这是一篇与来自Games24x7的侯赛因·贾吉尔达尔共同撰写的客座博客文章。
Games24x7
是印度最有价值的多游戏平台之一,在各种技巧游戏中为超过1亿玩家提供娱乐。他们以 “游戏科学” 为核心理念,通过整合游戏人工智能、游戏数据科学和游戏用户研究的正交研究方向,实现了围绕游戏动态、游戏平台和玩家的端到端信息学愿景。人工智能和数据科学团队深入研究了大量的多维数据,并在 亚马逊云科技 上运行各种用例,例如玩家旅程优化、游戏动作检测、超个性化、客户 360 等。
Games24x7采用自动化、数据驱动、人工智能驱动的框架,通过平台上的互动来评估每个玩家的行为,并标记有异常行为的用户。他们建立了深度学习模型ScarceGan,该模型侧重于从带有小标签和薄弱标签的多维纵向遥测数据中识别极其稀有或稀缺的样本。该工作已发表在
CIKM'21
上,是
开源的 ,可以对任何纵向遥测数据
进行稀有类别识别。为了在平台上实现负责任的游戏玩法,可以引导被举报的用户经历不同的审核和控制之旅,因此制作和采用该模型是至关重要的。
在这篇文章中,我们将分享Games24x7如何使用Amazon SageMaker改善负责任游戏平台的训练管道。
客户面临的挑战
Games24x7的DS/AI团队使用了亚马逊云科技提供的多种服务,包括SageMaker笔记本、亚马逊云科技
Step Fun ctions、 AW S
Lambda
和Amazon EMR
,
为各种用例构建管道。 为了应对数据分布的偏差,从而重新训练他们的 ScarceGan 模型,他们发现现有系统需要更好的 mLops 解决方案。
在之前通过 Step Functions 的管道中,单个单体代码库运行了数据预处理、再训练和评估。这成为故障排除、添加或删除步骤,甚至对整个基础架构进行一些细微更改的瓶颈。此步骤函数实例化了一个实例集群以提取和处理来自 S3 的数据,而预处理、训练、评估的后续步骤将在单个大型 EC2 实例上运行。在管道在任何步骤都出现故障的情况下,整个工作流程都需要从头重新启动,这会导致重复运行并增加成本。所有培训和评估指标均由亚马逊 Simple Storage Service(Amazon S3)手动检查。没有机制可以传递和存储在模型上进行的多次实验的元数据。由于分散的模型监控,数据科学团队需要花费数小时才能进行彻底的调查和精心挑选最佳模型。所有这些努力的积累导致团队生产力下降和开销增加。此外,在快速成长的团队中,在整个团队中分享这些知识非常具有挑战性。
由于 mLOP 的概念非常广泛,实施所有步骤都需要时间,因此我们决定在第一阶段将解决以下核心问题:
-
一个安全、可控和模板化的环境,可使用行业最佳实践重新训练我们的内部深度学习模型
-
参数化训练环境,用于为每个再训练作业发送一组不同的参数并对最后一次运行进行审计
-
能够直观地跟踪训练指标和评估指标,并拥有用于跟踪和比较实验的元数据
-
能够单独扩展每个步骤,并在出现步骤失败时重复使用先前的步骤
-
用于注册模型、存储特征和调用推理管道的单一专用环境
-
一款现代工具集,通过整合在不同步骤中使用不同实例的灵活性,可以最大限度地减少计算需求、降低成本并推动可持续的机器学习开发和运营
-
创建最先进的 mLOPs 流水线的基准模板,可供各种数据科学团队使用
Games24x7 开始评估其他解决方案,包括亚马逊 Sage Maker Studio Pipelines。
通过 Step Functions 实现的现有解决方案存在局限性。Studio 流水线可以灵活地在任何时间点添加或删除步骤。此外,还可以通过 DAG 对整体架构及其每个步骤之间的数据依赖关系进行可视化。在我们采用了不同的亚马逊 SageMaker 功能(例如亚马逊 SageMaker Studio、Pipelines、处理、训练、模型注册以及实验和试验)之后,对再训练步骤的评估和微调变得相当高效。亚马逊云科技 解决方案架构团队表现出色,并在该解决方案的设计和实施中发挥了重要作用。
解决方案概述
下图说明了解决方案架构。
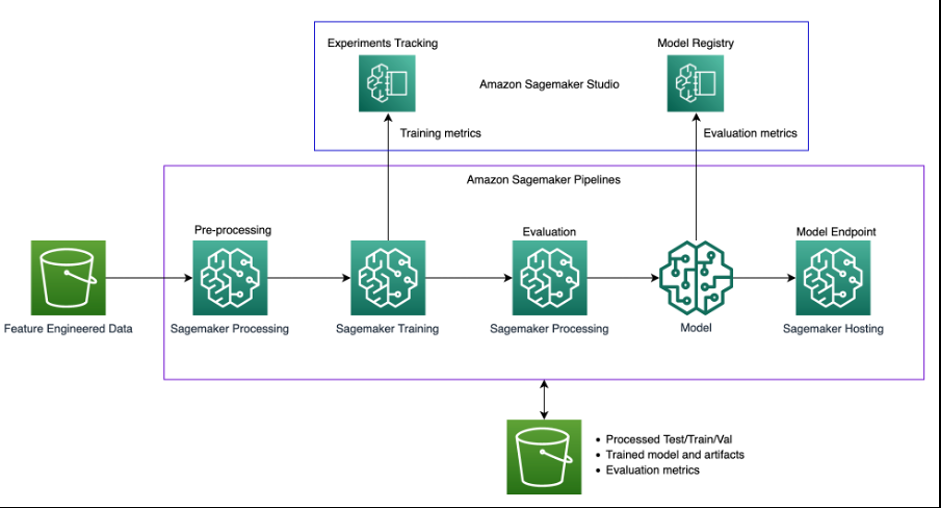
该解决方案使用
SageMaker Studio
环境来运行再训练实验。调用流水线脚本的代码在 Studio 笔记本中可用,我们可以在调用管道时更改超参数和输入/输出。这与我们之前的方法完全不同,在之前的方法中,我们将所有参数硬编码在脚本中,并且所有进程都密不可分。这需要将单芯片代码模块化为不同的步骤。
下图说明了我们最初的单片工艺。
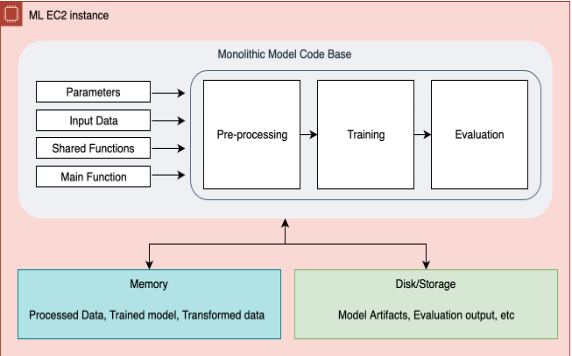
模块化
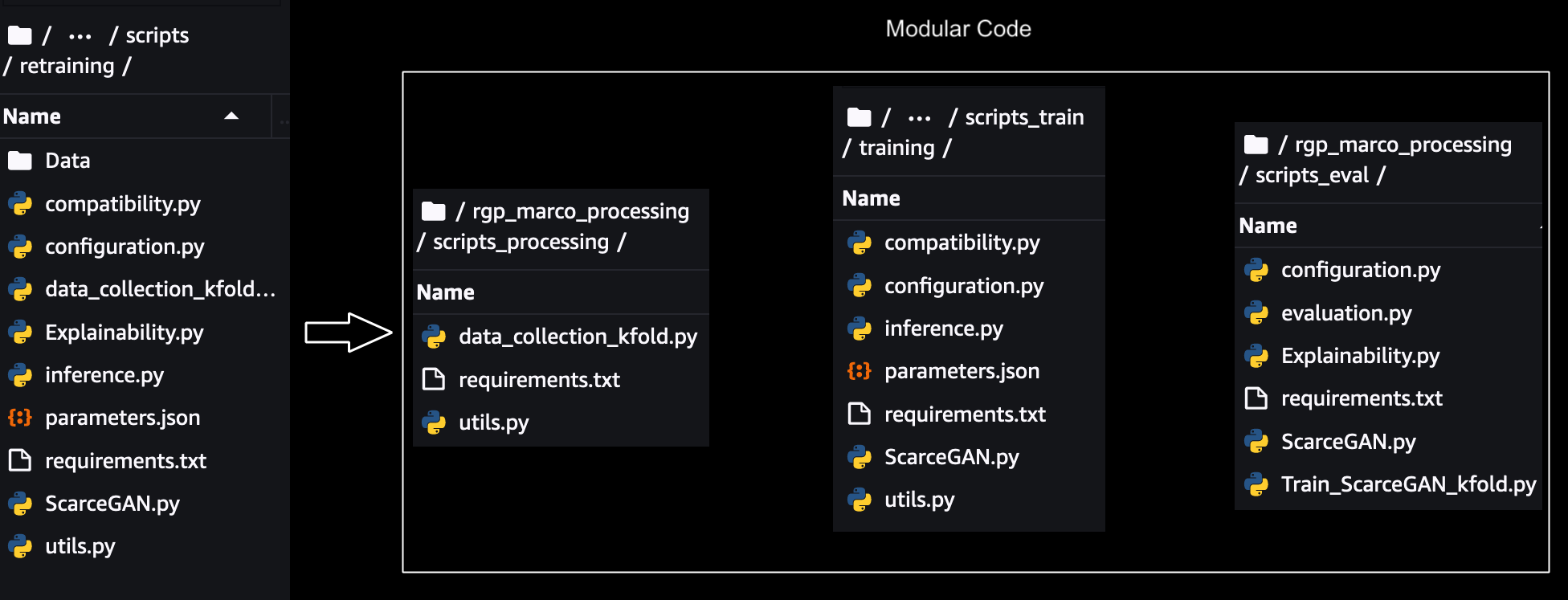
为了单独扩展、跟踪和运行每个步骤,需要对单片代码进行模块化。删除了每个步骤之间的参数、数据和代码依赖关系,并为跨步骤的共享组件创建了共享模块。模块化示意图如下所示:-
对于每个模块,测试都是使用 SageMaker SDK 的
脚本模式
在本地完成的, 用于训练、处理和评估,这
需要对代码进行细微更改
才能使用 SageMaker 运行。深度学习脚本 的
本地模式测试
可以在 SageMaker 笔记本电脑上完成(如果已经在使用 Pip
elines),也可以直接从流水线启动时使用 SageMaker Pipel ines 使用 本地模式
进行。这有助于验证我们的自定义脚本是否可以在 SageMaker 实例上运行。
然后,使用 SageMaker 训练/处理 SDK 使用
脚本模式
对每个模块进行隔离测试, 并使用 SageMaker 实例按顺序手动运行每个步骤,如下面的训练步骤:
estimator = TensorFlow(
entry_point="inference.py",
source_dir="scripts_train/training/",
instance_type="ml.c5.2xlarge", # Running on SageMaker ML instances
instance_count=1,
hyperparameters=hyperparameters,
role=sagemaker.get_execution_role(), # Passes to the container the AWS role that you are using on this notebook
framework_version="2.11",
py_version="py39",
)
estimator.fit(inputs)
2022-09-28 11:10:34 Starting - Starting the training job...
Amazon S3 用于处理源数据,然后将中间数据、数据帧和 NumPy 结果存储回 Amazon S3 以供下一步使用。在预处理、训练、评估的各个模块之间的集成测试完成后,与我们在上述步骤中已经使用
的 SageMaker Python SDK 集成的 SageMaker Pipelin
e SDK 允许我们通过将每个步骤的输入参数、数据、元数据和输出作为输入传递给后续步骤,以编程方式链接所有这些模块。
我们可以重复使用之前的 Sagemaker Python SDK 代码,将这些模块单独运行到基于 Sagemaker Pipeline SDK 的运行中。管道每个步骤之间的关系由步骤之间的数据依赖关系决定。
管道的最后步骤如下:
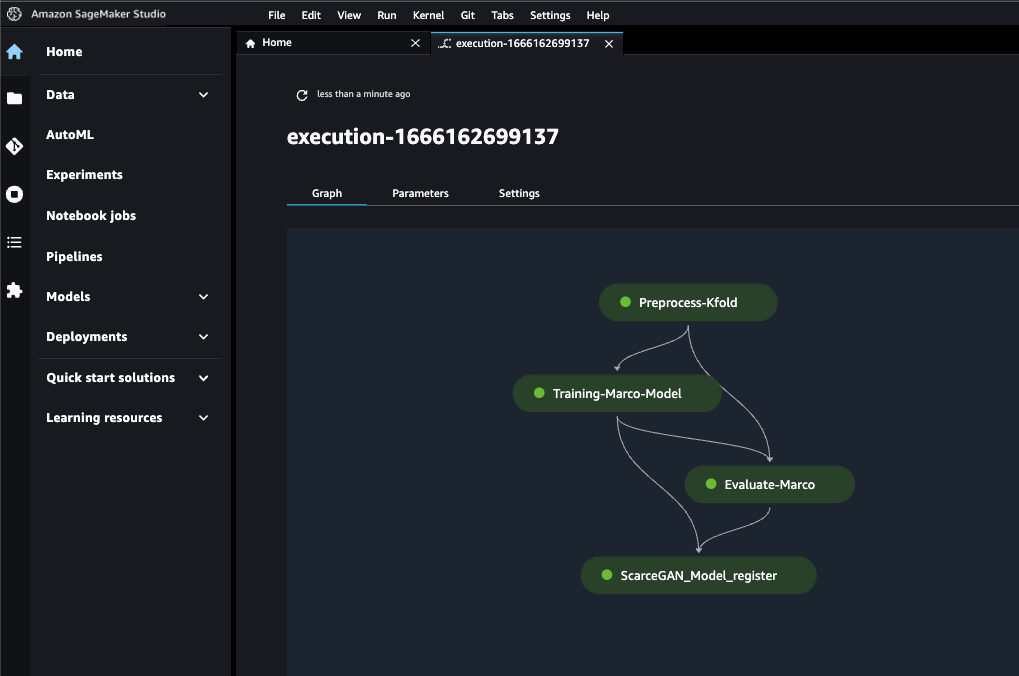
在以下部分中,我们将更详细地讨论使用 SageMaker Pipeline SDK 运行时的每个步骤。
数据预处理
此步骤转换原始输入数据并预处理和拆分为训练集、验证集和测试集。在此处理步骤中,我们使用 T
ensorFlow 框架处理器实例化了一个 SageMaker 处理
任务 ,该任务获取我们的脚本,从 Amazon S3 中复制数据,然后提取由 SageMaker 提供和维护的 Docker 映像。这个 Docker 容器允许我们在 requirements.txt 文件中传递库依赖关系,同时已经包含所有 TensorFlow 库,并传递脚本的 source_dir 路径。训练和验证数据进入训练步骤,测试数据被转发到评估步骤。使用此容器的最好之处在于,它允许我们将各种输入和输出作为不同的 S3 位置传递,然后这些输入和输出可以作为步骤依赖关系传递给 SageMaker 管道中的后续步骤。
#Initialize the TensorFlowProcessor
tp = TensorFlowProcessor(
framework_version='2.11',
role=get_execution_role(),
instance_type='ml.m5.xlarge',
instance_count=1,
base_job_name='frameworkprocessor-TF',
py_version='py39',
sagemaker_session=pipeline_session,
)
from sagemaker.processing import ProcessingInput, ProcessingOutput
from sagemaker.workflow.steps import ProcessingStep
processor_args = tp.run(
code='new_data_collection_kfold.py',
source_dir='scripts_processing',
inputs=[
ProcessingInput(input_name='data_unlabeled',source=data_unlabeled, destination="/opt/ml/processing/data_unlabeled"),
ProcessingInput(input_name='data_risky',source=data_risky, destination= "/opt/ml/processing/data_risky"),
ProcessingInput(input_name='data_dormant',source=data_dormant, destination= "/opt/ml/processing/data_dormant"),
ProcessingInput(input_name='data_normal',source=data_normal, destination= "/opt/ml/processing/data_normal"),
ProcessingInput(input_name='data_heavy',source=data_heavy, destination= "/opt/ml/processing/data_heavy")
],
outputs=[
ProcessingOutput(output_name="train_output_data", source="/opt/ml/processing/train/data", destination=f's3://{BUCKET}/{op_train_path}/data'),
ProcessingOutput(output_name="train_output_label", source="/opt/ml/processing/train/label", destination=f's3://{BUCKET}/{op_train_path}/label'),
ProcessingOutput(output_name="train_kfold_output_data", source="/opt/ml/processing/train/kfold/data", destination=f's3://{BUCKET}/{op_train_path}/kfold/data'),
ProcessingOutput(output_name="train_kfold_output_label", source="/opt/ml/processing/train/kfold/label", destination=f's3://{BUCKET}/{op_train_path}/kfold/label'),
ProcessingOutput(output_name="val_output_data", source="/opt/ml/processing/val/data", destination=f's3://{BUCKET}/{op_val_path}/data'),
ProcessingOutput(output_name="val_output_label", source="/opt/ml/processing/val/label", destination=f's3://{BUCKET}/{op_val_path}/label'),
ProcessingOutput(output_name="val_output_kfold_data", source="/opt/ml/processing/val/kfold/data", destination=f's3://{BUCKET}/{op_val_path}/kfold/data'),
ProcessingOutput(output_name="val_output_kfold_label", source="/opt/ml/processing/val/kfold/label", destination=f's3://{BUCKET}/{op_val_path}/kfold/label'),
ProcessingOutput(output_name="train_unlabeled_kfold_data", source="/opt/ml/processing/train/unlabeled/kfold/", destination=f's3://{BUCKET}/{op_train_path}/unlabeled/kfold/'),
ProcessingOutput(output_name="test_output", source="/opt/ml/processing/test", destination=f's3://{BUCKET}/{op_test_path}')
],
arguments=["--scaler_path", op_scaler_path,
"--bucket", BUCKET],
)
再培训
我们通过
SageMaker Pipel
ines T rainingStep API 封装了训练模块,并通过 TensorFlow 框架估算器(也称为脚本模式)使用已经可用的深度学习容器镜像进行 SageMaker 训练。
脚本模式允许我们对训练代码进行最少的更改,而 SageMaker 预建的 Docker 容器可以处理 Python、框架版本等。来自
Data_Prep
rocessing 步骤的 ProcessingOutpu t 已作为该步骤的训练输入转发。
from sagemaker.inputs import TrainingInput
inputs={
"train_output_data": TrainingInput(
s3_data=step_process.properties.ProcessingOutputConfig.Outputs["train_output_data"].S3Output.S3Uri,
content_type="text/csv",
),
"train_output_label": TrainingInput(
s3_data=step_process.properties.ProcessingOutputConfig.Outputs["train_output_label"].S3Output.S3Uri,
content_type="text/csv",
)
所有超参数都通过 JSON 文件通过估算器。在训练的每个时期,我们都已经通过脚本中的 stdOut 发送了训练指标。因为我们想跟踪正在进行的训练作业的指标并将其与之前的训练作业进行比较,所以我们只需要通过正则表达式定义来解析这个 StdOut,然后从 stdOut 中获取每个时代的指标。
tensorflow_version = "2.11"
training_py_version = "py39"
training_instance_count = 1
training_instance_type = "ml.c5.2xlarge"
tf2_estimator = TensorFlow(
source_dir='scripts_train/training/',
entry_point='train.py',
instance_type=training_instance_type,
instance_count=training_instance_count,
framework_version=tensorflow_version,
hyperparameters=hyperparameters,
image_uri = "763104351884.dkr.ecr.ap-south-1.amazonaws.com/tensorflow-training:2.11.0-cpu-py39-ubuntu20.04-sagemaker",
role=role,
base_job_name="Training-Marco-model",
py_version=training_py_version,
metric_definitions=[ {'Name': 'iteration', 'Regex': 'Iteration=(.*?);'},
{'Name': 'Discriminator_Supervised_Loss=', 'Regex': 'Discriminator_Supervised_Loss=(.*?);'},
{'Name': 'Discriminator_UnSupervised_Loss', 'Regex': 'Discriminator_UnSupervised_Loss=(.*?);'},
{'Name': 'Generator_Loss', 'Regex': 'Generator_Loss=(.*?);'},
{'Name': 'Accuracy_Supervised', 'Regex': 'Accuracy_Supervised=(.*?);'} ]
)
有趣的是,SageMaker Pipelines 会自动
与 SageMaker 实验 API 集成
,默认情况下,它会为每次运行创建实验、试用和试用组件。这使我们能够比较多次跑步的精度和精度等训练指标,如下所示。
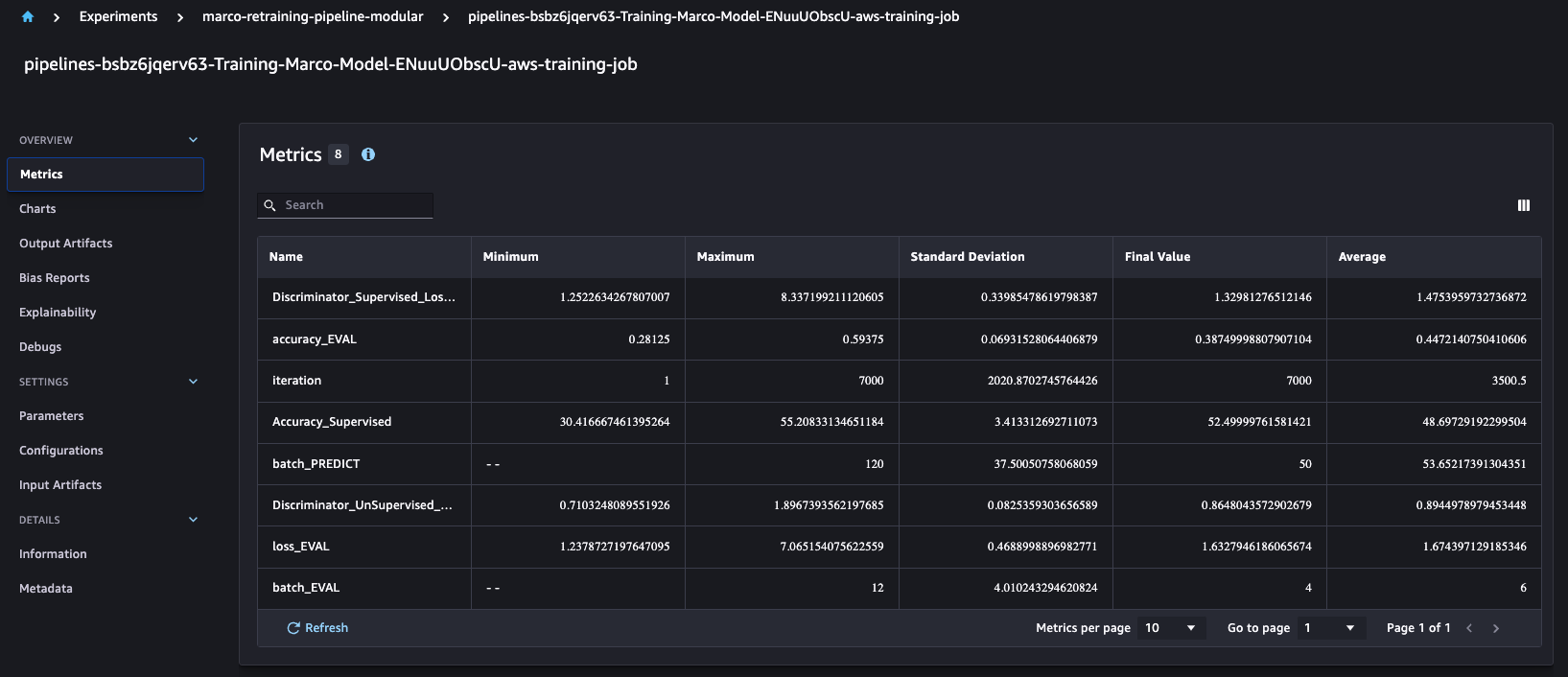
对于每次运行的训练任务,我们都会根据自定义业务定义为 Amazon S3 生成四种不同的模型。
评估
此步骤从 Amazon S3 加载经过训练的模型并根据我们的自定义指标进行评估。此 ProcessingStep 将模型和测试数据作为输入,并将模型性能报告转储到 Amazon S3 上。
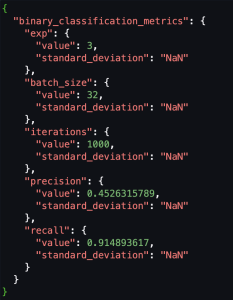
我们正在使用自定义指标,因此为了将这些自定义指标注册到模型注册表,我们需要将以 CSV 格式存储在 Amazon S3 中的评估指标的架构转换为 S
ageMaker 模型质量 JS
ON 输出。然后我们可以将此评估 JSON 指标的位置注册到模型注册表。
以下屏幕截图显示了我们如何将 CSV 转换为 Sagemaker 模型质量 JSON 格式的示例。

模型注册
如前所述,我们在单个训练步骤中创建了多个模型,因此我们必须使用 SageMaker Pipelines Lambda 集成将所有四个模型注册到模型注册表中。对于单一模型注册,我们可以使用
ModelStep
API 在注册表中创建 SageMaker 模型。对于每个模型,Lambda 函数从 Amazon S3 检索模型构件和评估指标,并为特定 ARN 创建一个模型包,这样所有四个模型都可以注册到单个模型注册表中。
SageMaker Python API
还允许我们发送自定义元数据,我们希望通过这些元数据来选择最佳模型。事实证明,这是提高生产率的重要里程碑,因为现在可以从单个窗口比较和审计所有模型。我们提供了元数据以唯一地区分模型。这也有助于在同行评审和基于模型指标的管理审查的帮助下批准单一模型。
def register_model_version(model_url, model_package_group_name, model_metrics_path, key, run_id):
modelpackage_inference_specification = {
"InferenceSpecification": {
"Containers": [
{
"Image": '763104351884.dkr.ecr.ap-south-1.amazonaws.com/tensorflow-inference:2.11.0-cpu-py39-ubuntu20.04-sagemaker',
"ModelDataUrl": model_url
}
],
"SupportedContentTypes": [ "text/csv" ],
"SupportedResponseMIMETypes": [ "text/csv" ],
}
}
ModelMetrics={
'ModelQuality': {
'Statistics': {
'ContentType': 'application/json',
'S3Uri': model_metrics_path
},
}
}
create_model_package_input_dict = {
"ModelPackageGroupName" : model_package_group_name,
"ModelPackageDescription" : key+" run_id:"+run_id, # additional metadata example
"ModelApprovalStatus" : "PendingManualApproval",
"ModelMetrics" : ModelMetrics
}
create_model_package_input_dict.update(modelpackage_inference_specification)
create_model_package_response = sm_client.create_model_package(**create_model_package_input_dict)
model_package_arn = create_model_package_response["ModelPackageArn"]
return model_package_arn
上面的代码块显示了我们如何通过模型包输入将元数据与模型指标一起添加到模型注册表的示例。
下面的屏幕截图显示了注册后我们可以轻松地比较不同模型版本的指标。
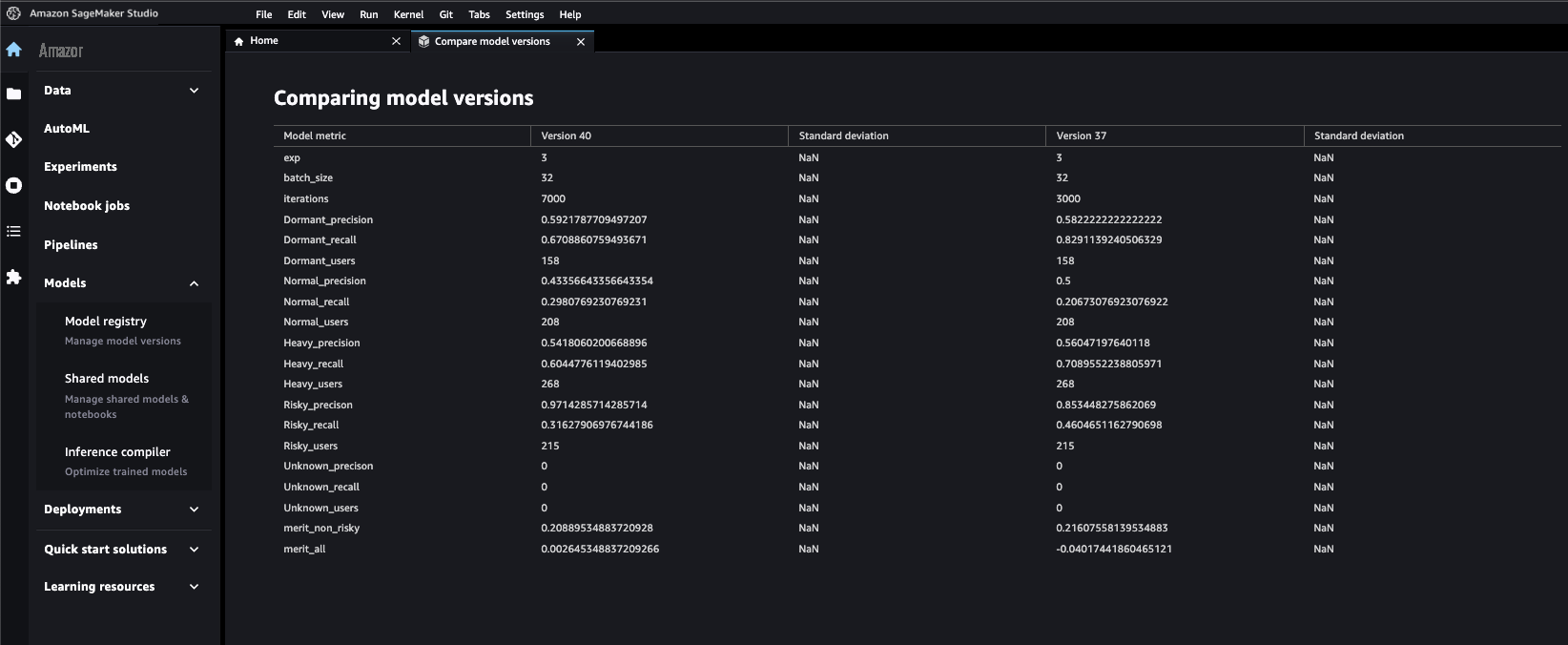
管道调用
该管道可以通过
EventBridge
、Sagemaker Studio 或 SDK 本身调用。
调用根据步骤之间的数据依赖关系运行作业。
from sagemaker.workflow.pipeline import Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[Preprocess-Kfold,Training-Marco,Evaluate-Marco,ScarceGAN-Model-register]
)
definition = json.loads(pipeline.definition())
pipeline.upsert(role_arn=role)
execution = pipeline.start()
execution.wait()
结论
在这篇文章中,我们演示了Games24x7如何通过SageMaker管道改造他们的mLops资产。事实证明,能够在参数化环境中直观地跟踪训练指标和评估指标,使用正确的处理平台和中央模型注册表单独扩展步骤,这是标准化并向可审计、可重复使用、高效和可解释的工作流程迈出的重要里程碑。该项目是不同数据科学团队的蓝图,通过允许成员操作、管理和使用最佳实践,提高了整体生产力。
如果你有类似的用例并想开始使用,那么我们建议你使用 Sagemaker Studio 通过 SageMaker
脚本模式
和
SageMaker 端到端示例
。这些示例包含本博客中介绍的技术细节。
现代数据策略为您提供了管理、访问、分析和处理数据的全面计划。亚马逊云科技 为所有工作负载、所有类型的数据和所有预期的业务成果的整个端到端数据旅程提供最完整的服务集。反过来,这使得 亚马逊云科技 成为从您的数据中释放价值并将其转化为见解的最佳场所。
作者简介
 侯赛因·贾吉尔达尔 是Games24x7
的资深科学家——应用研究。他目前参与可解释人工智能和深度学习领域的研究工作。他最近的工作涉及深度生成建模、时间序列建模以及机器学习和人工智能的相关子领域。他还热衷于 mLOP 和标准化需要限制的项目,例如可扩展性、可靠性和灵敏度。
侯赛因·贾吉尔达尔 是Games24x7
的资深科学家——应用研究。他目前参与可解释人工智能和深度学习领域的研究工作。他最近的工作涉及深度生成建模、时间序列建模以及机器学习和人工智能的相关子领域。他还热衷于 mLOP 和标准化需要限制的项目,例如可扩展性、可靠性和灵敏度。
 Sumir Kumar
是 亚马逊云科技 的解决方案架构师,在科技行业拥有超过 13 年的经验。在 亚马逊云科技,他与 亚马逊云科技 的主要客户紧密合作,设计和实施基于云的解决方案,以解决复杂的业务问题。他对数据分析和机器学习充满热情,在使用亚马逊云科技 Cloud帮助组织释放数据的全部潜力方面有着良好的记录。
Sumir Kumar
是 亚马逊云科技 的解决方案架构师,在科技行业拥有超过 13 年的经验。在 亚马逊云科技,他与 亚马逊云科技 的主要客户紧密合作,设计和实施基于云的解决方案,以解决复杂的业务问题。他对数据分析和机器学习充满热情,在使用亚马逊云科技 Cloud帮助组织释放数据的全部潜力方面有着良好的记录。