我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 EventBridge 在 CDK 管道中实现自动漂移检测
使用CloudFormation堆栈,有人有可能在CloudFormation和部署堆栈的管道的权限之外手动更改堆栈资源的配置。这会导致部署的资源与应用程序中的意图不一致,这被称为 “漂移”,这种情况可能会使应用程序的行为变得不可预测。例如,在对应用程序进行故障排除时,如果应用程序已进入生产阶段,则很难在开发环境中重现相同的行为。在其他情况下,它可能会在应用程序中引入安全漏洞。例如,最初为允许来自特定 IP 地址的入站流量而部署的
CloudFormation 为堆栈和堆栈资源提供
在这篇博客文章中,您将了解如何使用事件驱动的方法将CloudFormation漂移检测作为部署前验证步骤集成到CDK管道中。
解决方案概述
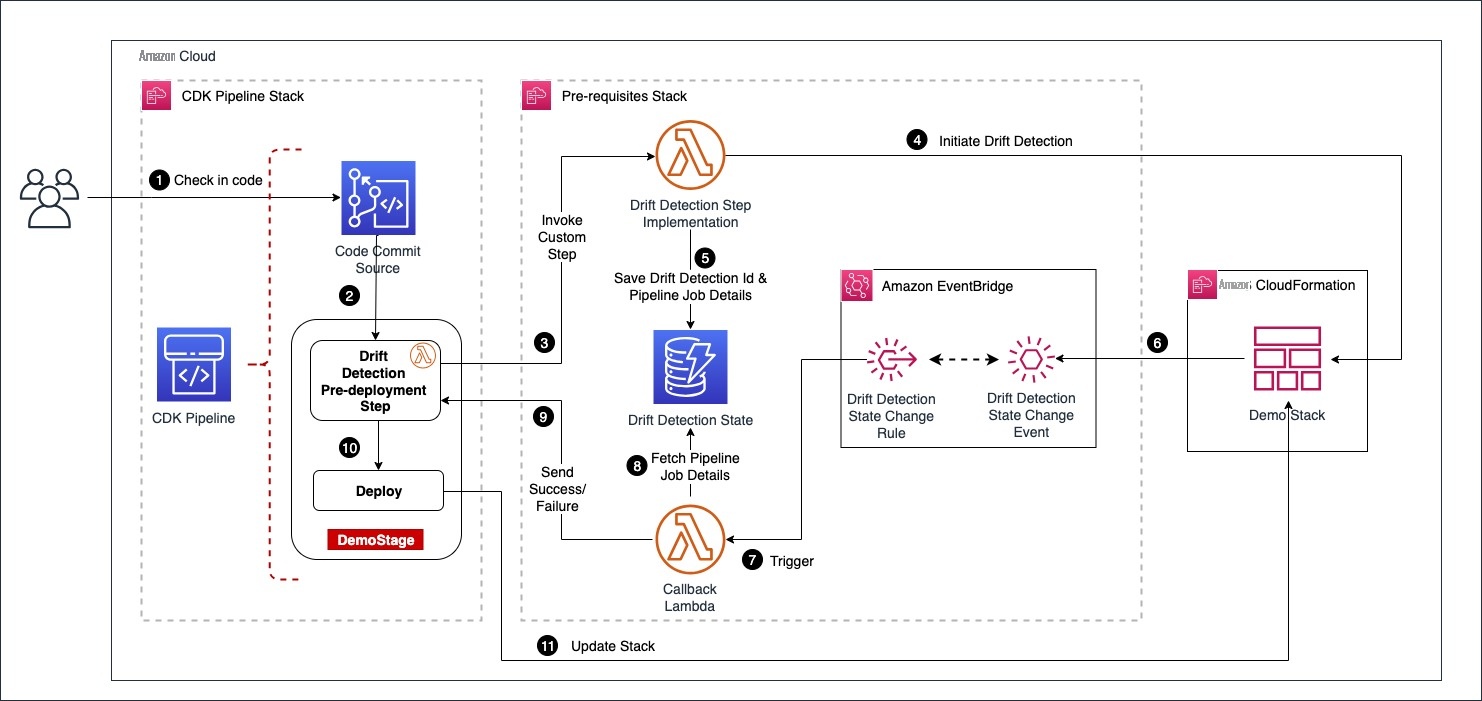
架构图
用户通过将代码存入
当漂移检测步骤调用提供商 lambda 函数时,它首先在 CloudFormation 堆栈
同时,管道正在等待对漂移检测状态的响应。
演示
堆栈上启动漂移检测,然后将 drift_detection_id 与管道_job
_id 一起保存到 D
ynamoDB 表中。
EventBridge 规则的设置是为了捕获默认事件总线接收到的
演示堆栈
的漂移检测状态变化事件。回调 lambda 已注册为规则的预期目标。
回调 lambda 函数 从 DynamoDB 中提取 pi
漂移检测完成后,它会触发 EventBridge 规则,该规则反过来调用回调 lambda 函数,堆栈状态为 DRIFTED 或 IN SYNC。
peline_job_id
并将相应的状态发送回管道,从而使管道退出等待状态。如果堆栈处于 IN
SYNC
状态,则回调 lambda 会发送成功状态,管道将继续部署。 如果堆栈处于
DRIFTED
状态,则回调 lambda 将失败状态发送回管道,管道运行最终以失败告终。
解决方案深度探讨
该解决方案部署了两个堆栈,如上面的架构图所示
- CDK 管道堆栈
- 必备堆栈
CDK Pipelines 堆栈定义了一个流水线,其中集成了 CodeCommit 源代码和漂移检测步骤。必备堆栈部署 CDK Pipelines 堆栈所需的以下资源。
- 实现漂移检测步骤的 Lambda 函数
-
一个保存 drift_detection_id 和 pipeline_job_id 的 DynamoDB 表 - 用于捕获 “CloudFormation 漂移检测状态更改” 事件的事件桥接规则
- 一个回调 lambda 函数,用于评估漂移检测的状态,并通过查找 DynamoDB 中捕获的数据将状态发送回管道。
先部署先决条件堆栈,然后部署 CDK Pipelines 堆栈。
定义漂移检测步骤
CDK Pipelines 提供了一
首先,你要定义一个名为
DriftDetectionStep 的类 ,该类扩展了 St
ep 并实现了
icodePipeline
ActionFactory,如以下代码片段所示。构造函数接受 3 个参数
StackName
、
账户
、
区域 作为输入
。
当管道运行该步骤时,它会调用漂移检测 lambda 函数,并将这些参数封装在 UserParameters 变量中。
函数 p
roduceAction ()
将调用漂移检测 lambda 函数的操作添加到管道阶段。
请注意,该解决方案使用
export class DriftDetectionStep
extends Step
implements pipelines.ICodePipelineActionFactory
{
constructor(
private readonly stackName: string,
private readonly account: string,
private readonly region: string
) {
super(`DriftDetectionStep-${stackName}`);
}
public produceAction(
stage: codepipeline.IStage,
options: ProduceActionOptions
): CodePipelineActionFactoryResult {
// Define the configuraton for the action that is added to the pipeline.
stage.addAction(
new cpactions.LambdaInvokeAction({
actionName: options.actionName,
runOrder: options.runOrder,
lambda: lambda.Function.fromFunctionArn(
options.scope,
`InitiateDriftDetectLambda-${this.stackName}`,
ssm.StringParameter.valueForStringParameter(
options.scope,
SSM_PARAM_DRIFT_DETECT_LAMBDA_ARN
)
),
// These are the parameters passed to the drift detection step implementaton provider lambda
userParameters: {
stackName: this.stackName,
account: this.account,
region: this.region,
},
})
);
return {
runOrdersConsumed: 1,
};
}
}
在 CDK 管道中配置漂移检测步骤
在这里,您将看到如何将先前定义的漂移检测步骤集成到 CDK Pipelines 中。该管道有一个名为
demoStage 的阶段
,如以下代码片段所示。在构建
DemoStag
e 期间 ,我们将漂移检测宣布为部署前的步骤。这可确保管道在部署之前始终进行漂移检测检查。
请注意,对于阶段中定义的每个堆栈,我们添加了一个专门的步骤,通过实例化上一节中详述的 Dri
ftDetectionStep
类来执行漂移检测。因此,该解决方案可根据每个阶段定义的堆栈数量进行扩展。
export class PipelineStack extends BaseStack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
const repo = new codecommit.Repository(this, 'DemoRepo', {
repositoryName: `${this.node.tryGetContext('appName')}-repo`,
});
const pipeline = new CodePipeline(this, 'DemoPipeline', {
synth: new ShellStep('synth', {
input: CodePipelineSource.codeCommit(repo, 'main'),
commands: ['./script-synth.sh'],
}),
crossAccountKeys: true,
enableKeyRotation: true,
});
const demoStage = new DemoStage(this, 'DemoStage', {
env: {
account: this.account,
region: this.region,
},
});
const driftDetectionSteps: Step[] = [];
for (const stackName of demoStage.stackNameList) {
const step = new DriftDetectionStep(stackName, this.account, this.region);
driftDetectionSteps.push(step);
}
pipeline.addStage(demoStage, {
pre: driftDetectionSteps,
});
演示
在这里,您将了解解决方案的部署步骤,并查看漂移检测的实际运行情况。
部署先决条件堆栈
从此
部署 CDK 管道堆栈
从此
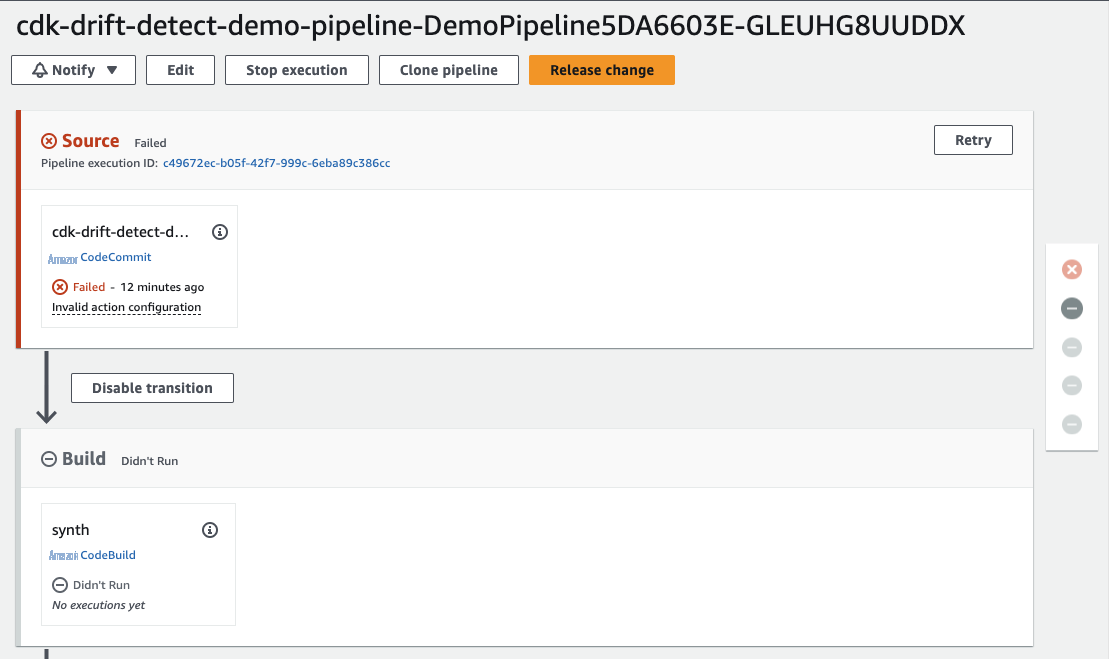
script-deploy.sh
。这将部署一个以空的 CodeCommit 存储库作为源代码的管道。由于 CodeCommit 存储库为空,管道运行最终失败,如下所示。
接下来,将克隆存储库中的代码签入 CodeCommit 源存储库。你可以在
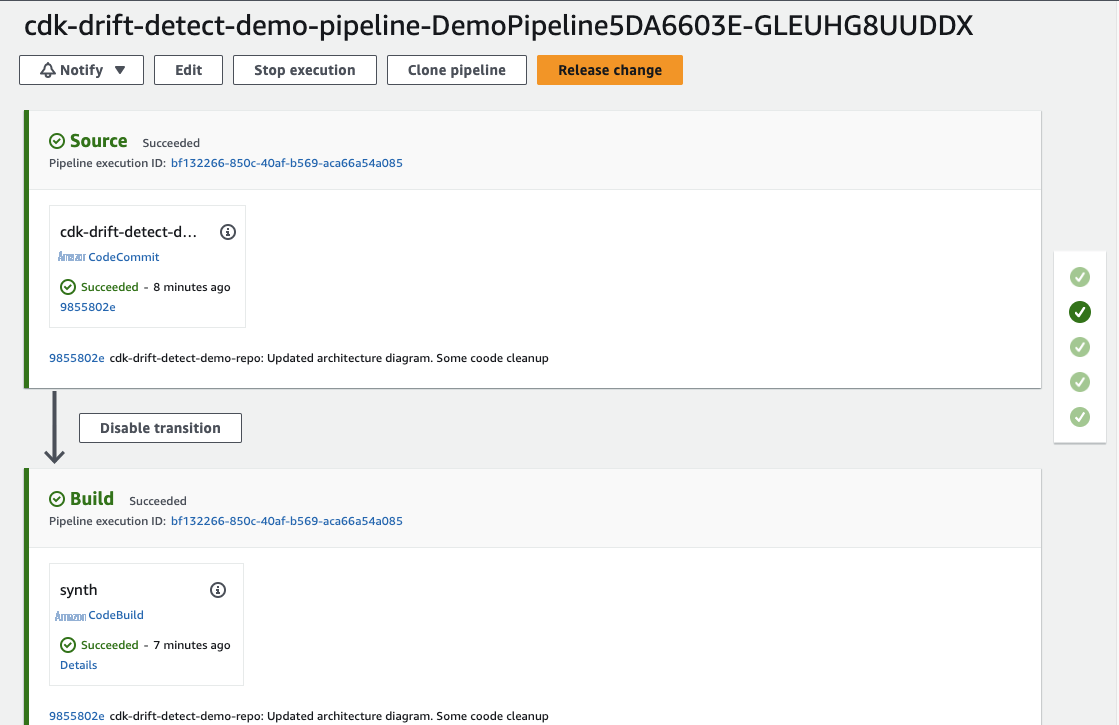
该管道部署了两个堆栈
这些堆栈中的每一个都会创建一个 S3 存储桶。
demoStackA 和 demoSt
ackB。

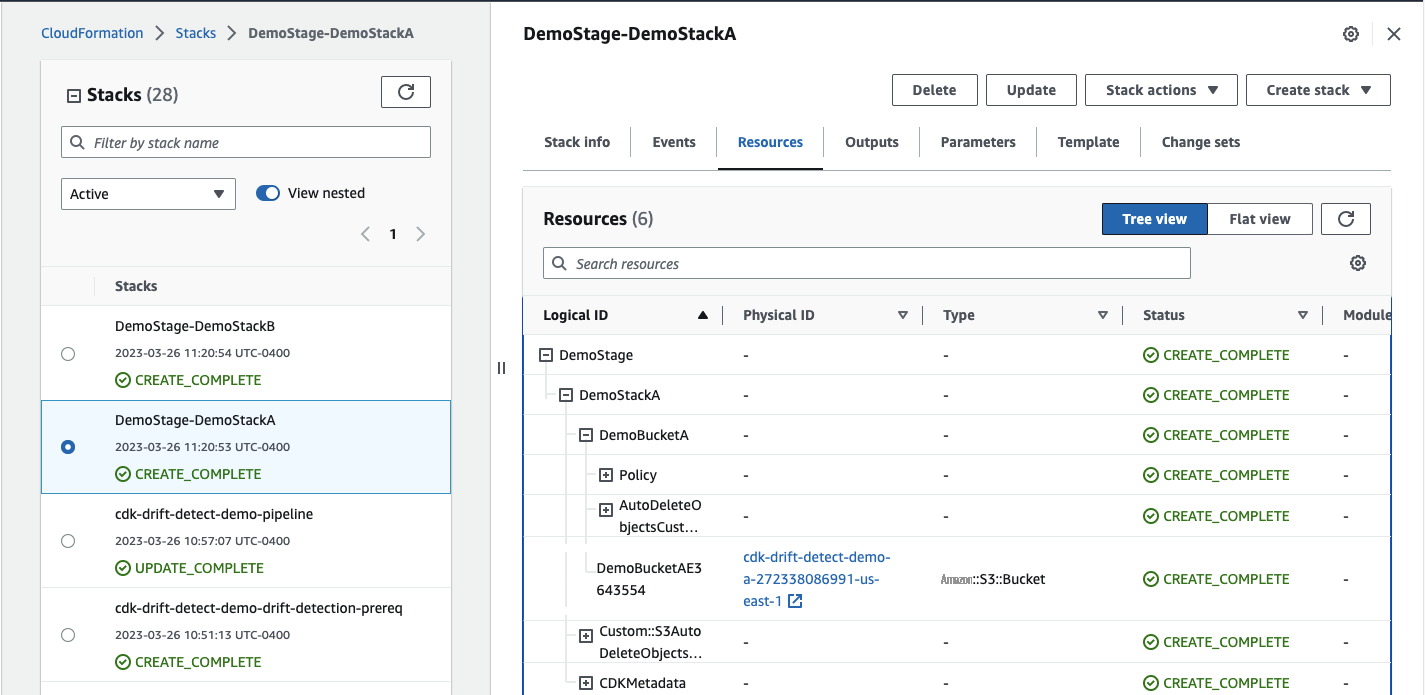
演示漂移检测
在资源 下找到
demoStackA
创建的 S3 存储桶,导航到 S3 存储桶,然后将 a
ws-cdk: auto-delete-objects 标签从真修改为假,如下
所示
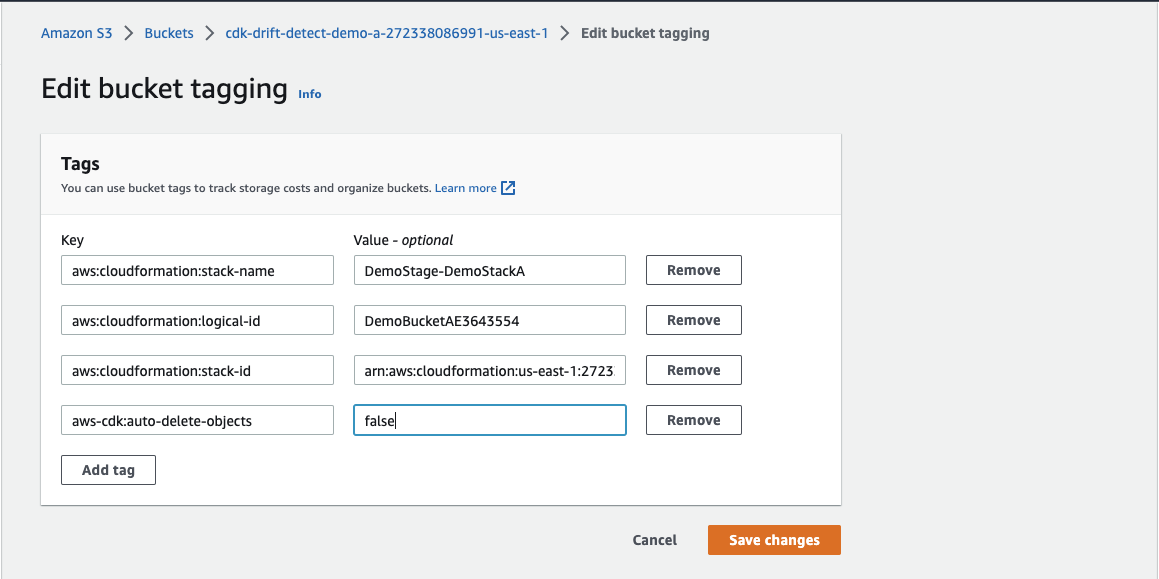
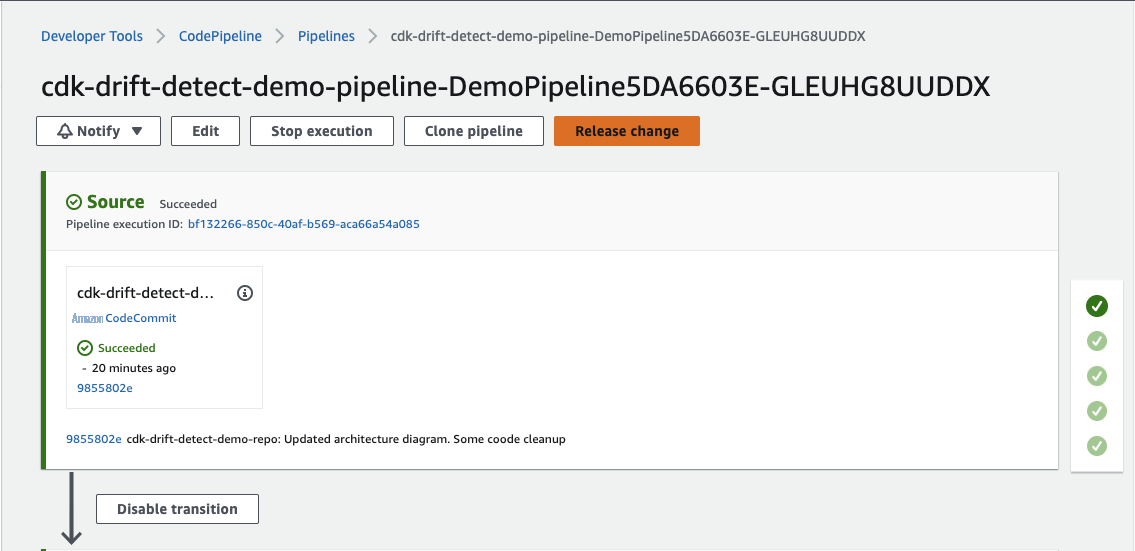
现在,进入管道,单击 “
发布更改
” 触发新的执行
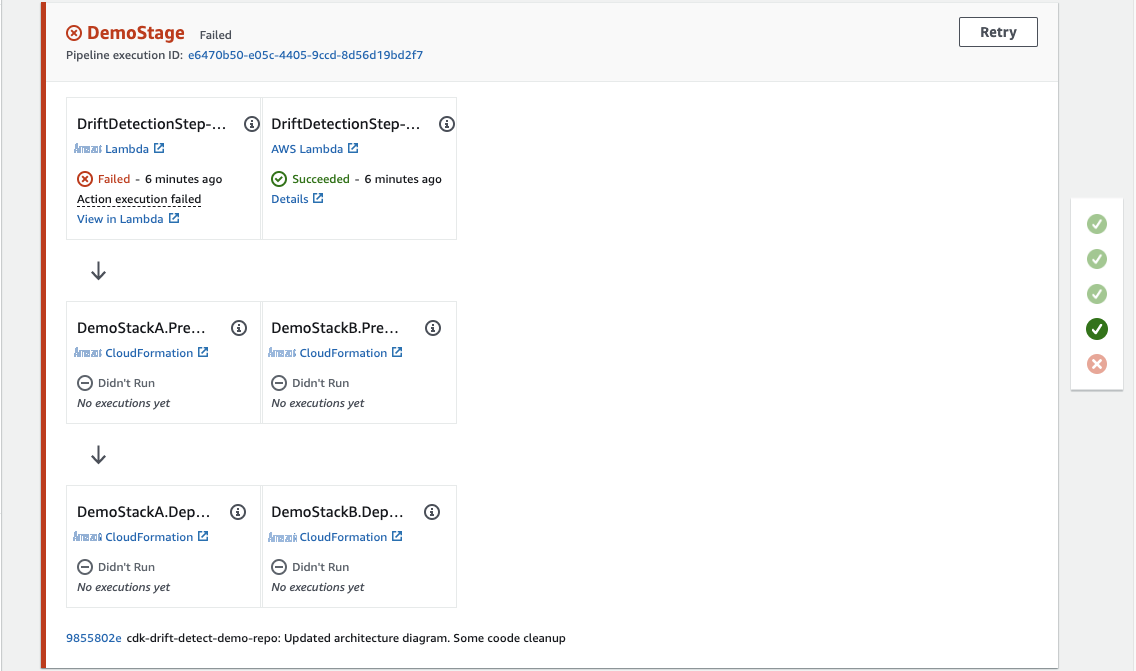
现在,管道运行将在部署前的漂移检测步骤中以失败告终。
清理
请按照以下步骤清理所有堆栈。
-
导航到 S3 控制台并清空堆栈demoStackA 和 demoStackB 创建的存储桶。 -
导航到 CloudFormation 控制台并删除堆栈
DemoStackA 和 DemoStackB,因为删除 CDK Pipelines 堆栈不会删除管道部署的应用程序堆栈。 -
删除 CDK 流水线堆栈 cdk-drift-detect-demo-Pipeline -
删除必备堆栈 cdk-drift-detect-demo-drift-detection-prereq
结论
在这篇文章中,我展示了如何在 CDK Pipelines 中添加自定义实现步骤。我还使用该机制将漂移检测检查整合为部署前步骤。这使我们能够在部署云Formation堆栈之前验证其完整性。由于验证已集成到管道中,因此可以更轻松地将解决方案作为总体管道的一部分集中在一个地方进行管理。尝试一下该解决方案,然后看看是否可以将其整合到组织的交付管道中。
作者简介:

Damodar Shenvi Wagle 是 亚马逊云科技 专业服务的高级云应用程序架构师。他的专业领域包括架构无服务器解决方案、CI/CD 和自动化。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。