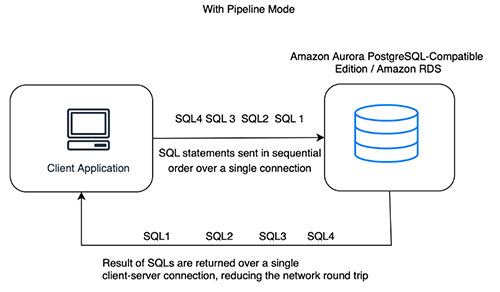
使用管道模式,我们示例中的网络跳闸等待时间减少到仅 0.2 秒,因为只需要一次行程。下图说明了更新的工作流程。
在以下部分中,我们将介绍如何在 Python 语言中使用管道模式。
切换连接模式
在 PostgreSQL 中,
连接模式
是指客户端应用程序连接到 PostgreSQL 服务器的方式。要使用管道,应用程序必须将连接切换到管道模式。PostgreSQL 数据库适配器 Ps
使用管道模式进行查询
将应用程序使用的连接设置为管道模式后,连接可以将多个操作分组为更长的消息流。这些请求在客户端排队直到刷新到服务器,当调用
sync ()
操作在管道中建立同步点时,就会发生这种情况。服务器运行语句并按从客户端接收到的相同顺序返回结果。服务器立即开始在管道中运行命令,无需等待管道结束。因此,客户可以在一次往返中收到多个响应。
让我们使用之前的连接运行两个操作:
我们可以使用一个或多个游
标使用 Connection.Execute () 、c ursor.Execute ()
和 execut
在管道块中运行多个操作:
em
any ()
处理结果
在管道模式下,Psycopg 不会等待服务器收到每个查询的结果。相反,当服务器刷新其输出缓冲区时,客户端会成批接收结果。这与普通模式行为不同。
执行刷新(或同步)时,所有待处理的结果都将发送回运行这些结果的游标。如果游标运行了多个查询,它将按运行顺序收到多个结果。参见以下代码:
错误和异常
值得注意的是,服务器将所有以管道模式发送的语句封装在隐式
在以下代码中,表清单不存在,这会导致区块中出现由插入语句引起的错误:
错误消息将由
sync ()
调用引发。在区块的末尾,
mytable
表将包含以下内容:
管道模式的局限性
尽管管道模式有益于网络延迟,但值得注意的是,它可能不适合所有查询,并且可能会增加应用程序的复杂性。仅允许使用扩展查询协议的异步操作。某些命令字符串是不允许的,包括包含多个 SQL 命令和
结论
在这篇文章中,我们了解了流水线 PostgreSQL 查询如何通过减少网络上的查询延迟来帮助提高整体应用程序性能。尽管管道模式可以为某些工作负载提供性能优势,但在决定使用管道模式之前,仔细评估每个查询的具体要求很重要。总体而言,PostgreSQL 流水线模式是一项强大的功能,可以提高依赖 PostgreSQL 进行数据处理的应用程序的性能。
如果您对此帖子有任何意见或疑问,请在评论部分提交。
作者简介
 Anjali Dhanerwal
是印度企业支持部的技术客户经理。她于 2022 年加入 亚马逊云科技,支持客户设计和构建高度可扩展、弹性和安全的解决方案。她还是数据库社区和云运营社区的一员,其重点领域包括亚马逊 Aurora、适用于 PostgreSQL 的亚马逊 RDS 以及架构运行状况和云优化。
Anjali Dhanerwal
是印度企业支持部的技术客户经理。她于 2022 年加入 亚马逊云科技,支持客户设计和构建高度可扩展、弹性和安全的解决方案。她还是数据库社区和云运营社区的一员,其重点领域包括亚马逊 Aurora、适用于 PostgreSQL 的亚马逊 RDS 以及架构运行状况和云优化。
 穆罕默德·阿萨杜拉·拜格
是印度企业支持部的高级技术客户经理。他于 2017 年加入 亚马逊云科技,帮助客户规划和构建高度可扩展、弹性和安全的解决方案。除了担任高级助理经理外,他还专门研究亚马逊 Aurora 和适用于 PostgreSQL 的亚马逊 RDS 等数据库。他通过为多家企业客户提供各种 亚马逊云科技 服务,为他们提供了帮助,并提供了实现卓越运营的指导。
穆罕默德·阿萨杜拉·拜格
是印度企业支持部的高级技术客户经理。他于 2017 年加入 亚马逊云科技,帮助客户规划和构建高度可扩展、弹性和安全的解决方案。除了担任高级助理经理外,他还专门研究亚马逊 Aurora 和适用于 PostgreSQL 的亚马逊 RDS 等数据库。他通过为多家企业客户提供各种 亚马逊云科技 服务,为他们提供了帮助,并提供了实现卓越运营的指导。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。