我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
环球电信如何大规模使用 亚马逊云科技 DataSync 迁移 7.2 PB 的 Hadoop 数据
数据迁移是组织在云之旅中至关重要的第一步。它通常需要提升和转移关键业务应用程序、数据库、数据分析工作负载、数据仓库、大数据和经过训练的人工智能/机器学习 (AI/ML) 模型。数据生成并存储在不同的层中,导致迁移过程变得复杂。由于这种复杂性,必须精心设计数据摄取和迁移流程,并采用简化的方法,以确保数据传输的持续流动。
在这篇文章中,我们将带您了解环球电信的数据迁移之旅,包括将Cloudera数据迁移到
环球电信的技术要求
Globe Telecom 需要在 Amazon S3 上构建和管理作为原始数据湖的集中式数据存储库。当数据进入Amazon S3时,需要对其进行预处理并与分析引擎共享才能获得数据见解。商业用户稍后将利用商业智能 (BI) 工具来可视化数据并帮助做出数据驱动的业务决策。
环球电信的数据迁移要求:
- Cloudera 是 HDFS 的来源
- 从没有暂存区的 HDFS 存储节点迁移数据
-
使用 亚马逊云科技 Direct Connect 进行在线数据迁移,可用网络带宽为 10Gb/s - 数据大小为 7.2 PB,包括历史数据和新的传入数据
- 文件总数大于 10 亿
- 历史数据和新数据集的增量同步
- 将迁移基础设施的本地占用空间降至最低
- 自动化、监控、报告和脚本编写支持
评估解决方案
最初,我们研究了一款供应商产品,该产品可以执行历史数据迁移、随后传输新采集的数据,以及从源 Cloudera 系统执行打开文件同步的能力。整体功能集引人注目,符合我们的主要要求。但是,由于许可成本高、基础设施要求高,以及大规模实施时的复杂性,我们决定不继续进行。此外,很难访问该软件来进行概念验证测试。
我们评估了将 HDFS 数据迁移到亚马逊 S3 的其他解决方案,包括
在概念验证期间,我们列出了以下提到的成功标准,并对每种工具进行了一系列测试。这是一场激烈的竞赛,我们考虑了以下因素:
- 敏捷性
- 可靠性
- 功能
- 可用性和可扩展性
- 安全
- 支持和经得起未来考验
- 成本
在这些领域中,差异化领域是成本、可用性和可扩展性。我们最终选择了DataSync,这是基于这些因素以及影响我们决策的以下其他原因。
- 易于设置和部署
-
支持
亚马逊云科技 命令行接口 (亚马逊云科技 CLI) 和脚本 - 源和目标之间的增量数据传输
- 用于监控的单一仪表板
- 基于任务,具有扩展能力
-
亚马逊弹性计算云 (亚马逊 EC2)上的数据同步代理 - 简单的定价模型
解决方案概述
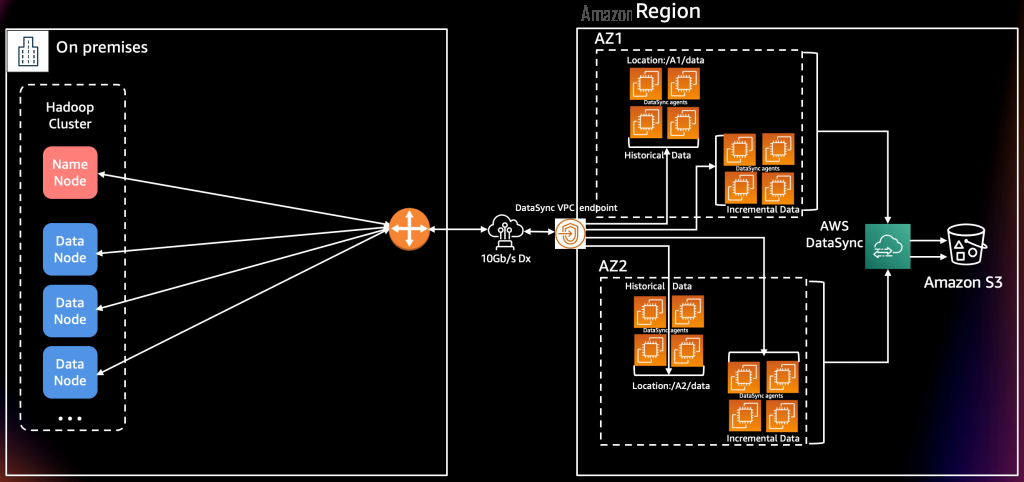
我们构建了一个独特的解决方案架构,用于使用 DataSync 迁移 7.2PB 的 Cloudera 数据。亚马逊云科技 团队建议您在尽可能靠近存储系统的地方运行 DataSync 代理,以实现低延迟访问和提高性能。但是,在我们的设置中,我们采用了将所有 DataSync 代理安装为 EC2 实例的方法,并且使用了性能稳定的高带宽网络。
我们在每个
增强抵御能力
我们通过在可用区 (AZ) 之间分配 EC2 实例,为 HDFS 数据迁移构建了一个弹性架构,并根据带有 “包含过滤器” 的任务对代理进行分组。我们没有遇到任何延迟或性能问题,因为我们的环境有可用的 10-Gbps 网络管道和提供稳定读取吞吐量的源存储系统。仔细规划每个代理的任务分配并使用过滤器帮助我们优化了数据采集。
在每个可用区中运行的任务使用为每个源 HDFS 位置配置的三个 DataSync 代理。为了防范不可预见的事件,又部署并启动了两名备用代理。虽然 DataSync 任务不提供代理之间的自动故障转移,但备用代理可用作随时可用的替代品。
为规模而设计
亚马逊云科技 DataSync 代理是使用
|
源系统 |
网络带宽 |
网络吞吐量 |
阅读 IOPS |
|
Cloudera CDH 5.13.3、370 Datanodes、2 Namenodes |
10 Gb/s |
800 Mb/s |
27K |
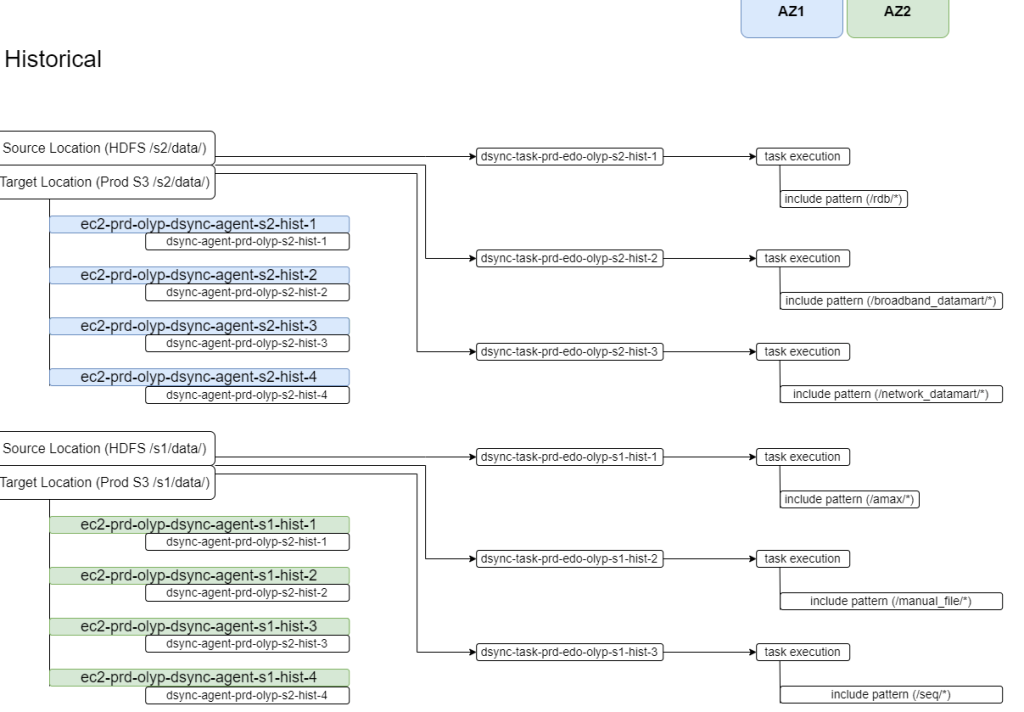
在以下来源 Cloudera 位置中,我们在每项任务中都包含有要处理的特定代理的文件夹。使用这种方法,我们使用跨可用区的 9 到 12 个代理处理了 6 到 9 个任务。
| Data Type | Source directory location | Destination location on Amazon S3 |
| Historical data | HDFS /S2/data/ | Prod S3 /s2/data |
我们并行运行任务,实现了每天高达 72 TB 的数据迁移率,网络利用率为 85%。这接近 800MB/s 或 2.2 TB/h。
DataSync 代理作为 M5.4Xlarge
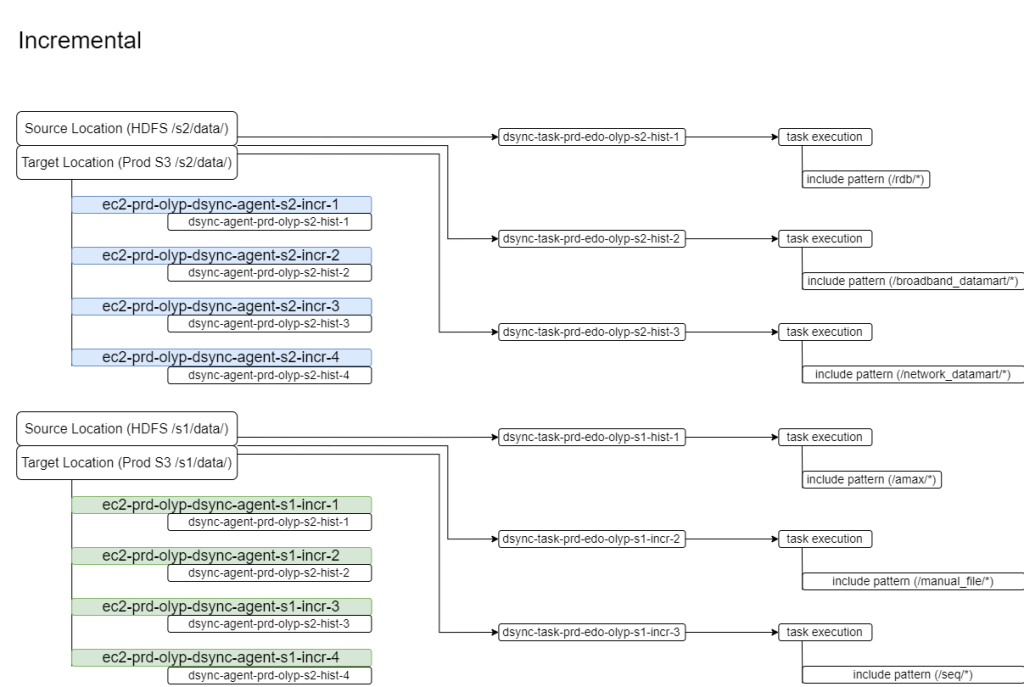
此外,我们使用源位置和任务筛选器的相同组合运行任务以迁移增量文件更新。
结论
环球电信的EDO数据迁移项目在规定的四个月的项目时间内成功完成。DataSync 提供了敏捷性、灵活性和安全性,可以构建横向扩展架构,从而实现高性能和更快的数据安全移动。内置的自动化、监控、单一仪表板视图和任务完成报告帮助我们的团队成员专注于数据迁移策略,降低了数据传输成本,并在迁移阶段高枕无忧。DataSync 的数据完整性和验证检查使我们对迁移后的数据充满信心。我们很快启动了分析数据管道,以便在更短的周转时间内为最终用户进行进一步处理和数据可视化。DataSync 简化了我们向 亚马逊云科技 云迁移的 HDFS 数据迁移之旅。
感谢您阅读这篇文章。如果您有任何意见或问题,请随时将其留在评论部分。要了解更多信息,请观看我们的 亚马逊云科技 DataS ync
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。