我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
SafetyCulture 如何使用 Amazon Redshift 以经济实惠的方式扩展不可预测的债务云工作负载
这篇文章由SafetyCulture的数据工程师Anish Moorjani共同撰写。
在这篇文章中,我们分享了SafetyCulture用于通过Amazon Redshift以经济实惠的方式扩展不可预测的债务云工作负载的解决方案。
用例
SafetyCulture 运行 Amazon Redshift 预置的集群,以支持不可预测和可预测的工作负载。
由于计划进一步增长 dbt Cloud 工作负载,SafetyCulture 需要一个具有以下功能的解决方案:
- 以经济实惠的方式应对不可预测的工作负载
- 将不可预测的工作负载与可预测的工作负载分开,以独立扩展计算资源
- 继续允许根据生产数据创建和修改模型
解决方案概述
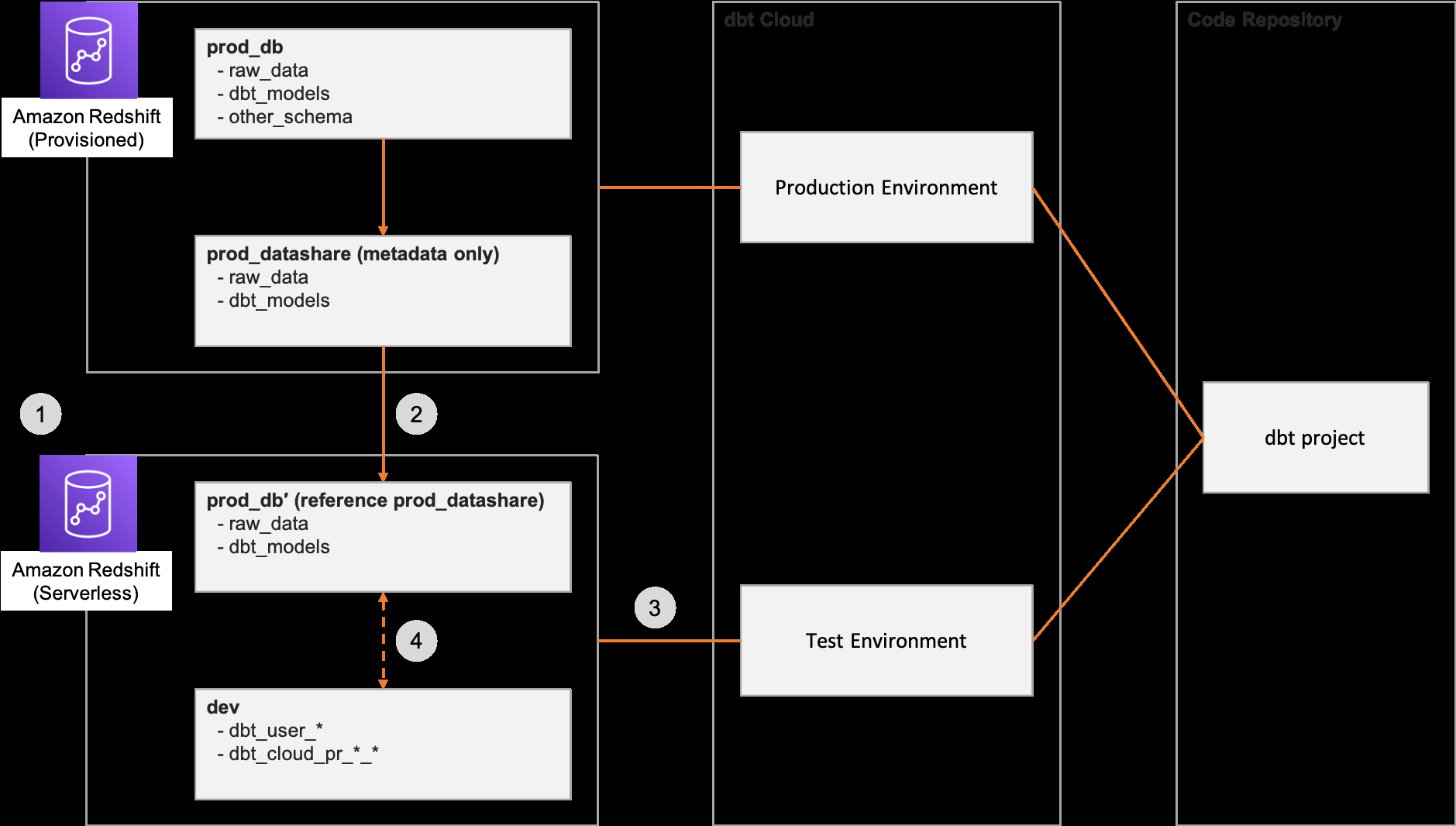
SafetyCulture 使用的解决方案包括亚马逊 Redshift Serverless 和亚马逊 Redshift 数据共享,以及现有的亚马逊 Redshift 预置集群。
下图显示了解决方案和工作流程步骤:
-
我们创建了一个无服务器实例来应对不可预测的工作负载。有关设置步骤,请参阅
使用控制台 管理 Amazon Redshift 无服务器 。 -
我们创建了一个名为
prod_datashare 的数据共享, 以允许无服务器实例访问已配置集群中的数据。有关设置步骤,请参阅使用控制台 开始数据共享 。数据库名称相同,允许使用完整路径表示法的查询database_name.schema_name.object_name 在两个数据仓库中无缝运行。 -
dbt Cloud 连接到无服务器实例和模型,无论是创建还是修改,都是在默认数据库
开发中 ,在每个用户的个人架构或拉取请求相关架构中实现的。你可以使用其他指定用于测试的数据库,而不是dev。有关设置步骤,请参阅将dbt 云 连接到 Redshi ft 。 - 您可以使用预置集群中的实例化模型在无服务器实例中查询实例化模型以验证更改。验证更改后,您可以在预配置集群的无服务器实例中实现模型。
结果
SafetyCulture 采取措施轻松创建无服务器实例和数据共享,并与 dbt Cloud 集成。SafetyCulture 还成功运行了其 dbt 项目,通过来自 dbt Cloud IDE 和 dbt Cloud CI 作业的运行命令,将所有种子、模型和快照具体化到无服务器实例中。
在性能方面,SafetyCulture观察到,在无服务器实例中,dbt Cloud工作负载的完成速度平均提高了60%。更好的性能可以归因于两个方面:
-
Amazon Redshift 无服务器使用 Redshi
ft 处理单元 (R PU) 来测量计算容量。 由于在 10 分钟内运行 64 个 RPU,在 5 分钟内运行 128 个 RPU 的成本相同,因此最好使用更多数量的 RPU 来更快地完成工作负载。 -
将 dbt Cloud 工作负载隔离在无服务器实例上后,dbt Cloud 配置了更多
线程 ,以允许同时实现更多模型。
要确定成本,您可以进行估算。128 个 RPU 提供的内存量与 ra3.4xlarge 21 节点预置集群提供的内存量大致相同。在美国东部(弗吉尼亚北部),运行具有 128 个 RPU 的无服务器实例的成本为每小时 48 美元(每 RPU 小时 0.375 美元 * 128 个 RPU)。在同一区域,按需运行 ra3.4xlarge 21 节点预配置集群的成本为每小时 68.46 美元(每个节点小时 3.26 美元 x 21 个节点)。因此,无服务器实例上累积的不可预测工作负载小时比按需预置群集高出 29% 的成本效益。在进行未来成本估算时,应重新计算此示例中的计算,因为
学习
SafetyCulture在更好地将dbt与Amazon Redshift整合方面有两个关键经验,这可能有助于类似的实现。
首先,在将 dbt 与 Amazon Redshift 数据共享集成时,
请配置
includeN ew=TRUE 以简化架构中数据库对象的管理:
例如,假设 dbt
接下来,将
将 customers.sql
模型具体化为视图 客户。
客户
添加到数据共享。
当 dbt 修改和重新实现
尽管新视图具有相同的名称,但它是一个未添加到数据共享中的新数据库对象。因此, 在数据共享中找不到
customers.sql
时,dbt 会使用临时名称创建一个新视图,删除
客户 ,并将新视图重命名给客户
。
客户
。
配置 inc
ludenew=True
允许将新的数据库对象自动添加到数据共享中。
denew=True
并提供更精细的控制外,另一种方法是使用 dbt post-hook。
其次,在将 dbt 与多个 Amazon Redshift 数据仓库集成时,
例如,假设在两个 dbt Cloud 环境中使用一个 dbt 项目来隔离生产和测试工作负载。用于生产工作负载的 dbt Cloud 环境使用默认数据库
prod_db
进行配置, 并连接到已配置的集群。用于测试工作负载的 dbt Cloud 环境使用默认的数据库
开发
配置 并连接到无服务器实例。
此外,预置的集群包含表 prod_db.raw_data.sales,该表通过名为 p
rod_db'.raw_data.s ales
的数据共享提供给无服务器实例。
当 dbt 编译包含源
如果未为源定义数据库,则 dbt 会将数据库设置为配置环境的默认数据库。
{source('raw_data','sales')}} 的模型时,
该源被评估为数据库 .raw_data.sales。
因此,连接到预置群集的 dbt 云环境将源评估为 p
rod_db .raw_data .sales,而连接到无服务器实例
的 dbt 云环境将源评估为 dev .raw_data.sales
,这是不正确的。
为源定义数据库可以让 dbt 在不同的 dbt Cloud 环境中一致地评估正确的数据库,因为它可以消除歧义。
结论
在测试了Amazon Redshift无服务器和数据共享之后,SafetyCulture对结果感到满意,并已开始生产解决方案。
SafetyCulture数据工程师团队负责人蒂亚戈·巴尔迪姆说:“PoC显示了Redshift无服务器在我们的基础设施中的巨大潜力。”“我们可以通过简单更改我们在dbt中使用的标准来迁移管道以支持Redshift Serverless。结果清楚地描绘了我们可以实现的潜在实现,将工作量完全分散在团队和用户身上,并提供适当水平的快速和可靠的计算能力。”
尽管这篇文章专门针对来自 dbt Cloud 的不可预测的工作负载,但该解决方案也适用于其他不可预测的工作负载,包括来自仪表板的临时查询。立即开始探索 Amazon Redshift 无服务器以应对不可预测的工作负载。
作者简介
 Anish Moorjani
是 SafetyCulture 数据与分析团队的数据工程师。随着数据量和种类的指数级增长,他帮助SafetyCulture的分析基础设施进行扩展。
Anish Moorjani
是 SafetyCulture 数据与分析团队的数据工程师。随着数据量和种类的指数级增长,他帮助SafetyCulture的分析基础设施进行扩展。
 Randy Chng
是亚马逊网络服务的分析解决方案架构师。他与客户合作,加速解决他们的关键业务问题。
Randy Chng
是亚马逊网络服务的分析解决方案架构师。他与客户合作,加速解决他们的关键业务问题。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。