我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
在 亚马逊云科技 上实施以太坊智能合约开发的 CI/CD 管道 — 第 2 部分
本文讨论了
解决方案概述
本文中的 亚马逊云科技 CDK 代码建立在第 1 部分的解决方案架构之上,如下图所示。
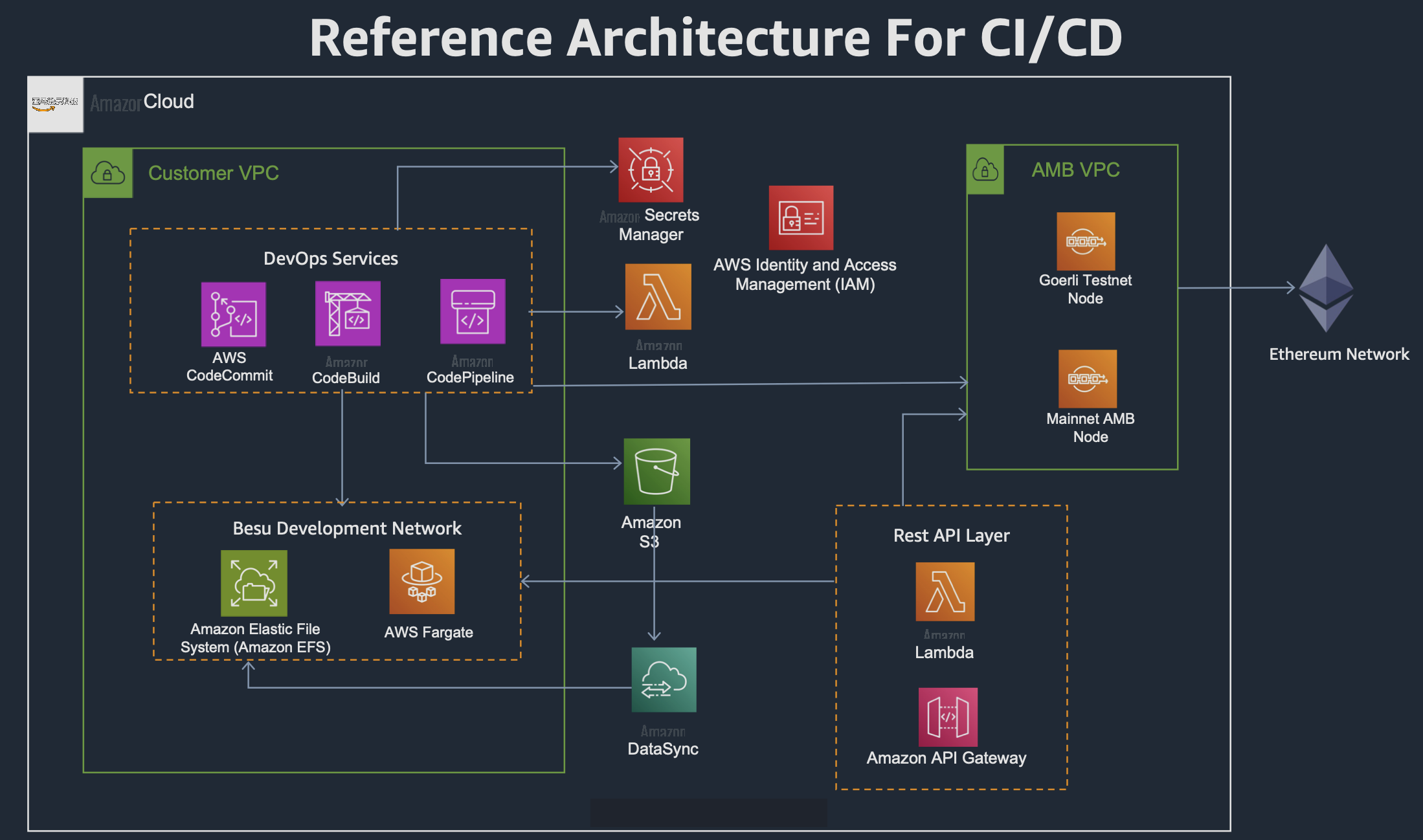
亚马逊云科技 CDK 代码在 AW
自述
文件包含有关如何部署 亚马逊云科技 CDK 堆栈的说明,以便创建架构中显示的所有资源。当您在您的 亚马逊云科技 账户中部署堆栈时,在安装和配置所有 亚马逊云科技 服务之后,它还将运行 CI/CD 管道。
亚马逊云科技 CDK 项目代码组织
以下屏幕截图显示了实施我们的 CI/CD 管道的 亚马逊云科技 CDK 项目是如何布局的。
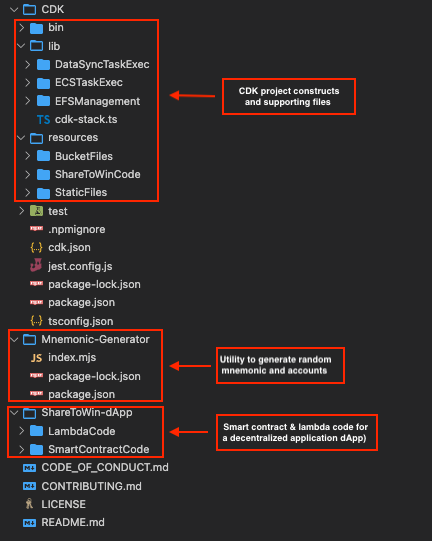
所有 AWS CDK
DataSyncTaskExec 、 ecstaskExec
和 e
fsManagem
ent 这三个文件夹包含支持 cdk-st
ack.ts 文件中的 AWS CDK 定制
堆栈中所需的所有各种配置和.zip 文件都在资源文件夹中。
Sharetowin-dApp
实现了一个示例去中心化应用程序,并用作 CI/CD 管道的基础应用程序。我们将在本文后面详细讨论其中的一些文件。
以太坊开发网络:Hyperledger Besu
正如本系列第一部分所讨论的那样,以太坊开发网络允许无限量供应以太币用于测试和调试目的,因此在开发阶段被广泛使用。为了支持多开发者团队,该开发网络需要在允许多个开发人员连接的基础架构上运行。本文中讨论的示例 CI/CD 基础设施使用
在启动 Besu 节点时,Besu 会读取两个配置文件 ,即 d
ev .json
和 config.toml
。这两个文件都是由 A
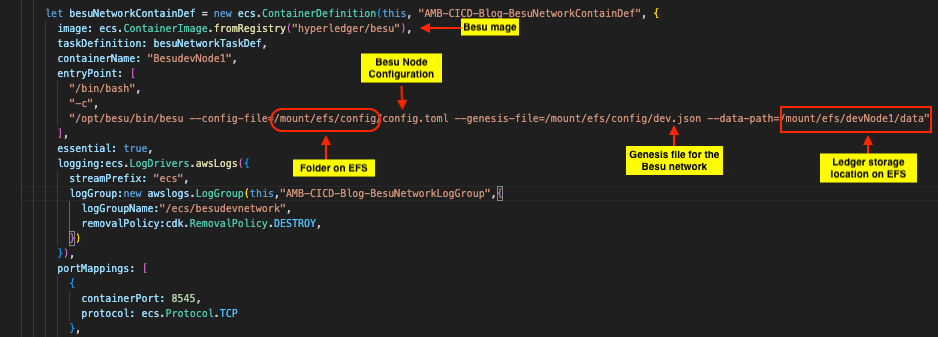
作为创世 文件提供的
dev.json
文件创建了 10 个测试以太坊地址。它的公钥和私钥在
dev.json
文件中提供。这些地址基于
Mnemonic-Generator
文件夹中提供了一个实用程序,可随机创建新的助记词组和 10 个带有公钥和私钥对的帐户,您可以使用这些帐户来创建自己的帐户。GitHub 存储库的自述文件包含如何运行此实用程序的详细步骤。
注意:请勿在使用此解决方案创建的任何生产 CI/CD 管道中使用 亚马逊云科技 CDK 项目中提供的助记符或从该助记符串派生的任何公钥或私钥。在没有真正的以太币关联的开发网络中,从中衍生出的助记符和地址只能用于学习目的。
存储助记符和其他秘密
CI/CD 管道需要某些与安全相关的参数,例如
除了在开发网络上进行测试外,请勿将前面的助记符用于任何目的。
在前面的代码中,仅提供了与开发网络相关的助记符;其余的密钥留待用户在创建 亚马逊云科技 CDK 堆栈后输入。亚马逊云科技 CDK 资源仅为这些密钥提供占位符。
S3 存储桶
亚马逊云科技 CDK 堆栈创建了一个名为
amb-cicd-blog-s3bucket 的 S3 存储桶, 并将所有文件复制到 G
itHub 存储库上 亚马逊云科技 CDK 项目的 Resour
ces/Buc
ketFiles 文件夹中。
BucketFiles 文件夹中的文件
如下所示:
- BlockchainDevLayer.zip — 这个.zip 文件用于为作为已部署的 DApp 一部分的 Lambda 依赖项创建 Lambda 层。
- config.toml — 这是 Besu 节点的配置文件。
- deploy.js — 此文件是将智能合约部署到以太坊网络所必需的。
- dev.json — 这是贝苏网络的创世文件。
-
hardhat.config.js
— CI/CD 管道内部使用 H
ardhat 来编译和部署智能合约。Besu 和Goerli 的网络都是在这个文件中定义 的。 - ShareToWinLambda.zip — 这个.zip 文件包含为支持 DApp 而创建的 Lambda 函数的源代码。
自定义资源提供者
为了配置和运行 Besu 开发网络,亚马逊云科技 CDK 定义了三个自定义资源提供商。这些提供商配置了 Lambda 函数,使其在创建、更新和删除
创建 EFS 文件夹
Besu 节点需要在文件系统上具有特定的文件夹结构。
在 AWS CDK 堆栈创建 EFS 卷后,将运行
lib/EFSManagement 文件夹中定义的 Lambda 函数,在 EF
S 卷上创建
配置
和 数据文件夹。
配置
文件夹包含运行 Besu 节点时所需的文件,
数据
文件夹包含账本数据库、密钥和 Besu 节点所需的其他文件。启动 Besu 节点时,这两个文件夹的位置以命令形式提供。
将文件从亚马逊 S3 复制到亚马逊 EFS
c
ustrsrcDatasyncTasklambdaExec 自定义资源负责通过 DataSync 任务
将文件从亚马逊 S3 复制到亚马逊 EFS。亚马逊云科技 CDK 堆栈定义了一个 DataSync 任务,该任务以 Amazon S3 作为源位置,将亚马逊 EFS 作为目标位置。
与该自定义资源相关的 Lambda 函数位于
lib/datasyncTaskExec 中,用于运行 DataSync 任务 ,该任务会在 EC
S 集群上的 Besu 节点启动之前复制
config.toml 和 dev.js
on 文件。
运行 Besu 节点的 ECS 任务
由启动 Besu 节点的 AWS CDK 堆栈创建的 Fargate 任务由一个名为 custrsrcecstaskLambdaExec 的自定义资源启动。
它关联的 Lambda 函数位于
lib/ecstaskExe
c 文件夹中。ECS 任务在启用公有 IP 的情况下启动。这个公有 IP 是 亚马逊云科技 CDK 堆栈的输出参数,也被配置为其他 亚马逊云科技 CDK 结构的环境变量,我们稍后将讨论。
去中心化应用程序的代码存储库
这篇文章的 GitHub 存储库提供了一个示例 dApp,用作创建 CI/CD 管道的基础。
此示例应用程序由 Sharetowin-dapp/
此示例 dApp
smartContractcode/ContractContractcode/Contracts 文件夹 中的智能合约 AssetToken.s ol
和调用智能合约中函数的 Sharetwin-dapp/lambdacode/
index.mjs 文件中的 Lambda 函数组成。
开发相同或不同智能合约的多个开发者只需将其智能合约文件 (*.sol) 上传到此存储库中的合约文件夹即可。这样,他们就可以在本地开发环境中自由使用他们选择的任何 IDE 工具和扩展,并且只将经过单元测试的.sol 文件推送到 GitHub 存储库以集成到 CI/CD 管道中。开发人员还应将其智能合约的任何 npm 依赖项添加到智能合约代码的 pro
ject.json
文件中,这样 CI/CD 就可以在构建和部署智能合约时注入这些依赖关系。
一个包含 dApp 所有代码的.zip 文件被创建并存储在
资源/sharetoWinCode
文件夹中,以使其可用于 亚马逊云科技 CDK 堆栈。该堆栈创建了一
代码生成项目
亚马逊云科技 CDK 堆栈定义了两个
es
/StaticFiles 文件夹中。
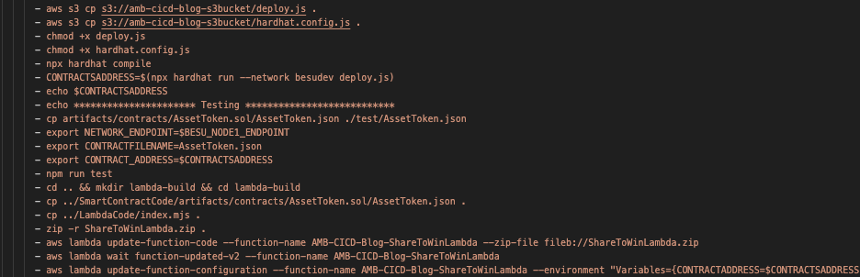
Besu CodeBuild 项目的编译规范文件名为 besubuildspec.yml,Goerli Code
以下屏幕截图显示了 besubuildspec.yml 文件的代码片段,我们将对其进行更详细的讨论。
Build 项目的编译规范文件名为 goerlibuildspec.yml
。
CodeBuild 使用 Hardhat 来编译和部署智能合约。
ardhat
.config.js文件中需要与之交互的各种区块链网络。该文件是此 亚马逊云科技 CDK 项目的一部分,已上传到亚马逊 S3 以供 CodeBuild 使用。buildspec 文件中的以下代码从 Amazon S3 下载这两个文件,以便在 CodeBuild 环境中使用:
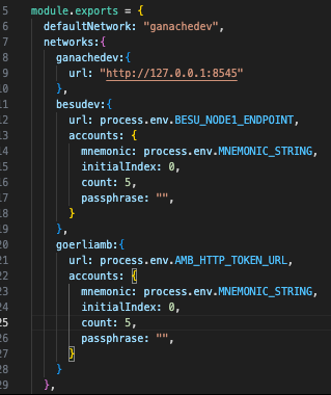
以下屏幕截图显示了
hardhat.config.j
s 文件中定义的各种区块链网络配置。
构建过程的下一步是编译智能合约并将其部署到 Besu 网络,这是通过运行以下两个命令来完成的:
运行这些命令后,CodeBuild 环境可以访问新部署的智能合约地址以及作为编译命令输出生成的智能合约的
构建和部署过程的下一步是 CodeBuild 运行智能合约代码库中提供的测试脚本。如果测试脚本失败,则整个构建管道将被回滚并且管道处于失败状态。
测试脚本成功后,它会使用智能合约的 ABI 以及 dApp Lambda 存储库中的 Lambda 代码,并创建一个新的.zip 文件,用于部署新版本的 Lambda 代码。它还更新了 dApp Lambda 环境变量,使其指向新部署的智能合约地址。以下代码片段显示了如何在 buildspec 文件中完成此操作:
目前,CI/CD 管道处于手动批准阶段。在批准此阶段之前,请确保 Secrets Managers 中的托管区块链计费令牌网址和与 Goerli 相关的助记符字符串已更新;否则,Goerli 构建项目将因无法检索这些机密而失败。
此示例代码使用托管区块链计费令牌访问托管区块链上的以太坊节点。有两种访问托管区块链节点的方法:通过计费令牌或通过 Sigv4。有关这些方法的更多信息,请参阅
清理
要终止我们在本文中创建的资源,请运行以下命令:
结论
在这篇文章中,我们对
试用
作者简介
 Rafia Tapia
是一位区块链解决方案架构专家。她拥有超过27年的软件开发和架构经验,对开发智能合约和区块链技术的设计模式和最佳实践有着浓厚的兴趣。
Rafia Tapia
是一位区块链解决方案架构专家。她拥有超过27年的软件开发和架构经验,对开发智能合约和区块链技术的设计模式和最佳实践有着浓厚的兴趣。
 Kranthi Manchikanti
是 亚马逊云科技 的云解决方案架构师,在为企业客户设计和实施可扩展的云解决方案方面拥有丰富的经验。对于希望将其应用程序迁移到云端并实现其现代化的组织而言,Kranthi 是一位值得信赖的顾问。他还为开源社区做出了重大贡献,包括Linux和Hyperledger基金会。
Kranthi Manchikanti
是 亚马逊云科技 的云解决方案架构师,在为企业客户设计和实施可扩展的云解决方案方面拥有丰富的经验。对于希望将其应用程序迁移到云端并实现其现代化的组织而言,Kranthi 是一位值得信赖的顾问。他还为开源社区做出了重大贡献,包括Linux和Hyperledger基金会。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。