我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 SageMaker 选择图像分类模型 JumpStart
研究人员继续为常见的机器学习 (ML) 任务开发新的模型架构。其中一项任务是图像分类,其中图像被接受为输入,模型尝试使用对象标签输出将图像作为一个整体进行分类。当今有许多模型可以执行此图像分类任务,机器学习从业者可能会问诸如此类的问题:“我应该微调然后部署哪个模型才能在我的数据集上获得最佳性能?”机器学习研究人员可能会问这样的问题:“在控制训练超参数和计算机规格(例如 GPU、CPU 和 RAM)的同时,如何才能自己生成多个模型架构与指定数据集的公平比较?”前一个问题涉及跨模型架构的模型选择,而后一个问题涉及根据测试数据集对经过训练的模型进行基准测试。
在这篇文章中,您将看到
解决方案概述
下图说明了在
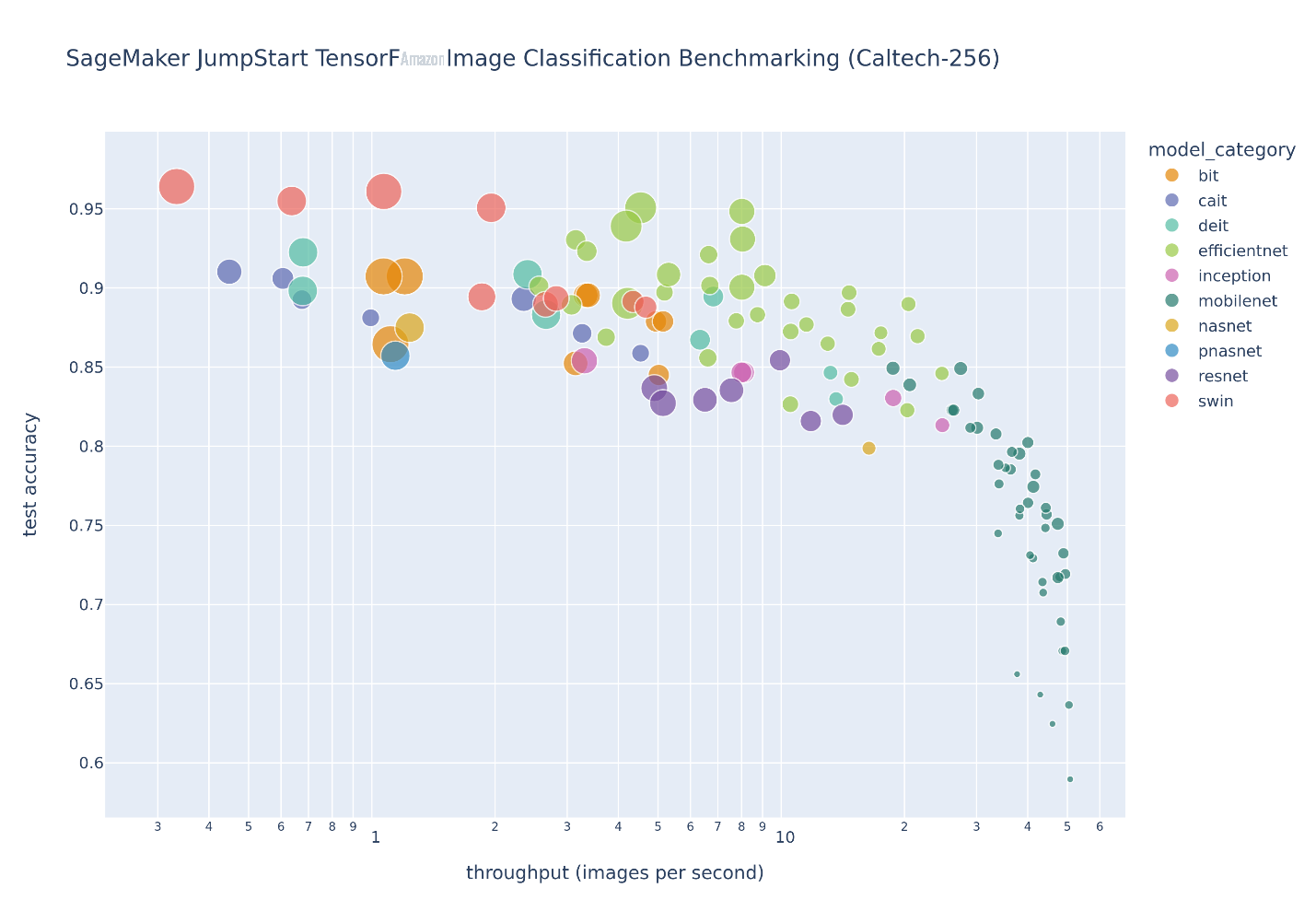
如果您观察到感兴趣的测试精度和测试吞吐量前沿,则将在下表中提取上图中的一组帕累托高效解。对行进行排序,使得测试吞吐量增加,测试精度降低。
| Model Name | Number of Parameters | Test Accuracy | Test Top 5 Accuracy | Throughput (images/s) | Duration per Epoch(s) |
| swin-large-patch4-window12-384 | 195.6M | 96.4% | 99.5% | 0.3 | 2278.6 |
| swin-large-patch4-window7-224 | 195.4M | 96.1% | 99.5% | 1.1 | 698.0 |
| efficientnet-v2-imagenet21k-ft1k-l | 118.1M | 95.1% | 99.2% | 4.5 | 1434.7 |
| efficientnet-v2-imagenet21k-ft1k-m | 53.5M | 94.8% | 99.1% | 8.0 | 769.1 |
| efficientnet-v2-imagenet21k-m | 53.5M | 93.1% | 98.5% | 8.0 | 765.1 |
| efficientnet-b5 | 29.0M | 90.8% | 98.1% | 9.1 | 668.6 |
| efficientnet-v2-imagenet21k-ft1k-b1 | 7.3M | 89.7% | 97.3% | 14.6 | 54.3 |
| efficientnet-v2-imagenet21k-ft1k-b0 | 6.2M | 89.0% | 97.0% | 20.5 | 38.3 |
| efficientnet-v2-imagenet21k-b0 | 6.2M | 87.0% | 95.6% | 21.5 | 38.2 |
| mobilenet-v3-large-100-224 | 4.6M | 84.9% | 95.4% | 27.4 | 28.8 |
| mobilenet-v3-large-075-224 | 3.1M | 83.3% | 95.2% | 30.3 | 26.6 |
| mobilenet-v2-100-192 | 2.6M | 80.8% | 93.5% | 33.5 | 23.9 |
| mobilenet-v2-100-160 | 2.6M | 80.2% | 93.2% | 40.0 | 19.6 |
| mobilenet-v2-075-160 | 1.7M | 78.2% | 92.8% | 41.8 | 19.3 |
| mobilenet-v2-075-128 | 1.7M | 76.1% | 91.1% | 44.3 | 18.3 |
| mobilenet-v1-075-160 | 2.0M | 75.7% | 91.0% | 44.5 | 18.2 |
| mobilenet-v1-100-128 | 3.5M | 75.1% | 90.7% | 47.4 | 17.4 |
| mobilenet-v1-075-128 | 2.0M | 73.2% | 90.0% | 48.9 | 16.8 |
| mobilenet-v2-075-96 | 1.7M | 71.9% | 88.5% | 49.4 | 16.6 |
| mobilenet-v2-035-96 | 0.7M | 63.7% | 83.1% | 50.4 | 16.3 |
| mobilenet-v1-025-128 | 0.3M | 59.0% | 80.7% | 50.8 | 16.2 |
这篇文章详细介绍了如何实施大规模的
JumpStart TensorFlow 图像分类简介
JumpStart 提供针对常见机器学习任务的一键微调和部署各种预训练模型,以及一系列解决常见业务问题的端到端解决方案。这些功能消除了机器学习流程中每个步骤的繁重工作,使开发高质量模型变得更加容易,缩短了部署时间。
JumpStart 模型中心提供对大量
每个模型架构的内部结构都大不相同。例如,ResNet 模型利用跳过连接来实现更深层次的网络,而基于变换器的模型则使用自我注意力机制,这些机制消除了卷积运算的固有局部性,转而支持更多的全球接受场。除了这些不同的结构提供的不同功能集外,每个模型架构还有多种配置,可以调整该架构中的模型大小、形状和复杂性。这导致 JumpStart 模型中心提供了数百种独特的图像分类模型。结合包含许多 SageMaker 功能的内置迁移学习和推理脚本,JumpStart API 是机器学习从业者快速开始训练和部署模型的绝佳起点。
请参阅
大规模模型选择注意事项
模型选择是从一组候选模型中选择最佳模型的过程。此过程可以应用于具有不同参数权重的相同类型的模型以及不同类型的模型。跨相同类型的模型选择模型的示例包括使用不同的超参数(例如学习率)拟合同一个模型,以及提早停止以防止模型权重过度拟合到训练数据集中。
跨不同类型的模型选择模型包括选择最佳模型架构(例如,Swin 与 MobileNet),以及在单一模型架构中选择最佳模型配置(例如,mobilenet-v1-025-128 与
mobilen
et-v3-large-100-224)。
本节中概述的注意事项使验证数据集上的所有这些模型选择过程成为可能。
选择超参数配置
JumpStart 中的 TensorFlow 图像分类具有大量可用的
在本分析和相关的笔记本中,除学习率、周期数和提前停止规格外,所有超参数都设置为默认值。学习率 由
一个特别重要的默认超参数设置是 t
rain_only_only_top_layer
,如果设置为 T
rue
,则不会根据提供的训练数据集对模型的特征提取层进行微调。优化器将仅训练顶部完全连接的分类图层中的参数,其输出维度等于数据集中类别标签的数量。默认情况下,此超参数设置为
True
,这是针对小型数据集的迁移学习的设置。您可能有一个自定义数据集,其中从 ImageNet 数据集的预训练中提取特征是不够的。
在这些情况下,你应该将 t
尽管此设置会增加训练时间,但您将为感兴趣的问题提取更多有意义的特征,从而提高准确性。
rain_only_only_top_l
ayer 设置为 False。
从 CloudWatch 日志中提取指标
JumpStart TensorFlow 图像分类算法在训练期间可靠地记录 SageMaker Estimator 和 HyperParameterTuner 对象可以访问的各种指标。
SageMaker E
stimator
的构造函数 具有
metric_d
efinition s 关键字参数,该参数可用于通过提供带有两个键的字典列表来评估训练作业:名称代表指标名称,正则表达式代表用于从日志中提取指标的正则
表达式
。随附的
| Metric Name | Regular Expression |
| number of parameters | “- Number of parameters: ([0-9\\.]+)” |
| number of trainable parameters | “- Number of trainable parameters: ([0-9\\.]+)” |
| number of non-trainable parameters | “- Number of non-trainable parameters: ([0-9\\.]+)” |
| train dataset metric | f”- {metric}: ([0-9\\.]+)” |
| validation dataset metric | f”- val_{metric}: ([0-9\\.]+)” |
| test dataset metric | f”- Test {metric}: ([0-9\\.]+)” |
| train duration | “- Total training duration: ([0-9\\.]+)” |
| train duration per epoch | “- Average training duration per epoch: ([0-9\\.]+)” |
| test evaluation latency | “- Test evaluation latency: ([0-9\\.]+)” |
| test latency per sample | “- Average test latency per sample: ([0-9\\.]+)” |
| test throughput | “- Average test throughput: ([0-9\\.]+)” |
内置的迁移学习脚本在这些定义中提供了各种训练、验证和测试数据集指标,以 f 字符串替换值表示。可用的确切指标因所执行的分类类型而异。所有编译后的模型都有一个
损失
指标,该指标由二进制或分类问题的交叉熵损失表示。当有一个分类标签时使用前者;如果有两个或更多类别标签,则使用后者。
,以及精确召回 (PR) 曲线 (pr
如果只有一个分类标签,则可以通过上表中的 f 字符串正则表达式计算、记录和提取以下指标:真阳性数 (true_pos)、假阳性数 (false
_pos )、真否定数 (tr
ue_n
eg )、假否定数 (false _
neg )、精度、召回率、接收
性曲线下方的面积 (ROC) (auc )
器
运行特
c
) 下方的区域。同样,如果有六个或更多类标签,则还可以通过前面的正则表达式计算、记录和提取排名前五的
精度指标(top_5_
accuracy )。
在训练期间,向 SageMaker
估算器指定的指标将发送到 CloudWatch
Logs。训练完成后,你可以调用
fin
alMetricDataList 密钥:
此 API 只需要向查询提供作业名称,因此,一旦完成,只要训练作业名称经过适当记录并可恢复,就可以在将来的分析中获得指标。对于此模型选择任务,将存储超参数调整作业名称,后续分析会重新附加给定调优作业名称的 HyperP
arameterTuner 对象,从附加的超参数调谐器
中提取最佳训练作业名称,然后如前
所述调用 DescribeTrainingJob API 以获取与最佳训练作业
相关的指标。
启动异步超参数调整作业
有关异步启动超参数调整作业 的实现详细信息,请参阅相应的
-
每个 亚马逊云科技 账户都与
SageMaker 服务 配额相关联。 您应该查看当前的限制,以充分利用您的资源,并可能根据需要请求增加资源限制。 -
频繁调用 API 来创建许多同步超参数调整作业可能会
超过 Python SDK 速率并引发限制异 常。 解决这个问题的方法是使用自定义重试配置创建一个 SageMaker Boto3 客户端。 -
如果你的脚本遇到错误或者脚本在完成之前停止,会发生什么?对于如此大规模的模型选择或基准测试研究,您可以记录调整作业名称并提供便捷功能来
重新连接 已经存在的超参数调整作业 :
分析细节和讨论
这篇文章中的分析对加州理工学院256数据集的JumpStart TensorFlow图像分类算法 中的
训练结束时,将在训练实例上评估测试数据集。模型选择在测试数据集评估之前进行,以将模型权重设置为具有最佳验证集性能的时代。测试吞吐量未优化:数据集批量大小设置为默认的训练超参数批次大小,未对其进行调整以最大限度地提高 GPU 内存使用量;报告的测试吞吐量包括数据加载时间,因为数据集未预先缓存;未使用跨多个 GPU 的分布式推理。出于这些原因,此吞吐量是一个很好的相对测量值,但实际吞吐量将在很大程度上取决于训练模型的推理端点部署配置。
尽管JumpStart模型中心包含许多图像分类架构类型,但这个帕累托前沿由精选的Swin、EfficientNet和MobileNet模型主导。Swin 模型更大,相对更准确,而 MobileNet 模型更小,精度相对较低,适合移动设备的资源限制。值得注意的是,这一前沿取决于多种因素,包括所使用的确切数据集和所选的微调超参数。您可能会发现,您的自定义数据集生成了一组不同的帕累托高效解决方案,并且您可能希望使用不同的超参数来延长训练时间,例如更多的数据增强或微调,而不仅仅是模型的顶级分类层。
结论
在这篇文章中,我们展示了如何使用 JumpStart 模型中心运行大规模模型选择或基准测试任务。该解决方案可以帮助您选择最适合您需求的型号。我们鼓励您在自己的数据集 上尝试和探索此
参考文献
更多信息可在以下资源中获得:
-
图像分类 — TensorFlow -
使用亚马逊 SageMaker 进行图像分类 JumpStart -
使用亚马逊 SageMaker JumpStart 构建高性能图像分类模型
作者简介
 凯尔·乌尔里希博士
是
凯尔·乌尔里希博士
是
 Ashish Khetan 博士
是一位高级应用科学家,拥有
Ashish Khetan 博士
是一位高级应用科学家,拥有
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。