我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 DynamoDB 和亚马逊 Athena 使用 Apache Iceberg 实施无服务器 CDC 流程
大多数企业将其关键数据存储在数据湖中,您可以在其中将来自不同来源的数据带入集中存储。数据湖环境中的变更数据捕获 (CDC) 是指捕获和传播对源数据所做的更改的过程。源系统通常缺乏发布修改或更改的数据的能力。这要求数据管道每天消耗满负载的数据集,从而增加数据处理持续时间和存储成本。如果来源是表格格式,则有一些机制可以轻松识别数据变化。但是,如果数据采用半结构化格式并将对源数据所做的更改以近乎实时的方式传播到数据湖中,则复杂性就会增加。
这篇文章提出了一种解决方案,用于处理来自源系统的传入半结构化数据集,并有效地确定更改的记录并将其加载到
解决方案概述
我们使用端到端的无服务器 CDC 流程来演示此解决方案。我们使用示例 JSON 文件作为
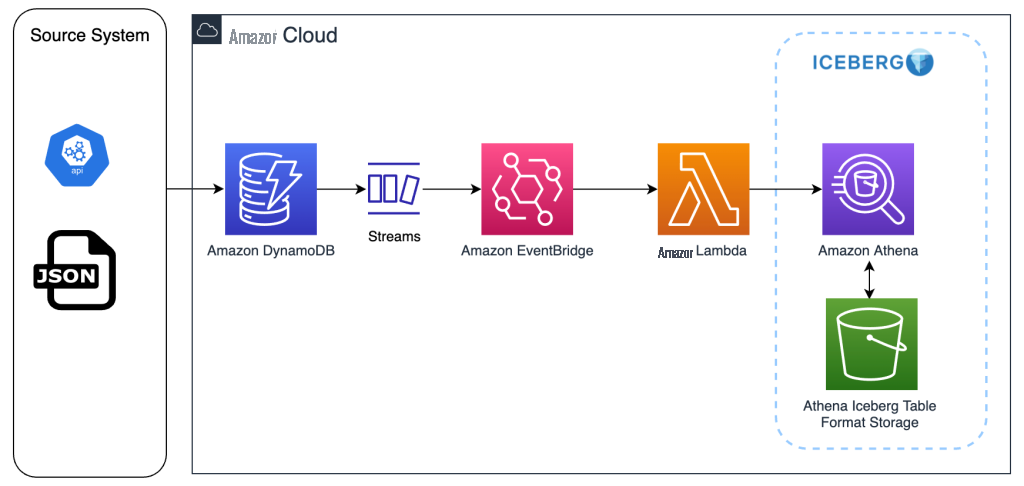
该架构的实现方式如下:
- 源系统将半结构化 (JSON) 数据集提取到 DynamoDB 表中。
- DynamoDB 表存储半结构化数据集,这些表启用了 DynamoDB 流。DynamoDB Streams 可根据定义的密钥帮助识别传入数据是新的、修改的还是删除的,并将已排序的消息传递给 Lambda 函数。
- 对于每个流,Lambda 函数都会解析流并生成动态 DML SQL 语句。
- 构造的 DML SQL 语句在相应的 Iceberg 表上运行以反映更改。
下图说明了这个工作流程。
先决条件
在开始之前,请确保满足以下先决条件:
-
一个
亚马逊云科技 账户 -
用于部署
亚马逊云科技 (IAM) 权限CloudFormation 堆栈资源的适当的 亚马逊云科技 身份和访问管理
部署解决方案
对于此解决方案,我们提供了一个 CloudFormation 模板,用于设置架构中包含的服务,以实现可重复的部署。
注意:— 在您的账户中 部署 CloudFormation 堆栈会产生 亚马逊云科技 使用费。
要部署解决方案,请完成以下步骤:
- 选择 “ 启动堆栈 ” 以启动 CloudFormation 堆栈。
-
输入堆栈名称。

- 选择 我承认 亚马逊云科技 CloudFormation 可能会使用自定义名称创建 IAM 资源 。
- 选择 创建堆栈 。
CloudFormation 堆栈部署完成后,导航到 亚马逊云科技 CloudFormation 控制台,记下 “输出” 选项卡上的 以下资源:
-
数据湖 S3 存储桶
—
iceberg-cdc-xxxxx-us-east-1-xxxxx -
AthenaWorkgroupName — AthenaWorkgroup-xxxxx -
数据生成器 LambdaFunction — UserRecordsFunction-xxxxx -
DynamodbtableNam
e — users_xxxxxx -
LambdadmlFunction — icebergupsertFunction-xxxxx -
A@@ thena icebergTableName — users_xxxxx
生成示例员工数据并使用 Lambda 加载到 DynamoDB 表中
要测试解决方案,请通过创建一个将示例数据加载到 DynamoDB 表中的测试事件来触发 UserRecordsFunction-xxxxx 函数。
- 在 Lambda 控制台上,打开名为 UserRecordsFunction-xxxxx 的 Lambda 函数。
-
在
代码
选项卡上,选择
测试
,然后选择
配置测试事件
。
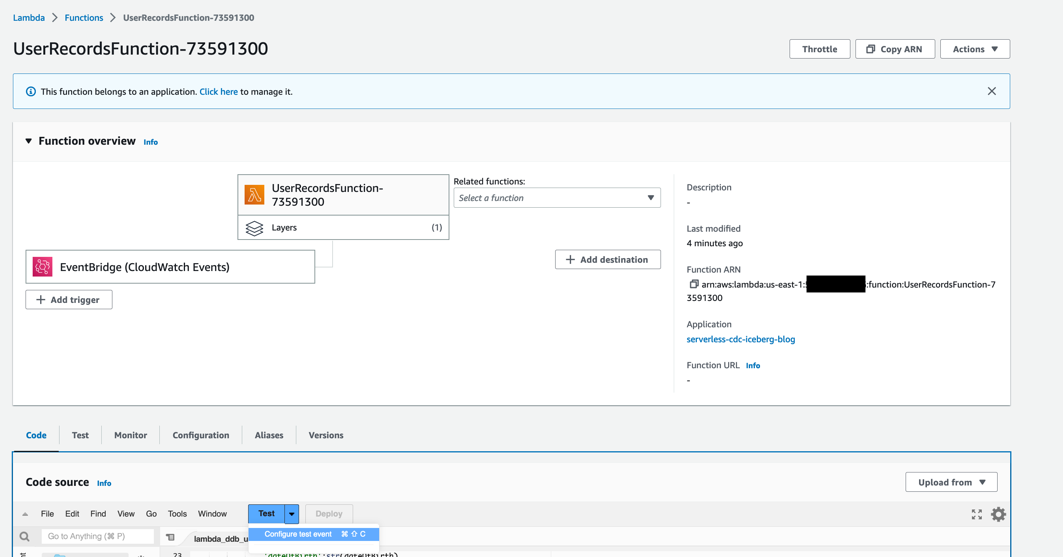
- 使用默认 hello-world 模板事件 JSON 配置测试事件。
-
提供不对模板进行任何更改的事件名称并保存测试事件。
-
在 “
测试
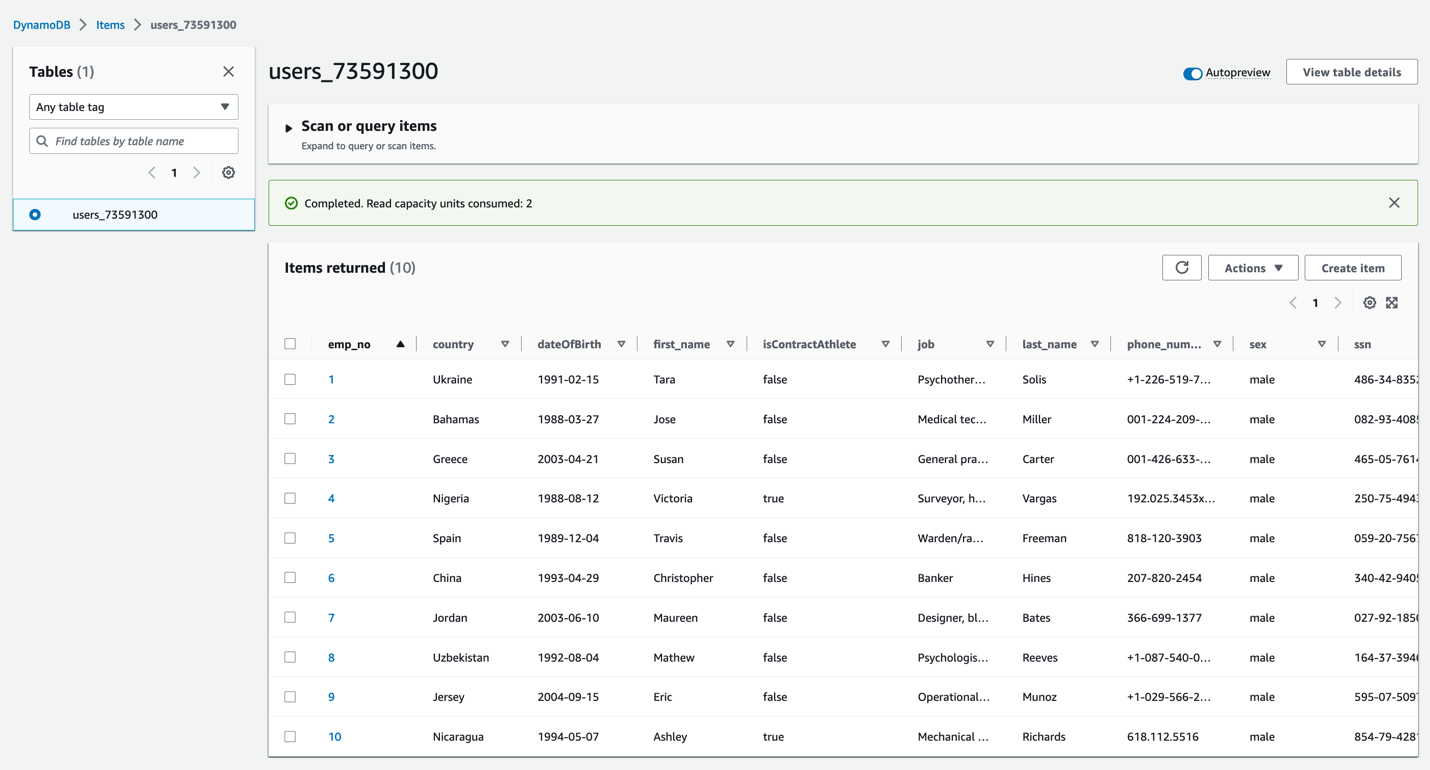
” 选项卡上,选择 “测试” 以触发 SampleEvent 测试事件。这将调用数据生成器 Lambda 函数将数据加载到 users_xxxxxx DynamoDB 表中。测试活动完成后,您应该注意到成功通知,如以下屏幕截图所示。

-
在 DynamoDB 控制台上,导航到 Users_xxxxx 表,然后选择 “
浏览表项目” 以验证加载
到表中的数据。
在 CloudFormation 模板部署的 IcebergupsertFunction-xxxxx Lambda 函数的帮助下,在 DynamoDB 表上执行的数据加载将级联到雅典娜表中。
在以下部分中,我们将模拟和验证各种场景以演示 Iceberg 的功能,包括 DML 操作、时空旅行和优化。
在 Athena 中模拟场景并验证 CDC 功能
首次运行数据生成器 Lambda 函数后,导航到 Athena 查询编辑器,选择
AthenaWorkgroup-xxxxx 工作组,然后预览 user_xxxxxx Ic
eberg 表以查询记录。
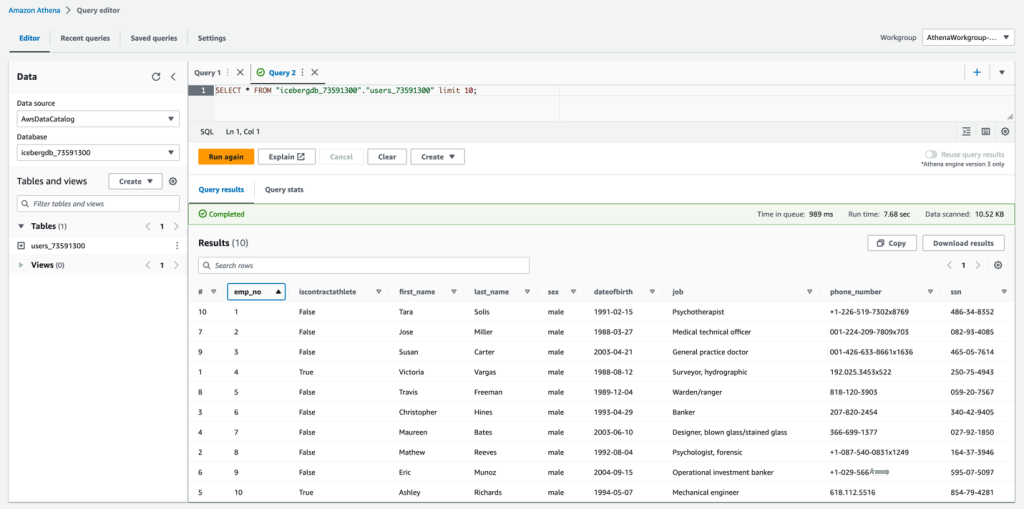
将数据插入到 DynamoDB 表中后,所有数据更改活动(例如插入、更新和删除)都将捕获到 DynamoDB 流中。DynamoDB Streams 会触发 IcebergupsertFunction-xxxxx Lambda 函数,该函数按接收事件的顺序处理事件。icebergupsertFunction-xxxxx 函数执行以下步骤:
- 接收直播事件
- 基于 DynamdoDB 事件类型(插入、更新或删除)解析流事件,并最终生成 Athena DML SQL 语句
- 在雅典娜中运行 SQL 语句
让我们深入了解一下 icebergupsertFunction-xxxx 函数代码以及它如何处理各种场景。
icebergupsertFunction-xxxx 函数代码
如以下 Lambda 函数代码块所示,该函数接收的 DynamoDB Streams 事件根据事件类型(插入、修改或删除)对事件进行分类。任何其他事件都会引发 InvalideVentException。修改被视为更新事件。
所有 DML 操作都在 Athena 中的
user_xxxxx 表
上运行。我们从雅典娜那里获取
users_xxxxxx
表的元数据。以下是有关 Lambda 函数如何处理 Iceberg 表元数据更改的一些重要注意事项:
- 在这种方法中,目标元数据在 DML 操作期间优先。
- 目标中缺少的任何列都将在 DML 命令中排除。
- 源元数据和目标元数据必须匹配。如果向源表中添加了新的列和属性,则当前解决方案被配置为跳过新的列和属性。
- 可以进一步增强此解决方案,将源系统元数据更改级联到 Athena 中的目标表。
以下是 Lambda 函数代码:
以下代码使用 Athena Boto3 客户端来获取表的元数据:
插入操作
现在让我们看看如何使用在 DynamoDB 表中生成的示例数据来处理插入操作。
-
在 DynamoDB 控制台上,导航到
users_xxxxx 表。 - 选择 创建项目 。
- 使用以下代码输入示例记录:
-
选择 “
创建项目
” 将新记录插入 到 DynamoDB 表中。
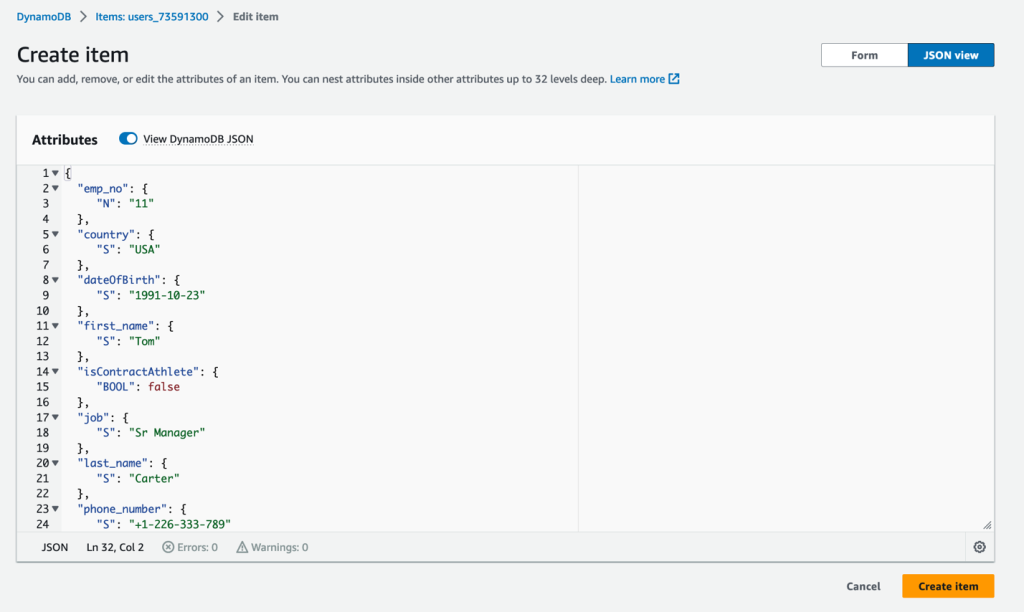
在 DynamoDB 表中创建项目后,将在 DynamoDB Streams 中生成一个流事件,该事件会触发 Lambda 函数。该函数处理事件并生成等效的 INSERT SQL 语句以在 Athena 表上运行。以下屏幕截图显示了 Athena 控制台上的 Lambda 函数在 “最近查询” 部分生成的 INSERT SQL。

icebergupsertFunction-xxxxx Lambda 代码对每种事件类型都有模块化函数
。以下代码重点介绍了该函数,该函数处理插入 EventType 流:
此函数解析创建项流事件并按以下格式构造 INSERT SQL 语句:
该函数返回一个字符串,它是一条符合 ANSI SQL 的语句,可以直接在 Athena 中运行。
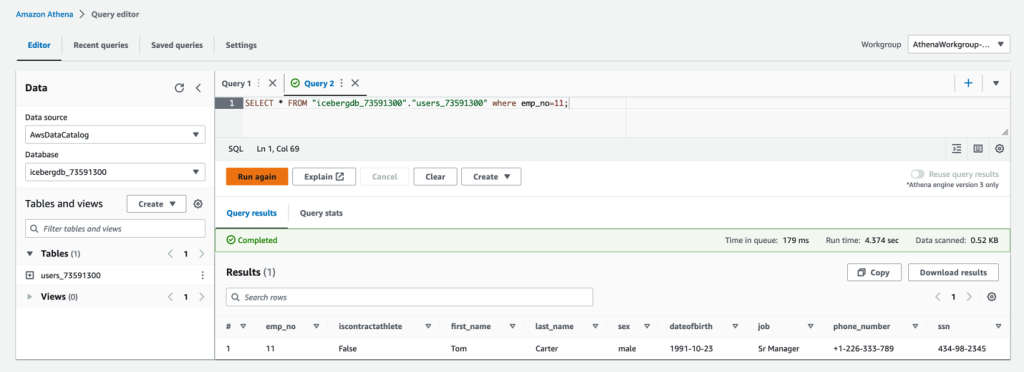
更新操作
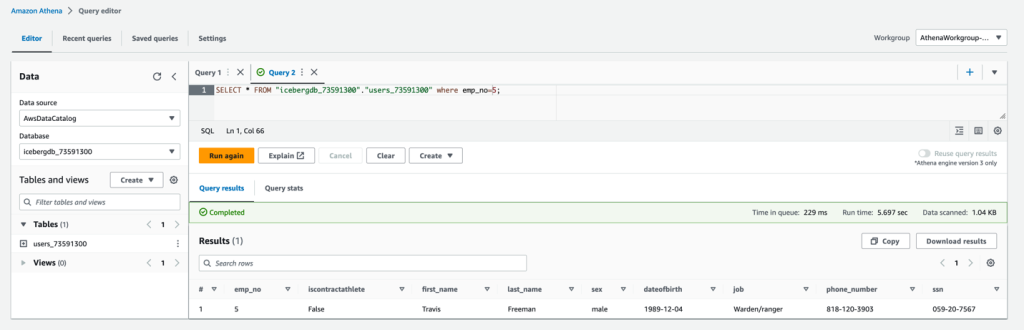
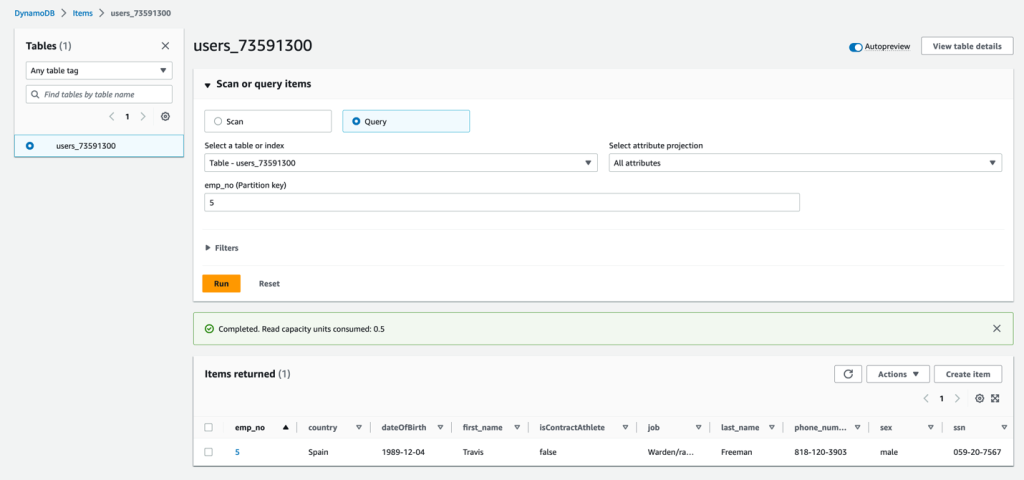
在更新操作中,让我们确定 Athena 表中记录的当前状态。我们在 Athena 中看到
emp_no=5
及其列值,并将它们与 DynamoDB 表进行了比较。如果没有更改,则记录应相同,如以下屏幕截图所示。
让我们在 DynamoDB 表中启动编辑项目操作。我们修改了以下值:
- isContractAthlet e — 没错
- 电话号码 — 123-456-789
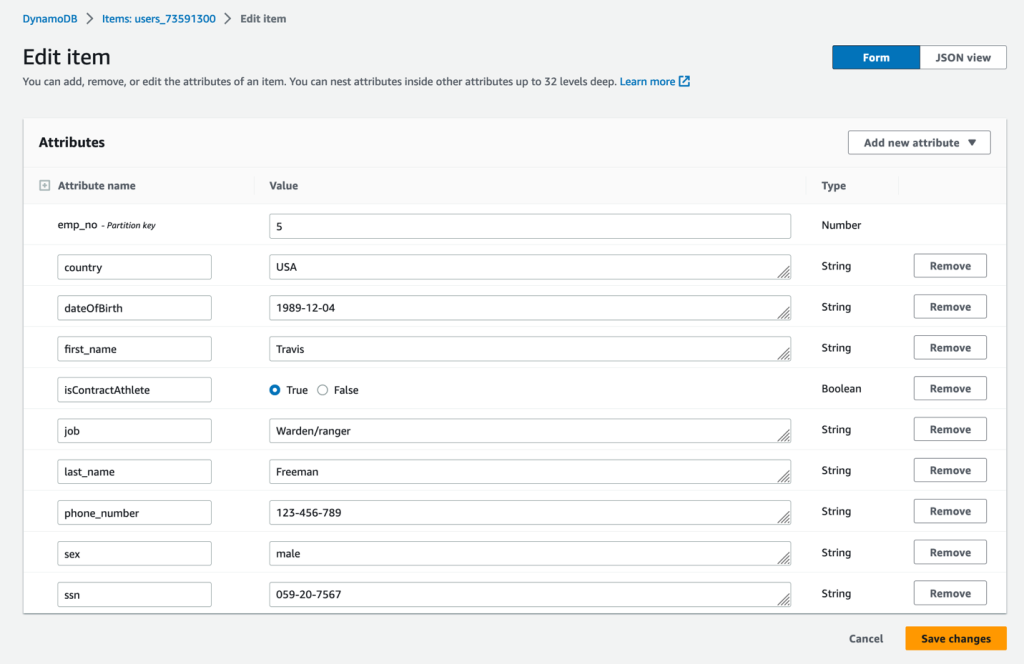
在 DynamoDB 表中编辑项目后,将在 DynamoDB Streams 中生成修改流事件,该事件会触发 Lambda 函数。该函数处理事件并生成等效的 UPDATE SQL 语句以在 Athena 表上运行。
修改 DynamoDB Streams 事件有两个组成部分:旧图像和新映像。在这里,我们仅解析新的图像数据部分来构造 UPDATE ANSI SQL 语句并将其运行在 Athena 表上。

以下
update_stmt
代码块解析修改项目流事件,并使用新的图像数据构造相应的 UPDATE SQL 语句。该代码块执行以下步骤:
-
查找 WHERE 子句
的键列 -
查找 SE
T子句的列 -
确保键列不是 SE
T命令的一部分
该函数返回一个字符串,该字符串是一条符合 SQL ANSI 的语句,可以直接在 Athena 中运行。例如:
参见以下代码:
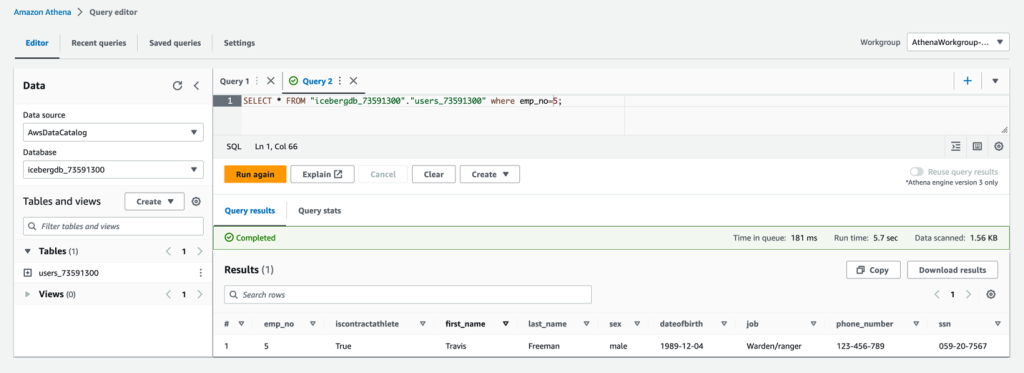
在雅典娜表中,我们可以看到
isContractAthlete
和
phone_Num
ber 列已更新为最近的值。其他列值保持不变,因为它们没有被修改。
删除操作
对于删除操作,让我们确定 Athena 表中记录的当前状态。我们为本次
活动选择 emp_no=6
。
- 在 DynamoDB 控制台上,导航到用户表。
-
选择
emp_no=6 的记录。 - 在 “ 操作 ” 菜单上,选择 “ 删除项目 ” 。
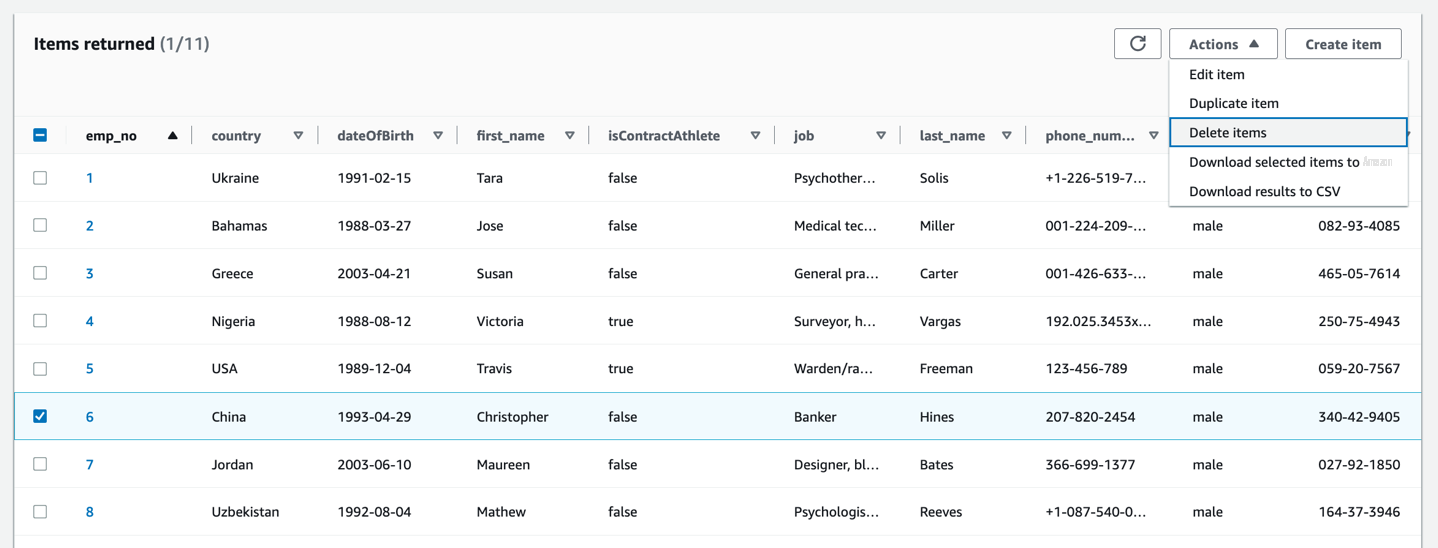
对 DynamoDB 表执行删除项目操作后,它会在 DynamoDB 流中生成一个 DELETE 事件类型,该事件类型会触发 Iceberg-Upsert Lambda 函数。
DELETE 函数根据流中的键列删除数据。以下函数解析流以识别已删除项目的关键列。我们使用一个
em
p_no=6 的 WHERE 子句构造一个 DELET
E
DML SQL 语 句:
DELETE <TABLENAME> WHERE key = value参见以下代码:
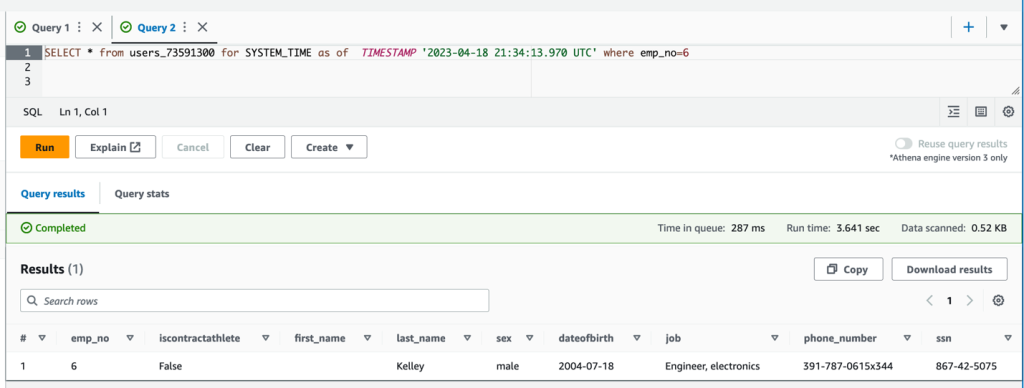
该函数返回一个字符串,该字符串是一条符合 ANSI SQL 的语句,可以直接在 Athena 中运行。以下屏幕截图显示了在 Athena 中运行的 DELETE 语句。

从下面的屏幕截图中可以看出,使用 Athena
查询时,emp_no=6
记录不再存在于 Iceberg 表中。

时空旅行
Athena 中的时空旅行查询会查询 Amazon S3,获取截至指定日期和时间的一致快照中的历史数据。Iceberg 桌子提供了时空旅行的能力。每个 Iceberg 表都维护其所包含的 S3 对象的版本清单。清单的先前版本可用于时空旅行和版本旅行查询。Athena 中的版本旅行查询会向 Amazon S3 查询截至指定快照 ID 的历史数据。Iceberg 格式会追踪 t
ablename$iceberg_history 表中表格
发生的所有变化。当您查询它们时,它将显示表中发生更改的时间戳。
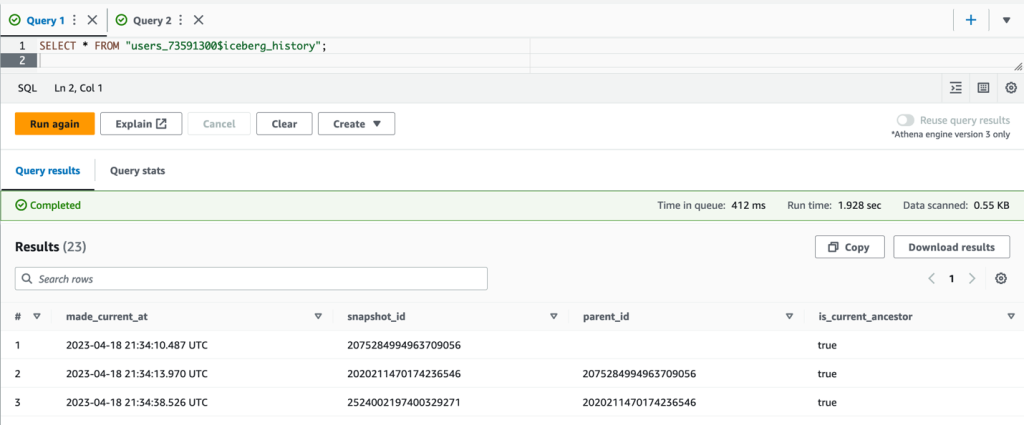
让我们找出将 DELETE 语句应用于 Athena 表时的时间戳。在我们的查询中,它对应于2023-04-18 21:34:13.970。有了这个时间戳,让我们查询主表以查看其中是否存在
emp_no=6
。
如以下屏幕截图所示,查询结果显示已删除的记录存在,如果需要,这可用于重新插入数据。
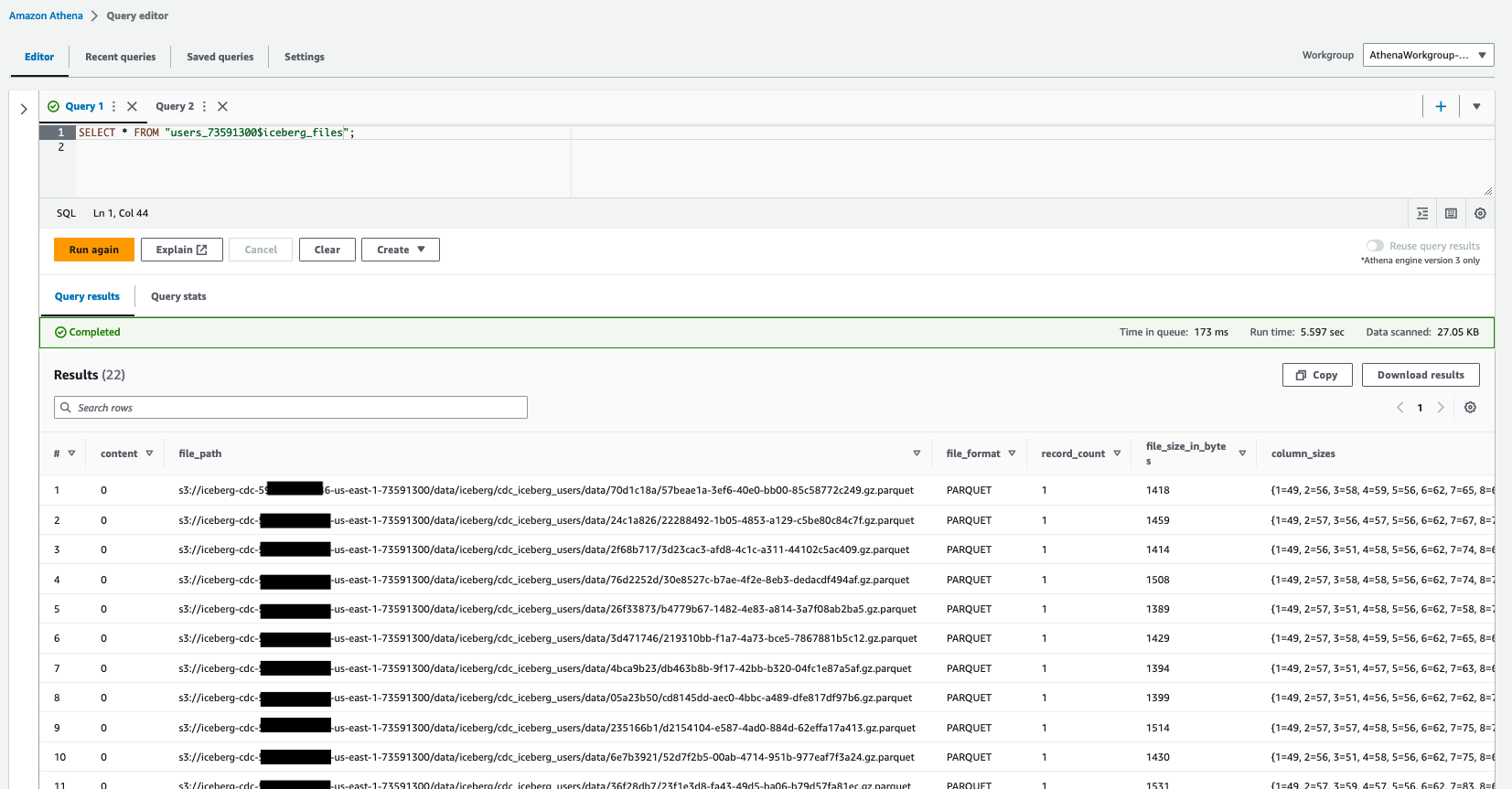
优化 Iceberg 牌桌
对 Iceberg 表的每次插入和更新操作都会创建一个单独的数据和元数据文件。如果有多个这样的更新和插入操作,则可能会导致多个小碎片化文件。拥有这些小文件可能会导致不必要的元数据数量和查询效率降低。使用 Athena OPTIMIZE 命令压缩这些小文件。
优化
优化表重写数据压缩操作会根据数据文件的大小和关联删除文件数量将数据文件重写为更优化的布局。
以下查询显示了压缩过程之前存在的数据文件的数量:
以下查询对 Iceberg 表执行压缩:
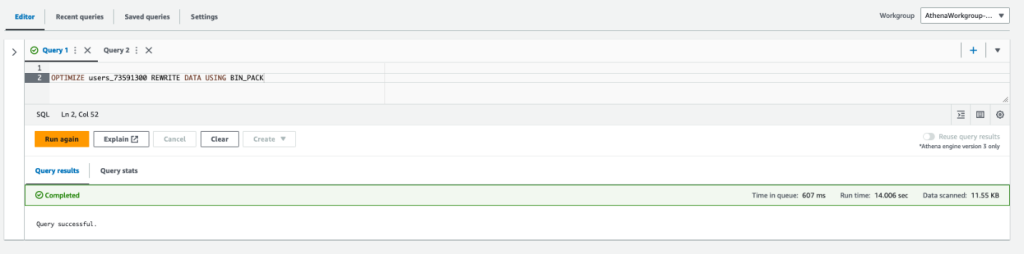
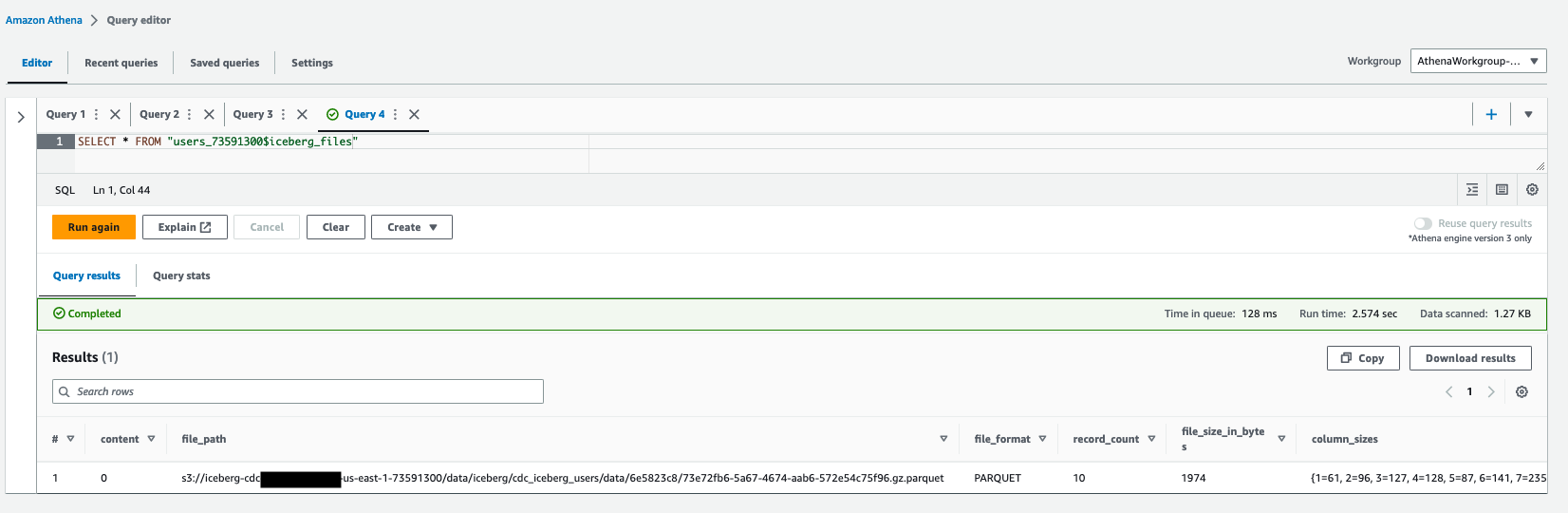
我们可以观察到,压缩过程将多个数据文件合并为一个更大的文件。
真空
Iceberg 表上的 VACUUM 语句会删除不再相关的数据文件,从而减少元数据大小和存储消耗。VACUUUM 会删除早于 vacuum_max_snapshot_age_snapshot_seconds 表属性(默认为 432000)指定的时间长度的有害文件,如以下代码所示:
以下查询对 Iceberg 表执行真空操作:
清理
当您完成此解决方案的试验后,清理您的资源以防产生 亚马逊云科技 费用:
- 清空 S3 存储桶。
- 从 亚马逊云科技 CloudFormation 控制台中删除堆栈。
结论
在这篇文章中,我们介绍了一种使用DynamoDB Streams并在Iceberg表中处理半结构化数据的无服务器CDC解决方案。我们演示了如何在 DynamoDB 中提取半结构化数据、使用 DynamoDB 流识别更改后的数据,以及如何在 Iceberg 表中处理这些数据。我们可以扩展解决方案,在数据湖中构建 SCD type-2 功能,以跟踪历史数据变化。此解决方案适用于更新频率较低,但对于高频率和更大数据量,我们可以使用 DynamoDB Streams 和
我们希望这篇文章能提供有关在源系统缺乏 CDC 功能时如何处理数据湖中的半结构化数据的见解。
作者简介
 Vijay Vel pul
a 是一名拥有 亚马逊云科技 专业服务的数据湖架构师。他通过实施大数据和分析解决方案帮助客户构建现代数据平台。工作之余,他喜欢与家人共度时光、旅行、远足和骑自行车。
Vijay Vel pul
a 是一名拥有 亚马逊云科技 专业服务的数据湖架构师。他通过实施大数据和分析解决方案帮助客户构建现代数据平台。工作之余,他喜欢与家人共度时光、旅行、远足和骑自行车。
 Karthikeyan Ramachandran
是 亚马逊云科技 专业服务的数据架构师。他专门研究 MPP 系统,帮助客户构建和维护数据仓库环境。工作之余,他喜欢狂看电视节目,喜欢打板球和排球。
Karthikeyan Ramachandran
是 亚马逊云科技 专业服务的数据架构师。他专门研究 MPP 系统,帮助客户构建和维护数据仓库环境。工作之余,他喜欢狂看电视节目,喜欢打板球和排球。
 Sriharrash Adari
是亚马逊网络服务 (亚马逊云科技) 的高级解决方案架构师,在那里他帮助客户从业务成果向后思考,在 亚马逊云科技 上开发创新的解决方案。多年来,他已帮助多个客户进行跨行业的数据平台转型。他的核心专业领域包括技术战略、数据分析和数据科学。在业余时间,他喜欢运动、狂看电视节目和玩 Tabla。
Sriharrash Adari
是亚马逊网络服务 (亚马逊云科技) 的高级解决方案架构师,在那里他帮助客户从业务成果向后思考,在 亚马逊云科技 上开发创新的解决方案。多年来,他已帮助多个客户进行跨行业的数据平台转型。他的核心专业领域包括技术战略、数据分析和数据科学。在业余时间,他喜欢运动、狂看电视节目和玩 Tabla。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。