我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Amazon SageMaker 在自定义数据集上实施多对象跟踪解决方案
许多行业(例如体育赛事直播、制造业和交通监控)对视频分析中的多对象跟踪(MOT)的需求已显著增加。例如,在体育直播中,MOT可以实时跟踪足球运动员,以分析实时速度和移动距离等身体表现。
自2021年推出以来,
继上一篇文章之后,我们添加了以下贡献和修改:
- 使用 Ground Truth 为自定义视频数据集生成标签
- 预处理 Ground Truth 生成的标签,使其与 ByteTrack 和其他 MOT 解决方案兼容
-
使用
SageMaker 训练作业 (可以选择 ByteTrack 算法扩展 预建容器)训练 - 使用各种部署选项部署经过训练的模型,包括异步推理
我们还
SageMaker 是一项完全托管的服务,可让每位开发人员和数据科学家快速准备、构建、训练和部署机器学习 (ML) 模型。SageMaker 提供了多种内置算法和容器映像,您可以使用它们来加速机器学习模型的训练和部署。此外,还可以通过自定义构建的 Docker 容器映像支持 ByteTrack 等自定义算法。有关决定容器的正确参与级别的更多信息,请参阅在
SageMaker 为模型部署提供了大量选项,例如实时推断、无服务器推理和异步推理。在这篇文章中,我们将介绍如何部署具有不同部署选项的跟踪模型,以便您可以在自己的用例中选择合适的部署方法。
解决方案概述
我们的解决方案包括以下高级步骤:
- 对数据集进行标注以进行跟踪,并在每个对象(例如行人、汽车等)上使用边界框。设置用于 ML 代码开发和执行的资源。
- 训练 ByteTrack 模型并在自定义数据集上调整超参数。
- 根据您的用例,使用不同的部署选项部署经过训练的 ByteTrack 模型:实时处理、异步或批量预测。
下图说明了每个步骤中的架构。

先决条件
在开始之前,请完成以下先决条件:
- 创建 亚马逊云科技 账户或使用现有的 亚马逊云科技 账户。
-
我们建议在
us-east-1 区域运行源代码。 -
确保至少有一个 GPU 实例(例如,用于单个 GPU 训练,
ml.p3.2xlarge,或 用于分布式训练作业,ml.p3.16xlarge)。还支持其他类型的 GPU 实例,但存在各种性能差异。 -
确保至少有一个 GPU 实例(例如,
ml.p3.2xlarge)用于推理端点。 -
确保至少有一个 GPU 实例(例如,
ml.p3.2xlarge ),用于使用处理作业运行批量预测。
如果这是您首次在上述实例类型上运行 SageMaker 服务,则可能需要
设置您的资源
完成所有先决条件后,您就可以部署解决方案了。
-
创建 SageMaker 笔记本实例 。 对于此任务,我们建议使用ml.t3.medium 实例类型。在运行代码时,我们使用docker build通过 ByteTrack 代码扩展 SageMaker 训练镜像(docker build命令将在笔记本实例环境中本地运行)。因此,我们建议将卷大小从高级配置选项增加到 100 GB(默认卷大小增加到 5 GB)。对于您的 AWS 身份和访问管理 (IAM) 角色,选择现有角色或创建新角色,然后将 Amazons3FullAccess、AmazonsS nsFullAccess、AmazonsagemakerFullAccess 和 AmazonElastic ContainerRegistryPublifullAccess 策略附加到该角色。 -
将
GitHub 存储库克隆 到您创建 的笔记本实例上的/HOME/ec2-user/SageMaker 文件夹。 -
创建 新的亚马逊 Simple Storage Servic e (Amazon S3) 存储桶或使用现有存储桶。
为数据集添加标签
在 data
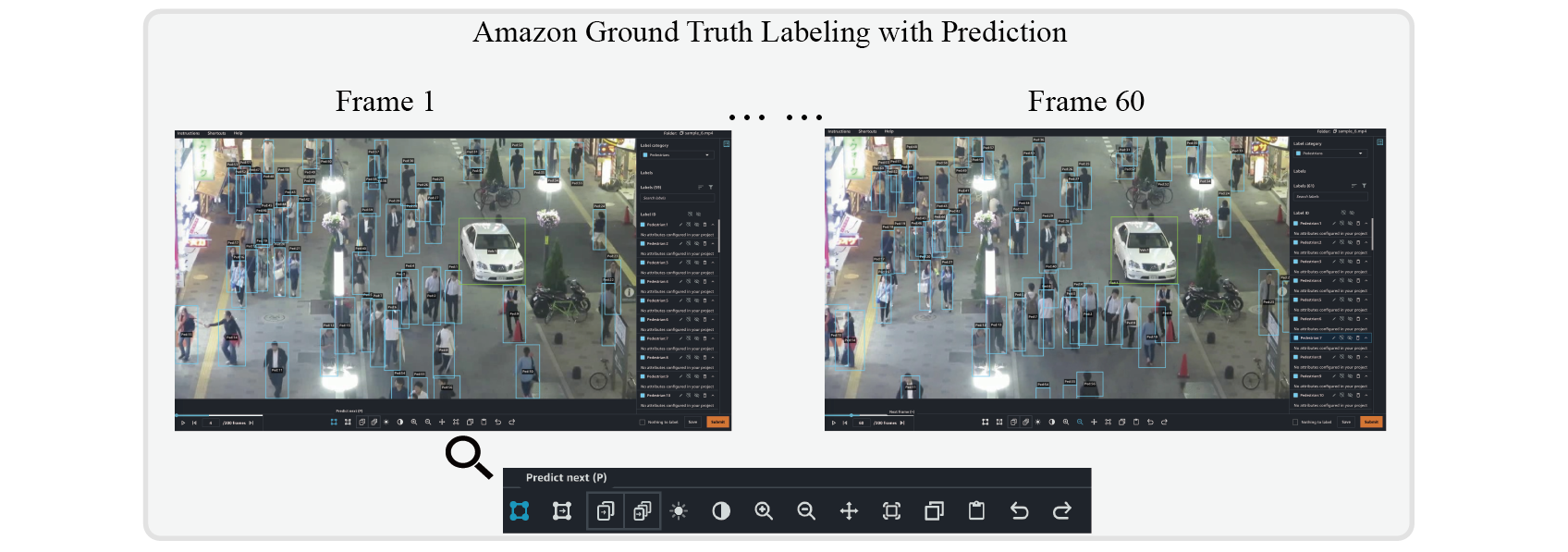
要标记 MOT 任务的数据集,请参阅

如果我们完成了对所有文件的标记,
清单
目录应该包含一个
输出
文件 夹。
我们可以在输出文件夹中看到 ou
此清单文件包含有关视频和视频跟踪标签的信息,您可以稍后使用这些信息来训练和测试模型。
tput.manifest
文件。
训练 ByteTrack 模型并调整自定义数据集上的超参数
为了训练你的 Bytetrack 模型,我们使用 bytetrack-training.ip
- 初始化 SageMaker 设置。
- 执行数据预处理。
- 生成并推送容器镜像。
- 定义训练作业。
- 启动训练作业。
- 调整超参数。
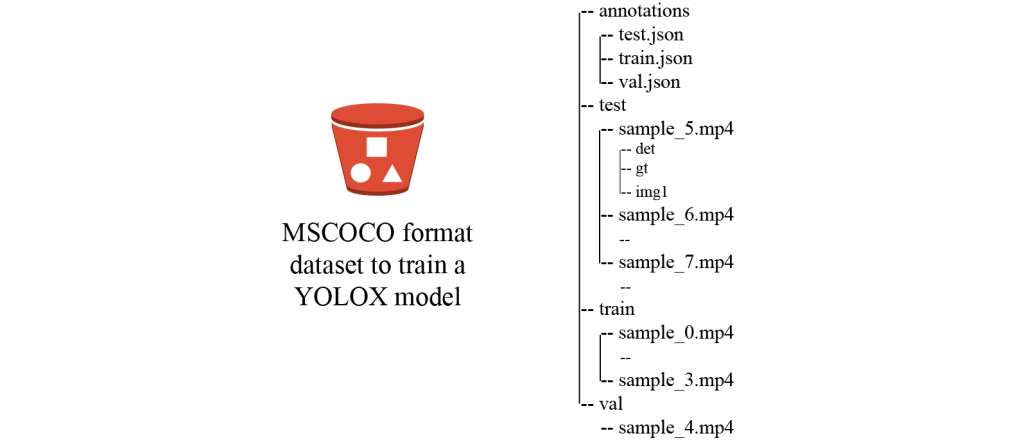
特别是在数据预处理中,我们需要将采用 Ground Truth 输出格式的标记数据集转换为 MOT17 格式的数据集,并将 MOT17 格式的数据集转换为 MSCOCO 格式的数据集(如下图所示),这样我们才能在自定义数据集上训练 YOLOX 模型。由于我们同时保留 MOT 格式数据集和 MSCOCO 格式的数据集,因此您可以训练其他 MOT 算法,而无需在 MOT 格式数据集上分离检测和跟踪。您可以轻松地将探测器更改为其他算法,例如 YOLO7,以使用现有的物体检测算法。
部署经过训练的 ByteTrack 模型
训练 YOLOX 模型后,我们部署经过训练的模型进行推理。
由于 SageMaker 批量转换要求将数据分区并作为输入存储在 Amazon S3 上,同时将调用发送到推理终端节点,因此它不符合需要按顺序发送目标的对象跟踪任务的要求。因此,我们不使用 SageMaker 批处理转换作业来运行批量推断。在此示例中,我们使用 SageMaker 处理作业进行批量推断。
下表总结了我们的推理作业的配置。
| Inference Type | Payload | Processing Time | Auto Scaling |
| Real-time | Up to 6 MB | Up to 1 minute | Minimum instance count is 1 or higher |
| Asynchronous | Up to 1 GB | Up to 15 minutes | Minimum instance count can be zero |
| Batch (with processing job) | No limit | No limit | Not supported |
部署实时推理端点
要部署实时推理端点,我们可以运行 bytetrack-inferenc
我们使用 SageMaker PytorchModel SDK 来创建和部署字节跟踪模型,如下所示:
成功将模型部署到端点后,我们可以使用以下代码片段调用推理端点:
在接受来自端点的检测结果后,我们在客户端运行跟踪任务(参见以下代码)。通过在每帧中绘制跟踪结果并另存为跟踪视频,您可以确认跟踪视频上的跟踪结果。
部署异步推理端点
SageMaker 异步推理是具有较大负载大小(最大 1 GB)、处理时间长(最多 1 小时)和接近实时延迟要求的请求的理想选择。对于 MOT 任务,视频文件通常超过 6 MB,这是实时端点的有效载荷限制。因此,我们部署了一个异步推理端点。有关如何部署
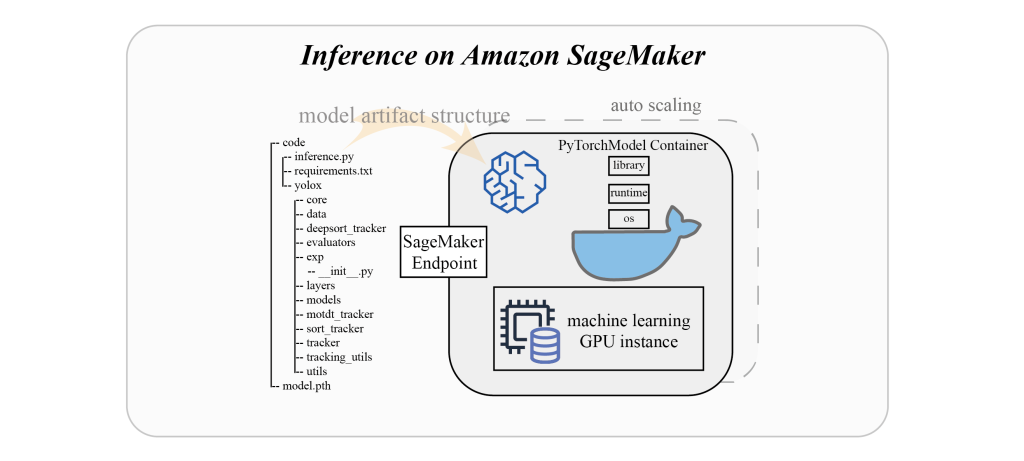
要在终端上使用与 ByteTrack 相关的脚本,我们需要将跟踪脚本和模型放入同一个文件夹,将该文件夹与
model.tar.gz
文件压缩在一起,然后将其上传到 S3 存储桶以创建模型。下图显示了
model.tar.gz
的结构 。
我们需要将请求大小、响应大小和响应超时明确设置为环境变量,如以下代码所示。环境变量的名称因框架而异。有关更多详细信息,请参阅
调用异步终端节点时,我们不是在请求中发送负载,而是发送输入视频的 Amazon S3 URL。当模型推断完成视频处理后,结果将保存在 S3 输出路径上。我们可以配置
使用 SageMaker 处理运行批量推断
对于大于 1 GB 的视频文件,我们使用 SageMaker 处理作业进行批量推断。我们定义了一个自定义 Docker 容器来运行 SageMaker 处理作业(参见以下代码)。我们在输入视频上绘制跟踪结果。您可以在
s3
_output 定义的 S3 存储桶中找到结果视频。
清理
为避免不必要的成本,请删除您在本解决方案中创建的资源,包括推理端点。
结论
这篇文章演示了如何使用SageMaker上最先进的算法之一在自定义数据集上实现多对象跟踪解决方案。我们还在 SageMaker 上演示了三种部署选项,以便您可以为自己的业务场景选择最佳选项。如果用例需要低延迟并且需要在边缘设备上部署模型,则可以使用
有关更多信息,请参阅
作者简介
 Gordon Wang
是 亚马逊云科技 高级人工智能/机器学习专家 TAM。他利用跨行业的人工智能/机器学习最佳实践为战略客户提供支持。他热衷于计算机视觉、自然语言处理、生成式 AI 和 mLOP。在业余时间,他喜欢跑步和远足。
Gordon Wang
是 亚马逊云科技 高级人工智能/机器学习专家 TAM。他利用跨行业的人工智能/机器学习最佳实践为战略客户提供支持。他热衷于计算机视觉、自然语言处理、生成式 AI 和 mLOP。在业余时间,他喜欢跑步和远足。
 崔延伟博士
是 亚马逊云科技 高级机器学习专家解决方案架构师。他在 IRISA(计算机科学与随机系统研究所)开始了机器学习研究,并在计算机视觉、自然语言处理和在线用户行为预测领域构建人工智能驱动的工业应用方面拥有多年经验。在 亚马逊云科技,他分享领域专业知识,帮助客户释放业务潜力,并通过大规模机器学习推动可操作的结果。工作之余,他喜欢阅读和旅行。
崔延伟博士
是 亚马逊云科技 高级机器学习专家解决方案架构师。他在 IRISA(计算机科学与随机系统研究所)开始了机器学习研究,并在计算机视觉、自然语言处理和在线用户行为预测领域构建人工智能驱动的工业应用方面拥有多年经验。在 亚马逊云科技,他分享领域专业知识,帮助客户释放业务潜力,并通过大规模机器学习推动可操作的结果。工作之余,他喜欢阅读和旅行。
 Melanie Li 博士
是位于澳大利亚悉尼的 亚马逊云科技 高级人工智能/机器学习专家 TAM。她帮助企业客户利用 亚马逊云科技 上最先进的 AI/ML 工具构建解决方案,并通过最佳实践为架构和实施机器学习解决方案提供指导。在业余时间,她喜欢在户外探索大自然,并与家人和朋友共度时光。
Melanie Li 博士
是位于澳大利亚悉尼的 亚马逊云科技 高级人工智能/机器学习专家 TAM。她帮助企业客户利用 亚马逊云科技 上最先进的 AI/ML 工具构建解决方案,并通过最佳实践为架构和实施机器学习解决方案提供指导。在业余时间,她喜欢在户外探索大自然,并与家人和朋友共度时光。
 杨光
是亚马逊机器学习解决方案实验室的高级应用科学家 ,他在该实验室与各个垂直领域的客户合作,运用创造性的问题解决方法,通过最先进的 ML/AI 解决方案为客户创造价值。
杨光
是亚马逊机器学习解决方案实验室的高级应用科学家 ,他在该实验室与各个垂直领域的客户合作,运用创造性的问题解决方法,通过最先进的 ML/AI 解决方案为客户创造价值。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。