我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 EventBridge Pipes 实现架构模式
这篇文章由多米尼克·里希特(解决方案架构师)撰写
架构模式可帮助您解决软件设计中反复出现的挑战。它们是经过多次使用和测试的蓝图。设计分布式应用程序时,
这篇文章向您展示了如何使用
内容过滤器和邮件过滤器模式
要删除不需要的消息和内容,请组合
在以下示例中,目标是仅保留 “订单” 事件中的非 PII 数据。要实现此目的,你必须删除所有不是 “ORDER” 事件的事件。此外,您必须删除 “订单” 事件中包含 PII 的任何字段。
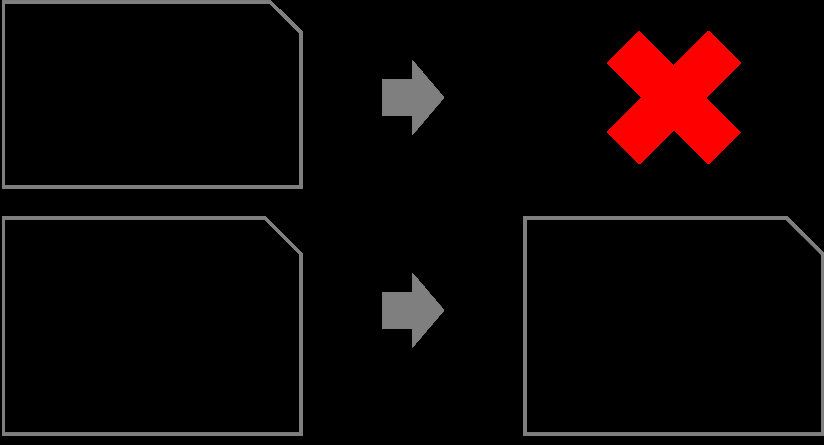
虽然您可以将这些模式用于不同的来源和目标,但以下架构在

您可以使用
有些情况需要充实功能。例如,如果你的目标是在不完全移除的情况下掩盖某个属性。例如,您可以将 “生日” 属性替换为 “age_group” 属性。

在这种情况下,如果您使用 Pipes 进行集成,则 Lambda 函数仅包含您的业务逻辑。另一方面,如果您将 Lambda 同时用于集成和业务逻辑,则无需为 Pipes 付费。同时,您的 Lambda 函数增加了复杂性,该函数现在包含集成代码。这可能会增加其执行时间和成本。因此,你的优先级决定了最佳选择,你应该比较两种方法来做出决定。
要使用
const filterPipe = new pipes.CfnPipe(this, 'FilterPipe', {
roleArn: pipeRole.roleArn,
source: sourceStream.streamArn,
target: targetStream.streamArn,
sourceParameters: { filterCriteria: { filters: [{ pattern: '{"data" : {"event_type" : ["ORDER"] }}' }] }, kinesisStreamParameters: { startingPosition: 'LATEST' } },
targetParameters: { inputTemplate: '{"event_type": <$.data.event_type>, "currency": <$.data.currency>, "sum": <$.data.sum>}', kinesisStreamParameters: { partitionKey: 'event_type' } },
});
要允许访问源和目标,必须分配正确的权限:
const pipeRole = new iam.Role(this, 'FilterPipeRole', { assumedBy: new iam.ServicePrincipal('pipes.amazonaws.com') });
sourceStream.grantRead(pipeRole);
targetStream.grantWrite(pipeRole);
消息翻译器模式
在事件驱动的架构中,活动制作者和消费者是相互独立的。因此,他们可能会交换不同格式的事件。要启用通信,必须对事件进行翻译。这被称为

如果需要计算来翻译消息,请使用丰富步骤。以下架构图显示了如何通过 API 目标实现此丰富。在示例中,您可以调用现有的地理编码服务将地址解析为坐标。
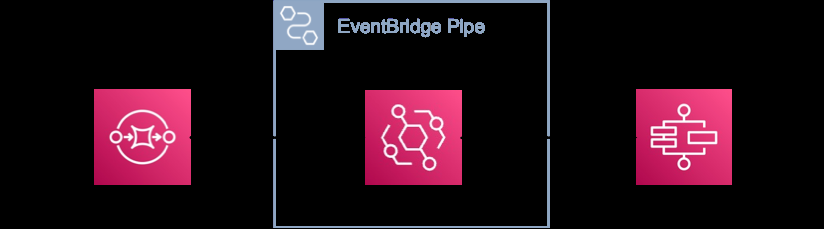
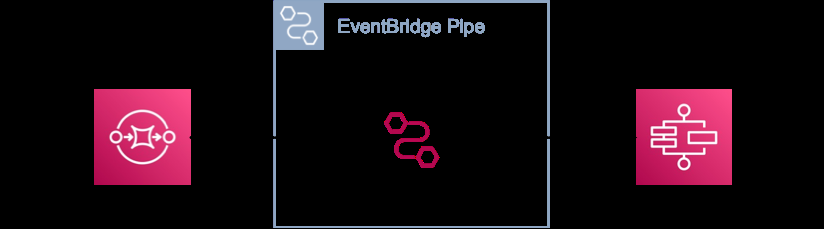
在某些情况下,翻译可能纯粹是语法性的。例如,一个字段可能有不同的名称或结构。

通过使用输入转换器,你可以在不进行充实的情况下实现这些翻译。
以下是管道的源代码,包括具有正确权限的角色:
const pipeRole = new iam.Role(this, 'MessageTranslatorRole', { assumedBy: new iam.ServicePrincipal('pipes.amazonaws.com'), inlinePolicies: { invokeApiDestinationPolicy } });
sourceQueue.grantConsumeMessages(pipeRole);
targetStepFunctionsWorkflow.grantStartExecution(pipeRole);
const messageTranslatorPipe = new pipes.CfnPipe(this, 'MessageTranslatorPipe', {
roleArn: pipeRole.roleArn,
source: sourceQueue.queueArn,
target: targetStepFunctionsWorkflow.stateMachineArn,
enrichment: enrichmentDestination.apiDestinationArn,
sourceParameters: { sqsQueueParameters: { batchSize: 1 } },
});
归一化器模式
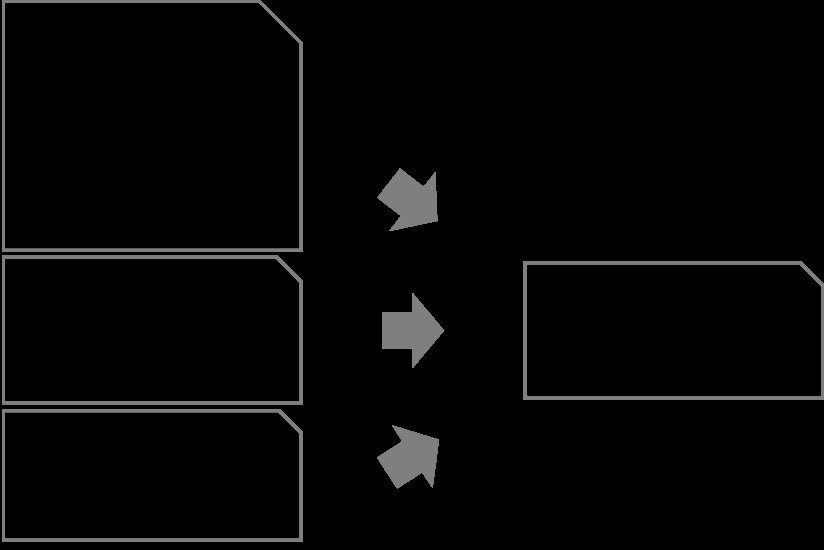
该示例显示了一个系统,其中不同的源系统以不同的方式存储名称属性。要根据消息来源以不同的方式处理消息,请使用
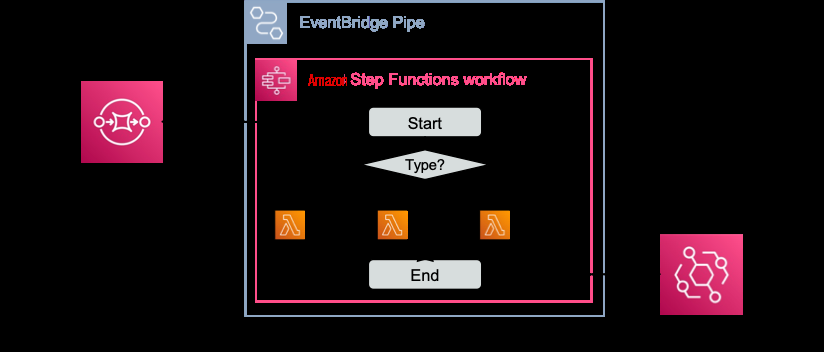
在示例中,在将事件放到事件总线上之前,使用 Step Functions 对事件进行统一。与架构选择经常出现的情况一样,也有其他选择。另一种方法是为每个源系统引入单独的队列,由其自己的管道连接,仅包含其统一操作。
![]()
这是使用 Step Functions 工作流程作为丰富功能的归一化器模式的源代码:
const pipeRole = new iam.Role(this, 'NormalizerRole', { assumedBy: new iam.ServicePrincipal('pipes.amazonaws.com') });
sourceQueue.grantConsumeMessages(pipeRole);
enrichmentWorkflow.grantStartSyncExecution(pipeRole);
normalizerTargetBus.grantPutEventsTo(pipeRole);
const normalizerPipe = new pipes.CfnPipe(this, 'NormalizerPipe', {
roleArn: pipeRole.roleArn,
source: sourceQueue.queueArn,
target: normalizerTargetBus.eventBusArn,
enrichment: enrichmentWorkflow.stateMachineArn,
sourceParameters: { sqsQueueParameters: { batchSize: 1 } },
});
索赔支票模式
要缩小事件驱动应用程序中事件的大小,可以临时移除属性。这种方法被称为

索赔核对模式分为两部分。首先,当接收到一个事件时,你将其拆分并将负载存储在其他地方。其次,在处理事件时,您将检索相关信息。你可以用管道实现这两个方面。
在第一个管道中,你使用丰富来拆分事件,在第二个管道中使用扩展来检索有效载荷。以下是几个丰富选项,例如通过 API 目标使用外部 API,或者通过 Lambda 使用
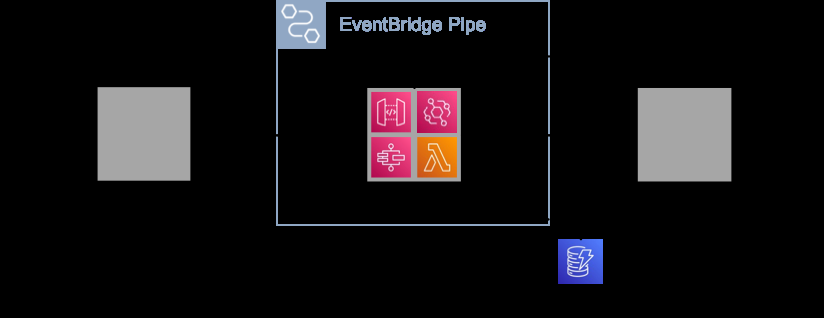
使用管道拆分和检索消息有三个优点。首先,当事件在系统中移动时,要保持简洁。其次,您要确保事件在处理时包含所有相关信息。第三,你概括了管道内拆分和检索的复杂性。
以下代码使用 CDK 实现了索赔检查模式的管道:
const pipeRole = new iam.Role(this, 'ClaimCheckRole', { assumedBy: new iam.ServicePrincipal('pipes.amazonaws.com') });
claimCheckLambda.grantInvoke(pipeRole);
sourceQueue.grantConsumeMessages(pipeRole);
targetWorkflow.grantStartExecution(pipeRole);
const claimCheckPipe = new pipes.CfnPipe(this, 'ClaimCheckPipe', {
roleArn: pipeRole.roleArn,
source: sourceQueue.queueArn,
target: targetWorkflow.stateMachineArn,
enrichment: claimCheckLambda.functionArn,
sourceParameters: { sqsQueueParameters: { batchSize: 1 } },
targetParameters: { stepFunctionStateMachineParameters: { invocationType: 'FIRE_AND_FORGET' } },
});
结论
这篇博客文章介绍了如何使用
您可以在
如需更多无服务器学习资源,请访问
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。