我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
汤森路透如何使用 Amazon Personalize 大规模提供个性化内容订阅计划
这篇文章由汤森路透的Hesham Fahim共同撰写。
汤森路透在税收、法律和新闻活动中提供市场领先的产品,用户可以使用订阅许可模式进行注册。为了增强客户的这种体验,TR 希望创建一个集中的推荐平台,让他们的销售团队能够向客户推荐最相关的订阅套餐,生成有助于提高产品知名度的建议,从而帮助他们的客户通过量身定制的产品选择更好地服务市场。
在构建这个集中式平台之前,TR 有一个基于规则的传统引擎来生成续订建议。该引擎中的规则是预定义的,是用 SQL 编写的,这不仅给管理带来挑战,还难以应对来自 TR 各种集成数据源的数据激增的情况。TR 客户数据的变化速度快于业务规则为反映不断变化的客户需求而演变的速度。TR 基于机器学习 (ML) 的新型个性化引擎的关键要求是考虑近期客户趋势的准确推荐系统。理想的解决方案将是运营开销低、能够加速实现业务目标的解决方案,以及可以持续使用最新数据进行训练的个性化引擎,以应对不断变化的消费者习惯和新产品。
对于销售和营销团队来说,根据哪些产品对TR的客户来说是有价值的产品来提供个性化的续订建议是一项重要的业务挑战。TR 拥有大量可用于个性化的数据,这些数据是从客户互动中收集的,并存储在集中式数据仓库中。TR 是 Am
解决方案架构
解决方案的设计必须考虑到 TR 的核心操作,即通过数据了解用户;从大量数据库中为这些用户提供个性化和相关的内容是一项关键任务。拥有精心设计的推荐系统是获得根据每个用户要求定制的高质量推荐的关键。
该解决方案需要收集和准备用户行为数据,使用 Amazon Personalize 训练机器学习模型,通过经过训练的模型生成个性化推荐,并利用个性化推荐推动营销活动。
TR 希望尽可能利用 亚马逊云科技 托管服务来简化操作并减少无差别的繁重工作。TR 使用
以下部分解释了解决方案中涉及的组件。
ML 训练管道
用户与内容之间的互动以点击流数据的形式收集,该数据是在客户点击内容时生成的。TR 会分析这是他们的订阅计划的一部分还是订阅计划之外,以便他们可以提供有关价格和计划注册选项的更多详细信息。来自不同来源的用户交互数据保存在其数据仓库中。
下图说明了 ML 训练管道。
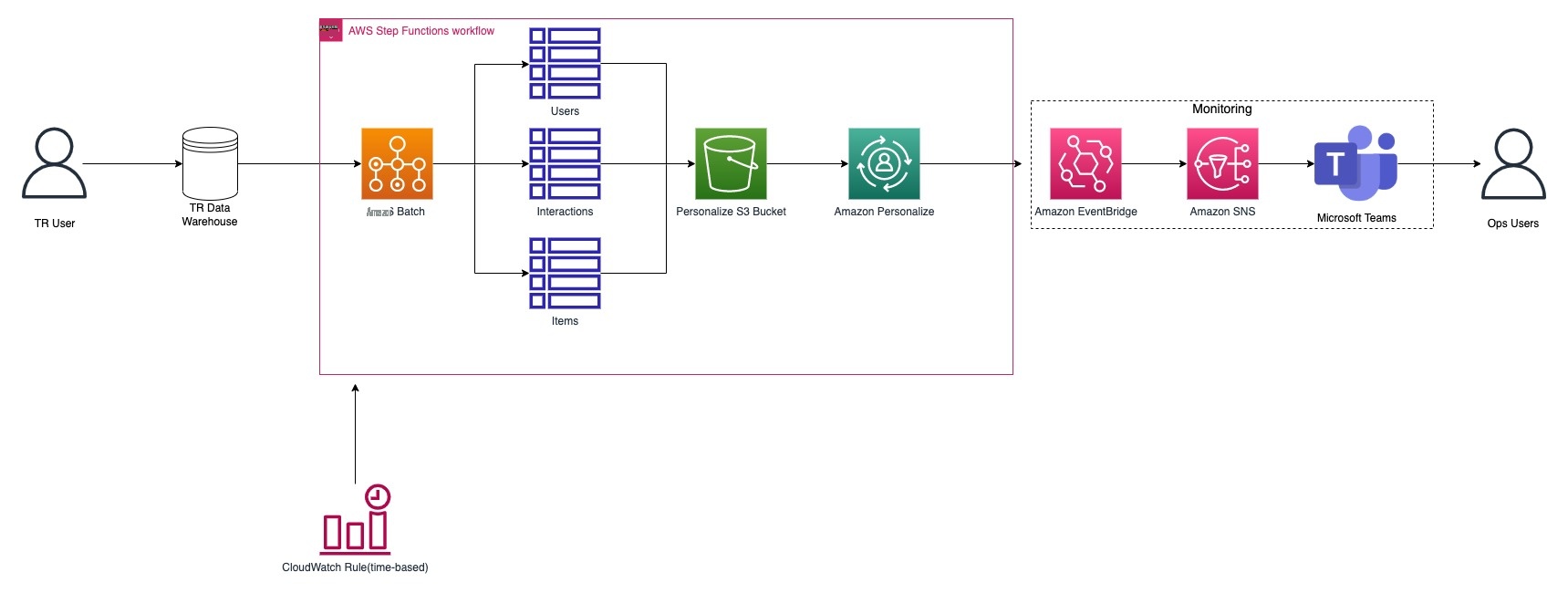
管道从一个 亚马逊云科技 Batch 任务开始,该任务从数据仓库提取数据并转换数据以创建互动、用户和项目数据集。
以下数据集用于训练模型:
- 结构化产品数据 -订阅、订单、产品目录、交易和客户详情
- 半结构化行为数据 -用户、使用情况和互动
转换后的数据存储在
整个工作流程使用
生成个性化推荐管道:批量推理
客户需求和偏好经常变化,点击流数据中捕获的最新互动是了解客户偏好变化的关键数据点。为了适应不断变化的客户偏好,TR 每天都会生成个性化推荐。
下图说明了生成个性化推荐的渠道。
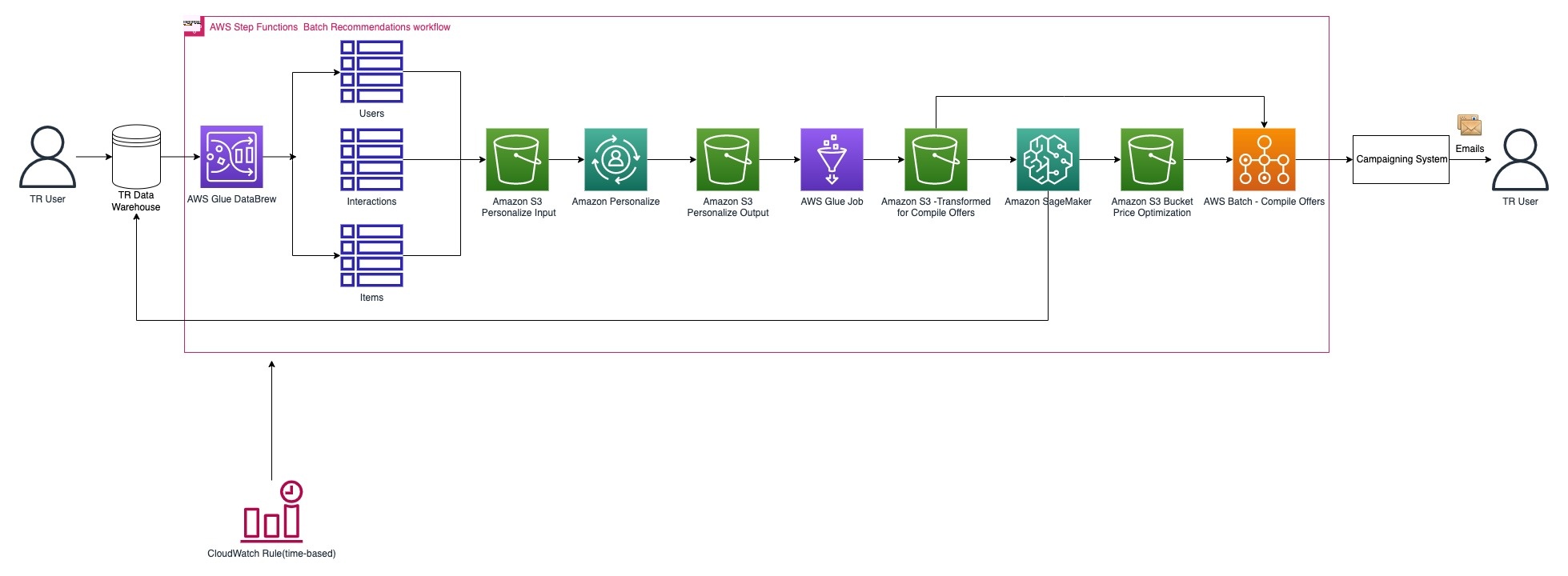
DataBrew 作业从 TR 数据仓库中提取数据,供有资格在续订期间根据当前订阅计划和近期活动提供推荐的用户使用。DataBrew 可视化数据准备工具让 TR 数据分析师和数据科学家可以轻松地清理和规范化数据,为分析和机器学习做好准备。一项重要功能是能够从可视化数据准备工具中的250多种预建转换中进行选择,以自动执行数据准备任务,而所有这些都无需编写任何代码。DataBrew 作业为批量推荐作业的交互和输入生成增量数据集,并将输出存储在 S3 存储桶中。新生成的增量数据集将导入到交互数据集中。增量数据集导入任务成功后,将使用输入数据触发 Amazon Personalize 批量推荐任务。Amazon Personalize 为输入数据中提供的用户生成最新推荐,并将其存储在推荐 S3 存储桶中。
价格优化是新形成的建议可供使用之前的最后一步。作为最后一步的一部分,TR 根据生成的建议运行成本优化作业,并使用 SageMaker 根据建议运行自定义模型。亚马逊云科技 Glue 任务负责整理 Amazon Personalize 生成的输出,并将其转换为 SageMaker 定制模型所需的输入格式。TR 能够利用 亚马逊云科技 提供的广泛服务,在推荐平台中使用 Amazon Personalize 和 SageMaker,根据客户公司和最终用户的类型量身定制推荐。
整个工作流程使用 Step Functions 进行解耦和编排,从而可以根据数据处理要求灵活地扩展流水线。警报和通知是使用亚马逊 SNS 和 EventBridge 捕获的。
推动电子邮件活动
生成的建议以及定价结果用于向TR的客户推广电子邮件活动。亚马逊云科技 Batch 任务用于为每位客户整理推荐,并使用优化的定价信息对其进行丰富。这些建议被采纳到TR的竞选系统中,这些系统推动了以下电子邮件活动:
- 使用客户可能感兴趣的新产品自动续订或升级活动
- 合同中期续订活动,提供更优惠的报价和更相关的产品和法律内容材料
此流程中的信息也会复制到客户门户,因此查看当前订阅的客户可以看到新的续订建议。自实施新的推荐平台以来,TR通过电子邮件活动获得了更高的转化率,从而增加了销售订单。
下一步是什么:实时推荐管道
客户需求和购物行为会实时变化,根据实时变化调整建议是提供正确内容的关键。在成功部署批量推荐系统之后,TR 现在计划通过实施实时推荐管道来使用 Amazon Personalize 生成推荐,将该解决方案提升到一个新的水平。
下图说明了提供实时建议的架构。
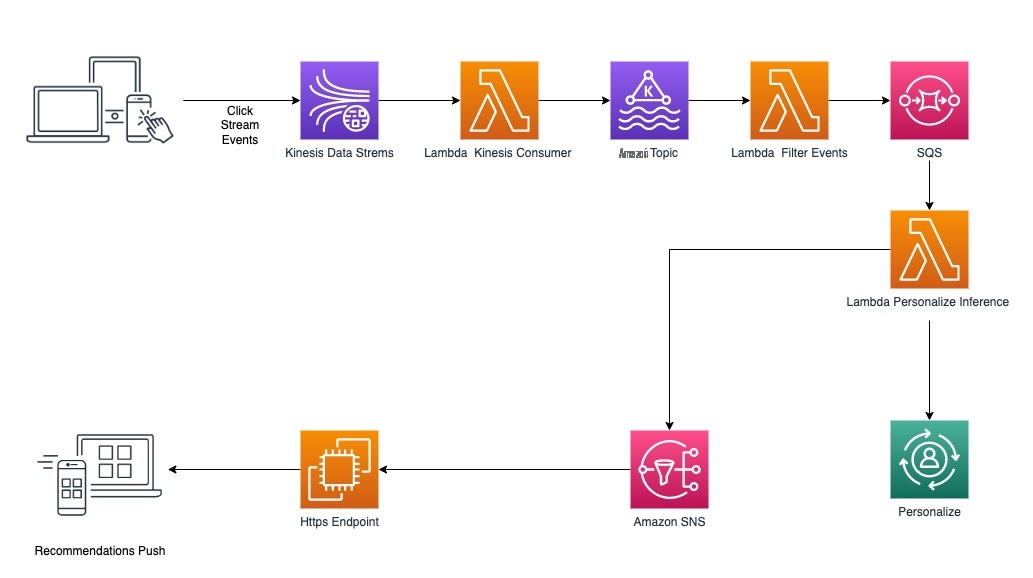
实时集成从收集实时用户参与数据开始,然后将其流式传输到Amazon Personalize。当用户与 TR 的应用程序交互时,他们会生成点击流事件,这些事件将发布到
然后,触发
这使得 Amazon Personalize 能够从您的用户的最新行为中吸取教训,并在推荐中加入相关项目。
TR 的网络应用程序调用部署在
Get
Rescommendations API 调用。Amazon Personalize 提供一组针对用户行为的最新个性化推荐,这些建议通过 Lambda 和 API Gateway 反馈给网络应用程序。
借助这种实时架构,TR 可以根据客户的最新行为向其客户提供个性化推荐,并更好地满足他们的需求。
结论
在这篇文章中,我们向您展示了 TR 如何使用 Amazon Personalize 和其他 亚马逊云科技 服务来实施推荐引擎。Amazon Personalize 使 TR 能够加快高性能模型的开发和部署,从而向客户提供建议。与几个月前相比,TR现在能够在几周内推出一套新的产品。借助Amazon Personalize和SageMaker,TR能够为客户提供更好的内容订阅计划和价格,从而提升客户体验。
如果你喜欢阅读这篇博客,想进一步了解 Amazon Personalize 以及它如何帮助你的组织建立推荐系统,请参阅
作者简介
 Hesh
am Fa
h
im 是汤森路透首席机器学习工程师和个性化引擎架构师。他曾与学术界和工业界的组织合作,从大型企业到中型初创企业。他专注于可扩展的深度学习架构,在移动机器人、生物医学图像分析和推荐系统方面拥有丰富的经验。除了计算机,他还喜欢天文摄影、阅读和长途骑行。
Hesh
am Fa
h
im 是汤森路透首席机器学习工程师和个性化引擎架构师。他曾与学术界和工业界的组织合作,从大型企业到中型初创企业。他专注于可扩展的深度学习架构,在移动机器人、生物医学图像分析和推荐系统方面拥有丰富的经验。除了计算机,他还喜欢天文摄影、阅读和长途骑行。
 Srinivasa Shaik 是位于波士顿的 A
WS 的解决方案架构师。他帮助企业客户加快云之旅。他对容器和机器学习技术充满热情。在业余时间,他喜欢与家人共度时光、烹饪和旅行。
Srinivasa Shaik 是位于波士顿的 A
WS 的解决方案架构师。他帮助企业客户加快云之旅。他对容器和机器学习技术充满热情。在业余时间,他喜欢与家人共度时光、烹饪和旅行。
 Vamshi Krishna Enabothal
a 是 亚马逊云科技 的高级应用人工智能专家架构师。他与来自不同领域的客户合作,以加快高影响力的数据、分析和机器学习计划。他热衷于人工智能和机器学习中的推荐系统、自然语言处理和计算机视觉领域。工作之余,Vamshi 是一名遥控爱好者,负责制造遥控设备(飞机、汽车和无人机),还喜欢园艺。
Vamshi Krishna Enabothal
a 是 亚马逊云科技 的高级应用人工智能专家架构师。他与来自不同领域的客户合作,以加快高影响力的数据、分析和机器学习计划。他热衷于人工智能和机器学习中的推荐系统、自然语言处理和计算机视觉领域。工作之余,Vamshi 是一名遥控爱好者,负责制造遥控设备(飞机、汽车和无人机),还喜欢园艺。
 西蒙娜·祖切特
是 亚马逊云科技 的高级解决方案架构师。Simone 拥有超过 6 年的云架构师经验,喜欢参与创新项目,这些项目有助于改变组织处理业务问题的方式。他帮助支持 亚马逊云科技 的大型企业客户,并且是机器学习 TFC 的一员。在他的职业生涯之外,他喜欢研究汽车和摄影。
西蒙娜·祖切特
是 亚马逊云科技 的高级解决方案架构师。Simone 拥有超过 6 年的云架构师经验,喜欢参与创新项目,这些项目有助于改变组织处理业务问题的方式。他帮助支持 亚马逊云科技 的大型企业客户,并且是机器学习 TFC 的一员。在他的职业生涯之外,他喜欢研究汽车和摄影。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。