我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Infomedia 如何使用 亚马逊云科技 Glue 和 Apache Hudi 构建具有变更数据捕获功能的无服务器数据管道
这是一篇与 Infomedia 的 Gowtham Dandu 共同撰写的客座文章。
在这篇文章中,我们将分享
Infomedia希望构建一个基于云的数据平台,利用高度可扩展的数据存储和灵活的云原生处理工具,为其SaaS应用程序提取、转换和交付数据集。该团队希望建立一个具有横向扩展功能的无服务器架构,使他们能够优化数据管道的时间、成本和性能,并消除大部分基础设施管理。
为了向最终用户提供数据,该团队希望开发一个 API 接口来按需检索各种产品属性。数据管道和 API 端点的性能和可扩展性是关键的成功标准。数据管道需要有足够的性能,以便在需要纠正数据问题时能够快速周转。最后,API 端点性能对于最终用户体验和客户满意度非常重要。在为属性 API 设计数据处理管道时,
他们看到了在无服务器环境中使用亚马逊云科技 Glue(提供流行的开源大数据处理框架)和Apache Spark进行端到端管道开发和部署的机会。
解决方案概述
该解决方案包括以不同格式从各种第三方来源提取数据,进行处理以创建语义层,然后将处理后的数据集作为 REST API 公开给最终用户。该 API 在运行时从
为了实现这种现代数据处理解决方案,Infomedia的团队选择了包含以下步骤的分层架构:
- 原始数据来自各种第三方来源,是具有固定宽度列结构的平面文件的集合。原始输入数据以 JSON 格式(称为青铜数据集层)存储在 Amazon S3 中。
- 使用 亚马逊云科技 Glue 将原始数据转换为优化的 Parquet 格式。Parquet 数据存储在单独的 Amazon S3 位置,在 CDC 流程中用作暂存区域(称为银数据集层)。Parquet 格式可以提高查询性能并节省下游处理的成本。
- 作为增量数据处理的一部分,亚马逊云科技 Glue 从暂存区读取 Parquet 文件并更新存储在 Amazon S3(黄金数据集层)中的 Apache Hudi 表。此过程有助于在 Amazon S3 上创建可变数据集以存储版本控制和最新记录集。
-
最后,使用 亚马逊云科技 Glue 在亚马逊 Aurora PostgreSQL 兼容版本中填充最新版本的记录。该数据集用于为 API 端点提供服务。该 API 本身是一个 Spring Java 应用程序,作为 Docker 容器部署在
亚马逊弹性容器服务 (亚马逊 ECS)亚马逊云科技 Fargate 环境中。
下图说明了这种架构。
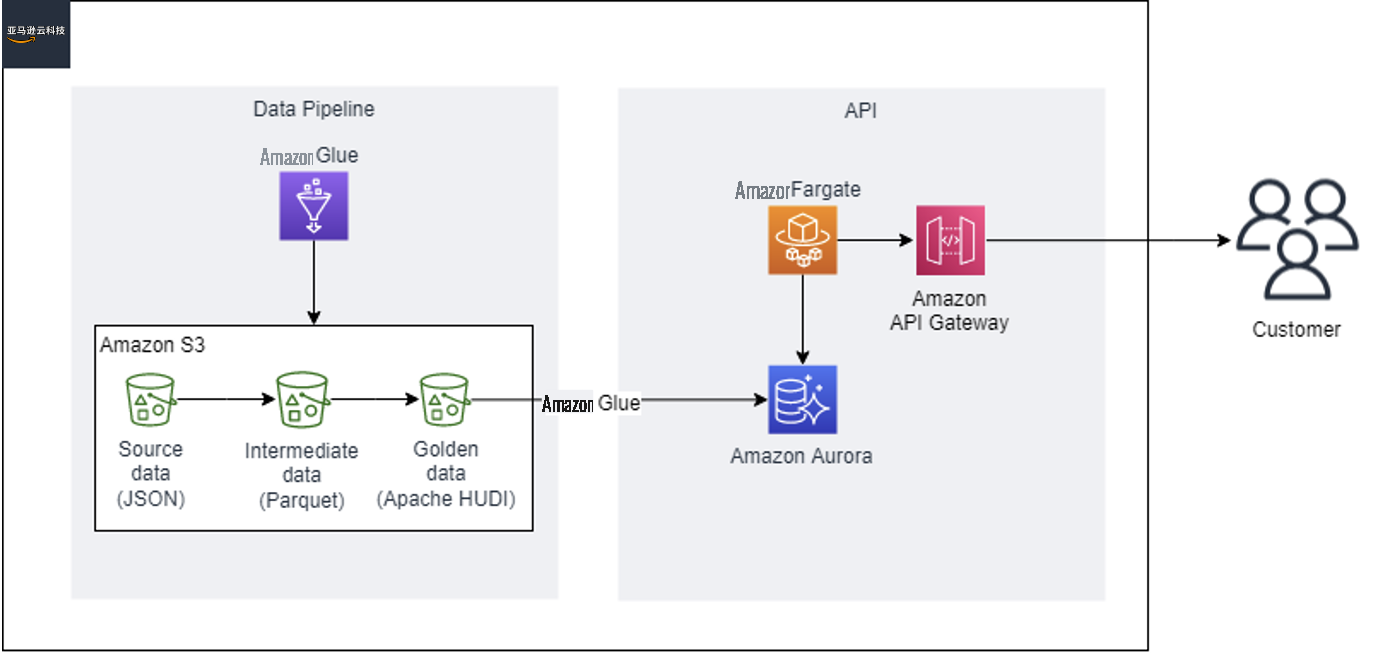
亚马逊云科技 Glue 和 Apache Hudi 概述
亚马逊云科技 Glue 是一项无服务器数据集成服务,可以轻松地大规模准备和处理来自各种数据源的数据。使用 亚马逊云科技 Glue,您可以从多个数据源提取数据、提取和推断架构、在集中式数据目录中填充元数据,以及为分析和机器学习准备和转换数据。亚马逊云科技 Glue 采用按使用量付费的模式,没有前期费用,您只需为自己消耗的资源付费。
解决方案的好处
自从Infomedia开始使用亚马逊云科技 Glue的旅程以来,Infomedia团队已经体验到了与自我管理的提取、转换和加载 (ETL) 工具相比的多项好处。通过 亚马逊云科技 Glue 的水平扩展,他们能够将数据管道工作负载的计算容量无缝扩展到 5 倍。这使他们能够增加记录量和可以处理以供下游消费的数据集的数量。他们还能够利用 亚马逊云科技 Glue 的内置优化,例如使用下推谓词进行预过滤,这使团队能够节省宝贵的工程时间,调整数据处理任务的性能。
此外,基于 Apache Spark 的 亚马逊云科技 Glue 使开发人员能够使用简洁的 Spark SQL 和数据集 API 来编写作业。这使已经熟悉数据库编程的开发人员能够快速提高技能。由于开发人员正在使用整个数据集的更高级别的结构,因此他们花在解决低级技术实现细节上的时间更少。
此外,与运行自我管理的 Apache Spark 基础设施相比,亚马逊云科技 Glue 平台具有成本效益。该团队进行了初步分析,结果显示,与为其工作负载运行专用 Spark EC2 基础设施相比,估计可以节省 70% 的费用。此外,亚马逊云科技 Glue Studio 任务监控控制面板为 Infomedia 团队提供了详细的作业级别可见性,可以轻松获取任务运行摘要并了解数据处理成本。
结论和后续步骤
Infomedia将继续使用亚马逊云科技 Glue平台和其他亚马逊云科技分析服务对其复杂的数据管道进行现代化改造。通过与诸如
如果您想了解更多信息,请访问
作者简介
 Gowtham Dandu
是Infomedia Ltd的工程主管,他热衷于在云端构建高效有效的解决方案,尤其是涉及数据、API和现代SaaS应用程序的解决方案。他擅长构建具有成本效益和高度可扩展性的微服务和数据平台。
Gowtham Dandu
是Infomedia Ltd的工程主管,他热衷于在云端构建高效有效的解决方案,尤其是涉及数据、API和现代SaaS应用程序的解决方案。他擅长构建具有成本效益和高度可扩展性的微服务和数据平台。
 Praveen Kumar
是 亚马逊云科技 的专业解决方案架构师,在使用云原生服务设计、构建和实施现代数据和分析平台方面拥有专业知识。他感兴趣的领域是无服务器技术、流媒体应用程序和现代云数据仓库。
Praveen Kumar
是 亚马逊云科技 的专业解决方案架构师,在使用云原生服务设计、构建和实施现代数据和分析平台方面拥有专业知识。他感兴趣的领域是无服务器技术、流媒体应用程序和现代云数据仓库。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。