我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
苏黎世保险如何利用 Amazon SageMaker 成为人工智能主导的保险公司
这篇亚马逊云科技 FSI 博客文章概述了英国苏黎世保险公司(或本文其余部分中的"苏黎世")如何利用人工智能和机器学习 (AI/ML) 以及 Amazon SageMaker 来预测洪水索赔,从而主动保护客户免受潜在灾难性事件的影响。苏黎世保险集团(苏黎世)是一家领先的保险公司,在全球范围内提供财产、意外伤害和人寿保险解决方案。2022 年,苏黎世启动了一项为期多年的计划,通过将 1,000 个应用程序(包括核心保险和 SAP 工作负载)迁移到亚马逊云科技,加速其数字化转型和创新。
导言
几百年来,保险模式大致相同。客户(通常是企业)购买保单,在发生灾难时,他们提出索赔并获得援助。这是一种成功的工作方式,并将持续到未来。但是,借助人工智能,保险公司可以通过全新的互补产品来增强这一点——苏黎世将这种主动方法称为"预测参数"。据《卫报》在其文章中报道,与气候有关的事件增加了英国的索赔,读者可以通过点击此链接找到这篇文章。
苏黎世主动保险的第一个用例是在洪水索赔发生前几周进行预测。洪水每年给英国的房屋和企业造成数十亿英镑的损失,由于气候变化,这个问题只会变得越来越严重。苏黎世正在使用多个数据源和 Amazon SageMaker,测试为客户财产提供预警的能力。如果发生洪水,如果苏黎世能够在一周或一个月内预测可能发生洪水,他们可以主动帮助客户降低这种风险。
关键业务挑战
尽管保险公司在数百年中积累了丰富的风险专业知识和数据,但手动评估方法无法有效预测数百万客户资产(从房地产到网络资产)的个人层面的索赔。机器学习 (ML) 现在通过实现自动化、持续的大规模风险监控来提供解决方案。
数据科学团队开发和训练模型,需要一条严格的生产路径,以确保模型部署和推理结果受管控且安全。这是 Amazon SageMaker 可以帮助客户为所有数据科学和机器学习操作 (MLOps) 奠定基础的地方,从而为人工智能模型提供一致且可审计的生产路径。借助内置的治理控制和监控功能,Amazon SageMaker 使苏黎世能够扩大其机器学习计划,同时保持负责任的人工智能实践。感兴趣的读者可以点击此链接,详细了解苏黎世对数据和负责任的人工智能的承诺。
使用 Amazon SageMaker 进行扩展
图 1 概述了使用 Amazon SageMaker 进行模型开发、部署和推理的端到端架构。为了便于阅读,图 2 中分别显示了模型批准和推广到生产环境的架构。这些图表共同代表了苏黎世采用的亚马逊云科技推荐的 MLOps 架构。
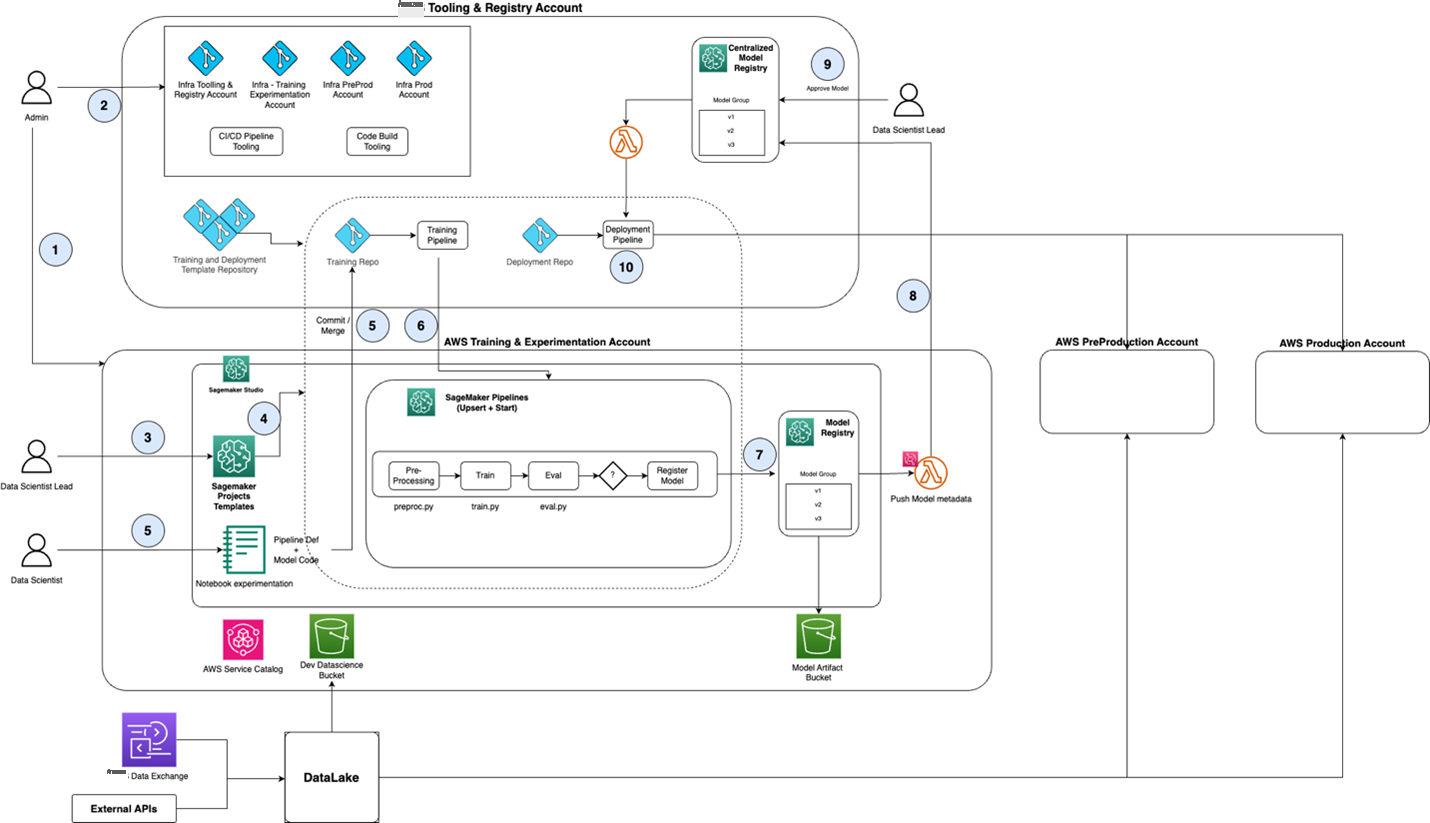
图 1:高级端到端 MLOps 架构
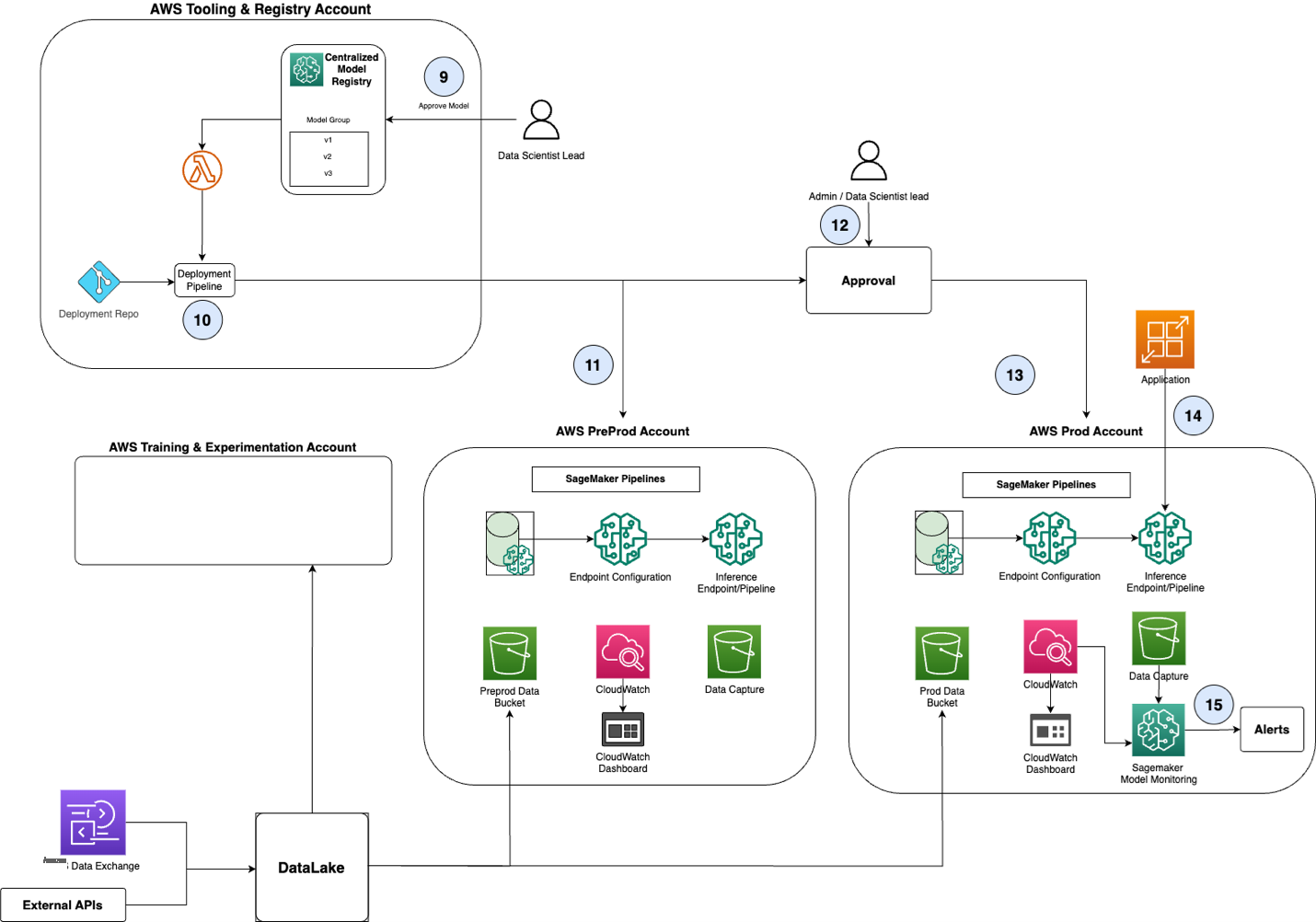
图 2:模型批准和推广
总体而言,完整架构包含一个中央工具和注册表帐户,以及用于为每个业务线 (LOB) 团队镜像环境的三个帐户:
- 训练和实验账户
- 用于 UAT 和测试的预生产账户(在图中标记为"preProd")
- 用于最终部署的生产帐户(图中标记为"Prod")
中央工具账户包含一个中央模型注册表,用于跟踪各个团队训练的模型、模型版本和部署状态。
苏黎世已使用亚马逊云科技合作伙伴 Snowflake 开发了其战略数据资产。该战略数据资产是该用例的主要数据源。以下是数据的处理方式:
- 每个客户的地址都经过匹配并链接到英国的唯一物业参考编号(UPRN),这是英国政府为有效识别各个地点而采用的标准。
- 其他外部来源,例如地理和天气数据,通过地理空间算法与 UPRN 进行匹配。
- 数据集经过匿名化(删除客户名称和地址)并存储在 Amazon S3 中。
- 然后,匿名数据将由 Amazon SageMaker 处理。
该数据源在图 1 中被描述为数据湖。
主要工作流程如下所述:
- 步骤 1 至 8 如图 1 所示
- 步骤 9 到 15 如图 2 所示
创建基础架构
首先,管理员角色(图 1 中的"管理员")创建了数据科学团队向 MLOps 工作流程提交模型所需的基础架构(图 1 中的步骤 1)。最初,"管理员"为数据科学团队创建三个亚马逊云科技账户(培训和实验、预生产和生产),然后执行 Terraform 脚本在这些账户中创建基础亚马逊云科技云基础设施。
培训和实验账户还包括一个新的 Amazon SageMaker Studio 域名,允许数据科学家使用他们首选的 IDE(例如 Jupyter 或 VS Code)进行构建(步骤 2)。
最后,该工作流程还为模型训练和模型部署创建了项目模板存储库,可以为每个数据科学项目克隆这些存储库。这些模板在 Amazon SageMaker 项目中注册为"项目模板",可供数据科学负责人为其项目克隆。例如,项目模板可能包含诸如 XGBoost 分类模型或使用 PyTorch 的深度学习模型之类的示例。
创建新项目
对于每个新的机器学习用例,数据科学负责人在训练和实验账户中登录 SageMaker Studio,选择符合其要求的项目模板,然后单击"部署"(步骤 3)。在幕后,这会触发一个 Amazon Lambda 函数,该函数克隆项目模板存储库以创建两个特定于项目的存储库(用于培训和部署代码),并使用所选的 CI/CD 工具设置 DevOps 管道(步骤 4)。该工作流程还创建了一个 S3 存储桶来存储用于训练和评估的数据。
训练和评估模型
数据科学家在训练和实验账户中使用 SageMaker Studio 访问来自 S3 的训练数据,并进行机器学习训练和评估实验(步骤 5)。
准备就绪后,数据科学家将训练代码提交到项目培训代码存储库中。提交会自动触发训练管道,该管道使用超参数优化和其他常用方法在完整数据集上训练模型。这样可以确保高性能模型不会过度拟合,并捕获模型性能的关键衡量标准(步骤 6)。
读者可以通过点击此链接查看 Amazon SageMaker 中可用的超参数调整策略。训练管道在团队的模型注册表中创建新的模型版本(步骤 7)。一旦对指标感到满意,数据科学家可以在其团队的模型注册表中触发批准流程,将模型推送到工具和注册账户中的集中模型注册表(步骤 8)。
将模型推广到 preProd 和 Prod
对模型和代码进行全面检查后,数据科学负责人将在工具和注册账户的集中式模型注册表中批准模型(图 2 中的步骤 9)。
因此,部署管道会自动触发(第 10 步),从而将模型工件升级到 Amazon SageMaker 的 PreProd 环境(步骤 11)。此处对模型进行测试,以保留数据集(存储在 Amazon S3 的预生产数据存储桶中),并与当前的生产实例(如果存在)进行比较(步骤 12)。
通过所需的检查后,数据科学负责人可以批准将模型工件部署到生产环境中(步骤 13)。Amazon SageMaker 开箱即用地支持不同的部署策略,例如一次性部署、金丝雀部署或线性部署。
监控风险
在生产中,该模型针对客户数据资产(存储在 Amazon S3 的生产数据存储桶中)运行,持续检查客户财产的洪水损失风险等级(图 2 中的步骤 14)。这种自动化是苏黎世如何根据需要扩展其监控客户群的能力的方式。以前,这项任务是不可能的,因为风险监控主要是手动任务,无法扩展到苏黎世承保的数千个客户资产。Amazon SageMaker 会监控模型中的关键风险,例如模型漂移和偏差(步骤 15)。
这个过程对于新模型是可重复的,每个新模型都存储在中央注册表中,从而为苏黎世的人工智能模型提供了一条一致且可审计的生产路径。
通过设计实现负责任的人工智能
Amazon SageMaker 的 MLOps 使苏黎世能够通过强大的监控和透明度来实施负责任的人工智能。苏黎世通过 Amazon SageMaker 将其人工智能保障框架直接集成到模型开发过程中,从而确保设计合规性。
为了减少模型训练中的偏见,他们的隐私优先方法在将个人信息(客户名称和地址,包括 UPRN)传输到 Amazon SageMaker 之前,将其从训练数据集中删除。该模型仅使用相关的属性特征,例如大小和与洪泛平原的距离来进行预测。
持续监控使苏黎世能够检测出其人工智能模型的突然性能变化和逐渐偏差。Amazon SageMaker 完全可审核的 MLOps 流程为每个开发步骤提供了清晰的文档,便于解释,并能够在需要时回滚模型。
可扩展性和可重用性
苏黎世是一家拥有分布式 AI 团队的全球性组织,需要一个用于生产模型和共享公司内部人工智能资产的平台。这些团队负责各种项目,不仅是风险模型,还有用于提高效率的生成式 AI 工具和简化客户互动的工具等。
苏黎世使用 Amazon SageMaker 对他们的 MLOps 进行了标准化,允许全球团队通过可追溯的流程部署模型。亚马逊云科技区域选择基于数据驻留要求。共享模型注册表允许在公司范围内发布和访问模型,包括统计数据和文档。通过这种方式,苏黎世正在开发模块化的人工智能组件,以加快风险模型的部署,同时最大限度地提高重复利用率。
英国苏黎世保险公司数据科学主管乔纳森·戴维斯强调了这种方法的影响:
"能够通过 Amazon SageMaker 重复使用部署模式极大地加快了我们的部署速度,从没有可重复使用模式的大约 26 周到使用这些模式的大约 8 周,整个组织中的其他团队也从中受益。"
交付方法
苏黎世已将 Amazon SageMaker 确立为其人工智能和机器学习工具包中的关键工具,内置 MLOps 功能,可确保他们能够快速构建和部署模型,并进行必要的检查,确保模型的可靠性、可审计性和安全性。特别是在英国,数据科学家一直在直接与亚马逊云科技团队合作,在将数据仓库资产迁移到亚马逊云科技上的 Snowflake 的同时,建立这种能力。这种组合意味着他们拥有一个端到端的平台,可以在该平台上根据现有风险经验中的匿名数据对人工智能和机器学习模型进行训练。部署这些模型是为了监控客户群中不断变化的风险。
为了加快 MLOps 平台的交付,苏黎世的数据科学团队与亚马逊云科技 FSI 原型设计和云工程 (PACE) 团队合作。FSI PACE 团队通过动手原型开发和领域专业知识的独特组合,加速金融服务客户的云之旅。通过为期 4 到 8 周的重点开发周期,该团队在亚马逊云科技自有账户中提供可行的解决方案,这些解决方案体现了切实的业务价值,同时通过基于体验的加速 (EBA) 研讨会实现知识传授,帮助客户成功部署和采用这些解决方案。
从白板会议开始,商定架构和范围,PACE 团队在 8 周内构建了原型,并使用 PACE 与苏黎世团队合作的 EBA 研讨会将第一个版本的代码部署到苏黎世的亚马逊云科技环境中。
结论
Amazon SageMaker 平台的实施标志着苏黎世在使用人工智能通过准确、及时的预测来防止洪水损失方面迈出了第一步,随着这些事件由于气候变化而变得更加频繁,这一点尤其重要。借助 Amazon SageMaker,苏黎世可以大规模开发 AI/ML 模型,采用严格的 MLOps 框架,确保模型能够在苏黎世快速部署和重复使用。苏黎世希望提高保险业使用人工智能的能力,确保客户始终获得优秀保障,目标是与 Amazon SageMaker 的合作仅仅是保险模式主动革命的开始。

Claire Sheridan
克莱尔·谢里丹是亚马逊云科技解决方案架构高级经理,与金融服务客户合作。她拥有信息学博士学位,在科技领域拥有超过 18 年的行业经验。她在合唱团唱歌,喜欢和丈夫和两个小男孩一起旅行。

Arnav Khare
Arnav Khare 是首席解决方案架构师,领导亚马逊云科技的人工智能/机器学习原型设计团队,与全球最大的金融机构合作。他的主要重点是帮助金融服务机构在云端构建生成式人工智能和机器学习应用程序,他还是一本关于同一主题的书的合著者。Arnav 拥有爱丁堡大学人工智能硕士学位,拥有 20 年的行业经验,从他创立的小型初创公司到除了亚马逊云科技以外的大型投资银行。

Jonathan Davis, PhD
乔纳森领导英国苏黎世保险公司的数据科学团队。他的团队致力于在整个企业中使用人工智能/机器学习推动创新,与整个企业的同事密切合作以推动价值。在苏黎世之前,乔纳森从事学术研究,使用先进的统计方法搜索暗物质。他热衷于让人工智能在金融领域产生切实的影响,并以清晰简洁的方式传达人工智能话题。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。