我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Getir 如何使用亚马逊 Neptune 和亚马逊 DynamoDB 构建全面的欺诈检测系统
这是一篇来自 Getir 的 Berkay Berkman、Yaqüz Yanikoglu、Mutlu Polatcan、Mahmut Turan、Umut Cemal Kiraq 共同撰写的客座文章。
在这篇文章中,我们解释了 Getir 如何建立端到端的欺诈检测系统,从收集实时数据到使用
Neptune 是专为云构建的完全托管的数据库服务,可轻松构建和运行图形应用程序。Neptune 提供内置安全性、持续备份、无服务器计算以及与其他 亚马逊云科技 服务的集成。
DynamoDB 是一项适用于任何规模的快速灵活的非关系数据库服务。DynamoDB 使您能够将运行和扩展分布式数据库的管理负担转移到 亚马逊云科技,这样您就不必担心硬件预置、设置和配置、吞吐量容量规划、复制、软件补丁或集群扩展。
解决方案概述
在这个项目中,来自数据和业务团队的五个人一起工作:三人来自数据团队,两人来自业务审计团队。该项目本身在3个月内就完成了,但是数据分析(检测互联客户,确定规则集)又花了3个月的时间。
下图显示了解决方案的架构。
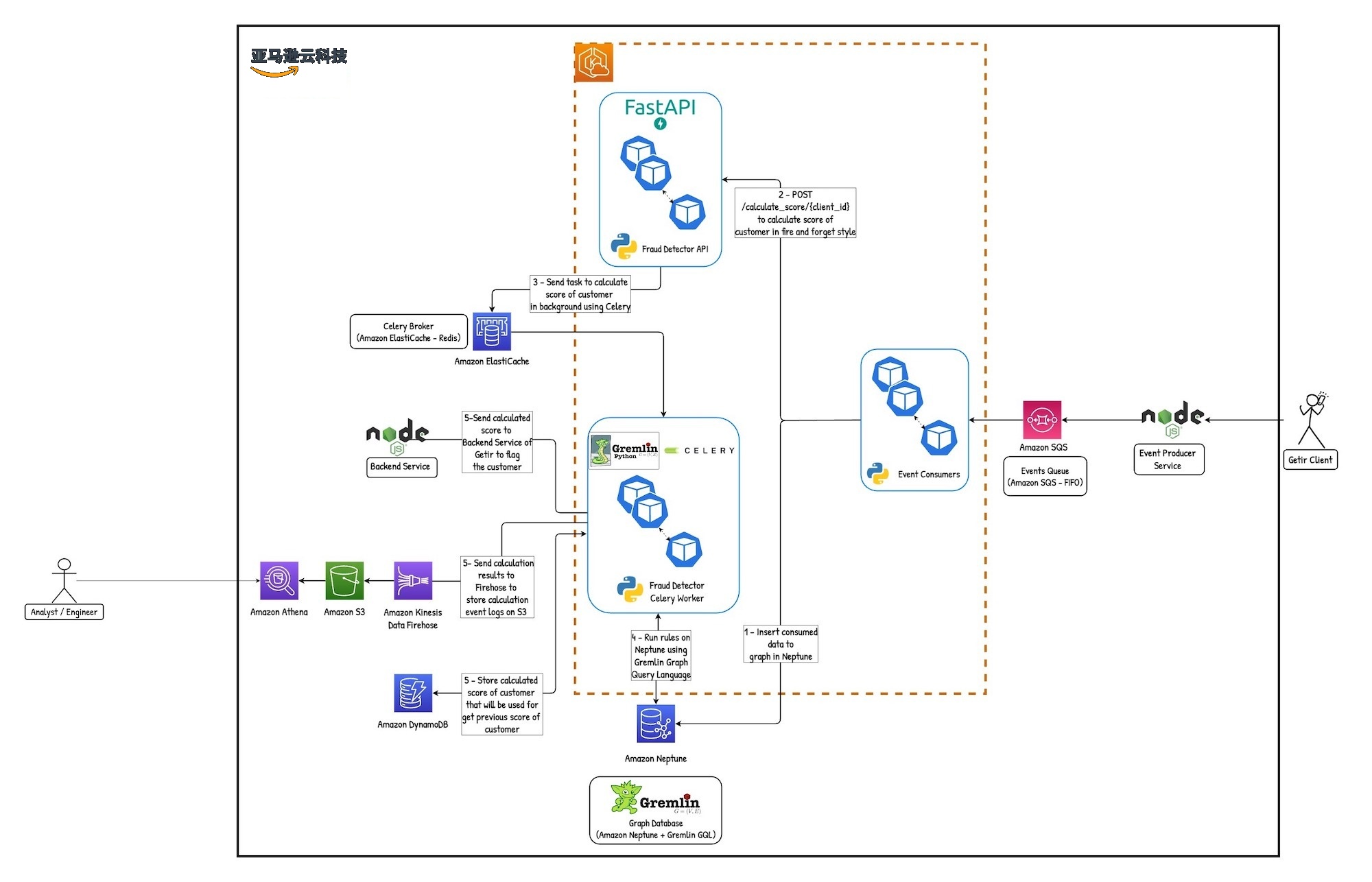
解决方案详情
我们需要从 Getir 客户那里获取实时数据。为此,我们需要一项能够为我们提供实时数据的服务,并确保这些数据以完全托管的方式到达我们手中。我们之所以选择
我们在
当用户使用新信息或新属性登录时,消费者会在毫秒内将这些新信息或属性详细信息写入海王星,并立即将其发送到数据图表树。
使用 Amazon Neptune 的一大优势是能够使用 海王
借助 Neptune Notebook,我们可以使用 Jupyter 笔记本来编写代码和创建可视化效果,使我们能够与图表数据进行实时交互。这在尝试识别实体之间的模式和关系时特别有用,因为它使我们能够从多个角度探索数据并更深入地了解底层结构。除了交互式可视化功能外,Neptune Notebook 还提供了一系列其他功能,使其成为数据分析的理想工具。例如,它提供了一系列预建模板和示例代码片段,可用于快速启动和运行我们的分析。
将实时数据插入数据库后,我们将其发送到计算器 API。实际分数计算是在计算器部分完成的。欺诈圈节点之间的连接可能非常大,计算可能需要很长时间,API 会将这些计算结果发送给 Celery 工作人员,即任务队列。Celery 工作人员需要键值存储器来检索任务。我们使用
这些分配的用户分数存储在
我们使用
结论
Neptune 使我们能够在团队中轻松高效地使用图形数据库,并提高了我们在处理实时数据方面的能力。DynamoDB 是我们尝试的第一项服务,它运行良好。在数据建模部分,使用 DynamoDB 作为键值数据存储可防止 Neptune 日复一日地减速。我们能够优化海王星的扩展,节省大量成本,减少开支。具体而言,我们通过优化工作节省了以前的大部分成本。在高流量中使用 DynamoDB 已经向我们证明了它的力量,由于其低成本和易于使用,它已成为我们在更多项目中的首选服务。
我们的多层方法结合了数据分析、用户验证、欺诈评分和机器学习。通过结合使用这些技术,我们可以更好地保护自己和客户免受95%的欺诈活动侵害,同时还节省了营销成本。
有关如何开始使用海王星构建自己的欺诈检测系统的更多信息,可以在亚马逊海王星
要获得更多有关 DynamoDB 的资源,您可以在 Amazon Dynamo
作者简介
 B
erkay Berkman
拥有计算机工程学士学位,拥有数据科学和工程方面的经验。他曾在Getir的数据平台和工程团队担任高级数据工程师。Berkay 喜欢研究数据问题并使用云原生平台创建解决方案。
B
erkay Berkman
拥有计算机工程学士学位,拥有数据科学和工程方面的经验。他曾在Getir的数据平台和工程团队担任高级数据工程师。Berkay 喜欢研究数据问题并使用云原生平台创建解决方案。
 Yaz Yaníkolu 在软件开发生命
周期方面拥有超过 13 年的经验。他的职业生涯始于后端开发人员,并于 2015 年与 亚马逊云科技 会面。从那时起,他的主要目标是创建安全、可扩展、容错和成本优化的云解决方案。他于2020年加入超快杂货配送领域的先驱Getir,目前担任高级数据工程和平台经理。他的团队负责为Getir设计、实施和维护端到端数据平台解决方案。
Yaz Yaníkolu 在软件开发生命
周期方面拥有超过 13 年的经验。他的职业生涯始于后端开发人员,并于 2015 年与 亚马逊云科技 会面。从那时起,他的主要目标是创建安全、可扩展、容错和成本优化的云解决方案。他于2020年加入超快杂货配送领域的先驱Getir,目前担任高级数据工程和平台经理。他的团队负责为Getir设计、实施和维护端到端数据平台解决方案。
 Mutlu Polatc
an 是 Getir 的高级数据工程师,专门设计和构建云原生数据平台。他喜欢将开源项目与云服务相结合。
Mutlu Polatc
an 是 Getir 的高级数据工程师,专门设计和构建云原生数据平台。他喜欢将开源项目与云服务相结合。
 Mahmut Turan
,经济学学士学位和法学学士学位,曾担任过各种技术和商业职务,在金融服务行业,包括监管和监管方面、q-commerce 和技术方面,也有丰富的经验。他在Getir工作了2年多,担任过各种职务:内部审计经理(数据和分析)、审计分析和防欺诈经理以及欺诈分析和损失预防主管。他的专长是内部审计、审计分析、数据科学、信用风险和欺诈风险。
Mahmut Turan
,经济学学士学位和法学学士学位,曾担任过各种技术和商业职务,在金融服务行业,包括监管和监管方面、q-commerce 和技术方面,也有丰富的经验。他在Getir工作了2年多,担任过各种职务:内部审计经理(数据和分析)、审计分析和防欺诈经理以及欺诈分析和损失预防主管。他的专长是内部审计、审计分析、数据科学、信用风险和欺诈风险。
 Umut Cemal Kiraq
是 Getir 的欺诈分析与预防经理。他负责管理全公司的欺诈风险以及Getir的审计分析职能。他还被指定为CIA(注册内部审计师)和CISA(注册信息系统审计师)认证。他的专业领域是提供商业风险分析解决方案。
Umut Cemal Kiraq
是 Getir 的欺诈分析与预防经理。他负责管理全公司的欺诈风险以及Getir的审计分析职能。他还被指定为CIA(注册内部审计师)和CISA(注册信息系统审计师)认证。他的专业领域是提供商业风险分析解决方案。
 Esra Kayabal
i 是 亚马逊云科技 的高级解决方案架构师,专门研究分析领域,包括数据仓库、数据湖、大数据分析、批处理和实时数据流以及数据集成。她拥有 12 年的软件开发和架构经验。她热衷于学习和教授云技术。
Esra Kayabal
i 是 亚马逊云科技 的高级解决方案架构师,专门研究分析领域,包括数据仓库、数据湖、大数据分析、批处理和实时数据流以及数据集成。她拥有 12 年的软件开发和架构经验。她热衷于学习和教授云技术。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。