我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
晨星如何在 亚马逊云科技 Lake Formation 中使用基于标签的访问控制来管理亚马逊 Redshift 数据仓库的权限
这篇文章由晨星的阿什什·普拉布、斯蒂芬·约翰斯顿和科林·英加菲尔德以及亚马逊云科技的唐·德雷克共同撰写。
晨星以 “赋予投资者成功” 为核心座右铭,旨在为我们的投资者和顾问提供他们做出明智的投资决策所需的工具和信息。
商业挑战
但是,我们的消费者要求我们提高查询性能和增强分析能力。我们意识到我们需要一个数据仓库来满足所有这些消费者需求,因此我们评估了 Amazon Redshift。Amazon Redshift 为我们提供了一些功能,我们可以利用这些功能与消费者合作并满足他们的分析需求:
- 性能更高,可满足消费者的分析需求
- 能够使用用户指定的排序键和分配键调整查询性能
- 能够通过视图和物化视图以不同的方式表示相同的数据
- 无论并发性如何,查询性能始终如一
许多新的亚马逊 Redshift 功能帮助解决和扩展了我们的分析查询需求,特别是亚马逊 Reds
由于我们强制组建湖的数据湖是所有数据的中央数据存储库,因此将数据权限从数据湖流入 Amazon Redshift 是有意义的。我们使用
但是,当我们迁移到 Amazon Redshift 时,我们在基于用户的权利方面遇到了问题。
应享待遇问题
尽管我们在整体解决方案中加入了 Amazon Redshift,但对于通过 Lake Formation 消费的用户来说,随之而来的权利要求和挑战保持不变。同时,我们必须想办法在 Amazon Redshift 数据仓库中实现权利,使用我们已经在 Lake Formation 中定义的相同标签集。Amazon Redshift 支持基于资源的授权,但不支持基于标签的授权。我们必须克服的挑战是如何将 Lake Formation 中基于标签的现有权利映射到 Amazon Redshift 中基于资源的权利中。
亚马逊云科技 Glue 数据目录中的数据还需要加载到亚马逊 Redshift 数据仓库的原生表中。这是必要的,这样用户才能获得熟悉的架构和表列表,在通过 Athena 进行访问时,他们习惯在数据目录中看到这些架构和表。这样,我们现有的数据湖用户可以轻松过渡到亚马逊 Redshift。
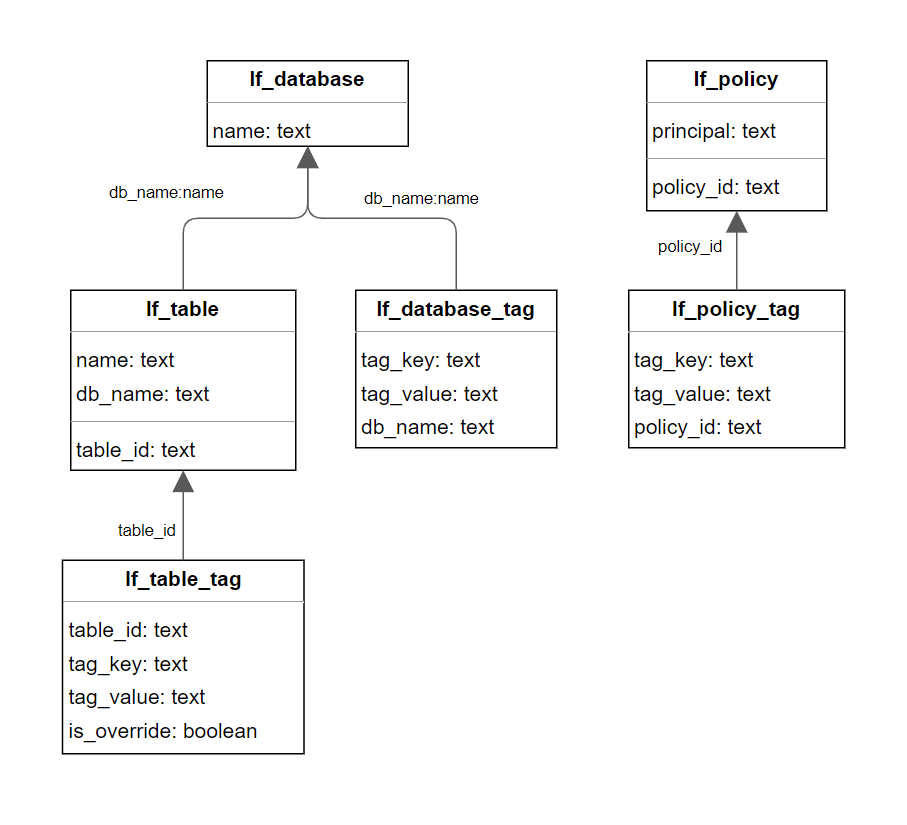
下图说明了 亚马逊云科技 Glue 数据目录的结构,与 Amazon Redshift 数据仓库的结构 1:1 映射。
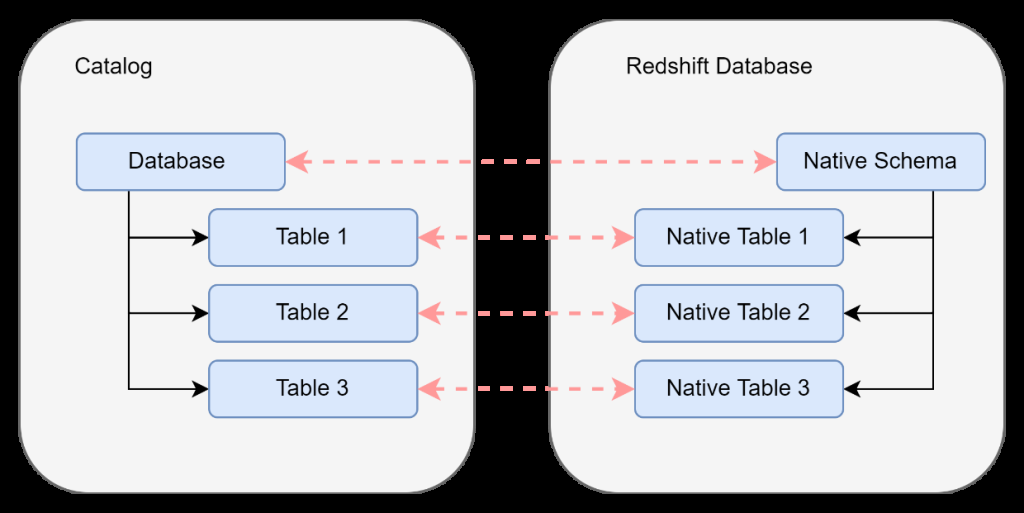
我们希望利用 Lake Formation 中的标签本体论也用于 Amazon Redshift 中的数据集,这样消费者就可以被授予在这两个地方访问相同数据集的权限。这使我们能够拥有单一的授权策略来源 API,该API可以授予对我们的 Amazon Redshift 表以及基于湖形成标签的策略的相应湖泊形成表的适当访问权限。
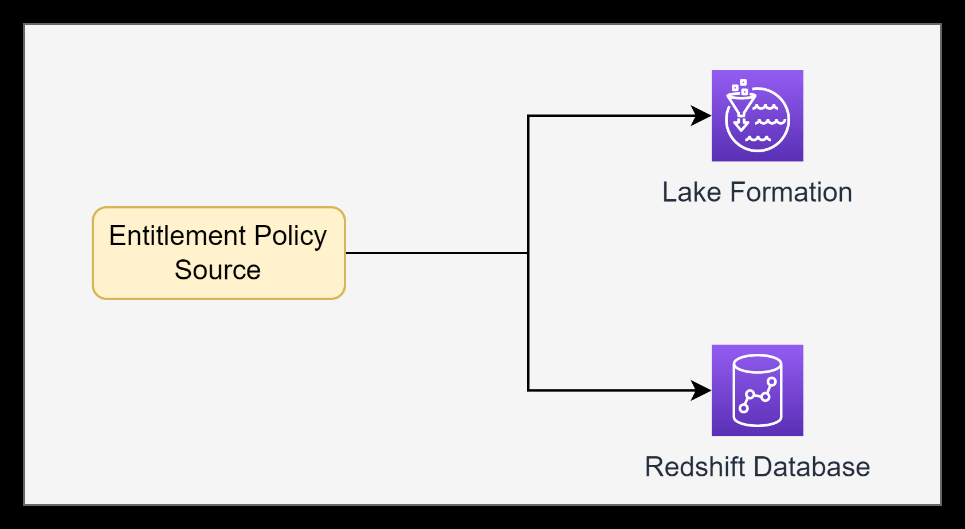
为了解决这个问题,我们需要构建自己的解决方案,将 Lake Formation 中基于标签的策略转化为 Amazon Redshift 中基于资源的权利的补助和撤销。
解决方案概述
为了解决这种不匹配问题,我们想将 Lake Formation 标签本体论和分类与 Amazon Redshift 权限模型同步。为此,我们通过以下步骤将 Lake Formation 标签和补助金映射到 Amazon Redshift 补助金:
- 将 Lake Formation 中标记为对等的 Amazon Redshift 表的所有资源(数据库、架构、表等)进行映射。
- 将 Lake Formation 中关于标签表达式的每项策略转换为一组 Amazon Redshift 表的授权和撤销。
最终结果是,当 Lake Formation 中的标签或政策发生变化时,系统会对等的 Amazon Redshift 表进行相应的授予或撤销,以保持我们的权利同步。
将 Lake Formation 中所有带标签的资源映射到 Amazon Redshift 等效资源
Lake Formation 基于标签的访问控制允许我们在 亚马逊云科技 Glue 数据目录中的单个资源(数据库和表)上应用多个标签。如果以映射表单进行可视化,则资源标签可以显示为 Amazon Redshift 表上的单个标签如何展平为单个权利。
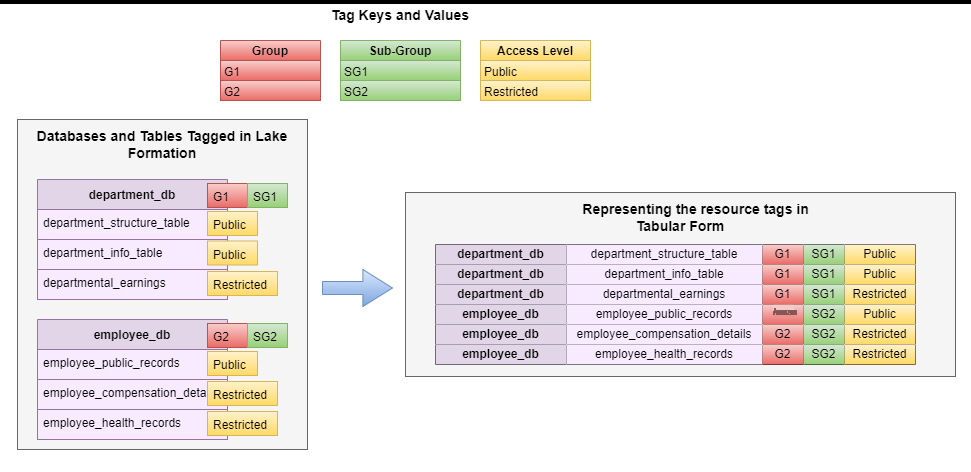
将标签翻译成亚马逊 Redshift 的补助金和撤销
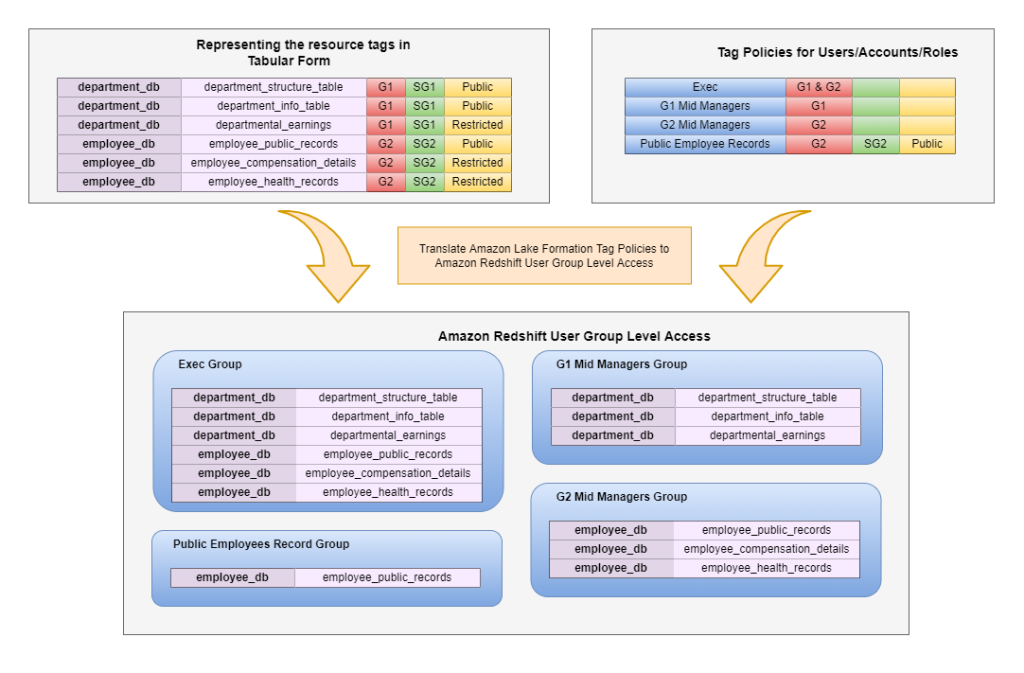
为了支持迁移在 Lake Formation 中强制执行的基于标签的策略,可以将权限转换为可以在每个组级别上完成的简单授予和撤销。
标签策略有两个基本部分:princ
ipal_id 和标签表达式(例如,“访问级别” = “公
开”)。假设每个 princip
al_id
都有一个 Amazon Redshift 数据库组 ,则可以相应地对代表标签表达式的资源进行许可。我们计划在未来的实施中从数据库组迁移到数据库角色。
解决方案的实施
该解决方案的实施促使我们开发了两个组件:
- 映射器服务
- 亚马逊 Redshift 数据配置
可以将映射器服务视为翻译服务。顾名思义,它的核心业务逻辑是在Amazon Redshift中将标签和政策信息映射到基于资源的补助金和撤销中。在处理标签策略翻译时,它需要模仿 Lake Formation 的行为。
要进行这种转换,映射者需要在两个级别上理解和存储元数据:
- 了解 Amazon Redshift 中的哪些资源要被标记为什么值
- 跟踪已经执行的补助和撤销,以便根据政策的变化对其进行更新
为此,我们在 Amazon Redshift 集群中创建了一个配置架构,该架构目前存储所有配置。
作为实施的一部分,我们将映射(翻译后的)信息存储在 Amazon Redshift 中。这使我们能够随着 Lake Formation 标签或策略的变化逐步更新表授权。下图说明了这个架构。
业务影响和价值
我们组合的解决方案在当前的实施中创造了关键的业务影响和价值,使我们能够在未来获得更大的灵活性。
它使我们能够通过应用于 Lake Formation 的标签策略更快地将数据提供给用户,并在 Amazon Redshift 中直接转换为权限,并立即生效。它还使我们能够根据标签策略产生的有效权限,在 Lake Formation 和 Amazon Redshift 中应用的权限保持一致。所有这一切都是通过单一来源进行的,该来源可以全面授予和撤消权限,而不是单独管理权限。
如果我们将其转化为我们产生的业务影响和业务价值,则该解决方案可以缩短数据的上市时间,同时为我们定义为标签的业务驱动类别提供一致的权限。
随着我们的产品在水平和垂直方向上扩展,该解决方案还开辟了解决方案,以增加更大的影响力。在自动化、用户自助权限、审计、仪表板等方面,我们可以实施一些潜在的解决方案。随着业务的扩展,我们希望利用这些能力。
结论
在这篇文章中,我们分享了晨星如何在数据湖中使用基于标签的访问控制和 Lake Formation,以及如何在 Amazon Redshift 中启用类似的控件。我们开发了两个组件,用于将基于标签的访问控制映射到 Amazon Redshift 权限。该解决方案缩短了我们数据的上市时间,并在不同的业务驱动类别中提供了一致的权限。
如果您有任何问题或意见,请将其留在评论部分。
作者简介
 Ashish Prab
hu 是晨星公司的软件工程高级经理。他专注于为晨星的企业数据和平台团队提供解决方案和提供数据湖和数据仓库的不同方面。在业余时间,他喜欢打篮球、画画和与家人共度时光。
Ashish Prab
hu 是晨星公司的软件工程高级经理。他专注于为晨星的企业数据和平台团队提供解决方案和提供数据湖和数据仓库的不同方面。在业余时间,他喜欢打篮球、画画和与家人共度时光。
 斯蒂芬·约翰斯顿
是晨星公司的杰出软件架构师。他专注于晨星企业数据平台团队的数据湖和数据仓库技术。
斯蒂芬·约翰斯顿
是晨星公司的杰出软件架构师。他专注于晨星企业数据平台团队的数据湖和数据仓库技术。
 科林·英加菲尔德
是晨星公司的首席软件工程师。总部位于奥斯汀,他专注于晨星不断增长的数据湖平台的访问控制和数据授权。
科林·英加菲尔德
是晨星公司的首席软件工程师。总部位于奥斯汀,他专注于晨星不断增长的数据湖平台的访问控制和数据授权。
 Don Drake
是 亚马逊云科技 的高级分析专家解决方案架构师。Don 总部位于芝加哥,帮助金融服务客户将工作负载迁移到 亚马逊云科技。
Don Drake
是 亚马逊云科技 的高级分析专家解决方案架构师。Don 总部位于芝加哥,帮助金融服务客户将工作负载迁移到 亚马逊云科技。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。